
SLV 原生多语言支持的工程实现 —— 把语言抽象成 Solana 节点运维与 AI Agent 配置的一等公民
开源 Solana 开发工具 SLV 在 v2026.4.13.1648 中加入了原生多语言支持。本文从工程角度梳理这一特性的设计:把语言抽象成运维 pipeline 的一等配置项,让 onboarding wizard 与 AI Console 都以所选母语运行,同时保留 Solana 专有名词、code block 与配置 key 的英文字面量。预设 5 种语言加 free-form Othe

开源 Solana 开发工具 SLV 在版本 v2026.4.13.1648 中加入了原生多语言支持。本文从工程角度梳理这一特性的设计动机、实现要点,以及它与 validator 运维、AI agent 协作两个场景的耦合方式。
一、为什么把语言抽象成一等公民
Solana validator 运维是高度依赖文档与命令行交互的工作。常见的工作流——升级 validator binary、配置 Geyser gRPC、调整 Shredstream pipeline、迁移 node、回放 ledger——每一步都伴随大量术语、配置 key 与排错对话。
在 English-first 的工具链里,operator 的母语和工具的输出语言之间存在持续的认知翻译开销。对非英语母语用户而言,这个开销在两个环节最明显:
- 理解 AI agent 的解释:当 agent 解释一段 Geyser 配置或 Shredstream 缓冲行为时,母语阅读的语义带宽通常比第二语言高出一个量级。
- 表达自己的意图:在出错状态下,operator 需要能精确描述现象并连续追问。母语能让追问形成一个连贯的诊断闭环。
SLV 的多语言支持就是把语言作为运维 pipeline 的第一类配置项,而不是 UI 层的本地化字符串表。
二、五种预设语言加 “Other” 的设计

onboarding wizard 的第一步即为语言选择,预设五种:英语、日语、中文、俄语、越南语。选择 Other 后可输入任意语言名称,进入 free-form 模式。
预设语言不是按市场规模拍板,而是基于实际 Discord 沟通日志与 operator 共享截图中的 OS / terminal 设置统计而来。这种 data-driven 的 preset 选择避免了「假装支持却没有真实用户」的问题——五种预设都对应着已存在的活跃 operator 群体。
free-form Other 模式的存在则让长尾语言不被截断。任何在 onboarding 时输入的语言名称会原样作为后续 prompt 的语言指令注入,让 LLM 端去处理具体的语言生成。
三、配置如何贯穿到 AI Console

onboarding 阶段确定的语言并不只作用于 wizard 文本,而是会作为持久化配置写入 SLV config,并在 AI Console 启动时作为 system prompt 的一部分注入到与 LLM 的会话中。
这意味着以下场景都会以所选语言运行:
- agent 对每一步操作的解释与确认 message
- 安全提醒与 destructive operation 的二次确认
- 运维结束后的结果汇总与下一步建议
而需要保留英文的内容会被显式排除:
- code block 内容一律保持原样
- Solana 生态的专有名词(validator、Geyser gRPC、Shredstream、SWQoS、Shred、Slot 等)按上下文保留英文
- 配置文件 key、命令行参数、错误码字面量原样输出
这样做的目的是在母语阅读体验和技术准确性之间取得平衡。术语的统一性对 operator 之间的协作以及与上游文档对齐都至关重要,强行翻译反而增加学习成本。
四、本地模式与远程管理模式的一致性
SLV 同时支持两种部署方式:直接 ssh 到 node 上运行的本地模式,以及通过 Ansible 统一管理多 node 的远程模式。
多语言配置在两种模式下行为一致:
- 本地模式:语言设置存储在该 node 的 SLV config 中,AI Console 启动时自动应用。即便从 smartphone 的 ssh client 连接,也会立刻进入母语对话。
- 远程模式:management node 上的 SLV config 持有语言设置,对每个被管 node 发起 agent 会话时都会传递该设置。这避免了在多 node 环境下重复配置的繁琐。
对 fleet operator 而言,这种一致性意味着可以以「人」为单位定义语言偏好,而不是以「机器」为单位。
五、移动端运维与多语言的叠加效应
只要 smartphone 安装了 ssh client,operator 就能完成完整的 validator 运维流程:连接 node → 启动 AI Console → 用自然语言对话执行升级、迁移、排障。
在移动端引入母语对话后,门槛会进一步降低。一台手机加母语,意味着:
- node 出现告警时可以立刻用母语描述现象并请 agent 协助诊断
- 不需要在小屏幕上切换输入法或反复查英文术语
- bot 开发、Pump.fun 监听、自动买卖等 Solana 应用层任务也能在移动端用对话方式推进
移动设备的输入效率本来就低,让语言通道贴近 operator 的母语,会显著改善移动端工作流的实际可用性。
六、对网络层面的意义
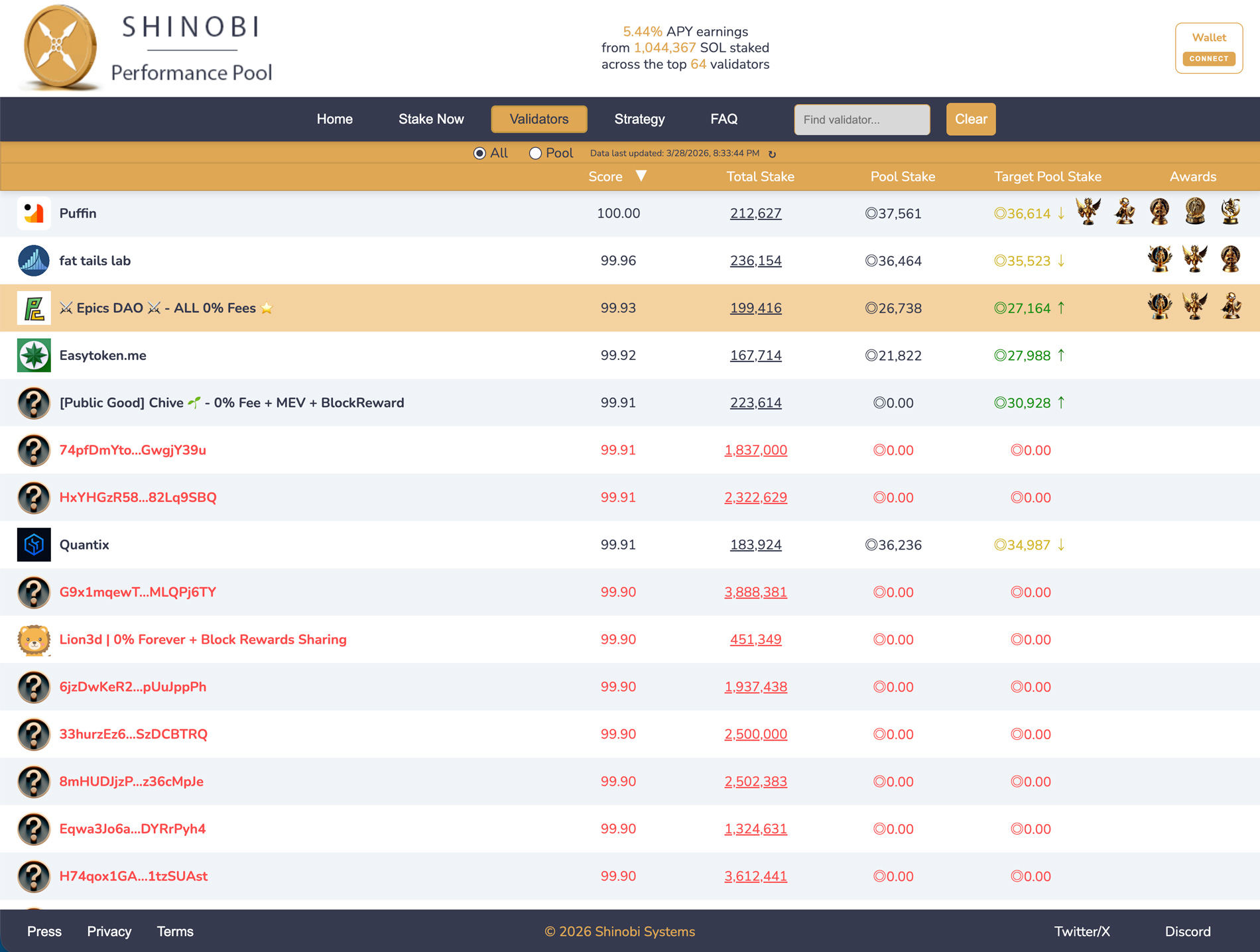
Solana 是分布式网络,整体性能取决于每个 validator 的运行质量与全球分布的均衡程度。Epics DAO validator 在 Shinobi Performance Pool 中以 99.93 分位列全球第 3,背后的运维知识被沉淀为 SLV 的 skills 模块。
母语化对网络层的意义不在于个体便利,而在于:
- 降低操作错误率:母语阅读 destructive operation 的确认提示,误操作概率明显低于第二语言。
- 拓宽地理分布:原本因语言门槛被排除在外的 operator 能够加入,validator 集合的地理多样性提升。
- 加快事故响应:母语通道下排障速度更快,对网络的弹性恢复有正向贡献。
去中心化网络的健壮性是统计意义上的均值与方差问题,多语言支持是把这个分布的「左尾」往右拉的工程手段之一。
七、配置持久化与切换
语言设置作为 SLV config 的一部分被持久化,不需要每次启动重新选择。后续切换也只是一次配置修改,无需重建会话历史或重新 onboarding。
这对团队场景尤为重要:同一个 management node 可以容纳多个 operator profile,每个 profile 持有自己的语言偏好,团队成员协作时不必互相迁就。
八、可观察的工程取舍
把语言抽象到 config 层而非纯 UI 层带来一个明显的取舍:模型端的 generation 必须稳定支持多种语言。SLV 通过以下设计来缓解:
- prompt 模板与 skills 描述用英文维护,但 agent 输出层接管语言
- 专有名词词表作为 system prompt 的固定段落,确保术语统一
- 错误信息的原始字符串保留,避免被翻译后失去 grep 价值
这种「输入端英文 / 输出端母语 / 关键字面量原样」的三层结构是当前实现的核心约束。
九、开源与可复现性
SLV 本体仍以开源形式发布在 GitHub(仓库名 validatorsDAO/slv),原生多语言支持的代码与 prompt 设计都包含在内。任何 operator 都可以自行 fork 并在本地模型上复现这一工作流。
对希望在内部模型上做类似多语言抽象的团队,这份实现可以作为一个参考起点:尤其是 system prompt 中术语保留段的写法,以及 onboarding wizard 与 AI Console 之间的 config 传递方式。
十、小结
SLV 的原生多语言支持把「使用母语」从 UI 本地化提升为运维 pipeline 的一等配置项。在 validator 运维、AI agent 协作、移动端工作流三个维度上,它降低了非英语母语 operator 的认知开销,并对整个 Solana 网络的去中心化分布带来正向影响。
对工程实现感兴趣的读者,可以在 SLV 仓库的 onboarding 模块与 AI Console prompt 模板中找到具体代码。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)