
如何开发需求文档质量评分的Skill
本文介绍了一种利用AI评价需求文档质量的智能方法。传统人工评审存在标准不一、效率低下等问题,该方案通过5个核心指标(关注内容边界、可验证性、无歧义性、正确性、一致性)对需求文档进行结构化分析。AI能自动识别文档中的需求条目,逐条评估质量,生成包含问题定位和改进建议的详细报告,包括文档等级评定、高频问题词统计和修复清单。该方法将人工从重复性工作中解放出来,使团队能聚焦于业务逻辑和用户体验等核心问题。
前言
需求文档是软件项目的源头。一份写得好的需求文档,能让开发、测试、产品经理对同一件事有相同的理解;而一份模糊、矛盾、充满技术实现细节的需求文档,则是返工、扯皮和Bug的温床。
传统上,需求文档的质量全靠人工评审。但人工评审存在三个痛点:标准不一(不同评审者尺度不同)、效率有限(逐条评审耗时耗力)、难以追踪(质量变化缺乏量化度量)。
AI的出现,给了我们一个破局的机会。本文将介绍如何开发一个AI智能化评价需求文档描述质量的Skill。
一、整体设计思路
1.1 这个Skill要做什么
这个Skill的核心任务很简单:输入一份需求文档,输出一份结构化的质量评审报告。
但“质量评审”这个词太笼统了。我们需要把它拆解为可操作的具体步骤:
- 识别出文档中的所有需求条目
- 逐条判定每条需求的描述质量
- 汇总统计整份文档的质量全貌
- 生成报告,告诉用户问题在哪、怎么改
1.2 指标体系的取舍
评价需求质量,业界有很多标准和指标。IEEE 830提出了8个特性,ISO 29148有更复杂的框架。但如果我们一开始就用全套指标,会让AI判断变得复杂,用户也很难理解评审结果。
经过反复筛选,我最终锁定了5个核心指标:
|
# |
指标 |
一句话解释 |
|
1 |
关注“什么” |
只说需要什么,不说怎么实现 |
|
2 |
可验证性 |
能量化、能测试、能客观判定 |
|
3 |
无歧义性 |
所有人读完只有一种理解 |
|
4 |
正确性 |
描述的业务规则没有事实错误 |
|
5 |
一致性 |
需求之间不冲突,术语统一 |
这5个指标的逻辑关系是:1关注内容边界,2和3关注表述工程,4关注事实准确,5关注集合协调。它们共同构成了一条好需求的充分必要条件。
二、指标体系的详细设计
2.1 指标1:关注“什么”
定义:需求应陈述系统“需要什么”,而非“如何实现”。
这个指标的目的是把需求从设计文档中剥离出来。需求只说“系统要做什么”,至于用什么技术栈、什么架构、界面长什么样,那是设计阶段的事。
判定要点:
- 扫描语句中是否出现技术实现词汇(如“MySQL”“Redis”“React”“微服务”)
- 检查是否描述了UI布局细节(如“按钮放在右上角”“弹窗从底部滑出”)
- 例外情况:如果某条陈述本身就是一项不可协商的设计约束(例如法规强制的“必须使用AES-256加密”),则不判为违规
案例:
|
类型 |
需求原文 |
判定 |
|
不合格 |
“用户登录时,后端使用Redis缓存Session信息。” |
描述了技术实现方案 |
|
合格 |
“系统在连续5次密码错误后,应锁定账户15分钟。” |
仅描述了系统能力,无实现细节 |
2.2 指标2:可验证性
定义:需求中存在客观、可量化的验收标准,通过检查、演示或测试可判定其是否满足。
这是最容易出问题的指标。需求工程师在写文档时,常常不自觉地使用模糊、主观的词汇。这些词在编写时很省事,但到了开发测试阶段就成了麻烦。
模糊词禁用清单:
快速、高效、稳定、用户友好、易于、灵活、健壮、美观、尽可能、适当、必要、相关、显著、较好、支持、增强
判定要点:
- 是否包含上述模糊词且无量化的补充说明
- 是否有可度量的数值、比率、时间或明确的布尔条件
案例:
|
类型 |
需求原文 |
判定 |
|
不合格 |
“系统响应应快速。” |
“快速”是模糊词,无量化标准 |
|
合格 |
“在500并发请求下,95%的支付接口响应时间应≤3秒。” |
有场景、有数值、可测试 |
2.3 指标3:无歧义性
定义:需求语言精确,任何两位读者都能得出相同的解释。
歧义是需求的隐形杀手。一个有歧义的需求,从产品经理到开发到测试,每个人理解的都“差不多”,但最终做出来的东西往往“差很多”。
常见歧义来源:
- 指代不明的代词(它、这、那、其)
- 未定义的简写或专业术语
- 多重条件嵌套(和/或、除非、但是)
- 度量单位缺失或不统一
案例:
|
类型 |
需求原文 |
判定 |
|
不合格 |
“当它失败时,系统应报警。” |
“它”指代不明;“报警”方式未定义 |
|
合格 |
“当支付网关连接超时时,系统应向用户展示‘支付服务暂不可用’提示,并向运维中心发送error级别告警。” |
触发条件、系统行为、通知对象均明确 |
2.4 指标4:正确性
定义:需求描述的规则、数据、流程符合业务逻辑和客观事实。
这个指标对AI来说存在能力边界。AI可以检查公式是否引用了不存在的变量、同一参数前后是否矛盾,但它无法判断需求是否真的是用户“想要的”。因此,AI的定位是标记“疑似错误”和“待确认项”,最终的判断权还是交给人。
AI可检查的:
- 计算公式引用了不存在的字段
- 引用的法规条款版本过时或明显不适配
- 业务规则在逻辑上无法闭环
AI无法判断的:
- “用户真的需要这个功能吗?”(需要业务方确认)
2.5 指标5:一致性
定义:需求在文档内部以及与其他文档之间,不存在矛盾或冲突。
一致性问题的典型表现是:需求A说了一件事,需求B说了另一件与之矛盾的事。更隐晦的问题是术语混用——前文用“消费者”,后文用“客户”,看似都懂,但可能被理解为不同实体。
常见冲突类型:
- 同一参数值定义矛盾(如“密码≥8位”与“密码6-12位”)
- 行为描述冲突(如“所有用户需认证”与“游客可下单”)
- 术语不统一(“用户ID”与“账号”
三、从单条到整体:文档级聚合
逐条判定完成后,需要把所有结果汇聚成对整份文档的评价。
3.1 统计维度
|
统计项 |
说明 |
|
需求总条目数 |
文档中识别出的需求总数 |
|
合格率 |
合格条目数 ÷ 总条目数 × 100% |
|
各指标达标率 |
每个指标合格的条目占比 |
|
严重/轻微问题分布 |
问题标签的数量和占比 |
|
高频问题词 |
被标记的模糊词汇出现频次Top 10 |
3.2 文档等级评定
基于统计结果,给文档打一个直观的等级,如:
|
等级 |
条件 |
建议动作 |
|
A(优秀) |
合格率≥90%,严重问题0% |
可直接进入开发 |
|
B(良好) |
合格率≥75%,严重问题<5% |
少量修改后进入开发 |
|
C(需修改) |
合格率≥60%,或严重问题5%-15% |
需针对性修改后复审 |
|
D(不合格) |
合格率<60%,或严重问题>15% |
建议重写或大规模返工 |
四、评价报告的结构设计
评价报告是Skill面向用户的最终产出。一份好的报告不应只是一个分数,而应该像一份体检报告:告诉用户整体健康度、哪里有毛病、怎么治。
4.1 报告模块设计
需求文档质量评审报告
├── 基本信息(文档名称、评审时间、需求总数)
├── 一、总体评价(一段话概括)
├── 二、质量画像
│ ├── 红绿灯分布(合格/轻微问题/严重问题)
│ ├── 各指标达标率
│ └── 高频问题词云
├── 三、分级修复清单
│ ├── 必须修复项(阻断类)
│ ├── 建议修复项(高风险类)
│ └── 待人工确认项
├── 四、改进建议(面向团队的通识建议)
└── 五、附录:逐条评审明细表
4.2 修复清单的重要性
这是报告中最有实用价值的部分。AI不能只给用户丢一个“60分,不合格”,它必须告诉用户具体哪条需求有问题、违反了哪个指标、建议怎么改。这份清单就是团队的待办事项列表,可以直接用于工作分派。
五 评分案例
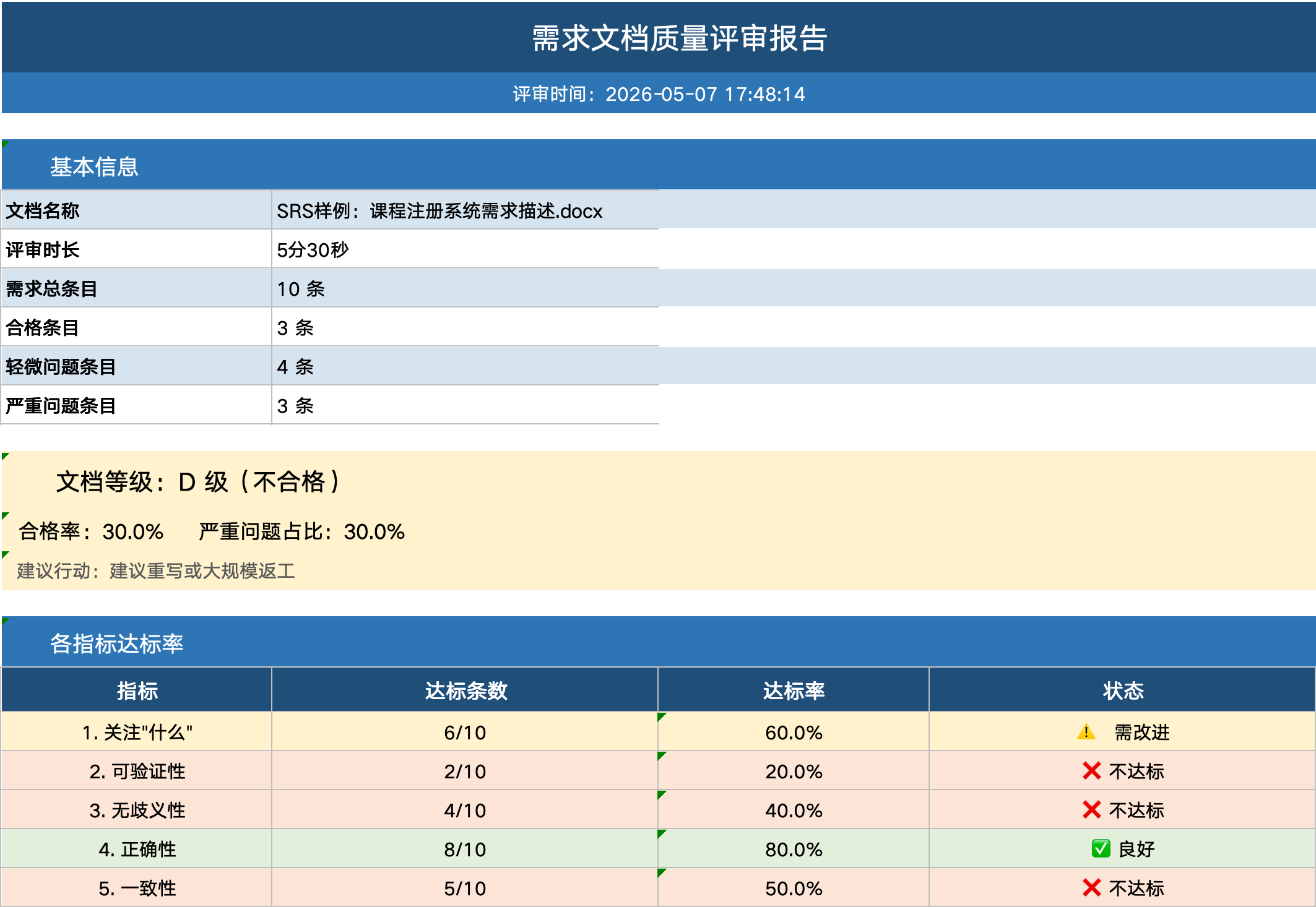

|
�� 逐条评审明细 |
|||||||||||
|
需求ID |
原文摘要 |
指标1 |
指标2 |
指标3 |
指标4 |
指标5 |
综合标签 |
||||
|
REQ-001 |
登录:用户输入用户名和密码,系统确认密码后显示主程序 |
✅ |
❌ |
✅ |
✅ |
✅ |
�� |
||||
|
REQ-002 |
维护教授信息:管理员增加、修改、删除教授信息,包括姓名、出生日期、身份证号、部门等 |
✅ |
❌ |
❌ |
✅ |
✅ |
�� |
||||
|
REQ-003 |
选择预授课程:教授从课程目录中选择符合条件的期望课程,系统验证课程冲突 |
✅ |
❌ |
❌ |
✅ |
✅ |
�� |
||||
|
REQ-004 |
维护学生信息:管理员增加、修改、删除学生信息,包括姓名、出生日期、身份证号、毕业日期等 |
✅ |
❌ |
❌ |
✅ |
✅ |
�� |
||||
|
REQ-005 |
注册课程:学生选择4门主要课程和2门备选课程,每门课程注册人数不超过50人 |
✅ |
✅ |
❌ |
✅ |
✅ |
�� |
||||
|
REQ-006 |
结束注册:管理员结束注册过程,课程人数最小值3人,向学生发送通知 |
✅ |
✅ |
❌ |
✅ |
✅ |
�� |
||||
|
REQ-007 |
提交分数:教授提交上学期学生完成课程的分数 |
✅ |
❌ |
❌ |
✅ |
✅ |
�� |
||||
|
REQ-008 |
浏览报告卡:学生浏览上学期的报告卡,显示完成的课程分数信息 |
✅ |
❌ |
✅ |
✅ |
✅ |
�� |
||||
|
�� 必须修复项(阻断类) |
|||||||||||
|
需求ID |
原文摘要 |
违反指标 |
问题描述 |
修复建议 |
|||||||
|
✅ 无必须修复项,文档质量良好 |
|||||||||||
|
�� 建议修复项(高风险类) |
|||||||||||
|
需求ID |
原文摘要 |
违反指标 |
问题描述 |
修复建议 |
|||||||
|
REQ-001 |
登录:用户输入用户名和密码,系统确认密码后显示主程序 |
指标2-可验证性 |
无量化验证标准:未明确密码验证规则(如错误次数限制、锁定时间) |
增加量化验证标准,如:连续输入错误密码5次后账户锁定30分钟 |
|||||||
|
REQ-002 |
维护教授信息:管理员增加、修改、删除教授信息 |
指标2-可验证性, 指标3-无歧义性 |
可验证性:'确认该日期'未定义验证标准;无歧义性:'正确的数据格式'具体指什么格式未说明 |
明确日期格式标准(如YYYY-MM-DD);说明数据验证的具体规则 |
|||||||
|
REQ-003 |
选择预授课程:教授从课程目录中选择符合条件的期望课程 |
指标2-可验证性, 指标3-无歧义性 |
可验证性:'符合条件的'未量化;无歧义性:'承诺的课程'定义不明,课程冲突判断规则未具体说明 |
明确教授资格条件(如资质证书、职称要求);定义'承诺的课程'为已签署授课协议的课程;说明冲突检测的具体逻辑(相同日期+时间段) |
|||||||
|
REQ-004 |
维护学生信息:管理员增加、修改、删除学生信息 |
指标2-可验证性, 指标3-无歧义性 |
可验证性:'有效'的日期格式未定义;无歧义性:'相同姓名'判断逻辑不明确(完全相同还是模糊匹配) |
明确日期格式标准(如YYYY-MM-DD);说明学生姓名查重规则(如精确匹配身份证号或姓名+出生日期组合) |
|||||||
|
REQ-005 |
注册课程:学生选择4门主要课程和2门备选课程 |
指标3-无歧义性 |
'前提条件'的具体内容未定义;'开放的课程'指什么状态不明确 |
列出学生注册课程的前提条件清单(如已缴费、已完成选课咨询);定义'开放'为课程未被取消且仍在注册期内 |
|||||||
|
REQ-006 |
结束注册:管理员结束注册过程,人数最小值3人 |
指标3-无歧义性 |
'相应的事务信息'具体指什么内容未定义;发送通知的具体方式和内容不明确 |
明确通知内容(如课程确认信息、课表摘要);定义通知方式(如邮件/短信/系统消息)和触发时机 |
|||||||
|
REQ-007 |
提交分数:教授提交上学期学生完成课程的分数 |
指标2-可验证性, 指标3-无歧义性 |
可验证性:分数格式和有效范围未定义(如0-100分或A-E等级制);无歧义性:'上学期'具体指哪个时间段未说明 |
明确分数有效范围(如0-100整数)和不及格判定标准;定义'上学期'为当前学期的前一个完整学期 |
|||||||
|
REQ-008 |
浏览报告卡:学生浏览上学期的报告卡 |
指标2-可验证性 |
'报告卡'应包含的具体内容未定义;无明确的展示格式或字段说明 |
定义报告卡必含内容:课程名称、分数/等级、学分、 GPA贡献;说明显示格式(如学期汇总、历年累计) |
|||||||
|
⚪ 待人工确认项 |
|||||||||||
|
需求ID |
原文摘要 |
涉及指标 |
疑似问题 |
确认要点 |
|||||||
|
✅ 无待确认项 |
|||||||||||
|
�� 改进建议 |
|
|
1 |
本次评审中'可验证性'达标率偏低(12.5%),建议团队建立量化标准清单,在需求编写阶段明确数值、时间、布尔条件等可验证指标,避免使用'快速'、'高效'等模糊词汇。 |
|
2 |
发现多处术语和概念定义不明确的问题(如'前提条件'、'开放的课程'、'承诺的课程'),建议建立项目级术语表,对关键业务概念进行统一定义和说明。 |
|
3 |
8个用例均采用自然语言描述,缺乏结构化的验收条件。建议引入验收标准模板,每条功能需求应包含明确的输入条件、处理规则、预期输出和异常处理描述。 |
结语
一个AI Skill的价值,不在于它替代了人,而在于它把人从重复、机械的检查中解放出来,让人可以聚焦在真正需要判断力的地方——业务是否正确、体验是否恰当、取舍是否明智。
需求质量的提升,最终还是要靠团队的共识和纪律。AI的角色是:用稳定的标准、高效的扫描、清晰的报告,帮团队看见问题、对齐标准、持续改进。
如果你正准备在团队中落地这个Skill,希望这篇文章能给你一个可参考的设计蓝图。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)