
OpenClaw专题
选 HTTP:├── RESTful API(增删改查)├── 偶尔的数据获取├── 需要缓存的静态/半静态数据└── 简单的表单提交选 WebSocket:├── 即时通讯(聊天、消息推送)├── 实时数据流(股票、游戏、监控大盘)├── 协作应用(多人编辑、白板)├── 物联网设备通信└── 需要服务器主动推送的任何场景选 SSE(折中方案):├── 只需要服务器→客户端的单向推送├── 新闻
OpenClaw的原理?
OpenClaw本质上是一个本地运行的多渠道AI网关(Multi-channel AI Gateway),它自己不做推理,只做调度和执行。把大模型的推理能力翻译成对操作系统、软件API、硬件设备的实际控制权。本质看做是AI的操作系统。
技术栈上,OpenClaw 用Node.js+TypeScript(ESM)实现,HTTP 服务直接基于Node原生的node:http模块(没有用Express/Koa),WebSocket做控制面实时通信。底层的Agent会话管理构建在pi-coding-agent SDK之上。
OpenClaw与 LangChain、AutoGPT 的核心定位差异是什么?
三者定位不同:应用层vs框架层vs研究原型。
理解OpenClaw,只需要抓住两个核心:架构和运行时机制(Agentic Loop+工具生态)。
架构上分两层:
- Gateway(网关层):统一的消息入口。把各平台千差万别的消息格式统一成OpenClaw内部的MsgContext
- Agent Runtime(运行时层):真正干活的地方。接收Gateway派发的消息,组装上下文、调用LLM、执行工具、返回结果。
OpenClaw 与传统的 Agent 有什么区别?
传统 AI Agent,本身就具备自主感知、任务规划、决策判断、工具调用的核心能力。它和纯对话式 AI 最核心的区别,就是能自主完成从需求到结果的任务闭环。
而 OpenClaw 和传统 Agent 的核心差异,本质是底层设计逻辑的完全不同。
第一点,运行模式不同——被动响应对比主动值守
第二点,权限边界不同——云端沙盒对比本地直连。
传统 Agent 活在云端的虚拟沙盒里,碰不到电脑里的真实文件。遇到需要落地的任务,它往往只能写段代码让你自己去跑。OpenClaw 本地优先,直接跑在设备上,拥有系统级最高读写权限。它能直接操作本地文件、执行终端命令、操控软件,把 AI 能力和你真实的工作环境彻底打通。
第三点,记忆机制不同云端黑盒对比本地透明。
传统 Agent 的记忆存在云端服务器,跨会话容易失忆,而且是个完全被厂商控制的黑盒,你插不上手。OpenClaw 的记忆则是保存在本地的纯文本 Markdown 文件里,全透明且全可控。它不仅永久保留你的偏好,你还能随时打开文件去修改、删减甚至做版本管理,越用越顺手。
第四点,产品定位不同——单一工具对比通用基建。
传统 Agent 多是针对特定场景设计的特定工具,比如专门写代码或者做数据分析,模型和交互方式都是定死的。而 OpenClaw 是一个通用的 AI 执行网关。大模型随你切换,交互入口直接对接到微信或飞书,能力全靠技能插件无限扩展,一套平台就能覆盖所有的 AI 执行需求。
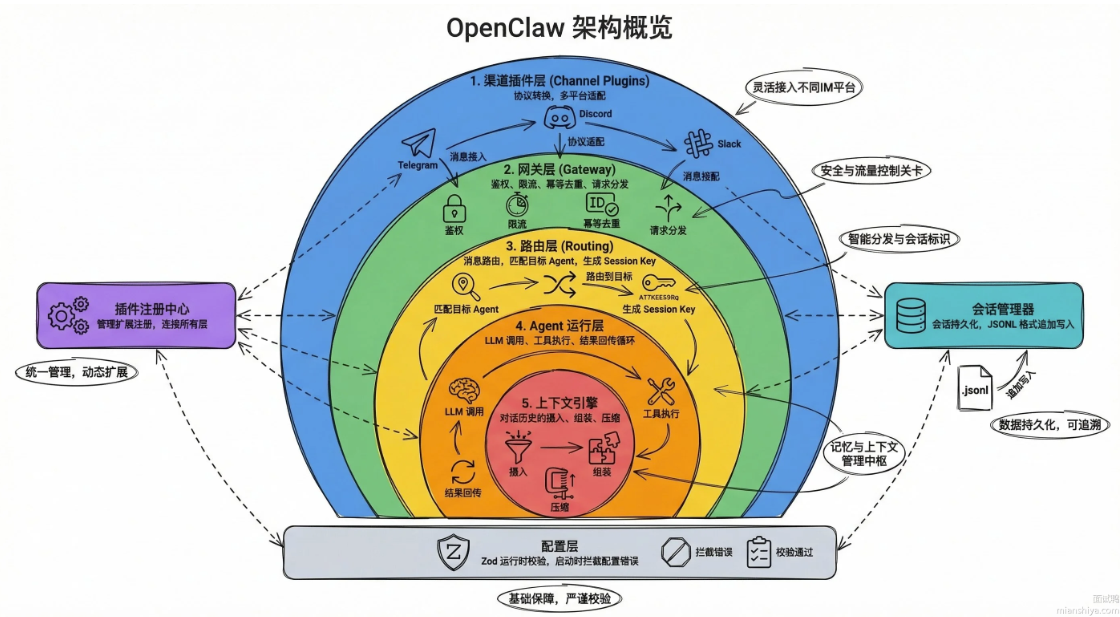
OpenClaw的核心组件
发生故障时分层检查10.1.2
Channel Plugins是最外层,每个消息平台一个插件,Telegram、Discord、Slack等各一套,干的活就是协议转换,把平台私有格式翻译成OpenClaw内部统一的消息结构。
Gateway是整个系统的中枢,所有请求都从这过。鉴权、限流、幂等去重并向下游分发请求
Routing是路由层,拿到消息后根据配置规则决定交给哪个Agent处理,同时生成SessionKey来追踪会话。
AgentRunner驱动LLM调用、工具执行与结果回传,一个Agent跑起来的所有脏活累活都在这。
ContextEngine管对话历史,摄入、组装、压缩全包了,接口化设计,随时可以插拔替换成自定义实现。
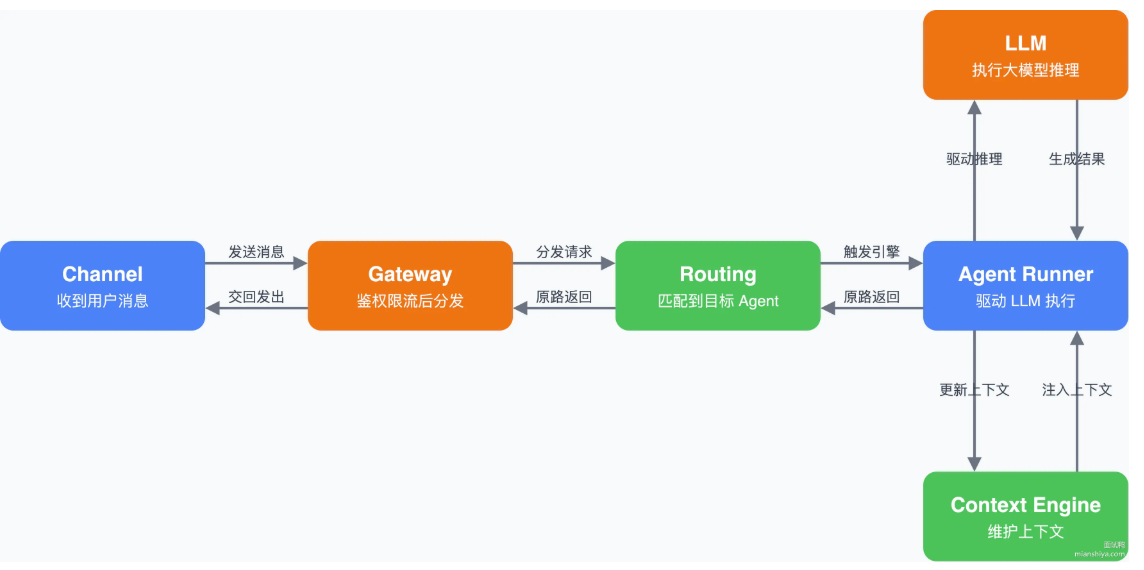
完整消息流:
源码层面的落点
1)Gateway 在src/gateway/,server.impl.ts负责启动,server-methods.ts负责请求分发
2)Channel在src/telegram/、src/discord/、src/slack/以及extensions/下的扩展
3)Routing 在src/routing/resolve-route.ts
4)Agent Runner 在src/agents/pi-embedded-runner/run.ts,这是执行主入口
5)Context Engine 在src/context-engine/types.ts定义接口,legacy.ts是默认实现(它把消息持久化委托给SessionManager,assemble直接透传消息列表,compact委托给compaction模块做摘要压缩)
辅助组件
除了五层核心组件,还有几个关键辅助角色。
Plugin Registry在src/plugins/registry.ts,统一收集插件注册的工具、Hook、渠道和 Provider,注册和管理所有插件扩展点。
Session Manager负责会话持久化,用JSONL格式,每轮对话追加一行,既方便调试也方便回放。
Config层在src/config/,基于Zod进行配置Schema校验,确保启动时即可发现配置错误。
为什么OpenClaw要采用五层分层架构?
分层是为了解耦与可维护性。每层职责单一、边界清晰,新增渠道或变更策略无需修改其他层
分层排障:10.1 请求流转与分层排障 | OpenClaw 从入门到精通 | OpenClaw Guide
System Prompt的框架:模块化组装+按需加载+分级加载+四字段钩子插件化扩展
OpenClaw的System Prompt不是一整坨字符串,而拆成了十几个独立模块,每次请求按需拼接。
这些模块可以分成三层来理解:
第一层:基础身份与安全(每次必加)
·身份声明:一句话告诉模型”你是谁”,这是整个prompt的锚点
·安全红线:写明不能自我复制、不能绕过安全机制、不能追求超出用户请求的目标
·工具列表:根据权限策略过滤后,列出当前可用的工具及调用规范
·工具调用风格:低风险操作不用解释直接调、敏感操作要先跟用户确认
第二层:场景能力模块(按需加载)
·技能提示:告诉Agent“你有哪些预装技能可以激活”,类似手机里的App列表
·记忆召回:指导模型在回答前先搜索历史记忆,避免”失忆”
·消息路由:跨通道(Signal、Telegram、Discord等)发消息的规则
·语音合成:只有开启了TTS功能才注入
第三层:动态运行时上下文(每次请求动态生成)
·当前时间、工作目录、操作系统、shell类型等环境信息
·授权白名单用户列表
·沙箱信息(如果Agent 跑在Docker里,要告诉它路径映射关系)
·项目配置文件的内容(行为规则、人格语气、用户偏好等)
还有个关键设计:分级加载。OpenClaw用一个加载级别参数控制注入哪些模块:
- 完整模式:加载全部模块,主Agent 用
- 精简模式:只保留工具列表、工作目录、运行时信息等核心模块,子Agent用(子Agent不需要消息路由、心跳这些能力)
- 最小模式:只返回一句身份声明
插件化扩展机制
除了内置模块,OpenClaw还支持第三方插件向System Prompt注入内容。原理是在System Prompt即将拼装完成时,系统广播一个信号:"我要构建prompt了,谁想加点东西?“注册了这个钩子(Hook)的插件就能在这时候把自己的内容塞进去。
插件有四种注入方式:
- 替换系统提示:直接覆盖整个SystemPrompt(后注册的覆盖先注册的)
- 系统提示头部追加:拼到System Prompt开头,适合静态指令,能被LLM 的prompt cache缓存
- 系统提示尾部追加:拼到System Prompt末尾,同样可缓存
- 对话层注入:放到用户消息前面,适合每轮可能变化的动态上下文
比如一个"代码规范检查“插件,可以通过钩子把当前项目的编码规范注入到SystemPrompt里,Agent写代码时就会自动遵守这些规范。不需要改任何核心代码。
长 System Prompt 的性能影响
System Prompt越长,每次请求消耗的 token就越多,响应延迟也会上去。
“按需加载”不只是架构上好看,在成本上也是刚需。模块化拼接+分级加载,能让子Agent的prompt 比主Agent 短得多,直接节省token开销。
prompt cache也是降本的重要手段。很多LLM提供商(如Anthropic、OpenAl)支持对System Prompt中不变的部分做缓存,第二次请求如果prompt 前缀没变,就不重复计算token 费用。
所以插件注入方式才区分了“系统提示层”和”对话层”:把稳定内容放系统提示里吃缓存,动态内容走对话层每轮注入。
业界其他方案的对比
Cursor的做法是把大量规则写进System Prompt,然后靠模型的长上下文能力硬扛,简单粗暴但有效。它的System Prompt非常长(包含工具说明、代码引用格式、提交规范等等),但因为Cursor面向的场景相对单一(代码编辑),所以每次都全量加载也还能接受。
Devin走的是另一个极端,把很多行为规则编码成代码逻辑而不是自然语言prompt,减少对System Prompt的依赖,但灵活性就差一些,改规则要改代码,不像改prompt 那样随时能调。
LangChain的Agent框架用模板化的方式组装prompt,跟OpenClaw思路类似,也有Callbacks系统可以在生命周期各节点插入逻辑,但它的Callbacks更偏”观测”(日志、追踪),在prompt注入这个环节的灵活度不如OpenClaw的四字段钩子精细。
模块化组装+按需加载已经成了Agent系统处理System Prompt的主流方案,OpenClaw在这个基础上加了分级加载(promptMode)和四字段插件钩子,算是做到了比较好的平衡。
如果把知识移到外部文件让Agent按需读取,模型读文件这个动作本身不也消耗token吗?怎么判断什么时候该放prompt里,什么时候该放外部?
判断标准就两条。第一看频率,每次请求都需要用到的信息放prompt里,偶尔才用到的放外部。第二看体积,几十个token的信息直接放prompt里没关系,但如果是几千token的编码规范文档,放外部按需读取更划算。读文件虽然也消耗token,但它是”用到才花钱”,比每次请求都带上要省得多。一般来说,超过500token且使用频率低于30%的信息,放外部就更经济。OpenClaw的Skills模块就是这个思路:System Prompt里只放一个技能目录(很短),模型判断需要某个技能时再通过read工具去读完整的SKILL.md 文件。
多个插件同时通过钩子注入SystemPrompt,有没有冲突的可能?怎么解决?
完全可能冲突。OpenClaw的解决方案是优先级机制:每个钩子注册时可以指定priority数值,数值越大优先级越高,执行越靠前。对于systemPrompt字段,合并逻辑是”后执行的覆盖先执行的”(即低优先级插件的systemPrompt会被高优先级的覆盖);对于prependContext、
prependSystemContext、appendSystemContext这些拼接型字段,则是按优先级顺序依次拼接,不存在覆盖。所以插件开发者需要注意:如果你要覆盖核心prompt,就设高优先级+用systemPrompt字段;如果只是追加上下文,用拼接型字段就不会跟别人冲突。
Agent Runner详细解读:
1.运行机制的核心Agentic Loop,基于ReAct范式的推理循环
这是OpenClaw的心脏。每当用户发一条消息,Agent进入一个循环:
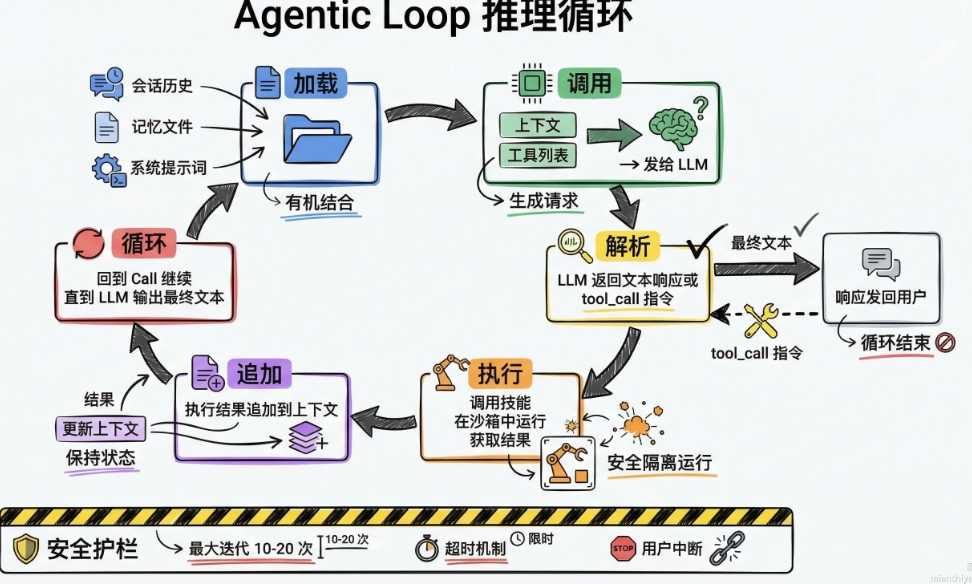
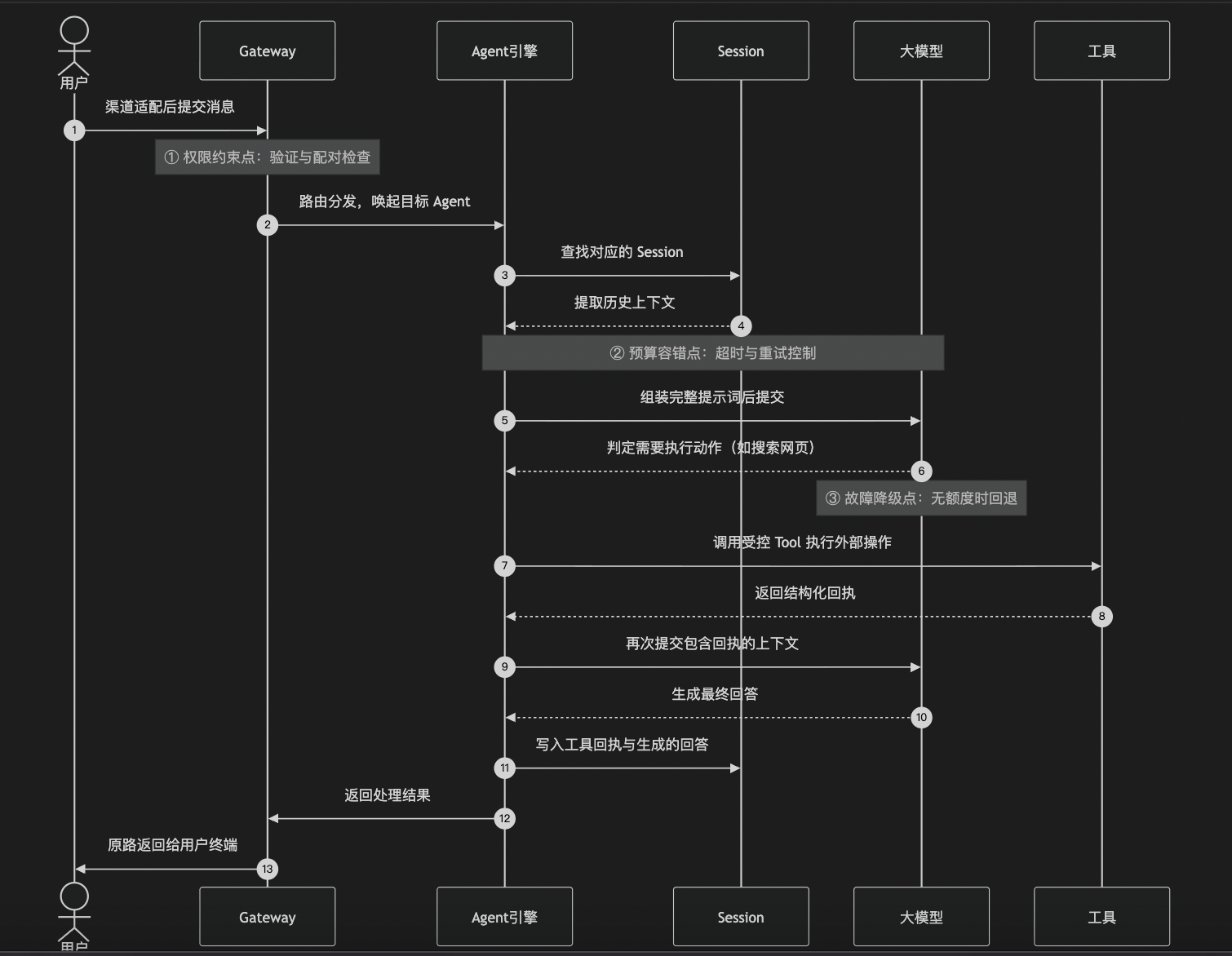
以“用户在 Telegram 发消息,智能体查了一个网页后回复”为例,还原完整Agent Loop流转过程:
组装上下文(System Prompt +历史+工具)
OpenClaw的系统提示词不是写死的,而是每轮对话由buildAgentSystemPrompt()动态拼装。数据来源包括:
●工作空间的 Markdown 配置文件:AGENTS.md(行为规则)、SOUL.md(人格语气)TOOLS.md(工具使用备注)、USER.md(用户偏好)、IDENTITY.md(身份配置)
●自动注入的运行时信息:可用工具列表及说明、当前时区、渠道能力、沙箱状态
●按需加载的技能指令(Skills)和语义搜索召回的记忆片段
插件还可以通过before_prompt_build钩子在构建阶段注入自己的上下文。改Agent行为只需编辑Markdown文件,完全不用动代码。
组装好上下文后,进入前面的核心循环Agentic Loop,底层使用pi-coding-agent SDK管理会话状态,在循环过程中,系统对上下文大小有严格的管控:
●ContextGuard:单条工具结果最多占context的50%,超出自动截断
●Token Budget:整体上下文有token预算,超出触发自动 Compaction(压缩)
●Overflow Recovery:如果遇到context overflow错误,系统会自动compaction→截断tool result→重试,最多重试数十次
循环结束对话结束后,保存状态:所有消息和工具调用结果以JSONL格式落盘到~/
.claw/sessions/目录,下次对话时加载恢复。
---------------------------------------------------------------------------------------------------------------------------------
Agent Loop中OpenClaw 没有使用同步阻塞式的开发范式,而是将底层推理引擎直接建立在 π (pi) 开源项目 的骨架之上,通过嵌入式集成(Embedded Integration)的方式复用其核心。
pi-coding-agent架构理念深深影响了 OpenClaw,体现为以下几个极简特性:
-
极简内核与高度可扩展:Pi 的引擎内核拒绝臃肿,默认只提供 Read、Write、Edit、Bash 四大底层高权限工具,并保持极短的系统提示词。若需更高级的能力或定制工具,它依靠一种插件化架构,通过配置文件从 npm 或 Git 动态解析并加载扩展包。
-
透明的记忆系统:它不依赖黑盒的本地向量数据库,而是完全通过读取工程目录下的
AGENTS.md或TODO.md等可见的纯文本文件来理解系统设定和项目架构。 -
完全自主执行模式:Pi 默认开启全自动模式。不同于传统框架在执行命令前总要求人工确认,Pi 在循环中不断读取、思考、执行,直到模型认为任务完成。这一“不被打断”的哲学,正是 OpenClaw 能实现真正的异步后台挂机自动化的基础保证。
事件驱动与 Tick 机制
Pi 的核心执行模型基于三个组件:事件(Event)、状态(State)与 执行内核(Executor/Tick)。
在 pi 框架中,所有对系统状态的增量改变都化作事件丢入中心总线——用户消息是 InputEvent,模型决定调用工具时抛出 ToolCallRequestedEvent,超时则产生 TimeoutEvent。将一切化作事件日志,意味着即使进程中断,也可以通过回放事件日志恢复状态。
执行内核通过 Tick(滴答) 机制驱动。一次 Tick 的使命非常简单:读取当前状态,推演出接下来应该执行的操作(例如向模型发起新一轮调用,或发出任务终结事件),然后交回控制权。Tick 并没有固定的时间频率,而是完全事件驱动——只有当总线接收到有效事件时才触发。
--------------------------------------------------------------------------------------------------------------------------------
整个流程的设计思路是每个阶段都可插拔。插件通过Hook介入、模型和Provider可动态切换、工具集按需组合。
2.Context溢出的三级降级
执行循环跑着跑着context可能会超限,特别是工具返回了大量内容的时候。
Runner 对此做了三级自动降级:
1)先尝试compaction,调用Context Engine压缩历史消息,腾出token空间
2) compaction还不够的话,截断超大 tool result。截断策略是动态的:先检测尾部是否包含错误信息或结果摘要,如果尾部重要就保留首尾、砍掉中间;否则只保留开头。截断位置会插入说明提示模型内容被截断了。单个tool result最多占上下文窗口的30%
3)前两步都救不回来,报错降级,告诉用户context太长了,建议开新会话,整个过程对用户透明,尽最大努力保证对话能继续下去。
3.AgentRunner的执行循环什么时候终止?有没有防死循环的机制?
AgentRunner每次循环就是调LLM拿到响应,如果响应里包含工具调用就去执行工具,把结果喂回LLM继续下一轮。终止条件是LLM返回纯文本回复、不再请求调用工具。防死循环靠多层保护:执行超时时间、工具循环检测(tool-loop-detection.ts内置多种检测策略:generic_repeat检测连续调同一工具同一参数、ping_pong检测两个工具交替调用、known_poll_no_progress检测轮询无进展、global_circuit_breaker全局断路器兜底)、以及context overflow 时的自动compaction和降级。超过限制就强制终止,返回一个兜底回复。
4.OpenClaw的 Agentic Loop 如果某一步工具调用失败了,怎么处理?
错误信息和详情会作为tool_result回填到上下文里,然后继续下一轮循环。错误处理逻辑不是硬编码的if-else,而是交给LLM的推理能力来判断。
系统层面提供兜底保护:用户发新消息可以直接中断当前循环(abort机制),防止Agent卡死烧Token;如果遇到context overflow,系统会按优先级自动恢复:先触发Compaction压缩历史→再截断过大的tool result→最后报错建议reset。整个重试循环有迭代次数上限(默认32~160次,取决于配置的auth profile数量),防止无限重试。
5.Agent Runner的attempt +fallback容错机制
1)Auth Profile轮转:如果一次尝试因为auth失败、限流或服务过载挂了,Runner会自动切到同Provider的下一个API Key重试。比如配了三个OpenAl Key,第一个被限流就自动换第二个。
2)模型级Fallback:如果所有Key都轮完还是失败,Runner向外层抛出FailoverError,外层的model-fallback层会切到配置的备用模型。比如Claude整体不可用就降级到GPT-4o,用户几乎感知不到切换。重试有上限(根据profile数量动态计算,范围32-160次),不会无限重试。遇到服务过载还会加指数退避,避免继续打爆上游。
fallback机制切换模型之后,之前的对话历史格式兼容吗?不同模型的消息格式不一样怎么办?
历史消息以统一的中间格式存储在session文件中。切换模型时用的是同一份sessionfile,新的attempt启动时会根据目标Provider的特性做格式适配。比如Gemini和Anthropic的turn交替规则不同、thinking block处理不同,这些都在session历史清洗阶段自动处理。所以fallback切换对历史消息是透明的,不需要手动做格式迁移。
6.工具调用的双层包装
每个工具在注册时会经过两层包装:
1)Hook拦截层:插件可以在工具执行前异步检查参数、做权限校验,甚至直接阻止执行。这一层还内置了循环检测,防止LLM反复调用同一工具陷入死循环。
2)取消机制层:把外部的AbortSignal和工具自带的信号合并。当用户发了新消息、超时了、或手动停止时,正在执行的工具可以被中断,不用干等到超时。
提问:工具的Hook拦截层会不会引入性能问题?每次工具调用都多走两层包装,延迟能接受吗?
回答:两层包装本身的开销可以忽略不计,就是几个函数调用和Promise包装,微秒级别。真正可能有性能影响的是Hook里的具体逻辑,比如某个插件在beforeToolCall里做了一次网络请求做权限校验,那这个延迟是插件自己的问题,不是框架的问题。没注册Hook的话,拦截层会直接透传到原始工具函数,几乎零开销。
Gateway
数据完全在本地,那多设备之间的会话同步怎么解决?手机上聊了几句,回到电脑上能接着聊吗?
会话数据存在Gateway所在的机器上,手机和电脑连的是同一个Gateway实例,所以天然就是同步的。手机上通过WhatsApp发消息,Gateway处理完存下来,你在电脑上打开Web客户端看到的就是完整的对话历史。关键是所有渠道的消息都汇聚到同一个session,不会出现手机一份、电脑一份的情况。
Gateway的幂等去重是怎么做的?
Gateway在接收到每条消息后,提取其唯一标识(如消息ID或签名哈希),在本地缓存中查询是否已处理过该标识;若存在则直接丢弃,避免重复进入下游流程,从而将幂等性保障收敛在系统入口
连接生命周期:握手、认证与心跳
OpenClaw Gateway 通过 WebSocket 长连接与远端设备进行持久通信。
1.为什么是 WebSocket
相比 HTTP 的请求-响应模式,WebSocket 长连接有三个优势:
选 HTTP: ├── RESTful API(增删改查) ├── 偶尔的数据获取 ├── 需要缓存的静态/半静态数据 └── 简单的表单提交 选 WebSocket: ├── 即时通讯(聊天、消息推送) ├── 实时数据流(股票、游戏、监控大盘) ├── 协作应用(多人编辑、白板) ├── 物联网设备通信 └── 需要服务器主动推送的任何场景 选 SSE(折中方案): ├── 只需要服务器→客户端的单向推送 ├── 新闻推送、通知系统 └── 比 WebSocket 简单,比轮询高效若WebSocket/长连接调试耗时,改用 `客户端每2秒轮询 + 服务端返回增量版本号`,稳定且易实现。
2. 心跳保活机制
在长连接中,网络中间件(代理、防火墙)可能因为空闲一段时间而主动断开连接。心跳机制用来防止这种“无辜掉线”,周期性发送 PING/PONG,防止代理中间件误断
Gateway 的检活逻辑:
if (now - last_message_time > 60s) {
// 超过 2 倍心跳间隔(默认 30s × 2)无消息,主动断开
connection.close(code=1000, reason="heartbeat_timeout");
log_event("device_offline", device_id);
}3. 异常恢复与重连策略
设备与 Gateway 的连接可能因为多种原因断开:网络抖动、设备重启、Gateway 升级等。OpenClaw 设计了智能重连机制。
重连的退避策略
设备应遵循指数退避(exponential backoff):
attempt = 0
while not connected:
delay = min(
base_delay * (exponential_base ^ attempt),
max_delay
)
attempt += 1
wait(delay)
try_connect()典型参数:
-
base_delay= 1 秒 -
exponential_base= 2 -
max_delay= 300 秒(5 分钟)
重连后的状态恢复
重连后,设备不需要从头推送所有状态。Gateway 的控制平面负责恢复:
-
会话状态持久化:所有已完成的步骤都被记录到存储(如 PostgreSQL)
-
设备重连时:控制平面加载该设备关联的所有未完成会话
-
继续执行:Agent 从上一个检查点继续执行,而不是重新开始
if device_reconnected(device_id):
sessions = load_sessions_for_device(device_id)
for session in sessions:
if session.status == "waiting_for_device":
resume_from_checkpoint(session)这样设计的意义是:即使设备断线数小时,重连后也能无缝恢复,用户不会丢失进度。
上下文管理(策略模式)
1.上下文的构建
上下文由workspace(文件夹中包含AGENTS.md、SOUL.md等系统身份信息)、skills、会话历史与工具回执共同组成;重点在注入顺序、预算分配与结构化回注
上下文组装遵循“身份先于知识,知识先于历史,历史先于工具”的优先级。当总预算紧张时,牺牲顺序为:旧工具回执 → 早期对话轮次 → 工作区知识 → 系统身份(不可牺牲)。
工程建议:
-
身份层锁定预算:SOUL.md 和技能指令的体积应在设计时控制,不随会话增长。
-
工具回注结构化:把关键字段与摘要回注进会话,把全量输出落盘为证据引用。避免将整个 API 响应作为工具结果留在上下文中。
-
检索按需注入:记忆检索结果(
memory_search)应在每轮组装时动态注入,而非一次性灌入全部候选项
2.Context Engine
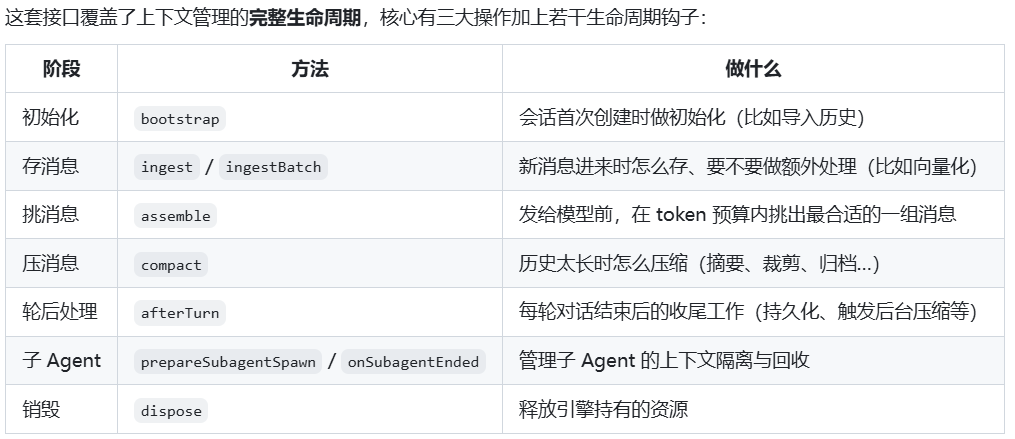
三大核心操作是:1)ingest /ingestBatch——新消息进入时的处理;2)assemble——组装prompt上下文;3)compact——历史过长时的压缩。
OpenClaw把Context管理抽象成了可插拔的Context Engine,为什么要做这层抽象?这个设计能支持哪些不同的策略?
根本原因是Context管理没有万能方案。
不同的应用场景、不同的模型上下文窗口大小、不同的任务类型,最优的Context策略差异巨大。
把Context管理抽象成接口(定义好”做什么”),让策略实现(“怎么做”)可以独立替换,既方便内部迭代,也方便社区扩展。这就是经典的策略模式。
ContextEngine接口定义在src/context-engine/types.ts,覆盖了完整的生命周期:
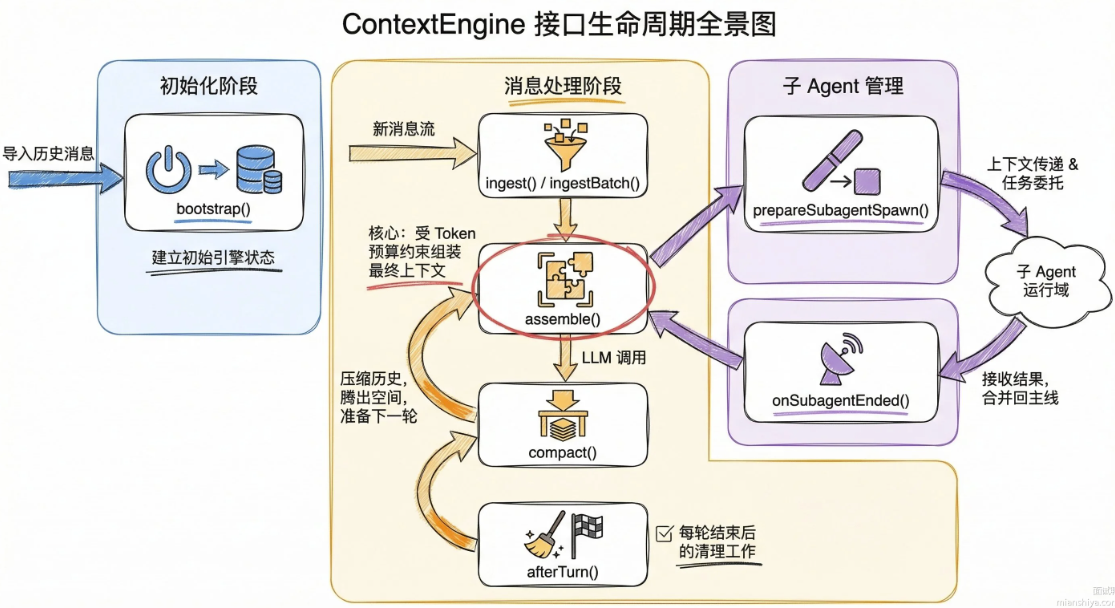
核心调度逻辑只依赖这套接口,不关心背后的具体实现。通过registerContextEngine(id,factory)注册新引擎,在配置里通过plugins.slots.contextEngine一行就能切换,完全不用动核心代码。
这就是典型的策略模式+插件化。
有了这层抽象,至少能支撑以下几种完全不同的策略方向:
1.默认的legacy策略:全部塞进去,塞不下了线性压缩最早的消息,assemble阶段按时间顺序拼接最近消息
2.基于检索的RAG策略:消息入库时向量化,组装时按语义相关性捞历史,适合长对话多话题场景
3.分层存储策略:类似冷热分离,最近几轮放内存、摘要放本地、更早的扔云端,按需拉取
4.任务感知策略:根据当前任务类型(写代码vs闲聊)动态决定保留哪些历史,同样的token预算质量更高
5.自定义压缩策略:通过ownsCompaction标记接管压缩,可以实现树状摘要、按话题分支压缩等高级方式
不同策略的解读
1.内置的 legacy 引擎
ingest是 no-op,消息持久化由 SessionManager 负责;assemble直接透传消息列表,不做任何筛选;compact委托给compactEmbeddedPisessionDirect()做线性压缩。
策略非常粗糙,“全部塞进去,塞不下了就压缩最早的”。
可以实现的高级策略
ContextEngine抽象真正的价值在于它能支撑完全不同的上下文管理思路:
2.基于检索的 Context Engine(基于RAG思想)
3.分层存储引擎
思路类似数据库的冷热分离。热数据就是最近3-5轮对话,直接放内存;温数据是最近几个compaction周期的摘要,放本地文件;冷数据是更早的历史,可以扔到外部存储甚至云端。assemble的时候按需从不同层拉取,既能保证最近上下文完整,又不会因为历史太长撑爆内存。
4.任务感知引擎
5.自定义Compaction 引擎
接口里有个ownsCompaction:true的标记,设了这个标记的引擎可以完全接管压缩策略。默认的线性压缩是把最早的消息一坨压成摘要,可以换成树状摘要,把对话按话题分支组织,每个分支独立压缩,保留更多结构化信息。
插件注册机制
整个切换过程对核心代码零侵入。写一个新引擎只需要实现ContextEngine接口,然后调用registerContextEngine("my-rag-engine",factory)注册进去。配置文件里把plugins.slots.contextEngine指向引擎ID。这跟Webpack 的 plugin 体系、VS Code 的扩展机制是一个思路,都是约定好接口,实现随便换。
legacy引擎的ingest是no-op,消息是谁在管?如果换成RAG引擎,职责怎么迁移?
legacy引擎的消息持久化是SessionManager 在做,ingest 啥也不干是因为职责没划到Context Engine这边。换成RAG引擎的话,ingest就得真正接管消息的处理了,至少要做向量化和入库。迁移的关键是SessionManager得把“写消息“这个动作让出来,或者两边做好协调,不能重复写。实际上这也是为什么要抽象成接口的原因之一,职责边界可以随着引擎实现灵活调整。
ownsCompaction这个标记具体怎么生效的?不设这个标记的话压缩是谁触发的?
OpenClaw 的压缩触发分两层。不设ownsCompaction的话,底层的 Pi runtime 有内置的auto-compaction,自己监控token用量,超过阈值就自动压缩,外层Runner不需要手动介入。设了ownsCompaction:true之后,Pi的内置auto-compaction会被禁用,改由引擎自己通过afterTurn等生命周期钩子决定什么时候压、怎么压。但不管设没设这个标记,Runner还有一层溢出压缩兜底,当上下文真的塞不下时,Runner会直接调contextEngine.compact()做紧急压缩。ownsCompaction控制的是”日常谁来管压缩”,但“快炸了"的时候Runner一定会兜底。
ContextEngine说可以插拔替换,那默认实现和自定义实现的边界在哪?
src/context-engine/types.ts里定义了接口契约,核心就三件事:摄入新消息(ingest)、组装 Prompt上下文(assemble)、压缩历史记录(compact)。默认的legacy.ts实现比较直白:ingest是no-op(消息持久化由 SessionManager负责),assemble直接透传消息列表,compact委托给compaction模块做LLM摘要压缩。如果业务需要更复杂的策略,比如按语义相关性检索历史、或者接入向量数据库做RAG,只要实现同一套接口,在配置里切换就行。
会话状态的双层存储机制
OpenClaw 的会话状态数据默认按智能体存储在 ~/.openclaw/agents/<agentId>/sessions/ 目录下。官方允许用 session.store 覆盖目录位置。根据底层设计,会话状态分为两层分开存储:
-
Session Store (
sessions.json):主要存储会话的元数据(如sessionId、Token 计数、压缩次数等)。这部分数据是轻量级的,即便由于意外被手动修改,也能被 Gateway 安全重建。 -
Transcript (
<sessionId>.jsonl):追加式的对话历史记录(JSONL 格式)。包含了原始消息、工具调用记录以及压缩后的摘要内容。
配置示例:
{
session: {
store: "~/.openclaw/agents/{agentId}/sessions/sessions.json",
},
}[!TIP] 避坑:
/new命令会让你失去记忆吗? 很多新手误以为执行/new命令会让当前的 AI 助手完全“失忆”。实际上,该命令仅仅是创建了一个全新的sessionId并清空了当前的 临时对话上下文(Transcript)。磁盘上持久化的记忆文件(如MEMORY.md)依然存活,它们会在这个新会话中 被自动重新加载。
3.长上下文
LLM的Context Window有上限,长对话如何保证Agent仍然能正常工作?OpenClaw怎么做的?
分层防御:
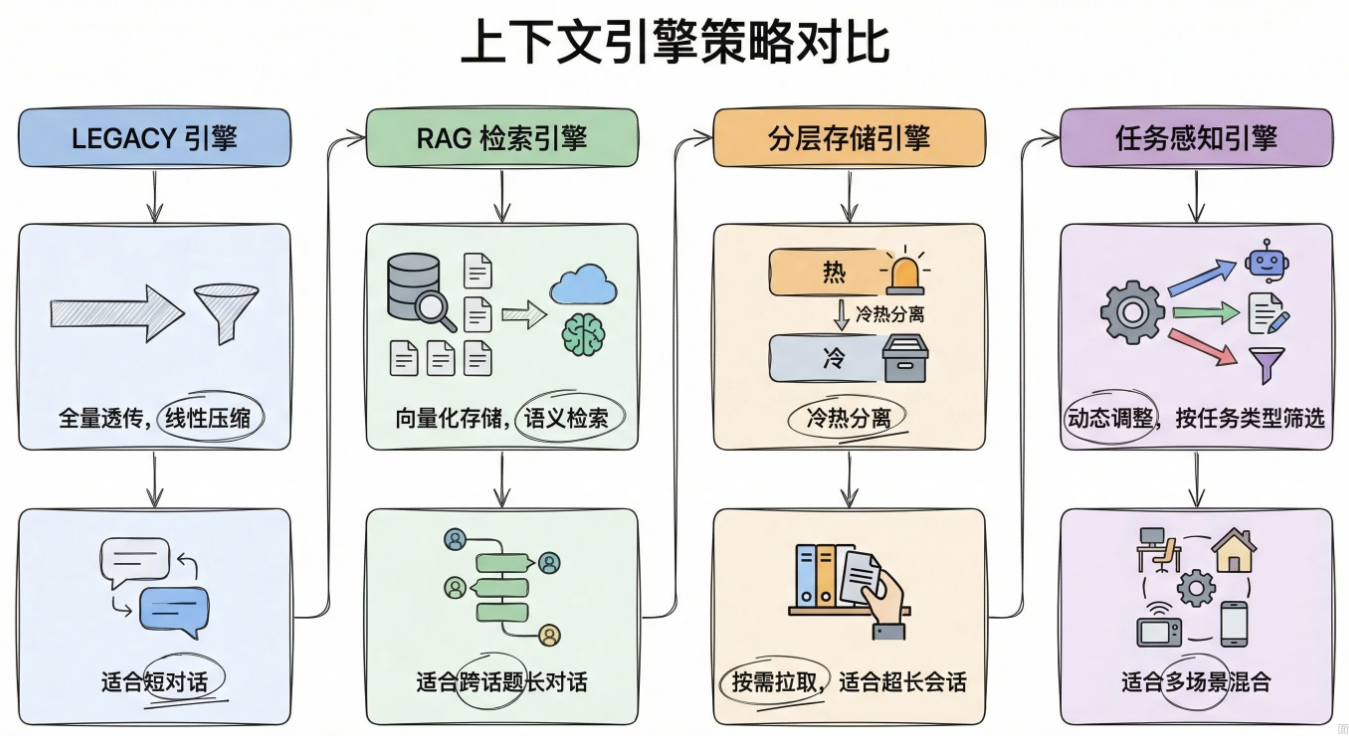
第一层是ContextPruning(上下文修剪),在每次向LLM发请求前清理不重要的内容。当上下文占比超过阀值时,对早期的tool result做head+tail裁剪甚至用placeholder替换。但最近几轮的assistant消息和System Prompt这些核心内容必须保留。
第二层是Tool Result Context Guard(工具返回兜底),也运行在transformContext阶段。先对单条超出预算的tool result 截断,如果所有tool result的总量还是超了,就从最早的开始用placeholder替换。这是一个实时安全网,保证送给LLM的context永远在安全范围内。
第三层是MemoryFlush(记忆刷盘),当token用量接近compaction阈值时,先让Agent把关键信息写到磁盘文件(memory/YYYY-MM-DD.md)做备份,防止后续压缩丢失重要细节。
第四层是Compaction(压缩),用LLM把旧的对话历史压缩成摘要,替换掉原始消息。100条消息压成一段摘要,token消耗直接降一个数量级。因为在它之前已经做了MemoryFlush,关键信息已经落盘,摘要的有损压缩就可以接受了。

引入冷却期(默认5分钟),避免每次LLM请求都重复扫描和裁剪上下文,减少CPU开销和延迟波动;同时保障在短时间内多次请求共享一致的上下文视图,提升推理稳定性。

Tool Result Context Guard兜底机制
installToolResultContextGuard()在src/agents/pi-embedded-runner/tool-result-context-guard.ts中实现,通过包装Agent 的transformContext方法拦截。
它会计算一个 context budget (context window x 4 chars/token x 0.75)。然后,先对超出单条上限的tool result 截断。如果总量还是超了,就从最早的tool result 开始用"[compacted:tool output removed to free context]"替换。不管前面的修剪和压缩有没有到位,这一层兜底保证送给LLM的context永远在安全范围内。
压缩摘要的时机怎么选?太频繁了或者太晚了都有问题吧?
太频繁了耗费token,太晚又会导致context逼近上限,留给新消息的空间不够。OpenClaw用的是pi-coding-agent库内置的自动compaction机制,当上下文token逼近模型窗口时自动触发。在compaction之前,Context Pruning已经在低阀值(默认30%开始裁剪tool result,50%开始
用placeholder替换)做了第一道减负,这样compaction不需要太频繁触发。同时MemoryFlush也有独立的触发条件(softThresholdTokens默认4000),确保在compaction 前关键信息已经落盘。
Context Pruning删掉的tool result,如果后面模型又需要了怎么办?
有两种恢复途径。第一,如果是文件内容类的tool result(比如readfile),文件本身还在磁盘上,模型可以再次调用工具读取。第二,Memory Flush机制会在compaction之前让Agent自行判断哪些关键信息需要持久化,写到memory/YYY-MM-DD.md文件中。注意MemoryFlush不是按工具类型选择性保存tool result原文,而是让LLM自行提取和总结关键信息落盘。比如重要的决策、配置参数、任务进度等。所以它保存的是”语义级别”的关键信息,不是tool result的原始副本
tool result中间被截断的部分不会在代码里被自动“补回来”,只能靠“重新执行 tool/分段读取”来取回
如果“中间被截断的部分”后面还需要用,代码如何处理?
1) **截断是“破坏性”的:被截断文本不会被缓存到别处,无论是 head-only 还是 head+tail,都是**直接把 toolResult message 的 text block 替换成截断后的字符串**(返回一个新 message 或在某些 guard 里原地 mutate)。所以**中间被砍掉的部分在消息层面就真的消失了**。
2) 发生截断的三条路径里,都没有“自动续传/自动重取”
有三种“变小”机制,目的都是避免上下文溢出,它们都不会尝试恢复中间内容:
- **发送给模型前(in-memory)预防性截断**
- 只在要发给 LLM 的 `messages` 数组里把 oversized 的 toolResult 截短
- **不会**存原文备份,也**不会**自动再调用 tool
- **写入 session transcript 时的硬上限截断(持久化阶段)**
- [installSessionToolResultGuard()
- [capToolResultSize()]用 `HARD_MAX_TOOL_RESULT_CHARS` =400K做硬截断,防止 session 文件里出现巨大的 toolResult
- 一旦写盘时被截断,之后 session 继续对话拿到的就是截断版本(原文已不在 transcript 里)
- **上下文预算 guard:必要时直接“清空旧 tool 输出”**
- [installToolResultContextGuard()][tool-result-context-guard.ts]先把单条 toolResult 截到 budget;如果整体仍超预算,会把**最老**的 toolResult 替换成占位符:
- `PREEMPTIVE_TOOL_RESULT_COMPACTION_PLACEHOLDER = "[compacted: tool output removed to free context]"`
- 这比截断更激进:直接删成占位符,同样不保留原文
3) “后面还需要用”的处理方式:**靠提示语引导模型/用户再次按块获取**
虽然代码不自动重取,但它用两种方式“约定”怎么把缺失内容再拿回来:
- **提示语层面**
- `TRUNCATION_SUFFIX` 明确写了:“If you need more, request specific sections or use offset/limit parameters to read smaller chunks.”
- [session-tool-result-guard.ts] `GUARD_TRUNCATION_SUFFIX` 也写了类似提示(持久化截断场景)。
- **机制层面(推断意图)**
- 代码本身不实现“续传”,而是依赖 tool 体系本来就支持 `offset/limit`(例如 read-file/read-log 一类工具)来做 **重新调用**。
- 也就是说:如果中间缺的那段后续真的需要,正确策略不是“指望它在 transcript 里还在”,而是让 agent **再次调用工具**,用更小窗口(分页/指定区间)拿。
OpenClaw的记忆系统是怎么做语义搜索的?纯向量检索还是有别的方案?
混合搜索策略(memory_search— 默认采用 混合搜索算法 BM25+向量相似度),实现在QmdMemoryManager里。还支持CK分词处理中日韩文本,有时间衰减机制(Temporal Decay)让旧记忆相关性自动降低,还有MMR(最大边际相关性)做多样性重排。对外暴露两个工具:memory_search做语义召回返回摘要片段,memory_get按路径和行号读取完整内容。
补充:
记忆系统:短期+长期的双层设计
OpenClaw的记忆系统解决的核心问题是:LLM只能看到当前context window里的内容,怎么让它记住更多?
短期记忆就是当前会话的对话历史。
当对话太长快撑爆context window时,会触发Compaction(压缩):用LLM对早期对话生成结构化摘要,替换掉原始消息。摘要中严格保留标识符(UUID、URL、文件名等)和关键结构(决策、待办等)。压缩前还有一个MemoryFlush机制:先让模型把关键信息主动写到memory/目录的文件里,确保压缩不会丢关键信息。
长期记忆存储在本地磁盘的memory/目录里,通过QmdMemoryManager管理。
长期记忆检索用的是混合搜索策略,搜”投资目标”也能命中“财务目标””资金规划”这种同义表达,同时支持CK分词。检索结果还经过时间衰减(越旧的记忆权重越低)和MMR多样性重排(避免结果太雷同)。
Agent通过两个工具接口使用记忆:memory_search做语义召回,memory_get按路径读取具体内容。数据全部存在本地,不出设备。
Agent调用工具可能返回超大结果(比如代码搜索返回50KB),这会带来什么问题?你会怎么处理?OpenClaw是怎么做的?
调用工具得到超大结果会带来三个直接问题:token爆炸、挤占上下文空间、延迟飙升。处理思路就两步:限额+截断。给每条tool result 设一个字符上限,超了就砍。
而截断的关键在于砍哪里。直觉是保留开头,但实际上尾部也很重要,因为错误堆栈、诊断信息往往在末尾(就像看日志,最后几行的报错信息通常最关键)。所以最优策略是head+tail截断:保留开头让模型知道内容是什么,保留尾部抓住错误信息,中间砍掉加一个省略标记。
OpenClaw实际上有两层防护:单条截断+全局预算守卫
中间省略标记如下:

全局守卫时最早替换的placeholder如下:

head+tail截断的比例怎么定?head和tail各占多少合适?
没有通用最优比例,看tool的类型。OpenClaw的实际做法是tail拿budget的30%(上限4000字符),head拿剩余的大部分空间,head最少保留2000字符。而且不是所有截断都走head+tail,只有hasImportantTail()检测到尾部含有error/exception/traceback等关键词时才分割,否则默认只保留开头。
除了截断,还有没有其他方式处理超大tool result?
- 一是在工具端就做好过滤,比如代码搜索只返回最相关的top10结果,不吐全量。
- 二是用摘要模型先把大结果压缩成摘要再喂给主模型,Anthropic内部就有类似的sub-agent做result summarization。
- 三是分页,把大结果拆成多页,模型可以选择翻页获取更多内容。
- 截断是最简单粗暴的兜底方案,理想情况下应该在工具端就控制好输出量。
其他Agent 框架怎么处理
LangChain 的 ToolMessage 默认不截断,但社区实践里通常在tool 的output parser层加限制。Anthropic的Claude tool use文档建议单条tool result不超过100K字符。AutoGPT早期版本压根没做截断,文件读取返回太大直接把context 撑爆,后来才加了max_length参数。
技能是注入到System Prompt里的,技能特别多上下文窗口不够用怎么办?
渐进式披露就是专门解决这个问题的。1.元数据层每个技能只占很少tokens,完整执行指令只有命中的少数几个才会加载。2.会话历史也有压缩机制,接近窗口上限时自动把早期对话做摘要。3.在摘要之前还有MemoryFlush机制,先让模型把关键信息写到磁盘的memory文件里,确保压缩不会丢失重要信息。4.再加上tool result的ContextGuard(单条结果最多占context的50%,超出自动截断),多套机制配合控制上下文长度。
补充:
技能系统(Skills)和渐进式披露
如果把所有工具的完整说明都塞进System Prompt,几十个工具就能吃掉大量Token,模型面对太多选择还容易选错。每个技能是一个带SKILL.md的文件夹,SKILL.md 的YAML frontmatter声明元数据(名称、描述、触发条件),正文是完整的执行指令。
加载分三层:
1.元数据层(始终加载):只解析 frontmatter,几十tokens 的开销
2.指令层(条件加载):根据用户查询做相关性评估,只有命中的少数技能才展开完整内容
3.资源层(按需加载):脚本、模板等只有技能被激活且确实需要时才拉进来
打个比方:传统做法是把整本操作手册塞给你让你自己翻,OpenClaw是先给你看目录,你说“我要搜网页”,再翻到那一章给你看。社区技能通过ClawHub分发,一行clawhub install<skill-slug>即可安装。
System Prompt 在Agent 系统中承载了哪些职责?如果System Prompt 越来越长,怎么处理?
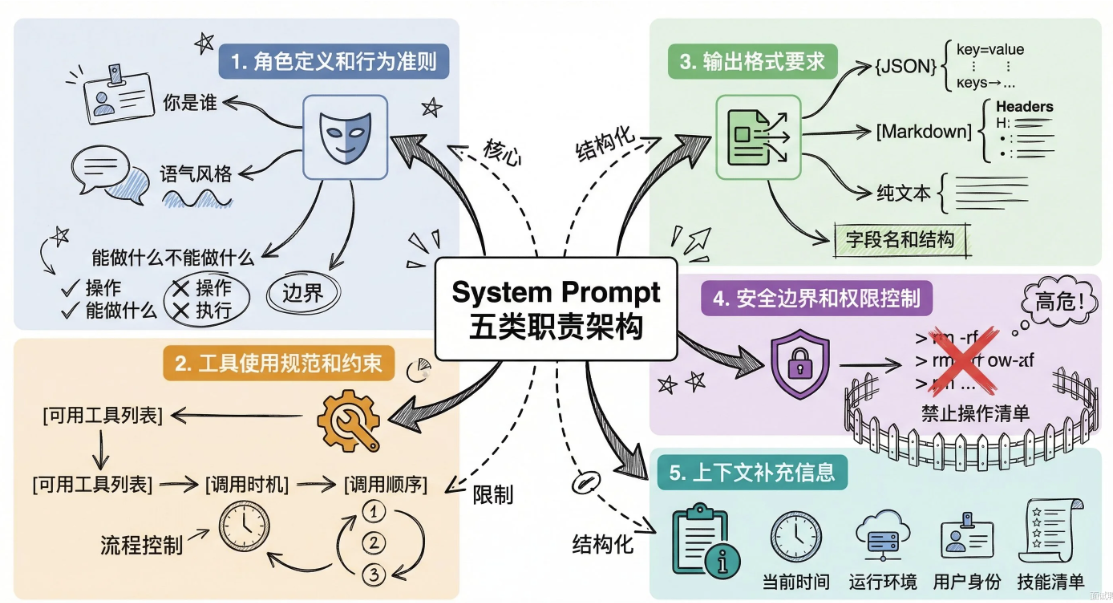
核心策略就三个字:拆、选、扔。
拆,是把System Prompt按职责拆成独立模块,每个模块管一件事。
选,是根据当前任务场景只注入相关模块,不需要的不塞进去。
扔,是把稳定不变的知识从prompt里移出去,放到外部文件或知识库里,让Agent需要的时候通过工具调用自己去读。
4.Compaction的核心流程
1.分块(Chunking):先把待压缩的消息按token预算切成多个chunk(默认切2段)。切分在单条消息的边界进行,chunk大小由Context窗口比例自适应计算。同时把最近几轮对话(默认3轮)分离出来保留原文,只压缩更早的消息。
2.逐块摘要(Per-chunkSummarization):每个chunk分别发给LLM生成一段摘要。超大消息降级:如果单条消息超过上下文窗口的 50%(isOversizedForSummary),会被排除在摘要之外并插入说明(如[Large assistant (~45K tokens) omitted from summary])。如果摘要整体失败,系统会逐步降级:先排除超大消息重试,最后回退到纯文本记录
3.合并摘要(MergeSummaries):多段局部摘要再调一次LLM融合成一份连贯的最终摘要
4.摘要增强(SummaryAugmentation):在合并摘要基础上,追加额外上下文,比如工具调用失败记录(包含exit code和error状态)、文件操作记录(读过和修改过的文件列表)、最近几轮对话的原文摘要、以及从AGENTS.md读取"Session Startup”和"红线规则"两个部分,重新注入到上下文里。最终的摘要替换掉原始消息,写入session历史。
为什么要这么做?
因为Compaction把早期消息替换成了摘要,但Agent的启动流程和红线规则可能就在那些被替换掉的早期消息里。如果不重新注入,模型压缩完之后可能忘了自己有哪些不能碰的红线,行为就可能失控。
摘要的质量检查
1.压缩完成后会检查摘要是否包含5个必要的结构化章节:
●Decisions(做过的决策)
●Open TODOs(未完成的任务)
●Constraints/Rules(约束条件)
●Pending user asks(用户尚未被回应的请求)
●Exact identifiers(需要精确保留的标识符)
除了章节完整性之外,质量审计还会检查两个方面:
摘要是否保留了从最近消息中提取的关键标识符(strict策略下)以及摘要内容是否反映了用户最新的请求。
不过需要注意,这套质量检查+重试机制默认是关闭的,需要在配置中显式启用。
2.标识符保留策略
摘要有一个特别容易踩的坑:LLM会把UUID、hash、API key、URL、文件名这些标识符"概括”掉。比如把file:src/controllers/UserController.ts概括成"修改了一个控制器文件",后续Agent想继续操作这个文件就找不到了。
OpenClaw默认采用strict策略,要求摘要中精确保留所有不可重构的标识符。Compaction的prompt里会给LLM一条通用指令,明确要求原样保留UUID、hash、ID、token、API key、主机名、IP、端口、URL、文件名等。同时要求摘要必须包含Exactidentifiers章节来列出关键标识符。
5.短期记忆的具体实现
在 OpenClaw 里,**短期记忆不是用 Redis** 做的;是“**对话上下文缓存**”,主要通过 **进程内 `Map`** 来存储“自上次机器人回复以来的消息片段”,在需要回复时把这段历史 **拼接进当前 prompt**,用于提升上下文理解。
1) 短期记忆存的是什么?数据结构长什么样?
核心存储结构:`Map<historyKey, HistoryEntry[]>`
- **`historyMap: Map<string, HistoryEntry[]>`**
- **[HistoryEntry]结构:
- `sender: string`
- `body: string`
- `timestamp?: number`
- `messageId?: string`
短期记忆存的是:**按会话/群/频道维度分组的一段消息列表**(通常是最近 N 条),重点用于“机器人准备回复时”提供上下文,并不是持久化存储
2) 两个“上限/淘汰”机制
- **每个会话的消息条数上限**:通过 `limit` 控制(默认 group limit 常见是 50)超过 `limit` 就 `shift()` 把最老的移除
- **会话 key 数量上限(LRU-like)**:`MAX_HISTORY_KEYS = 1000`
- `Map` 的插入顺序被用来做近似 LRU
- 每次追加会 `delete(historyKey)` 再 `set(historyKey)`,从而“刷新最近使用顺序”
- 超过 1000 个不同会话 key,就从最老的 key 开始删
这就是 OpenClaw 对短期记忆“热点会话 / 内存增长”的主要保护方式:**单 key 限长 + key 数限量(LRU 淘汰)**。
3) historyKey(会话维度)是怎么定的?
不同渠道选择不同粒度的 `historyKey`,本质原则是:**同一个群/频道共享一个 key**。
这也是为什么它叫“短期记忆”:它是**按会话维度**临时缓存,不是按用户长期沉淀。
4) 这个实现的特点
- **优点**
- **简单可靠**:不依赖 Redis/DB
- **性能好**:纯内存读写
- **语义清晰**:pending history + 回复后清理,实现“since last reply”
- **有上限保护**:单会话限长 + 会话 key 限量(LRU-like)
- **局限**
- **不跨进程**:多实例部署时每个实例各自一份短期记忆
- **重启即丢**:进程退出就失忆(但短期语义通常可接受)
- **热点会话风险仍在**:如果某个群极其活跃,会频繁写入同一 key,造成 CPU/GC 压力(但有 `limit` 限制 value 增长)"
多渠道接入(适配器模式)
如果一个Agent系统要同时接入Telegram、飞书、钉钉等渠道,你会怎么设计抽象层?OpenClaw的 Channel Plugin接口是怎么设计的?
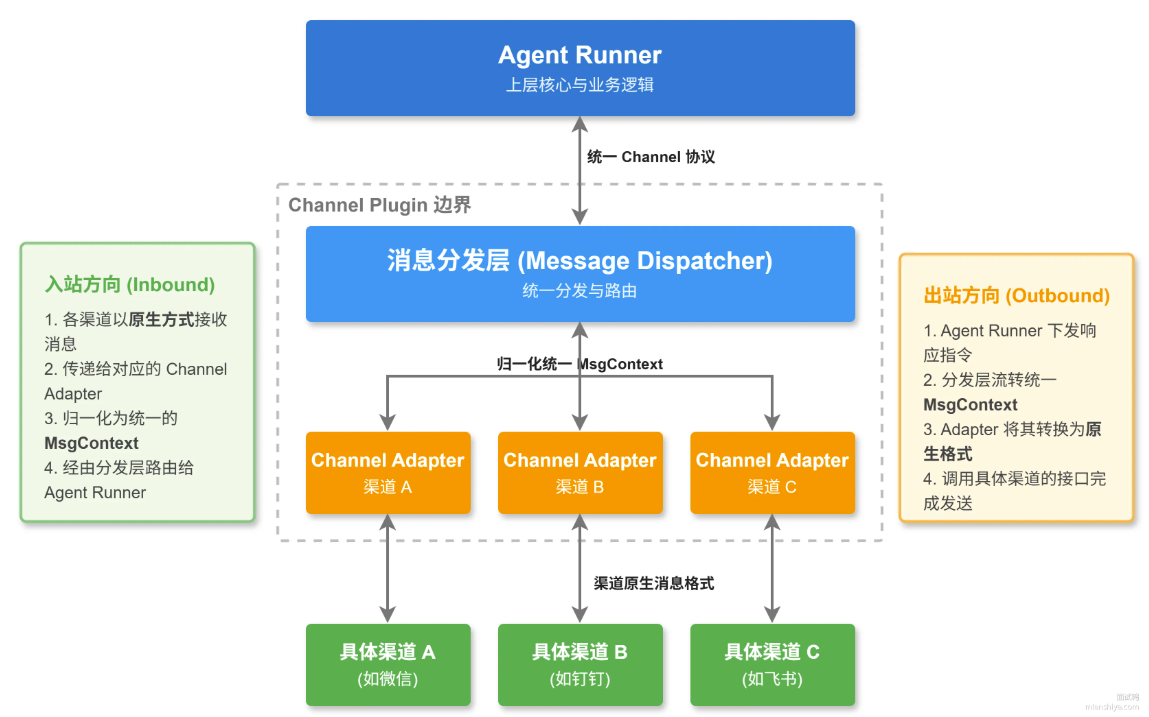
核心思路是适配器模式:定义一套统一的Channel协议,每个渠道实现一个适配器(Adapter),负责把该平台的消息格式”翻译”成系统内部统一的消息结构。上层Gateway只跟协议打交道,完全不关心底下接的是Telegram还是飞书。
这道题其实考的就是一个经典设计问题:如何隔离外部系统的差异性。三个层面:
第一层:统一消息模型
所有渠道的消息进来后,都归一化成一个统一的消息上下文(比如OpenClaw里叫MsgContext)。核心字段涵盖所有渠道的共性:发送者、文本内容、时间戳、会话标识。渠道特有的信息(比如Slack的 BlockKit组件、Discord的embed)放到扩展字段里。上层处理链路只认一种数据结构,跟渠道彻底解耦。
第二层:适配器协议
每个渠道实现一个ChannelAdapter,至少要实现两个核心能力:入站(收消息并归一化)和出站(把统一格式转成渠道原生格式发出去)。除此之外,还可以按需实现可选能力,比如群组管理、@提及处理、配对认证、限流策略等。
这里的关键设计决策是组合优于继承,不要搞一个大接口让所有渠道都实现,而是把每种能力拆成独立的小接口,渠道按需组合。比如iMessage不需要群组能力就不实现,某些内部渠道不需要@提及也可以跳过。避免了传统大接口模式下一堆空方法和UnsupportedOperationException 问题。
第三层:能力声明
每个渠道适配器带一个capabilities(能力声明),告诉系统”我支持什么”:能不能发图片、能不能发语音、支不支持Markdown。上层根据能力自动降级,比如遇到不支持图片的渠道就自动转成文字描述。这比在业务逻辑里写if(channel='telegram')优雅得多。
OpenClaw 的ChannelPlugin设计
ChannelPlugin接口在src/channels/plugins/types.plugin.ts里,设计得非常讲究。
它把一个渠道拆成了几个维度:
1)id 和meta负责标识,告诉系统“我是谁”。
2)capabilities做能力声明,上层可以根据能力决定行为,不支持图片的渠道自动降级成文字描述。
3)outbound负责发消息,gateway负责收消息,这两个是核心。
4)status做审计,groups管群组行为,mentions处理@,agentTools注入渠道特有的Agent工具。
5)config做配置解析和校验,每个渠道的配置格式不一样,这里统一处理。
新增一个渠道的成本非常低,实现对应的adapter然后一行注册就完事
api.registerChannel({ plugin: bluebubblesPlugin });
不同渠道消息格式差异很大,你怎么设计这个统一的消息模型,既能统一又不丢信息?
开闭原则的应用:对扩展开放,对修改关闭,新增渠道特有字段不需要改核心定义。[尽量不修改已有的、经过测试的代码。修改旧代码容易引入新的Bug(回归错误)]
核心字段(各渠道共性)+扩展字段,上层处理链路只读核心字段,保持简洁;渠道adapter在出站时从扩展字段还原渠道原生格式,不丢信息。
如果某个渠道API做了Breaking Change,比如Slack废弃了一个事件类型,怎么控制影响范围?
这正是适配器模式的核心价值:变更隔离。影响范围被锁死在对应的Slack adapter里,只要adapter内部修改,上层完全无感。
限流策略因渠道而异(如Telegram全局限流、Discord按channel限流),如何设计以避免逻辑污染?
限流必须下沉到各ChannelAdapter内部实现,而非放在统一层。每个adapter根据自身渠道约束(维度、窗口、配额)独立部署令牌桶或滑动窗口限流器,并在outbound方法中主动控制发送节奏。上层只调用send()接口,超限由adapter自行排队、重试或返回错误,体现单一职责原则和
变更隔离。
多智能体协作
工作区、记忆与会话状态:理解“隔离”的真实边界
路由把消息收敛到正确的智能体后,真正决定“它看到什么、写到哪里”的是工作区与状态目录。根据官方 FAQ,OpenClaw 的长期记忆本质上就是工作区里的 Markdown 文件,而会话历史与运行状态则保存在 $OPENCLAW_STATE_DIR(默认 ~/.openclaw)下的每个智能体目录中。
~/.openclaw/ # 状态目录(默认)
├── agents/
│ ├── main/
│ │ └── sessions/
│ └── work/
│ └── sessions/
└── credentials/
~/.openclaw/workspace-main/ # main 智能体工作区
├── AGENTS.md
├── MEMORY.md(长期记忆)
└── memory/(daily notes)
└── 2026-03-22.md
~/.openclaw/workspace-work/ # work 智能体工作区
├── AGENTS.md
├── MEMORY.md
└── memory/
└── 2026-03-22.md有关MEMORY.md和memory文件夹下的区分在~/.openclaw/workspace/AGENTS.md中有说明
这意味着多智能体“隔离”至少有两层:
1.工作区隔离:每个智能体可配置独立 workspace,其 AGENTS.md、MEMORY.md、memory/YYYY-MM-DD.md 等文件彼此独立。
-
文件污染(File Contamination)
-
数据越权访问(Data Leakage)
-
工具副作用(Side Effects)写文件、修改数据库、调用外部 API,副作用跨 agent 传播
-
可复现性:没有隔离,同一个任务多次执行结果不同,难以 debug
工作区需要根据协作模式决定是“完全隔离”还是“部分共享”(物理协同)。
如果不共享,协作将无法进行(数据孤岛)。在一个具体的协作任务中,底层的执行沙箱应该是一个整体。A 生成文件落盘,B 直接从同一个路径读取文件运行测试。
WorkSpace≠SandBox
要强调一个容易误解的点:工作区不是硬沙箱。官方 FAQ 明确指出,工作区只是默认 cwd 和记忆锚点;如果没有开启沙箱,工具依然可以访问宿主机上的其他绝对路径。因此,多智能体环境里要把“路径分离”和“安全隔离”分开看待:
-
路径分离:路由与
workspace只决定"当工具使用相对路径(如./data/file.txt)时,从哪里开始找"——仅此而已。不阻止工具访问/etc/passwd这样的绝对路径。它们仍然可以通过绝对路径互相读取对方的文件,因为底层没有任何操作系统级别的隔离 -
安全隔离:agents.defaults.sandbox或每个智能体sandbox配置才解决“能否越界访问”的问题。当沙箱启用且 `workspaceAccess` 不是 `"rw"` 时,工具在 `~/.openclaw/sandboxes` 下的沙箱工作区中运行,而非宿主机工作区。
2.会话状态隔离:每个智能体的会话历史、会话元数据与运行状态存放在 ~/.openclaw/agents/<agentId>/sessions/ 下,不会混写到别的智能体名下。
-
防上下文污染
-
防推理链泄漏(Chain-of-Thought Leakage)否则可能导致 prompt injection 横向传
工程建议是把这三件事始终一起设计:先用绑定确定所有权,再用独立工作区分离记忆与提示文件,最后用沙箱和工具策略把跨目录、跨工具、跨会话的越界路径堵住。
OpenClaw自我进化的闭环
对话开始
→ 加载 workspace 所有核心md文件到 system prompt
→ agent 根据用户问题,先 memory_search 检索相关记忆(0.7向量+0.3关键词混合检索)
→ agent 执行任务
→ 任务中学到新东西 / 犯了错 / 发现了用户新偏好
→ agent 写回相关文件(AGENTS.md / USER.md / memory/*.md / MEMORY.md)
→ 文件变更触发 Memory 索引重建(SQLite FTS5 + 向量索引)
→ 对话结束
下次对话开始
→ 加载更新后的 md 文件
→ 搜索到新索引的记忆
→ agent 行为更精准
→ 循环
注意这里面有两层循环:
- 外层循环:md 文件读写。 每次对话加载,对话中更新。这是"经验"层面的积累——agent 知道了哪些事该做、哪些事不该做、你喜欢什么、你的环境是什么样的。
- 内层循环:向量索引检索。 当 memory 文件越来越多,agent 不可能把所有内容都塞进 prompt(有 token 限制),所以 OpenClaw 用 SQLite 的 FTS5 全文搜索和 sqlite-vec 向量检索做了一个混合搜索引擎。agent 每次对话前被指令要求先搜索相关记忆再回答,这样即使积累了几百个 memory 文件,也能精准找到相关的信息。
两层循环合在一起,就是一个完整的"学习-记忆-检索-应用"系统。而这个系统的存储介质,全是 md 文件
具体检索方式的实现见《SQLite中的向量检索和关键词检索》
新场景设计分析
1.如果要给OpenClaw新增一个微信渠道,大概要改哪些地方?
只需要在Channel层新增一个微信插件,实现消息收发的协议转换接口,把微信的XML消息格式转成OpenClaw内部的统一消息结构,再把回复转回微信格式。Gateway往下的所有组件都不用动,这就是分层的好处。只需要实现ChannelPlugin接口(src/channels/plugins/types.plugin.ts),它采用adapter模式,按能力拆分为messaging(消息收发)、outbound(外发)、streaming(流式输出)、gateway(网关集成)等多个适配器,按需实现可选能力。提供唯一id和meta;声明capabilities;实现inbound(将WhatsApp Webhook消息归一化为MsgContext)和outbound(将MsgContext转为WhatsAppCloud API请求);完成config解析。最后调用api.registerChannel(plugin: whatsAppPlugin)一行注册,无需改动任何核心代码。
2.如果一个用户同时在Telegram和Discord上跟同一个Agent 对话,上下文怎么打通?
如果要打通,需引入‘跨渠道身份映射服务’:1)统一内部用户ID(把不同渠道的用户ID关联到同一个内部用户标识如UUID);2)映射表存储各渠道用户ID→内部ID的双向关系(如Telegram:123→user_abc,DingTalk:456→user_abc);3)会话管理器按内部ID而非渠道ID查找/创建上下文。该服务需独立部署、高可用,并支持映射关系的异步同步与冲突消解。如果不需要打通,每个渠道独立维护会话就行,实现更简单也更安全。OpenClaw目前选择的是按渠道隔离,每个渠道有独立的会话上下文,这在大多数场景下是更合理的默认行为。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)