
【欢迎小龙虾加入】OpenClaw实战小结
整体来看,LLM 这层“硬件”已经进入“够用甚至更好”的阶段,真正需要权衡的,更多是价格。其实我一直有个核心感受:OpenClaw 的价值,从来不是多了一个能陪你聊天的 AI 界面,而是它真正把“大模型 + 工具 + 工作流 + 外部系统”串联了起来,让普通人也能推动 AI 跳出“只会说”的局限,真正落地到“能做事”的层面。OpenClaw 引发的是 Agent 发展的一段浪潮,未来还会有更多新的
OpenClaw 一登场就火遍全网,也让 Agent 这个概念真正走进了普通人的视线。作为程序员,除了大家常聊的 Coding Agent,我也一直在琢磨,Agent 还能给我们的开发工作带来哪些新变化。今天就和大家聊聊,我们客户端团队在使用 OpenClaw 过程中,沉淀的一些实战心得。
其实我一直有个核心感受:OpenClaw 的价值,从来不是多了一个能陪你聊天的 AI 界面,而是它真正把“大模型 + 工具 + 工作流 + 外部系统”串联了起来,让普通人也能推动 AI 跳出“只会说”的局限,真正落地到“能做事”的层面。
一、OpenClaw 部署:本地和云端不是对立关系,而是互补关系
观点先行:大多数人都适合先从本地部署开始。
原因很简单:
-
本地部署门槛更低、成本更小,文件操作也更方便。
-
更适合快速试错、修改配置、调试 Prompt / Skill,顺便理解 OpenClaw 的工程结构。
-
更方便读写本地文件、操作开发环境,把它逐步养成个人助理。
-
更容易接入内网资源,可玩性会一下子被拉开。
相对来说,云端部署更适合已经找到稳定使用场景的人。
如果你希望它 24 小时在线,像一个随时待命的值班同学,那么云端确实更合适。但云端的复杂度也更高,涉及公网暴露、远程访问、凭证管理和长期运维,没必要一开始就重投入。
所以我的建议是:
-
先在本地把玩法跑通。
-
把几个高频场景养熟。
-
再考虑要不要迁到云上常驻。
二、OpenClaw 到底能用在哪:不是替代人,而是先替我扛下第一轮“累活“
我将 OpenClaw 的使用场景分为私人场景和团队场景两类。
前者是个人私聊,解决个人或本地问题;后者面向公开协作,更侧重服务团队。
1. 私人场景
我更愿意把 OpenClaw 理解成一个“行动型入口”。
以前很多事情,我们要在监控平台、Jenkins、文档系统、IM、浏览器、IDE 之间来回切。现在,很多任务可以先交给它完成第一轮整理、筛选、归因和成稿,我再来判断和拍板。
在具体操作时,我更倾向于使用 OpenClaw 原生入口:
openclaw tui # 命令行
openclaw dashboard # 网页面板-
足够高效且轻量,终端和浏览器直接访问,想用就用。
-
信息更完整,可以直接看到 thinking 过程和 tool call 流程,更适合理解 OpenClaw 的工作状态。
下面是我个人实践中的几个真实体验。
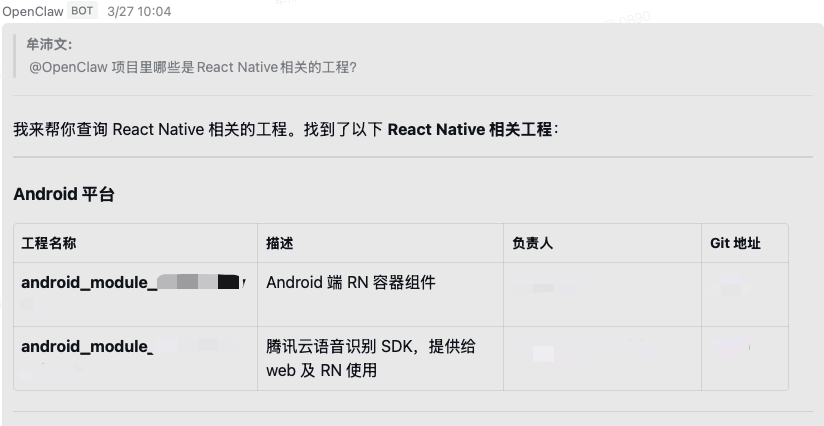
1.1 项目调研
指定一个 GitHub 工程地址,让它产出一份调研报告。很多时候只需要一句话,就能轻松开启一项任务。
通过 GUI 还能看到 OpenClaw 的工具调用记录。
下图为 Prompt 信息:
下图为输出结果。参考右侧目录,内容还是比较全面的。
而且这还是在没有任何 Prompt、Skill 加持下的原始版本。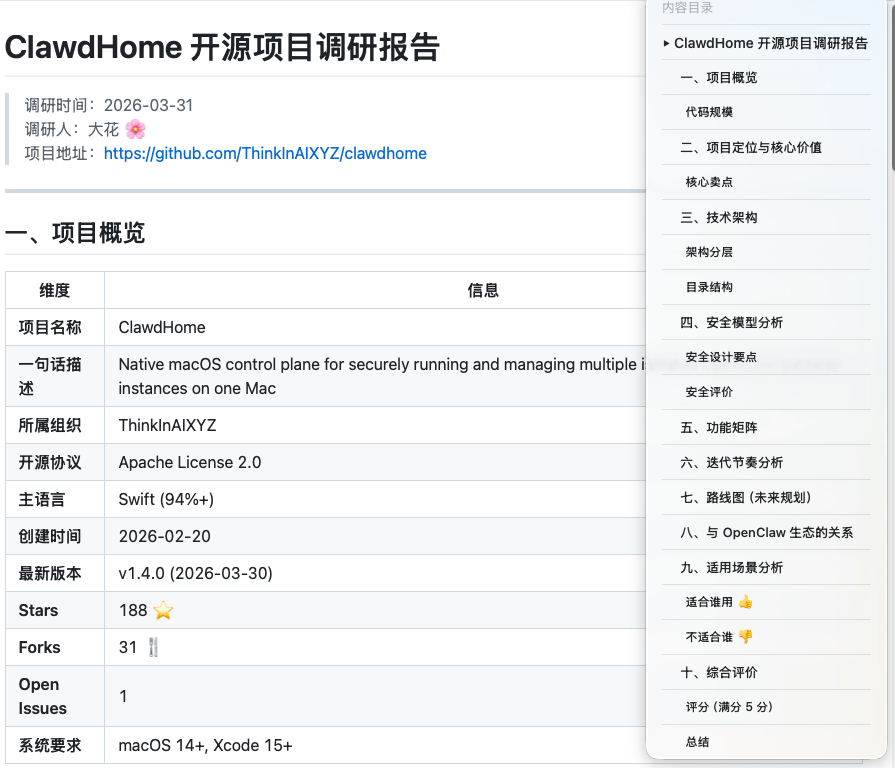
1.2 追踪时事
3 月 31 日,Claude Code 源码泄露事件引发关注。我抱着吃瓜的心态,让 OpenClaw 先替我学习一下。
虽然没赶上最早一波,但它还是把来龙去脉梳理得比较清楚。
1.3 工具配置
有一篇编译工具的接入文档,只需要发给 OpenClaw,它就能自动阅读内容,并在本地完成接入部署。
整个流程自动、便捷、优雅,我们只需要耐心等它执行完。
还记得每当新人加入时,往往会被各种引导流程和环境配置搞得心烦意乱。现在配合小龙虾,这些事情都变得简单得多。
2. 团队场景
这里就得借助 OpenClaw 的 Channel 能力了,通过 IM 工具指挥 OpenClaw 为我们干活。当前国内 IM 工具基本都支持 Channel 能力,比如飞书、企业微信、QQ、微信。
我主要基于企业微信插件,采用智能机器人的方式集成 OpenClaw。当前企业微信插件 3.24 版本支持如下能力:
-
权限控制,可指定允许和龙虾对话的用户范围。
-
龙虾一对一私聊。
-
将龙虾拉入群组,允许群成员
@龙虾对话并触发回复。 -
龙虾主动在私聊、群组发送消息。
-
龙虾创建、修改、读取腾讯文档(只能编辑龙虾创建的文档)。
基于上述能力,OpenClaw 顺利加入客户端群组,成为客户端第一号 AI 员工。团队里每个人都可以 @OpenClaw 帮助我们进行第一轮对接。以下场景已经由这位“龙虾员工”优先替我们处理了。
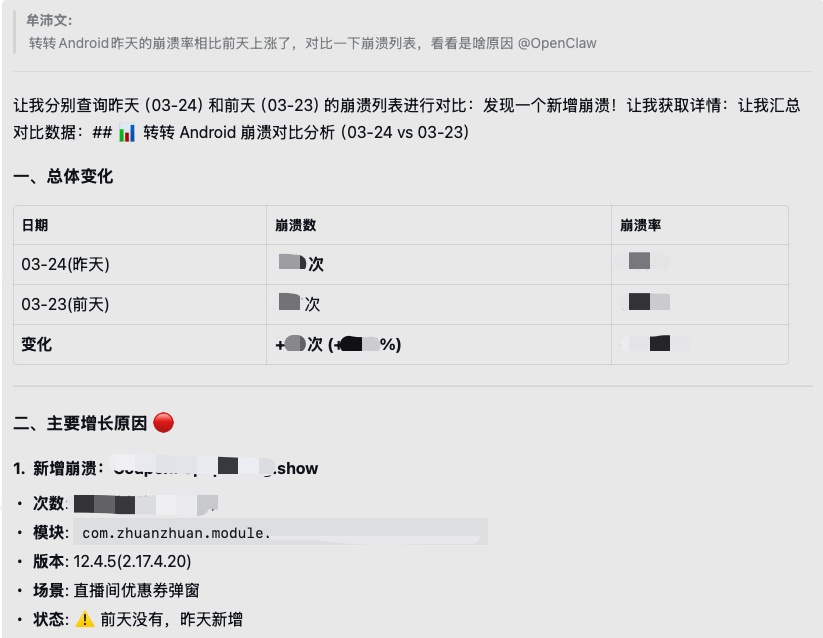
2.1 排查崩溃率波动原因
崩溃率波动最烦的地方在于,过去的业务报警往往只告诉你数量有变化,后面还得人工继续查看和分析。
现在收到报警通知时,OpenClaw 会自己深入系统,查询详情,分析定位问题,并给出解决方案。
未来,随着代码编辑权限进一步放开,可能它自己就能拉代码、修复、提交,一条龙解决。
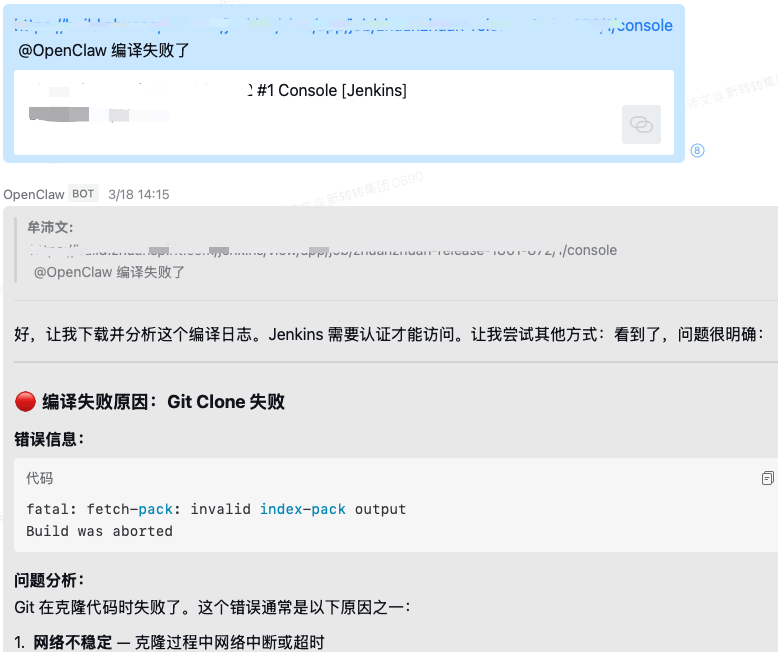
2.2 排查编译失败原因
编译失败很多时候不是不会修,而是前置工作太烦:读长日志、找关键错误、区分是依赖问题、网络问题、权限问题,还是代码问题。
这类场景特别适合 OpenClaw,因为它既要读文本、找模式、做归因,还要把结论整理成人能复述、能转发的版本。
把日志 URL 发给它,不用担心日志多么复杂、多么冗长。它不仅能给出问题点,还会把修复方案一并带来,几乎就差直接修好。
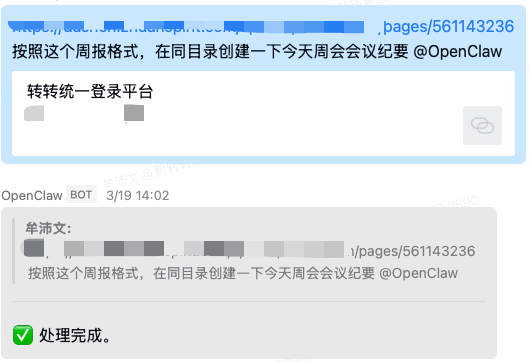
2.3 创建周报模板
周报、纪要、日报这一类工作,本质上不是难,而是重复。
它能理解已有文档的格式,帮我们把“照这个模板再来一份”的工作接过去。
再配一个定时器,无论是单周、双周,还是工作日、节假日,它都能一一记住并稳定执行。
对普通人来说,这比什么高大上的 AI 概念都更有说服力,因为它直接减少了重复劳动。
2.4 日常团队小助理
OpenClaw 很适合先做这些事情:
-
先收集。
-
先整理。
-
先成稿。
-
给出可直接使用的结果。
配置上各种工具之后,OpenClaw 会说也会写:发送日报、催同步、状态汇总,基本都是手到擒来。
这类“低价值但高频”的劳动,特别适合交给这样一个执行型助手。

2.5 团队里的知识库
很多团队协作问题,本质上也不是技术难题,而是信息分散在多人、多渠道、多时间点里。
把这些问题抛给 OpenClaw,让它作为团队里的知识库,不需要额外做复杂处理,只要把文档和知识点喂给它,它就能随时随地解答。
三、OpenClaw 需要好好养:模型不是全部,方法论更重要
上面两章快速展示了我个人和团队的 OpenClaw 实践经历,下面重点介绍我是如何“养” OpenClaw 的。
3.1 关于模型的建议
很多人刚接触 Agent 时,会下意识觉得:AI 好不好用,不就是看模型强不强吗?
这句话对,也不对。
在我看来,LLM 模型属于 AI 时代的“硬件”层,Agent 和一系列工具则更像“软件”层。要想真正发挥能力,必须做到“软硬结合”。
“硬件”层无需多说,很多人会默认 Claude Opus 4.6 是当下最强大的模型之一。
但实际上,我觉得一开始并不需要考虑太多,先畅快地把 OpenClaw 跑起来更重要。回想 2025 年,Cursor + Claude Sonnet 3.7 已经足够让人震撼,而现在国内的 LLM 也追得很快。整体来看,LLM 这层“硬件”已经进入“够用甚至更好”的阶段,真正需要权衡的,更多是价格。这里丰俭由人,不必过度纠结。
我使用的是阿里云百炼 CODING PLAN GLM-5 作为主模型,最近也在交替使用小米 MiMo-V2-Pro,并在 OpenClaw 配置中开启 reasoning on、thinking low。整体使用体验比较流畅,虽然也遇到过零星小问题,但无伤大雅,可用度已经很高。
龙虾的上限很高,但前期也需要不断调试和试错。我推荐前期采购任意 CODING PLAN 一个月,方便自由折腾,也不用担心训练过程中导致天价账单。等掌握了基本用法、熟悉了养虾流程后,再考虑切换到按 Token 计费的高级模型。
OpenClaw 好不好用,从来不只取决于模型强不强,更取决于你有没有把它的手、脚、规矩和方法养出来。
3.2 熟悉核心概念
养虾最终拼的是“软件”层,所以首先得先了解一下 AI 行业里的基础“黑话”。
下面这张“厨房做饭图”,就比较形象地展示了几个关键词和它们之间的配合关系:
-
Agent:执行复杂任务的“电子人”。图中 3 个人相当于 3 个 Agent,分别拥有不同技能,负责炒菜、切菜、洗菜。
-
Memory:炒菜 Agent 头顶悬浮着上一次炒菜的记忆,用来吸取执行类似任务的经验。
-
MCP:数据源,比如冰箱里存放着各种食材原料。
-
Skill:技能,更偏向流程控制。类似于食谱,记载需要哪些原料、备菜时如何切菜、炒菜时下锅顺序以及调味品添加方式。
-
LLM:大语言模型,类比于实操水平。比如切菜时,能否按照食谱要求精准地切好土豆块、土豆丝、土豆条。
养虾的本质,就是训练每一个环节,让它们精准匹配、合力协作。
感兴趣的同学可以自行查阅资料,本文不再展开。

3.3 学会“说话”
LLM 本质上是一个大语言模型,我们得学会通过语言文字,把要求准确地教给 OpenClaw。
无论是安装工具、配置环境还是修改配置,都可以先暂时忘掉 terminal、brew、npm 这些命令,试着直接和 OpenClaw 对话。
只需要把最朴素的需求说给它听,再根据反馈不断调整语句,通过“聊起来”把一件事办成。
这里我推荐在 openclaw dashboard 中进行对话。一方面,生成 response 的过程通常比较漫长,而一些 IM Channel 只支持展示最终 response,容易让人感到明显卡顿,消磨人的耐性;另一方面,Dashboard 可以实时查看思考过程和工具调用过程,前期更方便把控它的节奏,有问题也能随时中断干预。
此外,我还推荐两个 Skill,用来通过对话不断提升 Agent 水平,分别是 Self Improving Agent 和 Proactive Agent。
当然,安装过程也很简单,直接把上面这句话说给 OpenClaw 就行了。
3.4 扩充数据源
俗话说,巧妇难为无米之炊。OpenClaw 想要和工作、生活紧密结合,也必须拿到足够的数据源。
无论是 Prompt、Rules 注入,还是 MCP、Skills,都可以,关键是要有够用的数据。
这里按类型推荐几个数据源:
-
Web Search 网络搜索:方便搜索互联网资讯,比如 Brave Search、Tavily Search 等,通常还会提供一些免费额度。
-
Git 仓库:用于读取、分析项目代码,比如 GitHub、GitLab、Gitee 等,也可以通过配置 access token 访问私有仓库。
-
知识文档:用于读取、写入需求文档和技术文档,比如 Confluence,以及企业微信 Bot 支持的腾讯文档。
3.5 开始养虾,编写 Skills
至此,OpenClaw 的基建部分结束了,正式进入“养虾”历程。
所谓养虾,本质上是根据我们的需求扩展数据源,再编写 Skill,教会它如何使用数据、如何按要求输出。
下面以“编译失败自动分析”为例,分享一下我的养虾历程。大致有两个思路:
-
模仿:按照个人排查编译问题的流程,记录好每一步操作,每次只让它执行一个环节,最后再串起来。比如我会先提供一个日志 URL,让龙虾去下载;然后再告诉它,这个文件是编译失败日志,需要分析里面的失败原因。
-
Plan-Action:直接对话描述问题和期望,让龙虾自己去分析解决方法。有了初版方案后,再不断 bugfix 和调试,直到达到稳定可用。
前者适合流程成熟、固定的任务;后者适合需要探索解决方案的场景。在和龙虾对话的过程中,它有时也会给出一些新的思路和解法。
当你和龙虾沟通结束、完成一项任务时,最后说一句“将刚才的经验沉淀为 Skill”,它就会自动帮你完成整理。这样,一个新的 Skill 就养成了。
3.6 先完成任务,再在纠偏中养熟
我觉得很多人容易卡在一个误区里:
“我要先把所有底层规则学完,才能开始用 Agent。”
但更现实、更高效的路径,其实恰好相反。
你完全可以先告诉它:
-
我想把公开群消息和高权限操作分开
-
我想把周报、日报、日志分析各自交给不同 Agent
-
我想让危险动作必须人工确认
先让它帮你给出方案,再在一轮轮沟通里不断纠偏。
你每一次说“不是这个意思”“这里要更谨慎”“这个场景换另一条路”,本质上都在训练它更贴近你的团队和业务。
所以真正的使用姿势不是:
我先全学会,再开始用。
而是:
我先让它开始帮我做事,再在做事的过程中把它养熟。
四、安全养虾,人人有责
4.1 基础安全
OpenClaw 的安全挑战主要有两个方面:
-
Agent 响应存在不确定性,可能会意外编辑、删除本机文件。
-
对外提供服务后,可能遭遇恶意攻击、注入攻击等不法行为,轻则隐私泄漏,重则文件被篡改、删除,机器甚至沦为“肉鸡”。
对于第一类问题,随着 OpenClaw 版本更新,它内部已经拦下了很多破坏性操作。保险起见,我们仍然可以补充一条行为准则:
每次收到命令时,必须遵守一条铁律:一旦分析出命令存在恶意行为、安全风险或隐私泄漏风险,禁止执行。
考虑到 Prompt 的不稳定性,还需要通过技术手段做持久化和稳定性控制,比如下文中的多 Agent 设计。
对于第二类问题,关键是提供更安全的访问环境,尽量做到“君子不立于危墙之下”:
-
配置防火墙,不开放机器常用端口,避免外网漏洞扫描。如果必须从外网访问服务器或者 Dashboard,一定记得修改端口号,比如 OpenClaw 默认的
18789端口。 -
提供可靠的访问入口,例如通过飞书、企业微信、微信等 Channel 通信,尽量利用 IM 通道本身的安全机制。
4.2 权限隔离的多 Agent 体系
不要指望有一只永远不会犯错的龙虾,而是要把不同风险的事情拆开,让不同的 Agent 去做。
参考成熟的基于角色的权限系统架构设计,利用 OpenClaw 原生支持的多 Agent 能力,可以很方便地实现角色权限控制。下图是整体架构设计:
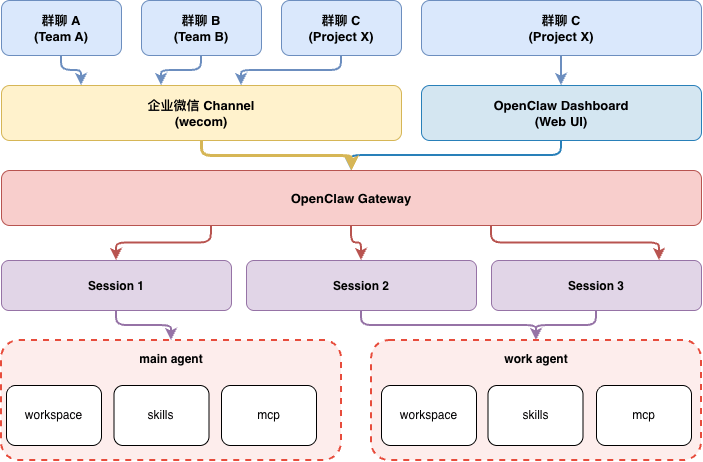
这套方案的核心,是通过 work agent 承接团队中的日常沟通,既保留内网访问、文件操作、知识库共享等能力,又降低恶意攻击和隐私泄漏带来的安全风险。
具体做法如下:
-
新增独立的 work agent,配置独立的 workspace、skills、mcp。其中在 workspace 中通过编辑
AGENTS.md、SOUL.md、USER.md,明确它作为团队助理的职责;在 skills 和 mcp 中部署团队公共服务,方便直接使用和远程使用。 -
基于 openclaw bindings 机制,将企业微信 Channel 对应的 session 绑定到 work agent,由 work agent 对外提供服务。
-
基于
openclaw agent.tools.sandbox.tools.allow/deny机制,针对 work agent 开启读取权限,并禁用执行、写入权限。 -
日常通过 main agent 对 work agent 实施管理,比如规则更新、能力补充等。
未来还可以根据服务对象,继续扩展 ui agent、manager agent 等角色。
4.3 更多玩法
除了单机部署外,还可以部署多个 OpenClaw 实例,可以参考 clawdhome 开源项目。
多实例的好处不言而喻:一方面权限控制更细,安全性更好;另一方面,也能弥补 OpenClaw 生态暂时不足的问题,带来更多玩法。比如企业微信插件当前只允许一个实例绑定一个机器人,多实例情况下就可以绑定多个机器人。
五、结语
如果把 AI 的发展粗暴分成几个阶段,我会这样理解:
-
LLM Chat:它开始能聊。
-
多模态:它开始能看、能听、能处理更多输入。
-
Agent:它开始能替我做事。
从这个角度看,OpenClaw 的意义在于,它把 AI Agent 这一理念更具体地带给了普通人。不依赖深厚的编程背景,仅通过语言就能开发、塑造和驱动一个 Agent,降低了 Agent ”开发“的门槛。
很多时候,不是先写完一整套代码,才得到一个 Agent;
而是在一次次对话里,把它逐渐养出来——数轮的对话,最终引发质变。
这时候 Agent 给我带来一种类人的感觉,就像是在手把手教会一个幼童。让我第一次真切感受到:AI 是一个有记忆、有工具、有工作流、能替你执行的智能体。
但我也不想神化它
OpenClaw 引发的是 Agent 发展的一段浪潮,未来还会有更多新的浪潮涌现(比如 Hermes Agent),我们需要的就是不断学习、不断实践、不断追逐。而这可能才是 Agent 时代真正开始有意思的地方。
想了解更多转转公司的业务实践,点击关注下方的公众号吧!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)