
Agent测试方法论:多智能体系统怎么测? 一个 Agent 翻车还好说,五个协作的呢

01 · THE SHIFT从一个 Agent 到五个,发生了什么
我们团队的测试用例生成平台,最终跑起来的是一套五节点的 Multi-Agent 流水线:需求分析(A1)、测试点设计(A2)、用例编写(A3)、用例评审(A4)、用例导出(A5),由一个 Supervisor 统一调度,每个节点各司其职。
系统设计完之后,第一个让我头疼的问题不是功能本身,而是:这玩意儿怎么测?
单节点时我们已经有了一套方法:Eval 数据集、LLM-as-Judge、故障注入。但把五个 Agent 接在一起之后,之前那套方法突然不够用了。原因不复杂——单个 Agent 的输出是独立的,你能清楚地定义「这个输入进来,期望这类输出」。五个 Agent 的输出是相互依赖的,A1 的输出是 A2 的输入,A2 的偏差会放大进 A3,到了 A4 评审时你看到的问题,可能是三个节点之前埋下的。

这个架构运行时的实际情况是:Supervisor 决定当前该激活哪个节点,每个节点把自己的输出写进共享 State,下一个节点从 State 里读取上游结果继续工作。看起来很清晰,但测试时的问题也在这里——State 是所有节点的交汇点,任何一个节点写坏了 State,下游所有节点都会跟着出问题。
02 · THE COMPLEXITY复杂度为什么是指数级的
「五个 Agent 的系统比一个 Agent 复杂五倍」——这个直觉是错的,实际要复杂得多。
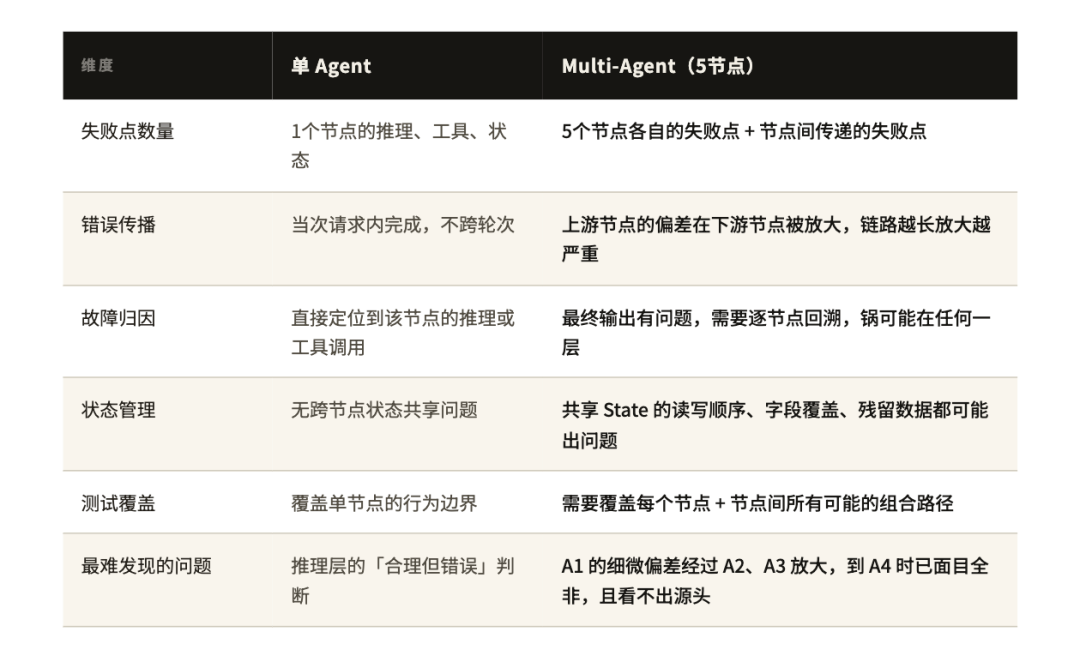

这段话说的是对话 Agent,但同样适用于我们的 Multi-Agent 流水线。A3 写出的用例「单独看」格式正确、措辞规范,但如果 A2 设计的测试点存在遗漏,A3 写得再好也是无用功。问题不在 A3,但 A3 的输出会让人误以为没问题。
03 · THE THREE PROBLEMSMulti-Agent 专属的三类测试难题

04 · THE MODESSupervisor 模式 vs Peer 模式,测试策略完全不同
Multi-Agent 系统有两种主要的架构模式,测试难点不一样,需要不同的应对策略。

我们用的是 Supervisor 模式,原因不只是因为它更容易实现,更重要的是它更容易测试。Supervisor 是一个清晰的责任边界:调度逻辑在这里,执行逻辑在各个节点,出了问题你知道去哪里找。Peer 模式理论上更灵活,但在工程实践里,「灵活」往往意味着「没有人知道这个系统到底在干什么」。
05 · THE STRATEGYMulti-Agent 测试的实践建议
分层测试,先单节点后整体
不要一上来就跑整条流水线的端到端测试。正确的顺序是:先单独测每个节点(给定标准输入,验证输出符合该节点的行为约束),节点通过之后,再测节点间的衔接(A1 的输出作为 A2 的输入,验证 A2 能正确消化),最后才是完整流水线的端到端测试。
这样分层有一个好处:当端到端测试出了问题,你已经知道每个节点的单独行为是正确的,可以把排查范围直接锁定在节点间的衔接部分。省掉了大量「到底是哪里有问题」的盲目排查时间。

给每个节点的输出定义「接口契约」
这是从软件工程借来的概念,在 Multi-Agent 测试里非常有用。每个节点对外输出的数据结构,要当成接口来定义和维护:哪些字段必须存在、数据类型是什么、允许为空吗、下游节点依赖哪些字段。
有了接口契约,当下游节点出问题时,你的第一个问题变成了:「上游节点是否履行了它的契约?」而不是「哪里出了问题」。这把一个模糊的问题变成了一个有答案的问题。
监控「跨节点的一致性」,不只是各节点的正确性
-
需求覆盖率追踪:A1 提取了多少个功能模块,A3 最终产出的用例覆盖了多少。如果 A1 提取了 10 个模块,A3 只覆盖了 6 个,中间丢了 4 个,这是 A2 还是 A3 的问题?
-
约束传递验证:A1 如果标注了「该功能不测性能」,这个约束能不能一路传到 A3,确保 A3 没有写性能相关用例?跨节点的约束传递是最容易静默丢失的信息。
-
评审结论的根源分析:A4 评审时提出的每一条修改意见,追溯来源节点。如果 80% 的意见都指向「测试点设计不完整」,说明 A2 节点有系统性问题,不是 A3 写得不好。
06 · THE HARDEST PART最难的不是技术,是设计测试的时机
说到这里,有一件事必须说清楚:Multi-Agent 系统的测试,必须在架构设计阶段就介入,而不是等系统建完再来想怎么测。
为什么?因为很多可测试性问题是架构决定的。节点之间用什么结构传递数据、State 的字段怎么命名和分层、每个节点的输入输出是否有明确的 schema——这些在架构评审阶段决定,对后续测试的难度影响是决定性的。

早介入的另一个好处是:测试工程师在理解架构的过程中,往往能发现设计层面的风险,在代码还没写的时候就提出来,成本趋近于零。等系统跑起来再改,代价可能是推翻重写。
TAKEAWAY带走这两条
第一:Multi-Agent 的复杂度是指数级的,不是线性的。不要用测单个 Agent 的思维来测一个五节点的流水线。分层测试——先节点、再衔接、最后端到端——是目前最可控的方式。
第二:出了问题先问「State 对不对」,而不是「哪个节点有 bug」。Multi-Agent 系统里大多数诡异的问题,根源都是共享 State 在某个节点被写坏了,然后在下游节点表现出来。State 快照是你最有效的侦探工具。
📞 支持与反馈
维护团队: 北京慧测·杭州但问智能技术团队

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)