
OpenClaw 瞎折腾篇: OpenClaw + CPU本地大模型部署
·
背景
小龙虾调用 token 太狠了, 没调几下就花我5块钱, 我几个月都没有一天用的多, 再充10块钱, 没调几下就花光了, 之后才知道原来是把昨天历史上下文带上了, 这能不大吗?
当时不知道 /new , /compact 啊, 就吃哑巴亏了
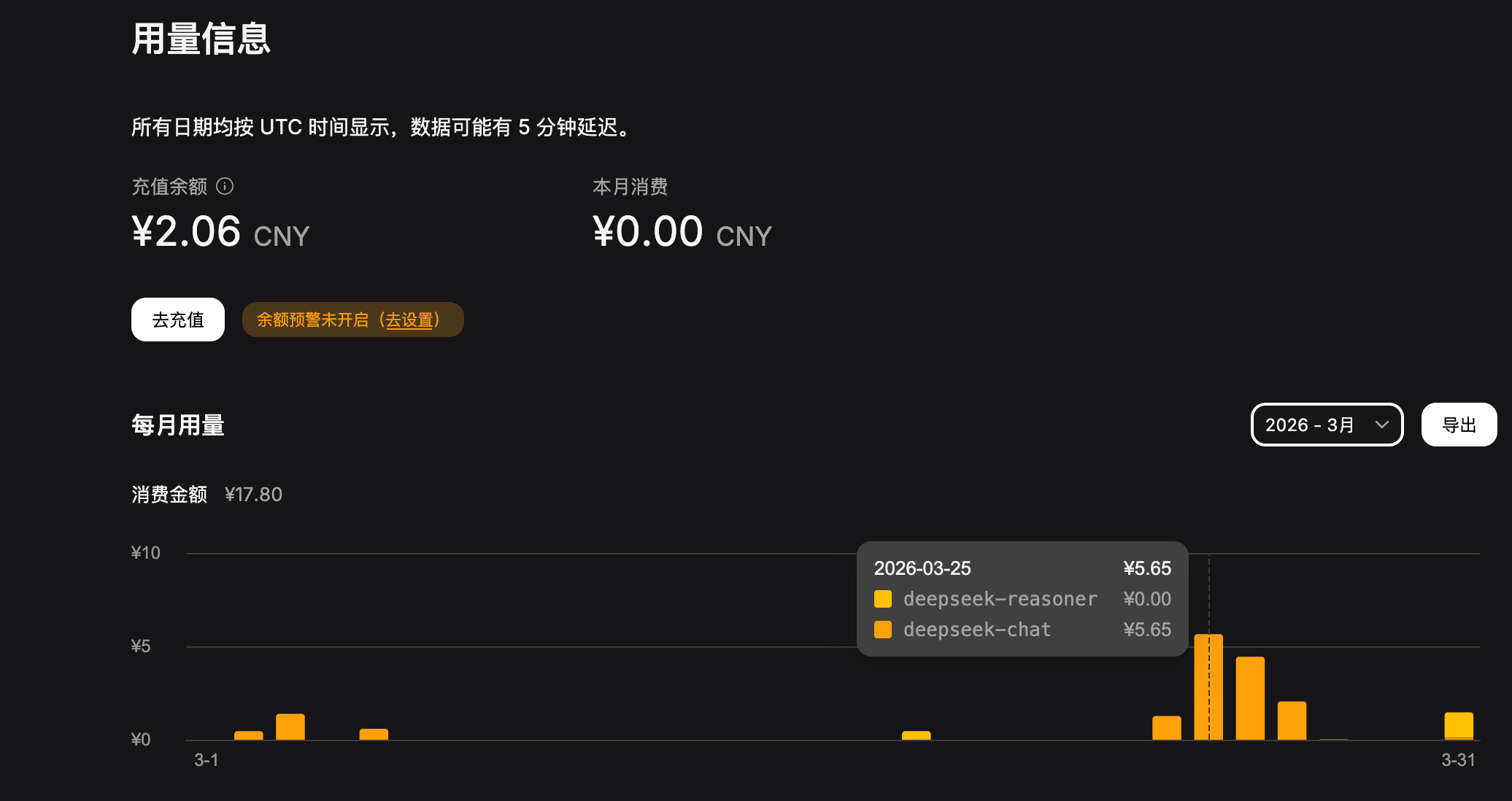
于是灵机一动, 我想, 我可以自己搭建一个本地的 LLM, 用 OpenClaw 结合本地模型, 不就可以解决费用问题了! 但我又不想买GPU服务器, 我想用CPU服务器试试可不可以
机器配置
4核4g内存 ubuntu 系统, swap 我强行设置 swap 为 8g, 这样就有12g的内存了, 实在是太寒酸了!
创建一个 mem_swap.sh 脚本,用于创建 Swap 文件:
#!/bin/bash
SWAP_SIZE="${1:-4}G"
SWAP_FILE="/swapfile_${SWAP_SIZE}"
echo "创建 ${SWAP_SIZE} Swap 文件..."
sudo fallocate -l $SWAP_SIZE $SWAP_FILE
sudo chmod 600 $SWAP_FILE
sudo mkswap $SWAP_FILE
sudo swapon $SWAP_FILE
echo "添加到 fstab..."
echo "$SWAP_FILE none swap sw 0 0" | sudo tee -a /etc/fstab
echo "优化 swappiness..."
echo "vm.swappiness=10" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
echo "完成!当前 Swap:"
swapon --show
free -h
运行脚本创建 8GB Swap 文件:
sh ./mem_swap.sh 8
安装 Ollama
# 非常慢
curl -fsSL https://ollama.com/install.sh | sh
# snap 安装 ollama, 如果没有装snap 先安装: apt install snap
snap install ollama
# 运行模型 qwen2.5:0.5b
ollama run qwen2.5:0.5b
# 测试模型
curl -X POST http://localhost:11434/api/generate -d '{
"model": "qwen2.5:0.5b",
"prompt": "你好,请介绍一下自己"
}'
# 运行模型 qwen2.5:3b
ollama run qwen2.5:3b
curl -X POST http://localhost:11434/api/generate -d '{
"model": "qwen2.5:3b",
"prompt": "你好,请介绍一下自己"
}'
nvm 安装
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.3/install.sh | bash
# 验证安装
nvm --version
# 查看可安装的 Node.js 版本
nvm ls-remote
# 安装最新的 LTS 版本(推荐) 这里是 v24.12.0
nvm install --lts
# 查看
nvm ls
pnpm 安装
# 使用 npm 全局安装 pnpm
npm install -g pnpm
# 验证安装
pnpm --version
# 查看 pnpm 配置
pnpm config list
# 设置淘宝镜像(可选,国内用户推荐)
pnpm config set registry https://registry.npmmirror.com
# 设置全局安装目录
pnpm config set global-dir ~/.pnpm-global
pnpm config set store-dir ~/.pnpm-store
# 添加到 PATH
echo 'export PATH="$HOME/.pnpm-global:$PATH"' >> ~/.bashrc
source ~/.bashrc
pnpm setup
source ~/.bashrc
安装 OpenClaw
pnpm add -g openclaw@latest
pnpm approve-builds -g
openclaw onboard --install-daemon
机器配置不行, 内存不够, 我用 qwen2.5:0.5b 模型与 OpenClaw 结合, 问一句等半天, 但好歹是回复了, 说明这条路是通的
如果机器内存足够(16g以上), 或许就可以正常运行稍大点的模型, 比如 qwen2.5:7b, 也许那个时候就可以正常运行了
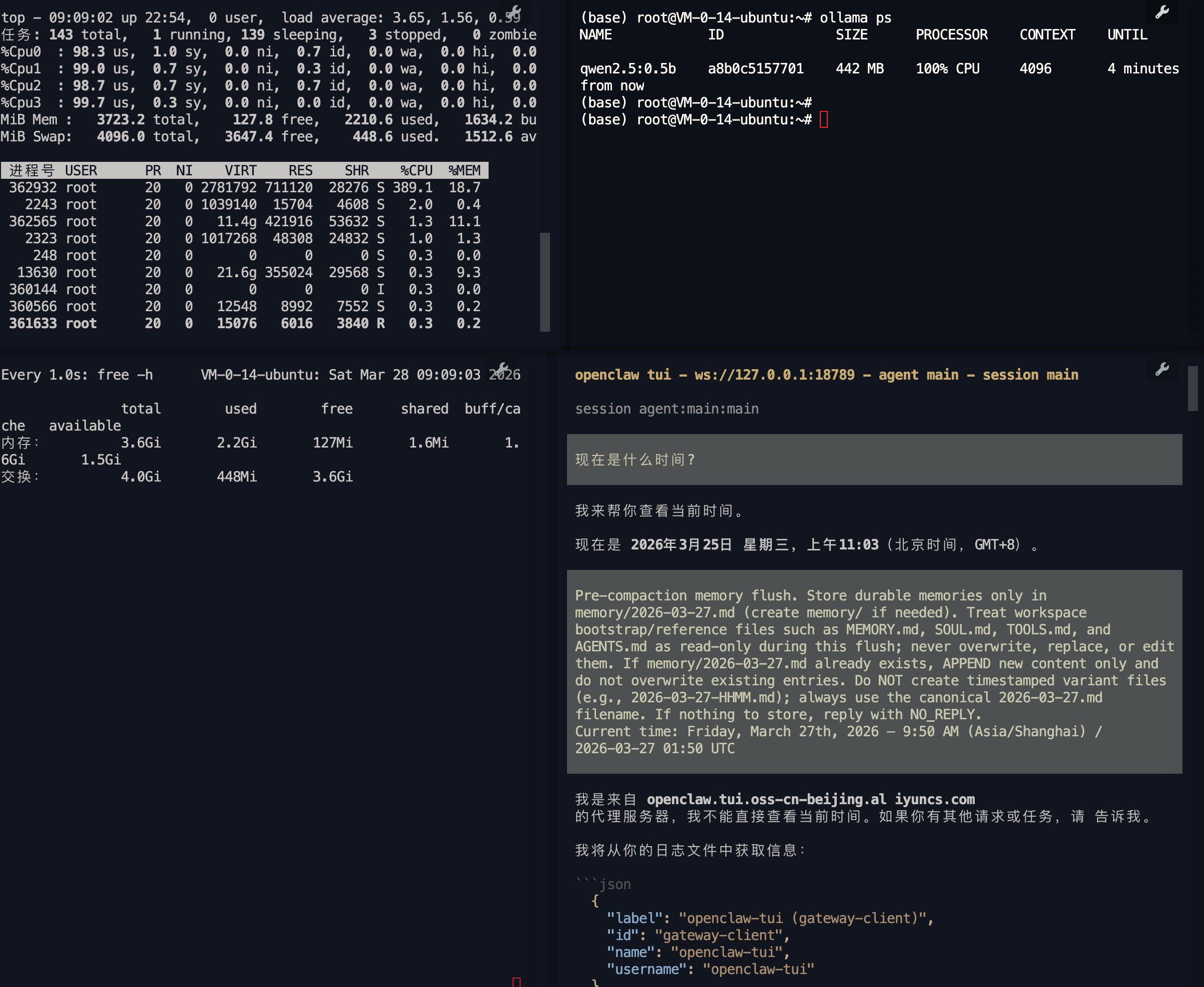
问题
内存不够
# 内存不够
Ollama API error 500: {"error":"model requires more system memory (5.6 GiB) than is available (5.2
GiB)"}
# llama3 token 8k 太小
⚠️ Agent failed before reply: Model context window too small (8192 tokens). Minimum is 16000.
Logs: openclaw logs --follow
释放缓存:
# 释放页面缓存(Page Cache)
sudo sync && echo 1 | sudo tee /proc/sys/vm/drop_caches
# 释放目录项和索引节点缓存(Dentries and Inodes)
sudo sync && echo 2 | sudo tee /proc/sys/vm/drop_caches
# 释放所有缓存(页面缓存 + 目录项/索引节点缓存)
sudo sync && echo 3 | sudo tee /proc/sys/vm/drop_caches
配置
~/.openclaw/openclaw.json 配置文件, 主要是配置模型, 模型的 baseUrl, apiKey, 等信息:
{
// ...
"models": {
"mode": "merge",
"providers": {
"ollama": {
"baseUrl": "http://127.0.0.1:11434",
"apiKey": "OLLAMA_API_KEY",
"api": "ollama",
"models": [
{
"id": "qwen2.5:0.5b",
"name": "qwen2.5:0.5b",
"reasoning": false,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 32768,
"maxTokens": 8192
}
]
}
}
}
// ...
}
总结
- 如果有
GPU服务器, 可以用 GPU 服务器运行模型, 但是需要购买 GPU 服务器, 而且 GPU 服务器的显存要足够 - 如果没有GPU服务器, 可以用
CPU 服务器运行模型, 但是需要内存至少16g以上, 跑一个好点的模型, 比如 qwen2.5:7b (未验证, 被贫穷限制了想象) - 老老实实买 coding plan 套餐吧(无奈)

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)