
AI Agent 记忆系统深度调研 2026:从基础原理到企业级方案
来源: OpenClaw EverMemOS Plugin 文档模式说明keywordBM25 精确匹配vector语义向量相似度hybridkeyword + vector 组合rrfReciprocal Rank Fusion 重排agenticLLM-guided 反复搜索注意:一些二手介绍里会说"4 种检索模式",实际以 5 种为准。
AI Agent 记忆系统深度调研 2026:从基础原理到企业级方案
文章目录
查询日期: 2026-05-13 | 数据来源: arXiv / GitHub / 官方博客
摘要: 从 LLM 无状态 API 的"失忆症"讲起,沿 CoALA 四分法与 Google 白皮书二分法拆解记忆分类与三种操作,横向对比 OpenClaw、EverOS、Letta、Mem0、Zep、LangMem 等主流方案,给出选型建议与未来方向。
一、大模型的"失忆症":问题的起点
每一次调用大模型 API,你其实都是在跟一个"失忆者"说话。
模型侧没有会话状态,所有"记忆"都靠客户端把历史塞进 prompt 里送回去。上下文一满,旧内容被截断或压缩,模型就忘了你们几分钟前聊过什么。Claude Sonnet 4 / Gemini 2.5 Pro / GPT-5 这样的顶级模型也逃不开——它们只是记性不好的时间,被拖得更久一点而已。
几个你很可能已经遇到过的真实问题:
- 在 Claude Code 里跟 Agent 磨了半小时才对齐的项目架构约定,关掉终端重开,它又把你当陌生人。
- 你告诉 Cursor “我偏好 Tailwind 不要 styled-components”,三天后它还是自动写出了一个 styled-components 组件。
- 用 Codex CLI 修复过的一个构建 bug,一个月后再次遇到同样的坑,它像从没见过一样重复踩。
- 你让 Gemini 记住 “我的生产数据库在 AWS eu-west-1”,它当前会话记得,新开一个会话就再也没印象。
- 做 agentic workflow 编排时,上游 agent 推导出的关键事实,下游 agent 拿不到,只能靠你手工 copy-paste 当"二传手"。
- 你期待 Agent 能像一个团队成员那样"越用越熟悉我",但它更像个实习生,每天早上都从零开始自我介绍。
这些症状指向同一个缺口:LLM 有推理能力,但没有记忆基础设施。它不是不会算,而是不会记。
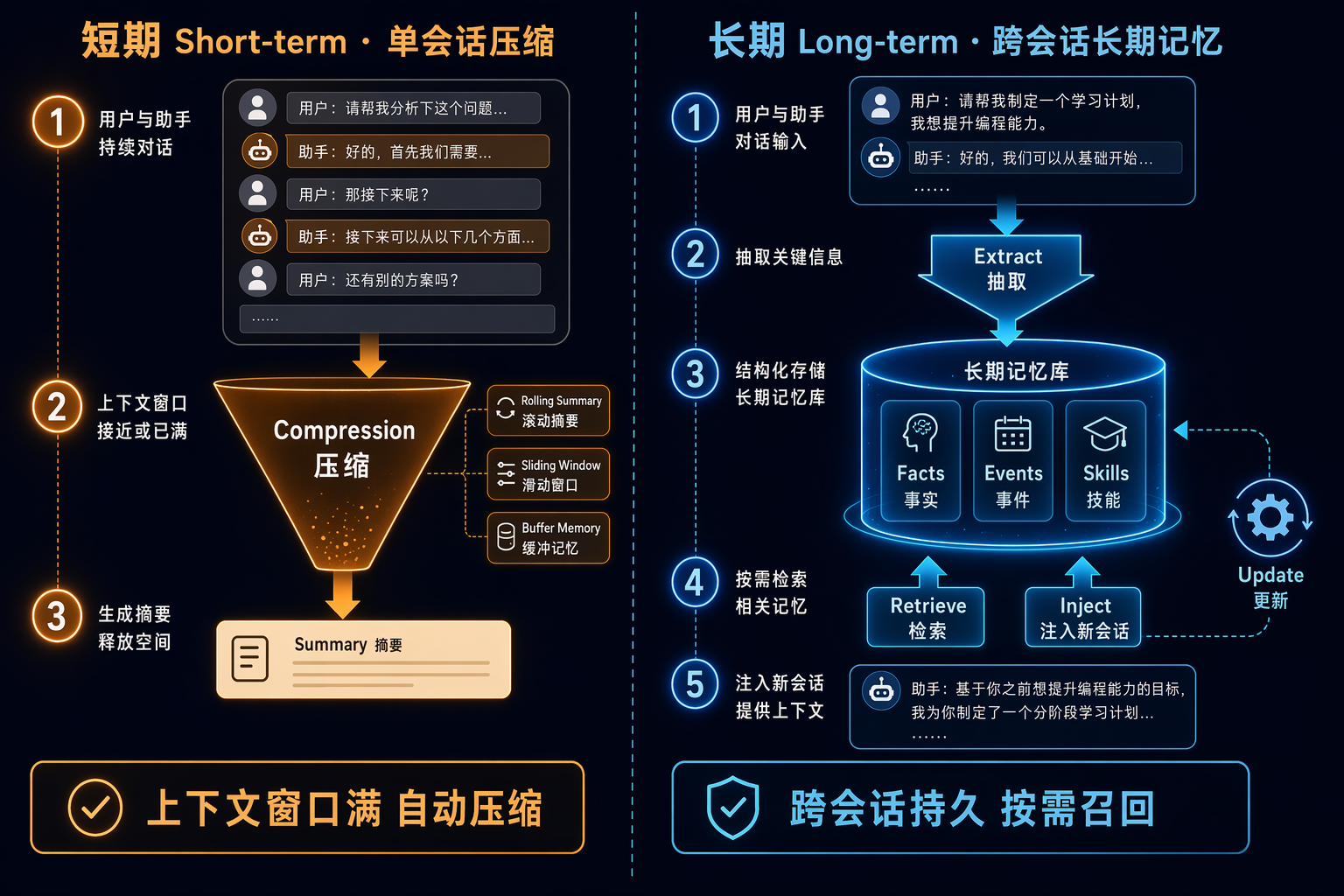
解决缺口的方向分两层:
- 单会话内: 上下文长了怎么办?通常靠压缩(rolling summary、sliding window、langchain 的 ConversationSummaryBufferMemory),让旧消息浓缩成摘要再续写。这是"短期记忆"。
- 跨会话: 会话之间的偏好、身份、事实、技能怎么留下来?需要外置存储 + 抽取 + 检索 + 更新的闭环。这是"长期记忆"。
短期记忆大部分 Agent 框架都解决得差不多了。真正的竞争和创新,发生在长期记忆这一层。
本文就是顺着这条主线,把 2026 年 5 月时点的记忆系统版图梳理一遍:从 CoALA / Google 白皮书的理论框架,到 OpenClaw 最朴素的 “记笔记” 方案,到 EverOS / MemGPT / Mem0 / Zep 这些企业级的"操作系统"级实现,最后给一个可操作的选型判断。
二、分析框架:两种分类 + 三种操作
要比较记忆系统,不能只看 feature list。先建立一个坐标轴。
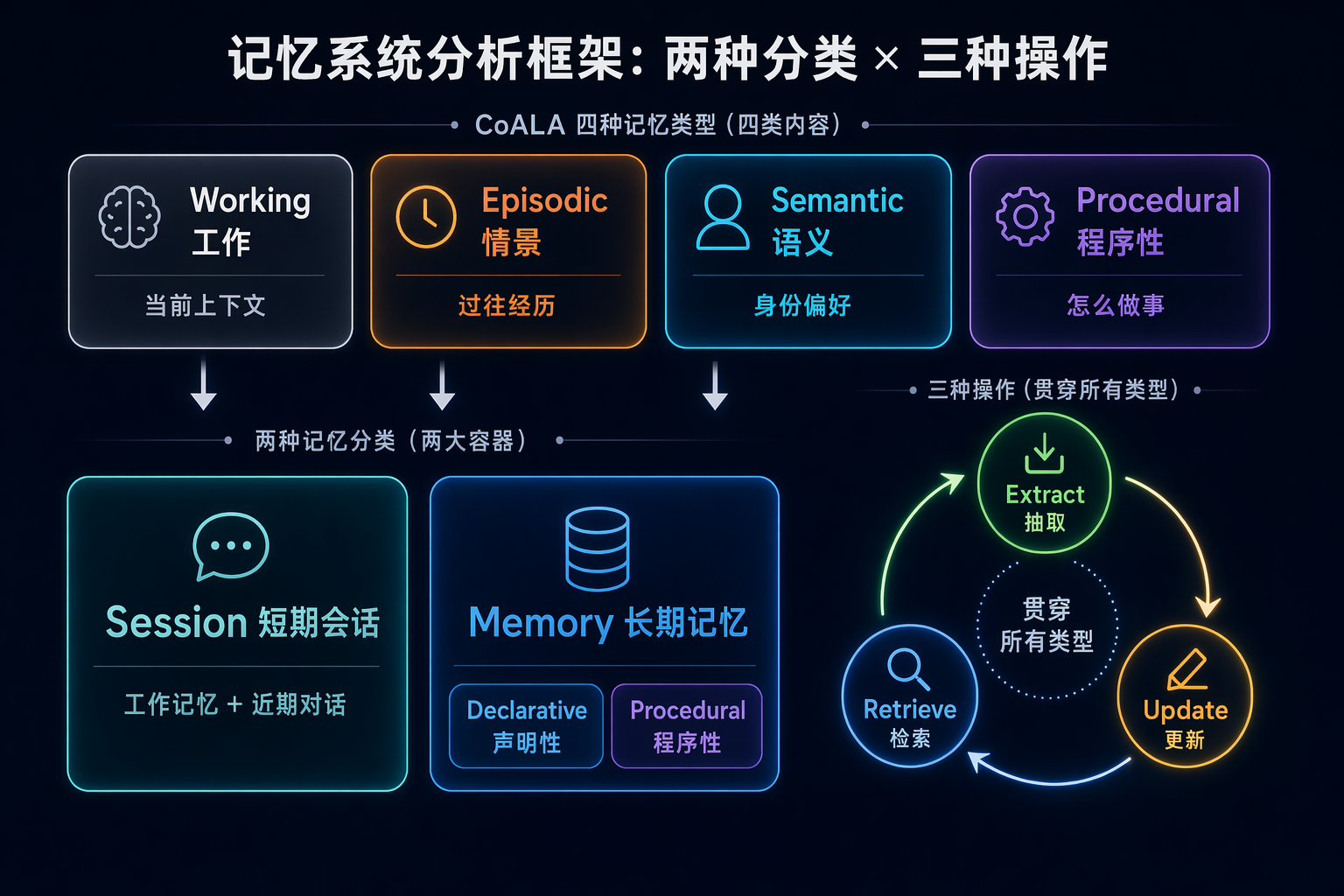
2.1 CoALA 四分法:认知架构的心智原型
CoALA: Cognitive Architectures for Language Agents 是 Princeton 的 Sumers、Yao、Narasimhan、Griffiths 在 arXiv:2309.02427 上提出的框架,发表在 TMLR 2024(https://arxiv.org/abs/2309.02427)。
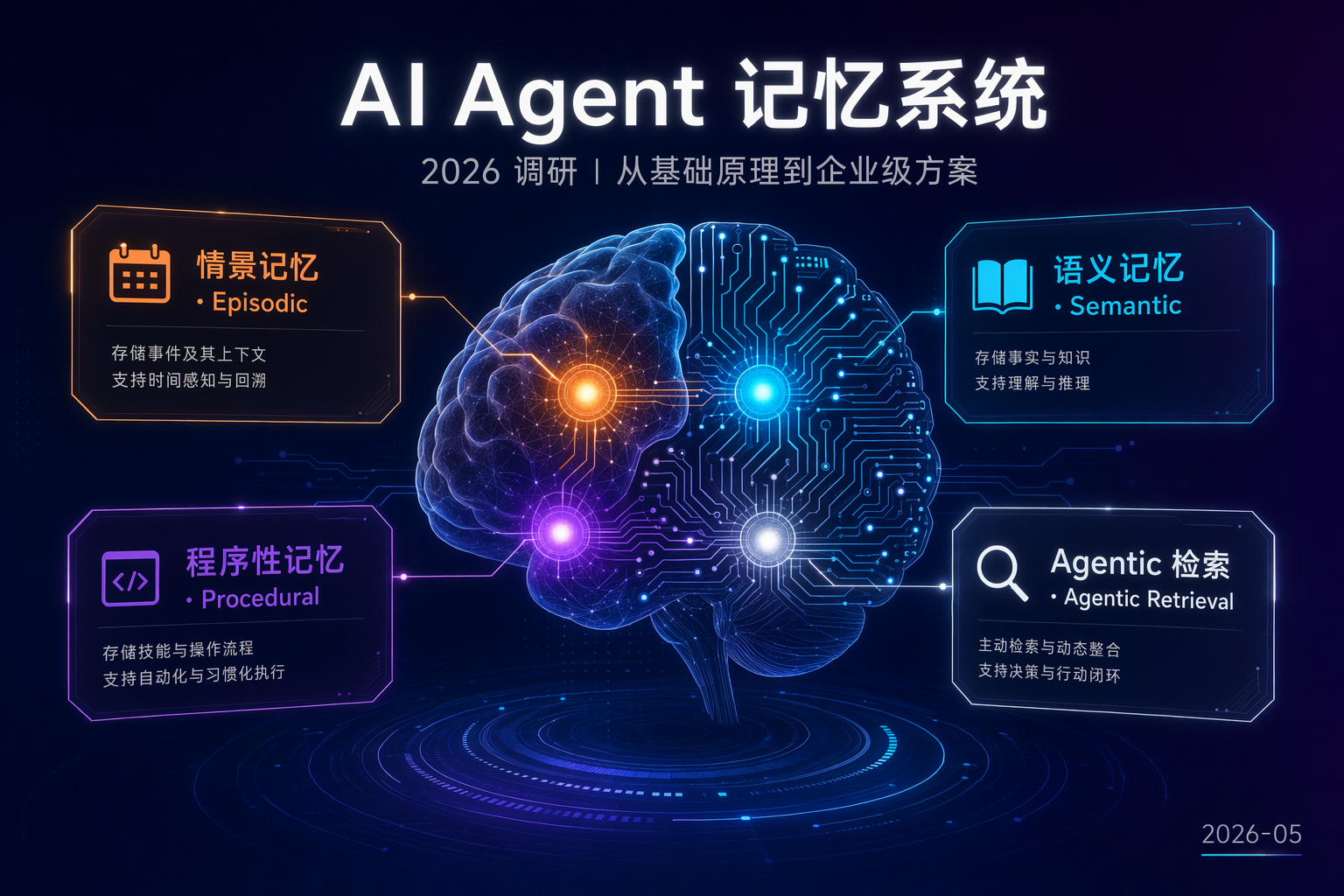
它把 Agent 的记忆切成四类:
Working memory(工作记忆)
当前推理所需的上下文,类似 CPU 寄存器,主要对应单会话 prompt。
Episodic memory(情景记忆)
过去发生过什么,带时间戳的"经历"——“昨天下午你让我改过一个 Python 脚本”。
Semantic memory(语义记忆)
稳定的、去时间化的事实——“你偏好 4 空格缩进”、“你的主仓库在 GitLab 自建实例上”。
Procedural memory(程序性记忆)
怎么做事的技能——如何调 CI、如何发版、如何检索代码库。
这个四分法成了后续研究的通用词汇,Letta、Zep、MemoryOS、Google 白皮书都直接引用或对齐。
2.2 Google 白皮书二分法:工程化压缩
Google “Context Engineering: Sessions, Memory” 白皮书于 2025-11 作为 AI Agents Intensive Course Day 3 发布,70+ 页,作者是 Antonio Gulli、Kimberly Milam 等 Google ADK 团队成员,PDF 可在 https://smallake.kr/wp-content/uploads/2025/12/Context-Engineering_-Sessions-Memory.pdf 下载。
它的定位是工程化视角,把 CoALA 四分压成了工程上更好落地的两分:
- Session: 短期对话 + 工作内存,对应 Working Memory 和 Episodic 的近端部分,工程上包含
events_compaction_config、session-level compaction 等机制。 - Memory: 跨会话的持久记忆,又内部切分:
- Declarative(knowing what): 包含 Semantic + 较远的 Episodic
- Procedural(knowing how): 对应 CoALA 的 Procedural
工程上,Google 把 Memory Manager 设计成解耦的独立服务,和 session 运行时分离。
CoALA 是学术词汇,Google 是工程落地。你在不同材料里看到两套说法时,记住它们是同一棵树:CoALA 给出四片叶子,Google 把叶子粘成两束,本质没变。
2.3 三种操作:抽取 / 更新 / 检索
记忆的分类只是静态视角。要让系统真正"活着",任何记忆系统都必须支持三件事:
- 抽取(Extraction): 从对话流里识别出值得记住的东西,并写到合适的分类里。可以是规则触发(上下文压缩前、/new /reset 命令)、可以是显式命令(用户说"记住这件事")、也可以是 Agent 自主判断。
- 更新(Update): 旧事实过时了怎么办?冲突怎么处理?用户说"我换工作了",旧的公司信息要怎样平滑过渡到新的?这是记忆系统里最难的一环。
- 检索(Retrieval): 推理时把相关记忆拉回 prompt 里。方式很多:关键词 BM25、向量相似度、混合检索、Reciprocal Rank Fusion 重排、甚至 LLM 主导的 agentic retrieval。
心智模型: 看任何一个记忆系统,只要回答两个问题——
- 记忆怎么分类? 每类存什么?
- 记忆怎么抽取/更新/检索?
把分类 × 操作两个维度搭成矩阵,你就可以快速看出一个方案的取舍在哪里。
三、OpenClaw 朴素方案:用 Markdown 记笔记
先从最简单的一档看起,它能让你把上面那个矩阵立刻跑一遍。
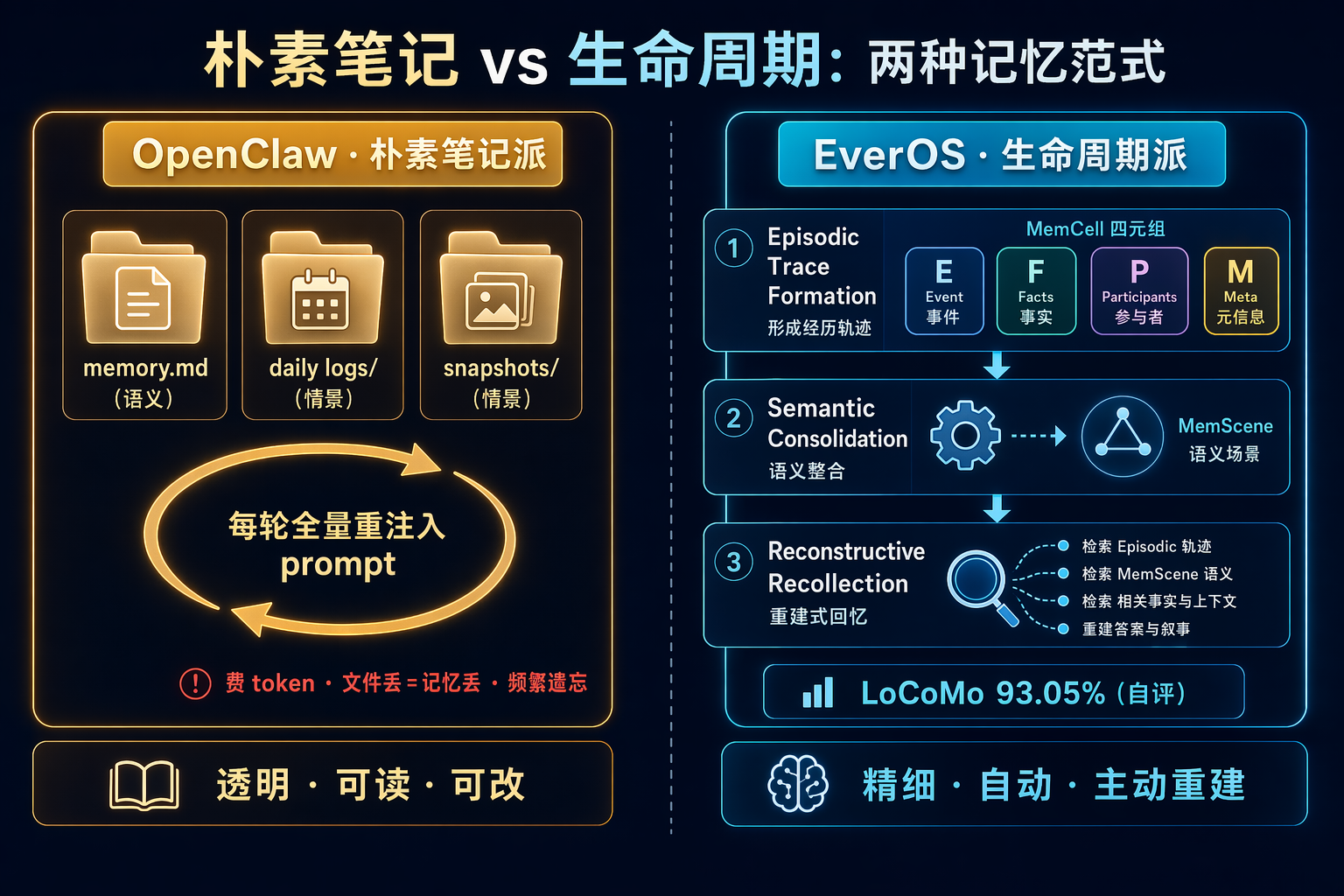
OpenClaw 是一个 CLI AI Agent,其记忆系统被 velvetshark 写成了一篇非常细致的 “Memory Masterclass”(https://velvetshark.com/openclaw-memory-masterclass)。它的整体设计非常符合 CoALA 的语义:
3.1 三类记忆文件
~/.openclaw/workspace/
├── MEMORY.md # 语义记忆:身份、偏好、稳定事实(约 20K 字符)
├── memory/2026-05-13.md # 情景记忆-每日日志,按天组织,只加不删
├── memory/2026-05-12.md
├── memory/snapshots/... # 情景记忆-会话快照,/new /reset 触发
└── DREAMS.md # 开放脑暴区
所有记忆都是人类可读的 Markdown。你可以 cat、可以 git commit、可以手工编辑。没有黑盒。
3.2 抽取触发点
OpenClaw 的写入时机非常明确:
- 对话即将压缩时 → 沉淀为当天的每日日志。
/new或/reset命令 → 生成会话快照,总结最后约 15 条有意义的消息。- 用户明确要求"记住这件事" → 直接写入
MEMORY.md。
这比完全自动化的方案更透明,也更可控——但代价是遗漏。
3.3 检索机制
- 启动时自动注入: 每个新会话开始,
MEMORY.md+ 今天/昨天的每日日志会被直接拼到系统 prompt 里。 - 按需召回: Agent 发现缺信息时,调
memory_search(关键词 + 向量融合,底层是 SQLite FTS5 + 向量索引)和memory_get。
3.4 它的硬伤
OpenClaw 官方文档自己承认的三个问题:
- 很费 Token: 每一轮都要把
MEMORY.md重新注入,长期用下来,20K 字符 × 每轮 = 20-30% 的 token 预算被记忆占掉。 - 丢了就是丢了: Markdown 文件如果没有 git 备份,手滑一删就永远找不回来。没有数据库层的保护。
- 经常遗忘东西: 抽取决策全靠 LLM 自己判断,判断错就漏记,而且没有事后回顾补救的机制。
3.5 OpenClaw 和 Hermes Agent 的关系
Hermes Agent(https://github.com/NousResearch/hermes-agent)是 OpenClaw 风格的一个"进化版",把记忆放到 ~/.hermes/memories/MEMORY.md(默认 2200 字符)+ USER.md(1375 字符),体量大幅收缩。
Hermes 的关键优化是冷冻快照 + 前缀缓存友好——session 启动时对记忆做一次冷冻,之后不再变动,配合 KV-cache 可以把重复注入的成本显著降下来。
Hermes 还提供 hermes claw migrate 命令,用于从 OpenClaw 工作区一键迁移到 Hermes 目录结构,方便已有用户切换。
根据社区统计,Hermes Agent 社区相当火热:
- Stars: ~79,900(2026-05-03)
- Commits: 4,095+
- 创建时间: 2025-07-22
- Release: 8 个
- 通讯平台: 15+(Telegram / Discord / Slack / WhatsApp / Signal / 飞书 / WeCom 等)
- 模型提供商: 10+(包括小米 MiMo)
- 子仓库: GitHub 上 68+ 相关仓库
四、CLI Agent 生态速览
OpenClaw 不是孤例。2025-2026 年是 CLI Agent 记忆机制集中化、标准化的一年。我们把主流 CLI Agent 的记忆机制并排列出来。
4.1 对比表
| CLI Agent | 记忆文件位置 | 是否自动累积 | 跨会话 | 特色 |
|---|---|---|---|---|
| Claude Code (Anthropic) | CLAUDE.md 四层(managed/user/project/local) + auto memory MEMORY.md(v2.1.59+) |
有,auto memory 默认开,前 200 行 / 25KB 入上下文 | 文件 + compact 重注入 | 外部 import 首次授权,managed 策略不可绕过 |
| Codex CLI (OpenAI) | AGENTS.md(沿 git 根 → cwd 叠加)+ ~/.codex/memories/ 自动 |
有,异步,闲置 ~6h 触发,两段式 LLM 挑 + 合并,30 天未召回淘汰 | 文件持久化 | 上限 32 KiB 硬截断;EEA/UK/CH 地域合规限制 |
| Cursor (Anysphere) | 旧 .cursorrules + 新 .cursor/rules/*.mdc + Memories(UI 管理) |
Memories 需用户批准入库 | 文件 + 云 | 社区反馈 Memories 作用域实现与文档描述不一致 |
| Gemini CLI (Google) | ~/.gemini/GEMINI.md + 项目 + 子目录层级 |
命令行 /memory add 和 save_memory 工具写入全局 |
文件 | 支持 @path.md import |
| OpenClaw | ~/.openclaw/workspace/ MEMORY.md + 日志 + 快照 + DREAMS.md |
压缩//new//reset 触发 |
文件 + SQLite FTS5 + 向量 | 每轮重注入,透明但 20-30% tokens 成本 |
| Hermes Agent | ~/.hermes/memories/MEMORY.md(2200)+ USER.md(1375) |
类似 OpenClaw 触发 | 冷冻快照 + session_search | 冷冻快照,前缀缓存友好;hermes claw migrate 可迁移 OpenClaw |
来源:
- Claude Code: https://code.claude.com/docs/en/memory
- Codex Best Practices: https://developers.openai.com/codex/learn/best-practices
- Cursor 讨论: https://forum.cursor.com/t/rules-vs-memories-and-global-vs-project/137149
- Gemini CLI: https://geminicli.com/docs/cli/tutorials/memory-management/
- OpenClaw Masterclass: https://velvetshark.com/openclaw-memory-masterclass
4.2 AGENTS.md:CLI Agent 的事实标准
主流 CLI Agent 在格式上已经悄悄收敛到一个开放标准:AGENTS.md。
- 托管: Linux Foundation 下的 Agentic AI Foundation
- 起源: OpenAI Codex、Amp、Google Jules、Cursor、Factory 联合发起
- 覆盖: 截至 2026-05,60,000+ 开源项目已采用
- 兼容工具(23 个): Codex、Jules、Factory、Aider、goose、opencode、Zed、Warp、VS Code、Devin、UiPath、Junie、Amp、Cursor、RooCode、Gemini CLI、Kilo Code、Phoenix、Semgrep、GitHub Copilot、Ona、Windsurf、Augment Code
- URL: https://agents.md/
这是一个重要信号:AGENTS.md 已经不再是某家 CLI 的私货,而是跨平台的 Agent “README”。你写一份 AGENTS.md,所有主流工具都能读。
另一个相关的开放标准是 agentskills.io,GitHub 上已有 31+ 仓库采用,从 Hermes 专属演变为跨平台 Skill 交换协议,兼容 Claude Code、GitHub Copilot、Codex CLI、Cursor、Gemini CLI 等 20+ 平台。
五、EverOS / EverMemOS:企业级记忆操作系统
CLI Agent 的朴素笔记派好处是透明,坏处是低效。往前一步,就出现了"操作系统级"的记忆方案。其中讨论度最高、数字最猛的是 EverOS。
5.1 背景
- 仓库: https://github.com/EverMind-AI/EverOS
- Stars: ~4.5K–4.7K(2026-05-13 实测,近期有小幅波动)+ 姊妹仓 MSA 3.4K
- License: Apache-2.0
- 语言: Python 94.4%
- 最近 commit: 2026-05-06
- 母公司: Shanda Group(盛大),陈天桥 1999 年创立;EverMind AI 注册在加州 SAN MATEO
- 已落地: Tanka(盛大自家 AI-native 消息 App)
- 2026 Q1 与 OpenAI 合办 Memory Genesis Competition,奖金 $80K+
陈天桥本人对这个方向的定位很直白:
“Memory will become the core competitiveness and turning point for future AI apps and is also the key for AI to evolve from a ‘tool’ to an ‘intelligent agent’ and from passive response to proactive evolution.”
—— 陈天桥微信视频号, 2025-11-17
5.2 论文三件套
- EverMemOS: arXiv:2601.02163(2026-01-05),“Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning”,11 位作者,包括 Chuanrui Hu、Xingze Gao、Lidong Bing、Yafeng Deng 等(https://arxiv.org/abs/2601.02163)
- HyperMem: arXiv:2604.08256,超图三层记忆架构(https://arxiv.org/abs/2604.08256)
- EverMemBench: arXiv:2602.01313,自研多方协作对话评测基准(https://arxiv.org/abs/2602.01313)
论文的一句核心 thesis:
“structured memory organization than on brute-force context expansion”
—— 与其野蛮扩上下文,不如结构化组织记忆。这也是 EverOS 整套设计的出发点。
5.3 记忆分类:4 种 + 2 种的"6 种说法"
论文权威定义 4 种 memory types:
| Type | 含义 |
|---|---|
episodic_memory |
事件和对话的叙述性记忆(Episode) |
event_log |
从情景中抽取的原子事实(EventLog) |
foresight |
带有效时间区间 [tstart, tend] 的预测性记忆(Foresight) |
profile |
渐进构建的用户画像(Stable Traits + Temporary States) |
附加记忆(非论文权威,但官方 blog 提及):
- Cases: Agent trajectory 记录
- Skills: 反复模式蒸馏而来的可复用技能
因此你会看到一些社区文档/第三方博客说 EverOS 有"6 种记忆"——这个说法来自 blog 而非论文。严格来说是 4 种 memory types + Cases + Skills 两类额外实体,引用时要注明差异,以免误导。
5.4 MemCell:所有记忆的原子单元
EverMemOS 把所有记忆统一封装成一个四元组:
MemCell = (E, F, P, M)
Episode, atomic Facts, foresight Predictions, Metadata
也就是说,一个"情景"不是孤立的文本,而是伴随着:
- E: 事件本身(谁、什么时候、发生了什么)
- F: 从事件抽取的原子事实(可单独检索、可与其他事实 join)
- P: 对未来的预测(比如"用户说下周要发版",就是一个 foresight)
- M: 元数据(时间戳、会话 ID、来源、置信度等)
这个结构让记忆本身就是一个微型知识图谱的节点,为后续的合并、冲突检测、时序查询打好底子。
小结:从 5.1 背景到 5.4 的 MemCell 四元组,我们看到了 EverOS 区别于朴素笔记的基石。接下来 5.5-5.7 展开的是动态流程与实测表现。
5.5 三阶段工作流
论文原话:
“Episodic Trace Formation converts dialogue streams into MemCells… Semantic Consolidation organizes MemCells into thematic MemScenes… Reconstructive Recollection performs MemScene-guided agentic retrieval to compose the necessary and sufficient context for downstream reasoning.”
翻译成工程语言就是三步:
- Episodic Trace Formation: 对话流 → MemCell。一边聊一边把每一段值得记的"情景"压成 MemCell。
- Semantic Consolidation: MemCell → MemScene(主题场景),并更新用户画像。多个相关 MemCell 被聚合为主题场景,矛盾在此阶段被识别和解决。
- Reconstructive Recollection: MemScene 引导的 agentic 检索,主动重建上下文。推理时不是"拉一堆相关文档回来",而是 LLM 主导地、多轮地重新构造出"当前任务最需要的上下文"。
举个 Semantic Consolidation 的例子:用户昨天说"我每天跑步 5 公里",今天说"我这周开始改成游泳,每周三次"——系统需要在 MemScene 这一层知道这是"运动偏好"这个主题的状态变更,而不是两条互相冲突的原子事实并置。
5.6 5 种检索模式(EverMemOS 官方 SDK 文档定义,注意与一些二手资料里的 4 种说法不同)
来源: OpenClaw EverMemOS Plugin 文档
| 模式 | 说明 |
|---|---|
| keyword | BM25 精确匹配 |
| vector | 语义向量相似度 |
| hybrid | keyword + vector 组合 |
| rrf | Reciprocal Rank Fusion 重排 |
| agentic | LLM-guided 反复搜索 |
注意:一些二手介绍里会说"4 种检索模式",实际以 5 种为准。
5.7 LoCoMo 上的成绩
在 GPT-4.1-mini backbone 下,EverMemOS 论文 Table 1:
| 系统 | Single Hop | Multi Hop | Temporal | Open Domain | Overall | Avg Tokens |
|---|---|---|---|---|---|---|
| MemoryOS | 67.30 | 59.34 | 42.26 | 59.03 | 60.11 | 5.5k |
| Mem0 | 68.97 | 61.70 | 58.26 | 50.00 | 64.20 | 1.0k |
| MemU | 74.91 | 72.34 | 43.61 | 54.17 | 66.67 | 4.0k |
| MemOS | 85.37 | 79.43 | 75.08 | 64.58 | 80.76 | 2.5k |
| Zep | 90.84 | 81.91 | 77.26 | 75.00 | 85.22 | 1.4k |
| EverMemOS | 96.67 | 91.84 | 89.72 | 76.04 | 93.05 | 2.3k |
超 Zep +7.83 pts,超 Mem0 +28.85 pts。
LongMemEval-S: EverOS 83.00% / Zep 63.8% / Mem0 49.0%(来自 evermind.ai 博客)
⚠️ 重要说明: 上述分数均为自评数据,尚无第三方复现。下一节的 Benchmark 争议里我们会具体讨论这类数字该怎么看。
六、百家争鸣:主流方案横向对比
市场上记忆系统的玩家远不止 EverOS 一家。下面把 2026 年 5 月时点的主流选手一一过一遍。
6.1 Letta / MemGPT
- 论文: MemGPT, arXiv:2310.08560(https://arxiv.org/abs/2310.08560),Packer et al, UC Berkeley, 2023
- 商业化: Letta, Felicis 领投 $10M seed
- 核心理念: OS 虚拟内存思想,Core / Recall / Archival 三层 memory
- Agent 被暴露
memory_insert/memory_search等函数,自己决定什么时候换页 - GitHub: https://github.com/letta-ai/letta
- Stars: ~21K(2026-05-13), Apache 2.0
- 定价: Free / $20 / $200 / 自定义
- LoCoMo: 官方未公布,第三方估 ~83.2%
6.2 mem0
- 论文: arXiv:2504.19413(2025-04, ECAI 2025)
- 融资: YC + $24M Series A(2025-10)
- GitHub: https://github.com/mem0ai/mem0
- Stars: ~55.6K(2026-05-13,所有记忆系统里最高)
- 架构: Mem0(向量) + Mem0g(有向标记图)
- LoCoMo 自评: 论文初版 66.9%,2026 新算法对外声称提升至 ~91%,第三方复现 62.47%
- 定价: Free 1K/月 → Pro $249/mo(图功能需 Pro)
6.3 Zep / Graphiti
- 论文: arXiv:2501.13956(2025-01, https://arxiv.org/pdf/2501.13956)
- 创始: Daniel Chalef
- 核心: 时序知识图谱,bi-temporal(真实时间线 + 摄入时间线)
- 事实带
valid_from/valid_to/invalid_at窗口,是所有开源方案里时序语义最完整的之一 - 子图三层: episode / semantic entity / community
- 后端: Neo4j / FalkorDB / Kuzu
- Graphiti 开源: https://github.com/getzep/graphiti,Stars ~24K(2026-05-13); Zep Cloud 闭源
- LoCoMo 自评: 原论文最初报 84.4%,后修正为 75.14%;Mem0 复现仅 58.44%
- LongMemEval: 63.8%(GPT-4o),baseline +18.5%,延迟 -90%
6.4 LangMem
- 发布: 2025-02,LangChain 官方出品
- GitHub: https://github.com/langchain-ai/langmem
- Stars: ~1.4K(2026-05-13), MIT
- 三类: semantic / procedural / episodic
- 运行时: Hot-path tools + 后台 memory manager
- LoCoMo 第三方测: 78.05%
6.5 Supermemory
- 融资: $3M(2025-10)
- 闭源 API-first,含 SuperRAG + 图谱
- LongMemEval ~70%
- 定价: Free / Pro $19 / Scale $399
- 客户: Cluely、Nissan、Composio
6.6 Memori
- 白皮书: arXiv:2603.19935(2026-03, https://arxiv.org/abs/2603.19935)
- 结构化: semantic triples + session summaries
- LoCoMo 自评: 81.95%(无第三方复现)
- Token 成本: full-context 的 4.98%
- 文档: https://memorilabs.ai/docs/memori-cloud/benchmark/results/
6.7 其他值得一提
- MemOS (MemTensor): 开源自演化 OS, OpenClaw 插件,LoCoMo 80.76(论文测)/ 75.80(自测),LongMemEval baseline +40.43%
- MemU (NevaMind-AI): 文件系统式分层记忆,PostgreSQL / in-memory,LoCoMo 自报 92.09%(自评,无第三方复现)
- MemoryOS (EMNLP 2025): OS 段页式分层 + 热度驱动淘汰
- Honcho (Plastic Labs): Hermes 集成的辩证式用户建模,正题/反题/合题
6.8 能力矩阵(心智对齐)
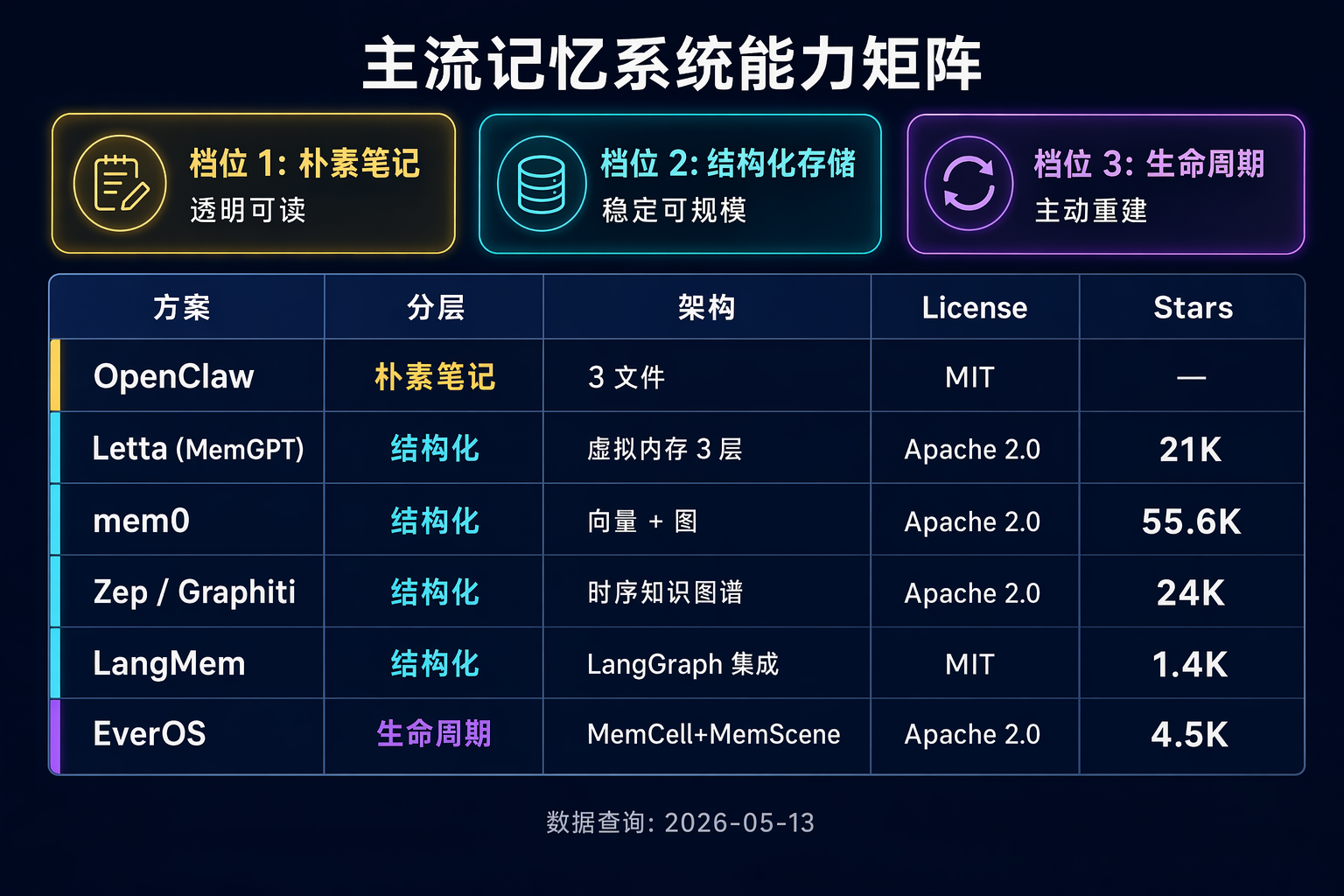
把上面这些玩家压到一张矩阵里,你会看到三档:
| 分层 | 代表 | 设计哲学 | 优点 | 代价 |
|---|---|---|---|---|
| 朴素笔记派 | OpenClaw / Hermes / Claude Code / Codex / Cursor / Gemini | Markdown 文件 + 手动/半自动抽取 | 透明、可 git、零基础设施 | 费 token、易丢、容易忘 |
| 结构化存储派 | Letta / Mem0 / Zep / LangMem | 向量 / 图 / 分层 DB,半自动抽取 | 稳定、可查询、便宜 | 碎片化、冲突处理靠人调 |
| 生命周期派 | EverOS / MemoryOS / MemU | MemCell 四元组 + MemScene + 主动重建 | 精细、自演化 | 复杂、自评数据、黑盒风险 |
不是"谁更好",是"匹配不同场景"。
七、Benchmark 争议:数字为什么靠不住
上面一堆数字看着清爽,实际上 2025-2026 年的记忆系统 benchmark 吵得很凶。
7.1 LoCoMo 是什么
- 全称: Long-term Conversational Memory(不是 “Long Conversation Memory”)
- 论文: arXiv:2402.17753(2024-02, https://arxiv.org/abs/2402.17753)
- 机构: Snap Research(Snapchat 母公司)
- 会议: ACL 2024 长文
- 项目主页: https://snap-research.github.io/locomo/
- 代码: https://github.com/snap-research/locomo - 821 stars
- 数据规模: 50 对话,每对话平均 300 turns / ~9K tokens / 最多 35 sessions
- 任务: QA(Single-hop / Multi-hop / Temporal / Open-domain / Adversarial)+ 事件图摘要 + 多模态对话
- 指标: F1-score(QA) + MM-Relevance(多模态)
理论上它是评测"长期对话记忆"最权威的公共 benchmark。实际上,大家的 LoCoMo 分数都是自评。
7.2 Zep vs mem0 的互怼实录
回合一:mem0 论文(2025-04)
- 宣称: Zep 拿 65.99%,Mem0 66.9%,Mem0 胜。
回合二:Zep 反驳(2025)
- Zep 发博客 “Lies, Damn Lies, and Statistics…”(https://blog.getzep.com/lies-damn-lies-statistics-is-mem0-really-sota-in-agent-memory/)。
- 指控: mem0 实验里错用
role_type="user"给对话双方,导致 user graph 崩坏。 - Zep 用正确实现应为 75.14%(原文最初错报 84.4%,后修正)。
回合三:mem0 再反驳(GitHub Issue)
- https://github.com/getzep/zep-papers/issues/5
- 声明: 完全遵照 Zep 官方 DMR 示例实现。
- 重新评估 Zep 只有 58.44%。
一眼结论: 两家自报的 LoCoMo 分数差距完全可以被实现细节颠倒——这不是 SOTA 之争,是 benchmark 设计之争。
中立第三方(Atlan)评价:
“both claiming SOTA, both questioning each other’s methodology — signaling that evaluation methodology itself is immature rather than a clear winner.”
—— atlan.com/know/zep-vs-mem0/
翻译: 两家都宣称 SOTA,都质疑对方方法论,这个信号更像是评估方法论本身不成熟,而不是有个明确的赢家。
7.3 数字可信度清单
| 系统 | 声称 LoCoMo | 第三方复现 | 备注 |
|---|---|---|---|
| EverMemOS | 92.3% / 93.05% | 无 | 自评,尚无第三方复现 |
| Mem0 | 67% → 91.6% | 62.47% | 自评,有争议 |
| Zep | 75.14% → 58.44% | 双向自评 | 看谁家的实现 |
| Letta | — | ~83.2% | 官方未公布 |
| MemoryOS (EverMemOS 论文复现) | 60.11 | — | 论文自评 |
| MemOS | 80.76 / 75.80 | — | 自评 |
| MemU | 92.09% | — | 自评 |
| Memori | 81.95% | — | 自评 |
| LangMem | — | 78.05% | — |
EverMemOS 的挑战: 目前仅有论文自评数据,论文发表 4 个月内尚无独立团队复现,企业用户在生产环境前务必用自己业务数据 POC 重测。自评 93.05% 的绝对值虽高,但只能作为"量级信号"而非"选型终点"。
还需警觉的是:EverMemBench(arXiv:2602.01313)由 EverOS 同一团队自研,自报 SOTA 的同时掌握测试集设计权。benchmark 的独立性问题比"谁跑分高"更值得警惕。
7.4 实用建议
不要把 LoCoMo / LongMemEval 分数直接拿来选型。建议:
- 把 benchmark 分数当作方向性信号——“上了 80% 的大概都在一个量级”,细差异不必纠结。
- 用自己业务数据重测。准备 50-200 条真实对话,做 memory write + query 的 end-to-end eval,这比任何公共榜单都说明问题。
- 关注延迟和 token 成本。Zep 宣称 LongMemEval 延迟 -90%,Memori 宣称 token 成本 4.98%——这些数字更难作弊,信息量更大。
八、如何选型:5 个典型场景的判断
把分类(朴素笔记 / 结构化存储 / 生命周期)和操作(抽取 / 更新 / 检索)搭配到业务场景上,常见选型如下。
场景 A:个人 CLI 开发助手(Claude Code / Codex 生态)
推荐: 直接用 Agent 自带的 AGENTS.md / CLAUDE.md 机制,按四层优先级组织(managed / user / project / local)。
理由: 文件可 git,透明可审计,token 成本可控(< 32 KiB 截断)。别给单机 CLI 引入向量数据库,边际收益低。
场景 B:单人长期陪伴型 Chatbot(心理/情感/教育)
推荐: Mem0 Pro 或 Supermemory Pro,或自建 LangMem。
理由: 需要长期稳定的"画像 + 情感上下文",结构化存储派够用。Mem0g 的图功能在"人际关系链"这种任务上有差异化。
场景 C:企业级多租户 SaaS 助手(CRM / 客服)
推荐: Zep 或 Letta 自建。
理由: 时序非常关键(订单状态、合同有效期),Zep 的 bi-temporal 设计正好对上;合规和租户隔离需求下,Letta 的 OS 思想 + 开源可自部署是硬优势。EverOS 也值得跟进,但因为自评数据未复现,建议先做 POC 再决定。
场景 D:多方协作 / 多 Agent 编排(含 Tanka 这类 IM 场景)
推荐: EverOS / EverMemOS,配合 EverMemBench 评测。
理由: 这正是 EverOS 的 sweet spot——多方对话会产生相互冲突的事实和预测(A 说周三发版、B 说周四),MemCell 的 foresight 带时间区间 + Semantic Consolidation 阶段的矛盾识别正好对上。这是结构化存储派做不到的。如果你做的就是 AI-native 消息类产品,EverOS 是目前架构最成型的选手,尽管数字需要自测验证。
已知风险: EverOS 的 93.05% 为论文自评,尚无第三方复现,生产前建议用自己业务数据 POC 重测。
场景 E:Agent 框架研究 / 教学
推荐: OpenClaw + MemoryOS + LangMem 对比跑。
理由: OpenClaw 让你看清"记忆系统的最朴素形态是什么",MemoryOS 让你理解段页式 + 热度淘汰,LangMem 让你看清 LangChain 生态怎么跟 Memory Manager 解耦。三者合起来是一套极好的入门教学组合。
决策速查表
需求 → 推荐方案
透明 / 可 git / CLI 场景 → OpenClaw / Claude Code / Codex (AGENTS.md)
个人长期陪伴 / 简单 CRUD → Mem0 / Supermemory / LangMem
企业多租户 / 时序敏感 / 合规 → Zep / Letta
多方协作 / 自演化 / 前沿探索 → EverOS / MemoryOS
教学 / 研究 / 构建自己的记忆系统 → OpenClaw + MemoryOS + LangMem 混合研究
九、未来展望:从"记笔记"到"主动重建"
梳理完这些方案后,你能看到一条清晰的演进路径。
9.1 从被动到主动
OpenClaw 是"Agent 自己做笔记给自己看"。EverOS 是"记忆系统主动重建上下文给 Agent 看"。这两者差了一整层——前者的被动等同于 RAG,后者的主动接近于 Thinking-as-Retrieval。
未来的趋势几乎肯定是"主动重建"这条路。Reconstructive Recollection、Agentic Retrieval、MemScene-guided 查询——这些词汇会变成记忆系统的标配。
9.2 记忆 + 技能的联合进化
记忆不是终点。EverOS 的 Cases + Skills、LangMem 的 procedural 记忆、Hermes 生态的 agentskills.io 都在指向同一件事:记忆和技能应当联合进化。
- 记忆(Memory): 我知道什么。
- 技能(Skill): 我会做什么。
好的 Agent 系统,应当能从情景记忆中蒸馏出可复用的技能(procedural),从历史执行中提取出 Cases(经验)。这是一个"记忆 → 技能 → 执行 → 新记忆"的飞轮。
落地层面:在 EverOS 里体现为 Cases → Skills 的蒸馏管线;在 LangMem 里体现为 procedural memory 的 prompt 模板演化。但两者都需要批量历史数据作为冷启动,不是上线第一天就能跑的。
9.3 开放标准的汇流
- AGENTS.md: 23 个工具、60k+ 项目、Linux Foundation 托管。Agent 的 “README” 已经统一。
- agentskills.io: 20+ 平台采用,从 Hermes 专属演变为跨平台 Skill 交换协议。
- CoALA → Google 白皮书: 学术和工程的描述正在收敛。
这意味着未来几年,记忆系统的上下游接口会逐步标准化——Agent 侧读什么、写什么、以什么格式存,会变成工业界共识。真正的竞争会从"我用什么记忆架构"转移到"我对记忆内容的理解质量有多高"。
9.4 可迁移的心智模型(送给读者)
两个问题搞懂任何 Agent 记忆系统:
- 记忆怎么分类? 每类存什么?
- 记忆怎么抽取/更新/检索?
三层演进:
- OpenClaw: 朴素笔记 - 透明但低效
- 企业级(Letta / Zep / Mem0): 结构化存储 - 稳定但碎片
- EverOS 及未来: 生命周期 + 主动重建 - 精细但黑盒
不是"谁更好",是"匹配不同场景"。
当你面对任何新冒出来的 Memory 方案,拿这两个问题 + 三层演进套上去,十分钟内就能搞清楚它的位置和取舍。
示例: 用这两个问题分析 LangMem——分类是 semantic / procedural / episodic,抽取是 hot-path tools + 后台 memory manager,检索看底层向量存储配置。取舍:透明度高、生态粘 LangChain,深度场景可能不够用。
十、参考资料
理论基础
- CoALA: Sumers et al., “Cognitive Architectures for Language Agents”, arXiv:2309.02427, TMLR 2024, https://arxiv.org/abs/2309.02427
- Google 白皮书: Gulli, Milam et al., “Context Engineering: Sessions, Memory”, 2025-11, 70+ 页, https://smallake.kr/wp-content/uploads/2025/12/Context-Engineering_-Sessions-Memory.pdf
EverOS / EverMemOS
- 仓库: https://github.com/EverMind-AI/EverOS
- 论文 EverMemOS: https://arxiv.org/abs/2601.02163
- 博客: https://evermind.ai/blogs/a-unified-evaluation-framework-for-ai-memory-systems
- 官网: https://everos.evermind.ai
LoCoMo Benchmark
- 论文: https://arxiv.org/abs/2402.17753
- 主页: https://snap-research.github.io/locomo/
- 代码: https://github.com/snap-research/locomo
主流方案
- MemGPT: https://arxiv.org/abs/2310.08560
- Letta: https://github.com/letta-ai/letta
- mem0 论文: https://arxiv.org/abs/2504.19413
- mem0 GitHub: https://github.com/mem0ai/mem0
- Zep 论文: https://arxiv.org/pdf/2501.13956
- Graphiti: https://github.com/getzep/graphiti
- LangMem: https://github.com/langchain-ai/langmem
- Memori Benchmark: https://memorilabs.ai/docs/memori-cloud/benchmark/results/
Benchmark 争议
- Zep 反驳博客: https://blog.getzep.com/lies-damn-lies-statistics-is-mem0-really-sota-in-agent-memory/
- mem0 在 Zep 仓库 Issue 的回应: https://github.com/getzep/zep-papers/issues/5
- Atlan 中立评: https://atlan.com/know/zep-vs-mem0/
CLI Agent 与标准
- Claude Code Memory: https://code.claude.com/docs/en/memory
- Codex Best Practices: https://developers.openai.com/codex/learn/best-practices
- Cursor Rules 讨论: https://forum.cursor.com/t/rules-vs-memories-and-global-vs-project/137149
- Gemini CLI 教程: https://geminicli.com/docs/cli/tutorials/memory-management/
- AGENTS.md 标准: https://agents.md/
- OpenClaw Memory Masterclass: https://velvetshark.com/openclaw-memory-masterclass
- Hermes Agent: https://github.com/NousResearch/hermes-agent
写在最后: 2026 年 5 月这个时间点,记忆系统领域处于"理论清晰、标准收敛、工程验证尚未到位"的阶段。benchmark 数字看看就好,真正的选型要回到你自己的业务场景和数据。这篇文章提供的不是一个排行榜,而是一副坐标系——让你在下一个新 Memory 方案出现时,十分钟就能把它放进去。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)