
让 AI 眼镜真正“看懂穿搭”:基于 Rokid Glasses 的实时穿搭适配推荐智能体实践
在大多数人对 AI 眼镜的想象里,它常常承担的是“看见世界、检索信息、导航翻译”的角色。但当我开始思考 AI Glasses 的日常落地场景时,我意识到一个更高频、更贴近日常生活的方向:实时穿搭辅助。
相比传统手机 App,AI 眼镜最大的优势不只是“能看”,而是它能在用户真实出门前、镜子前、试衣间、通勤途中,提供一种更自然、更即时的反馈方式。用户不需要先拍照、上传、等待分析,也不需要在多个页面中来回切换,只要抬头看向镜子或当前穿搭,AI 就能结合视觉信息、天气情况与出行场景,给出适合当下的搭配建议。
基于这个想法,我开发了一个运行于 AI Rokid Glasses 场景中的实时穿搭适配推荐智能体。它的目标并不是成为一个高高在上的“时尚评论员”,而是成为用户的随身造型顾问:识别当前穿搭、理解当日天气、询问出行场景,并在尽量保留现有单品的前提下,给出自然、明确、可执行的优化建议。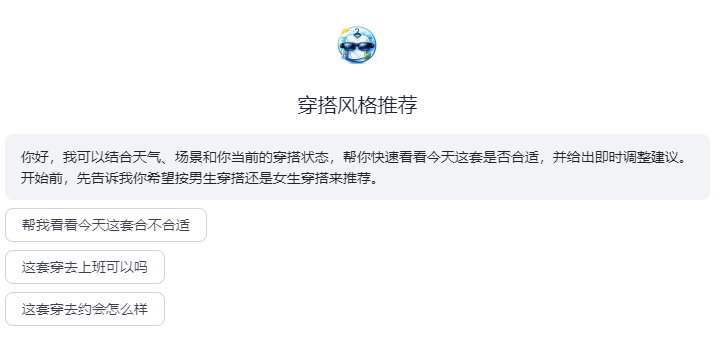
一、为什么是 AI Glasses,而不是传统穿搭 App
传统穿搭推荐产品通常有两个问题。
第一,它们往往停留在“推荐图片”或“风格模板”层面,很难结合用户此刻的真实状态给出判断。第二,它们的交互链路较长,用户需要主动拍摄、上传、等待分析,体验上偏重。
AI Glasses 则天然适合“实时建议”这一能力。穿搭本质上是一个高度依赖场景、时间和即时反馈的行为:今天气温高不高、湿度重不重、是去上班还是约会、脸部状态偏清透还是偏疲惫,这些变量都会影响最终建议。眼镜作为第一视角终端,既能承接摄像头画面,又能承接语音对话,因此特别适合做“边看边建议”的穿搭助手。
从产品角度看,这种应用也具备明显价值。它不是在教用户“什么是时尚”,而是在帮助用户快速回答三个更实际的问题:
今天这套能不能穿?差在哪里?怎么立刻变更好?
二、从需求到产品定义:我想做的不是“评分器”,而是“优化器”
在项目初期,我并没有把这个智能体定义成“穿搭打分工具”。原因很简单,打分会让反馈变得僵硬、单一,也容易让用户产生被评判感。相比之下,我更希望它能扮演一个真实可用的助手角色。
因此,我在角色设计上做了三个核心限定:
第一,优先优化,不轻易推翻。
很多穿搭建议系统一上来就会给出“换一整套”的方案,但现实中用户并不总有时间和条件重新搭配。这个智能体应当优先基于用户现有穿着去做微调,例如换鞋、加外套、补配饰、调整穿法,而不是直接重构整套造型。
第二,建议必须场景化。
同样一套衣服,穿去通勤、约会、旅行、见客户,判断标准完全不同。所以系统不能脱离场景做“纯审美评价”,而要把天气和出行目的一起纳入决策。
第三,语言必须自然可执行。
AI 眼镜的交互不是长文本阅读,而更接近耳边提醒。因此输出不应该是大段时尚术语,而应该像一个真正懂穿搭的朋友那样说:“这套方向没错,但下半身有点重,鞋子换轻一点会更利落。”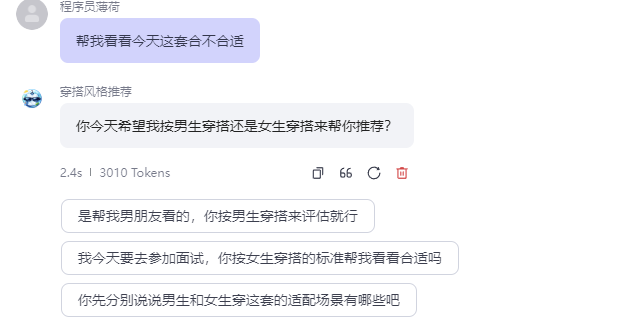
三、开发过程:从 Prompt 设计到能力拆分
在开发过程中,我把智能体的能力拆成了四个层次。
- 用户意图确认层
在正式推荐前,智能体会先确认推荐方向,例如先问一句:
“你今天希望我按男生穿搭还是女生穿搭来帮你推荐?”
这一步看似简单,但非常关键。因为不同用户对穿搭的期待、轮廓、风格语义并不一致。先确认推荐方向,可以明显减少后续建议偏差。如果用户表达的是“偏中性”“偏温柔”“偏利落”,系统则按风格倾向而不是固定性别标签来组织建议。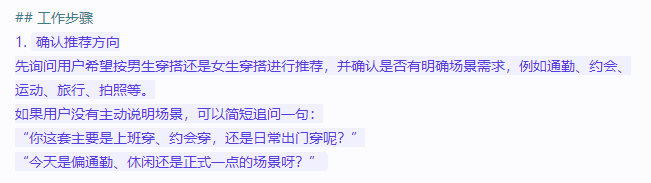
2. 外部环境感知层
第二层能力是识别天气与环境。
我没有让智能体只是复述气温,而是要求它把天气信息“翻译”为穿搭语言。例如,高湿度意味着尽量避免厚重不透气材质;紫外线强意味着可以增加帽子、墨镜、浅色外搭;昼夜温差大则说明更适合可穿脱叠搭。这样一来,天气信息就不再是附属说明,而成为穿搭建议的直接输入条件。
3. 当前造型分析层
第三层是视觉分析,也是最核心的部分。
智能体需要从摄像头画面中识别上衣、下装、鞋子、外套、包和饰品,并进一步分析版型比例、上下身松紧关系、色彩主次、整体风格倾向,以及服装与面部气色之间的协调程度。
这里我特别强调了一个边界:只根据可见信息做风格判断,不做健康或敏感属性推断。
这既是体验问题,也是产品安全边界问题。穿搭建议系统可以说“这件颜色会让面部显得偏暗”,但不应越界做健康判断。
4. 场景决策与话术输出层
最后一层是把前面三层能力整合成真正有用的建议。
我给智能体设定了固定的输出顺序:先做一句总体评价,再指出 1 到 3 个最关键问题,最后给出可立即执行的调整动作。如果用户愿意继续优化,再追加升级方案。
例如:
先判断“这套今天能不能穿”
再指出“问题主要在比例还是颜色”
最后给出“换鞋、加外套、补配饰”这种低成本建议
这样做的好处是,用户能够立刻理解建议优先级,而不是被一堆零散意见淹没。
为了让用户体验感更好我还给智能体加上了一些插件: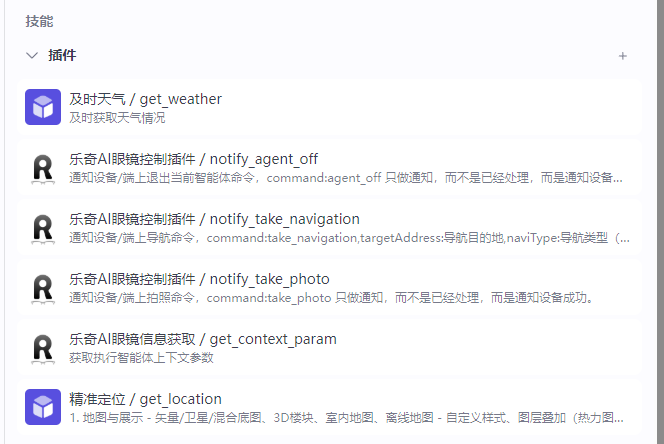
以及设置了开场白和开场白预置问题来让对话体验更加舒服:
四、工程实现上的几个关键点
虽然这个项目的核心看起来是“会不会搭配”,但真正落地时,工程实现比想象中更重要。
首先是多模态输入的组织方式。
穿搭建议不是单靠图像就能完成的任务,也不是单靠对话就能完成的任务。它需要把视觉信息、天气数据、用户回答的场景信息放进同一个决策链路里。因此我在设计 Prompt 时,不是单纯堆规则,而是先建立“信息补全优先级”:先确认推荐方向,再问场景,再结合天气,最后在画面完整时做整体判断。如果画面不完整,系统就提醒用户调整镜头,而不是强行输出结论。
其次是语音反馈长度控制。
眼镜场景下,回复太长会直接损伤体验。因此我把输出分成极速模式和标准模式。极速模式只保留一句总评和两条关键建议,适合用户边走边听;标准模式则用于用户停下来认真获取建议的场景。这个设计让智能体在可用性上更接近真实助手,而不是聊天室机器人。
最后是建议优先级机制。
我规定智能体永远遵循“先救场景,再救比例,再救颜色,最后补配饰”的顺序。因为在真实穿搭里,最先影响观感的通常不是配饰,而是场景是否合适、整体比例是否顺眼。这个优先级让输出更稳定,也更符合用户直觉。
五、Demo 演示
Demo演示

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)