
【杂谈】面试官:你了解Agent、OpenClaw、Harness吗? 我:当然(还好我看了这篇文章)
提示工程学习笔记 - aneasystone's blog要理解多智能体,首先要搞懂单智能体的核心逻辑。Agent 的本质是模拟人类的自主行为模式—— 它接收用户需求,自主进行思考、规划行动,执行任务后接收反馈,形成闭环。而其中最核心、最具落地性的范式,就是 ReAct Agent。ReAct Agent 的核心:思考 - 执行 - 观察闭环ReAct 范式奠定了单智能体的运行逻辑,也是所有复杂智
内容整合于网络、B站
1、LLM
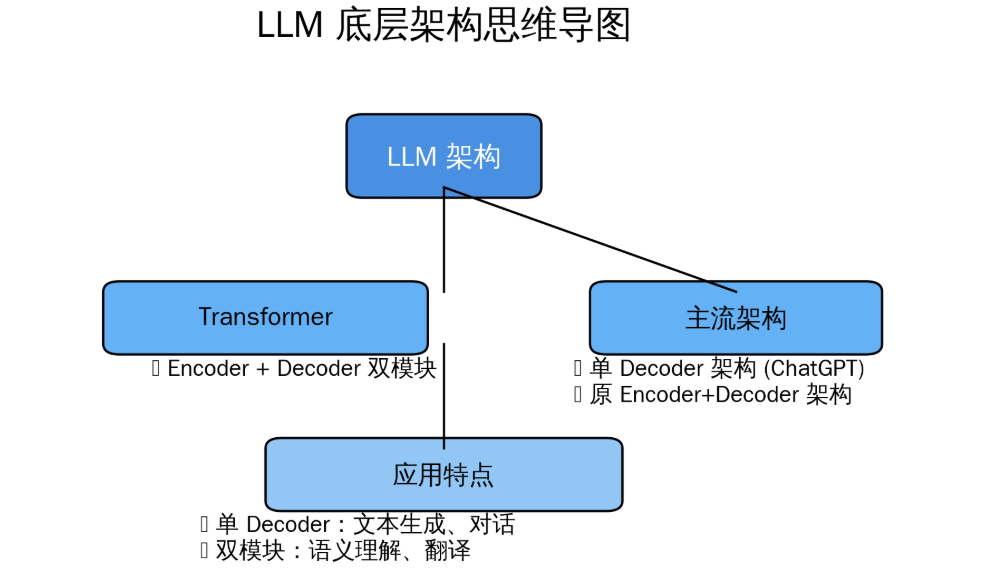
谈到人工智能大模型(LLM),就绕不开其核心底层架构——Transformer。作为LLM的技术基石,Transformer 最初采用的是「编码器(Encoder)+ 解码器(Decoder)」的双模块架构,两个模块协同工作,分别负责输入信息的编码处理与输出内容的生成,为早期大模型的语义理解和文本生成能力提供了核心支撑。
这种双模块架构在很长一段时间内是行业主流,直到 OpenAI 带来了突破性尝试:他们移除了 Transformer 中的编码器模块,仅保留解码器模块,基于这一简化架构推出了 ChatGPT。令人意外的是,单解码器架构不仅大幅降低了模型的复杂度和训练成本,还在对话生成、连续文本创作等场景中展现出更优的性能和灵活性。
ChatGPT 的成功打破了行业对双模块架构的固有认知,众多科技公司纷纷跟进模仿这一思路。久而久之,目前LLM领域的主流架构逐渐固化为两种:一种是保留传统优势的「编码器+解码器」双模块架构,适用于需要强语义理解的场景;另一种则是更适配生成式任务的「单解码器」架构,成为对话式AI、文本生成类大模型的首选。
2、Prompt Engineering->微调->RAG
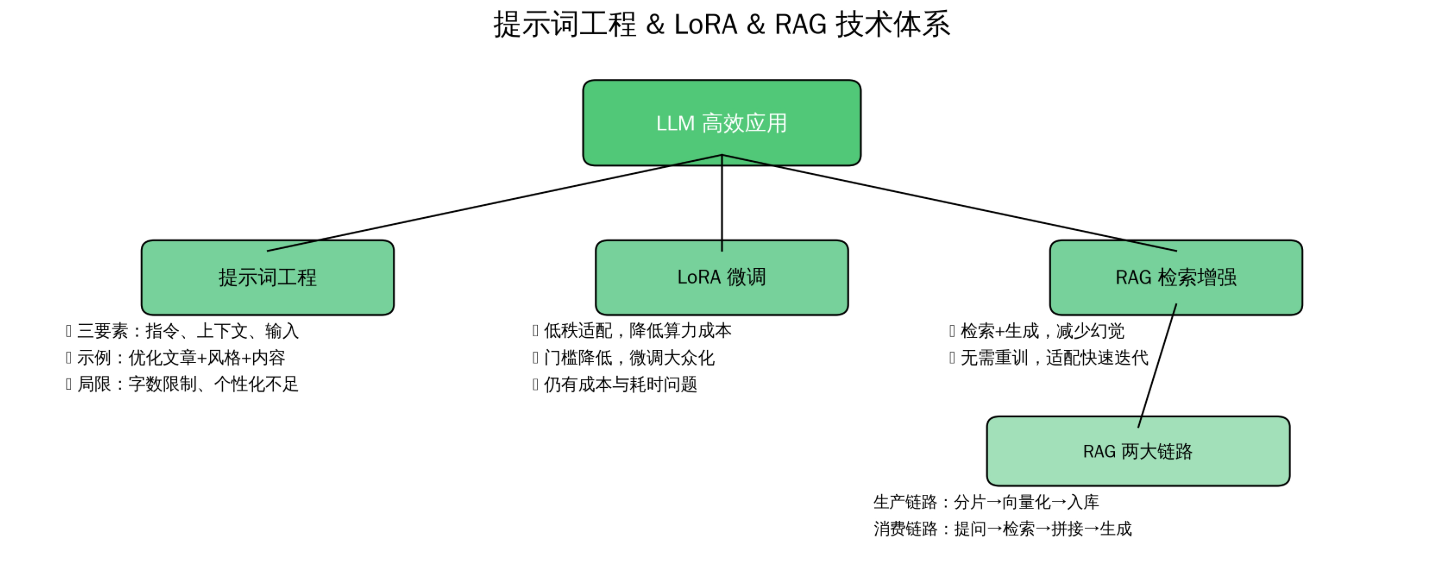
除了底层架构,提示词工程也是解锁LLM能力的关键,甚至可以称之为一门“技术艺术”——相同的需求,不同的提示词设计,最终反馈的结果可能天差地别。通常来说,一个优质的提示词可拆解为三个核心部分:指令(明确告知模型要做什么)、上下文(为模型提供必要的背景信息)、输入(需要模型处理的具体内容)。
举个直观的例子:“你是一名善于进行博客创作的技术专家,请你帮我优化下面文章内容:内容为XXX,风格参考过往笔记内容:XXXX”,这句话中,“优化文章内容”是指令,“风格参考过往笔记”是上下文,“XXX(具体文章内容)”是输入,三者结合能让模型更精准地贴合需求。但提示词存在天然的字数限制,仅靠提示词优化,难以充分适配不同场景的个性化需求,因此行业开始探索更高效的模型调优方案。
LoRA(Low-Rank Adaptation)相关论文的推出,率先解决了这一痛点——它成功破解了大模型微调过程中的算力紧张难题,大幅降低了微调的时间成本和硬件门槛,让原本高门槛的大模型微调技术真正走入大众视野,成为企业和开发者适配大模型的重要选择。
尽管LoRA大幅降低了微调成本,但对于多数中小团队而言,微调的成本和耗时依然偏高;再加上大模型行业发展迅猛,各大科技公司的模型版本迭代速度极快,如何在控制成本的同时,快速适配不同公司的大模型、复用已有知识,成为新的行业痛点。而RAG(检索增强生成)技术的出现,恰好给出了完美解决方案。
简单来说,RAG即检索增强生成技术,核心是通过“检索+生成”的结合,让大模型在生成回复时,能结合外部知识库的精准信息,既避免了模型“幻觉”,又能快速复用已有内容。其核心流程分为两大链路:生产链路和消费链路。生产链路的核心是将目标文档进行分片处理,再通过向量化技术转化为向量数据,存储到向量数据库中;消费链路则是当用户提出问题时,先根据用户提示词去向量数据库中检索相关的向量信息,将检索到的内容与用户问题拼接成完整上下文,再发送给大模型,最终由大模型生成精准、有依据的回复。
3、Function Calling->MCP
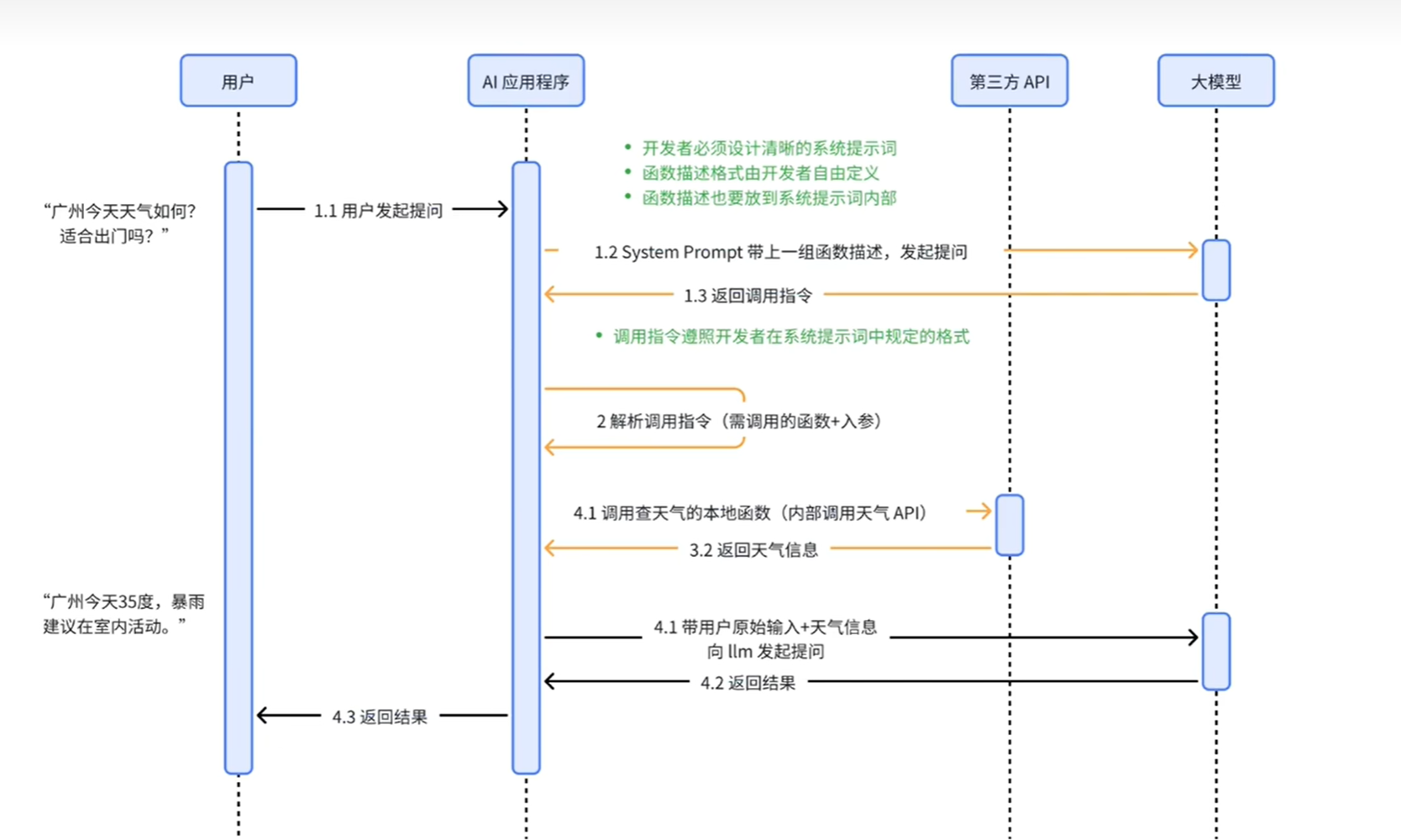
但是早期的大模型普遍存在一个局限:仅能完成基础的问答对话任务,不具备主动调用外部工具的能力,难以应对复杂的实际应用场景。而大模型工具调用能力的落地(Function Calling),打破了这一局限:大模型会根据用户提示词,判断并反馈完成任务所需的工具;应用程序接收该反馈后,解析并调用对应的外部服务,再将工具返回的相关信息与用户原始数据拼接整合,最终反馈给大模型,由大模型生成完整、精准的回复,实现“问答+工具”的协同闭环。
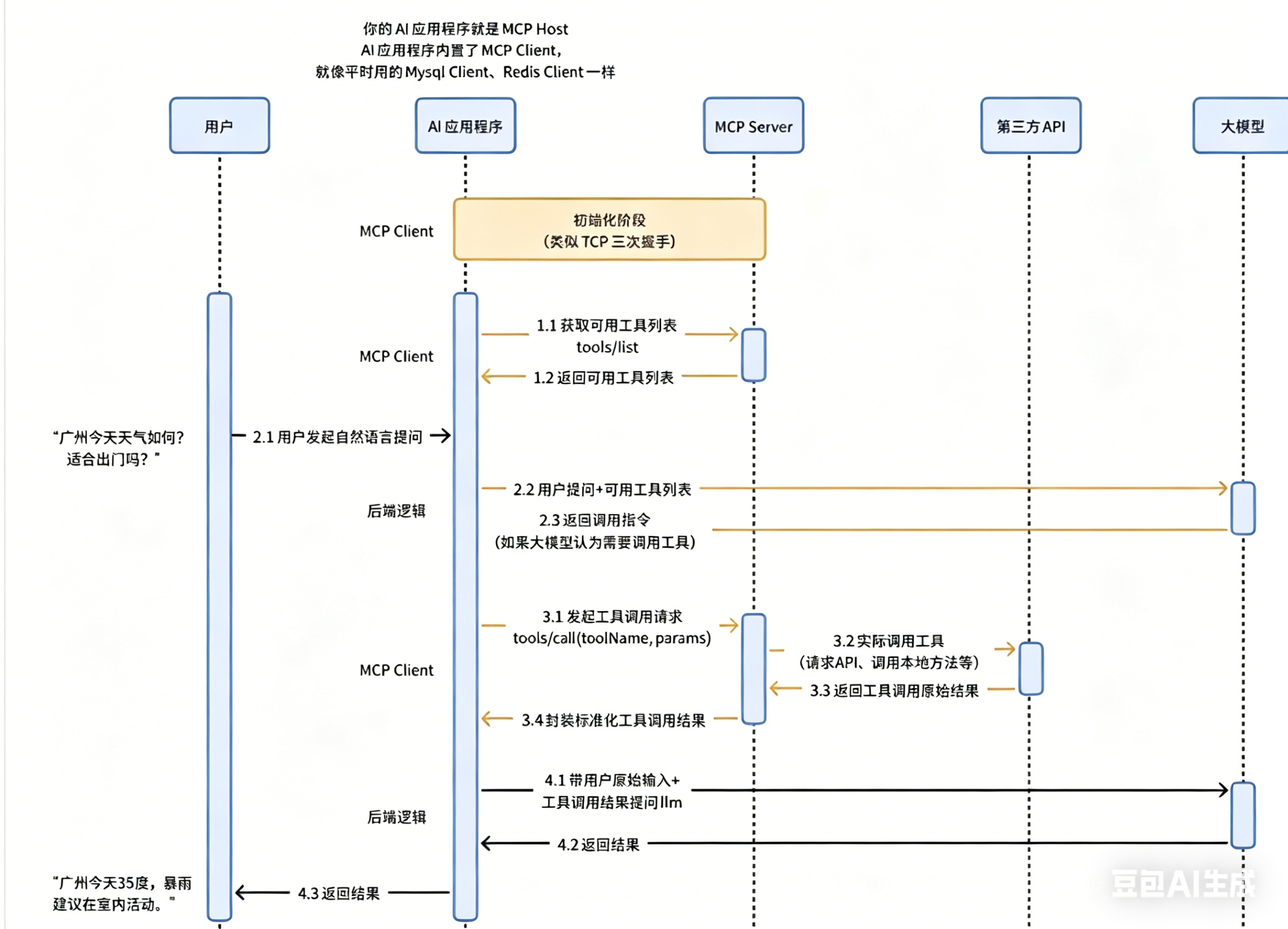
而 MCP(Model Control Protocol)协议的出现,进一步优化了大模型工具调用的体验。它是一种统一的调用协议,核心价值在于“简化调用流程、实现标准化适配”——开发者无需关注具体的 API 调用细节,只需遵循 MCP 协议规范,将 API 调用的具体操作交给 MCPServer 处理,就能快速实现大模型与各类外部工具、服务的对接,大幅降低了大模型工具调用的开发成本和适配难度。
4、Agent->Multi Agent
要理解多智能体,首先要搞懂单智能体的核心逻辑。Agent 的本质是模拟人类的自主行为模式—— 它接收用户需求,自主进行思考、规划行动,执行任务后接收反馈,形成闭环。而其中最核心、最具落地性的范式,就是 ReAct Agent。
ReAct Agent 的核心:思考 - 执行 - 观察闭环
ReAct 范式奠定了单智能体的运行逻辑,也是所有复杂智能体的基础:
- 思考(Reasoning):接收用户需求后,Agent 先拆解目标、规划步骤。比如用户说 “帮我写一篇技术博客并配图”,Agent 会先思考:“先确定博客主题→梳理技术框架→搜集素材→生成内容→调用工具绘图”。
- 执行(Acting):根据思考的规划,调用外部工具 / 服务落地动作。比如调用大模型生成博客正文、调用绘图工具生成思维导图、调用搜索引擎补充技术资料。
- 观察(Observation):接收工具返回的结果,判断是否达成阶段目标。如果生成的博客框架不完整,就重新调整思考路径;如果配图成功,就进入下一步。
这个 “思考 - 执行 - 观察” 的循环,让单 Agent 能独立完成从需求到交付的全流程,也是之前提到的 Function Calling、MCP 协议的核心应用场景 —— 单 Agent 通过标准化工具调用,把 “工具能力” 转化为 “自身执行力”。
但单 Agent 的局限性也很明显:单一目标下效率尚可,多目标、跨领域的复杂任务会力不从心。比如同时处理 “技术写作 + 数据统计 + 客户沟通”,单 Agent 会陷入任务混乱;而多智能体系统,就是通过 “分工协作” 解决这个问题。
多智能体系统,本质是多个具备独立能力的 Agent 组成的协作网络—— 每个 Agent 专注于特定领域 / 任务,通过交互、分工、协同,共同完成单 Agent 难以搞定的复杂目标。
| 维度 | 单 Agent | Multi-Agent |
|---|---|---|
| 能力边界 | 单一领域、单任务序列 | 多领域协同、多任务并行 |
| 决策模式 | 自主决策、独立执行 | 分布式决策、交互协商 |
| 容错性 | 单点故障导致任务失败 | 分工明确,局部故障不影响整体 |
| 适用场景 | 简单工具调用、基础问答 | 复杂项目协作、多角色任务、大规模优化 |
多智能体的核心优势,在于 “术业有专攻”+“协作提效”:
- 分工专业化:把复杂任务拆解为多个子任务,每个 Agent 负责一个子领域。比如项目协作中,“技术专家 Agent” 负责梳理技术框架、“写作 Agent” 负责生成内容、“绘图 Agent” 负责制作图表、“审核 Agent” 负责内容校对,比单 Agent “样样懂一点” 效率更高、质量更好。
- 交互智能化:Agent 之间通过消息传递、目标协商,实现高效联动。比如 “写作 Agent” 生成初稿后,会主动发送给 “审核 Agent”,“审核 Agent” 反馈修改意见,两者反复迭代,直到内容达标。
- 抗风险能力强:如果单 Agent 执行出错,其他 Agent 可及时补位;而多智能体中,每个 Agent 的职责明确,局部问题不会导致整体任务崩盘。
5、上下文工程
在大模型 Agent(尤其是 ReAct 范式的多轮循环执行)中,上下文工程(Context Engineering) 是决定系统稳定性、效率与效果的隐形核心。随着 Agent 不断执行「思考 - 执行 - 观察」的循环,会持续产生大量上下文关联数据 —— 用户提问、工具调用记录、返回结果、历史对话等,而大模型的上下文窗口是有限的,注意力机制也会因过长上下文出现「信息稀释」「重点丢失」的问题。因此,对上下文进行科学编排与管理,是 Agent 从「能跑通」到「跑的稳、跑的快」的关键一步。
上下文工程的核心目标与编排原则
1. 三大核心目标
上下文工程不是简单的「删内容」,而是围绕 Agent 任务目标的精准管理:
- 窗口适配:在不丢失关键信息的前提下,将上下文长度控制在模型窗口内,避免溢出;
- 注意力聚焦:通过编排让模型的注意力集中在当前任务的核心信息上,减少冗余干扰;
- 循环可持续:支持 Agent 多轮循环执行,保证长期任务中上下文的一致性与可追溯性。
2. 四大编排核心原则
- 目标导向:所有上下文操作都围绕「完成用户核心需求」展开,只保留与当前任务强相关的信息;
- 分层管理:将上下文分为「核心常驻信息」(如用户原始需求、系统提示词)、「阶段动态信息」(如当前工具调用结果)、「历史归档信息」(如已完成的步骤),分层处理;
- 最小冗余:对工具返回结果做摘要、结构化、去重,只保留模型推理需要的关键数据;
- 可追溯性:即使压缩历史上下文,也要保留关键步骤的索引,支持回溯与纠错。
6、Agent Skill
在复杂的 Multi-Agent 系统与长周期 ReAct 循环执行中,Agent 往往具备数十甚至上百种工具调用能力(Skill)。若每次循环都全量加载所有技能详情,不仅会严重挤占上下文窗口,还会导致模型注意力稀释,降低执行效率。渐进式披露(Progressive Disclosure) 作为一种成熟的上下文管理范式,通过 “按需加载、分层暴露” 的方式,完美解决了 “能力丰富性” 与 “上下文紧凑性” 的矛盾,成为 Agent Skill 管理的标配方案。
在传统的 Agent 设计中,为了保证任务不遗漏,习惯会在系统提示词(System Prompt)中全量罗列所有技能的详细说明。这种方式存在两个致命缺陷:
- 上下文溢出:即使是中等规模的技能库,全量文档也会轻松占用 2k-4k 的上下文,导致核心需求、历史结果被挤压,触发窗口溢出风险。
- 推理噪音:模型会被无关的技能描述干扰,在决策时 “想太多”,甚至出现幻觉调用不相关工具,导致执行效率低下。
而 渐进式披露 的核心逻辑正是:让 Agent 像人类学习一样,先知道 “有什么”,需要时再知道 “怎么做”,最后才获取 “具体细节”。这分为三个阶段,层层递进:
1. 发现(Discovery):轻量启动,只知 “名” 与 “意”
-
操作:Agent 启动时,仅加载所有技能的名称(Skill Name)和极简描述(Brief Description)。
-
上下文状态:此时上下文非常轻盈,仅保留核心元信息。
-
目的:让 Agent 快速建立技能地图,建立全局认知,知道自己具备哪些能力,以便在后续规划中初步判断是否需要调用。
2. 激活(Activation):匹配加载,读懂 “说明书”
-
操作:当 Agent 经过推理(Reasoning)判定当前任务需要调用某类技能时,触发加载机制,读取该技能对应的
SKILL.md或详细配置文件。 -
上下文状态:此时仅临时插入该技能的完整操作规范、入参要求、返回格式说明。
-
目的:确保 Agent 在执行前掌握所有必要规则,避免因信息不足导致调用失败。
3. 执行(Execution):按需引入,获取 “执行体”
-
操作:在确认具体执行逻辑时,根据需要加载关联的代码片段(Binding Code)、引用文件或第三方服务凭证。
-
上下文状态:仅保留当前执行所需的最小必要代码 / 数据,执行完毕后可自动清理。
-
目的:实现真正的 “按需取用”,杜绝长期占用上下文。
7、OpenClaw
OpenClaw 是一款面向大模型 Agent 的开源通用工具调用框架,核心定位是“降低 Agent 工具调用的开发门槛,实现多工具、多场景的快速适配”。不同于单一工具的调用封装,OpenClaw 提供了一套标准化的工具注册、调度与执行体系,完美适配 ReAct 范式的“思考-执行-观察”循环,同时兼容 MCP 协议,可与多 Agent 系统无缝集成。
其核心优势在于“通用性”与“灵活性”:一方面,它支持主流大模型(GPT、Claude、通义千问等)的快速接入,无需针对不同模型单独开发适配代码;另一方面,它提供了丰富的工具模板,涵盖搜索、数据处理、API 调用、文档生成等常见场景,开发者只需简单配置,即可让 Agent 具备对应工具能力。此外,OpenClaw 还支持自定义工具扩展,满足企业级场景的个性化需求,目前已成为中小团队搭建 Agent 工具调用模块的首选框架之一。
具体面试相关我会后面再写一篇文章
8、Harness Engineering
随着 Agent 从单智能体走向 Multi-Agent 系统,复杂度呈指数级提升,如何实现 Agent 行为的可监控、可追溯、可优化,成为工程化落地的核心痛点——这正是 Harness Engineering(工程化治理)所要解决的问题。Harness Engineering 并非单一技术,而是一套围绕 Agent 全生命周期的工程化管理体系,核心目标是“让 Agent 系统从‘能跑通’走向‘可运维、可迭代’”。
其核心模块包括三个方面:
一是行为监控,实时跟踪 Agent 的思考轨迹、工具调用记录与执行结果,及时发现异常行为(如无效工具调用、推理偏差);
二是链路追溯,将 Agent 每一轮的“思考-执行-观察”数据归档,支持问题回溯与故障定位;
三是迭代优化,基于监控数据与用户反馈,对 Agent 的提示词、技能配置、协作规则进行持续调优。结合上下文工程与渐进式披露范式,Harness Engineering 可进一步提升 Agent 系统的稳定性与执行效率,是企业级 Multi-Agent 系统落地的必备工程化能力。
9、ClaudeCode 源码泄露
近期,Anthropic 公司旗下 Claude 模型的相关源码(ClaudeCode)发生泄露事件,引发行业广泛关注。此次泄露的源码主要涉及 Claude 模型的部分推理逻辑、工具调用适配代码,以及部分安全校验机制,虽未包含模型核心训练参数,但仍对行业的大模型安全与合规敲响了警钟。
从技术层面来看,此次泄露事件暴露了大模型工程化落地中的安全漏洞——即使是头部企业,在源码管理、权限管控上也存在疏忽,而源码泄露可能导致恶意开发者模仿 Claude 的核心逻辑,搭建仿冒模型,甚至利用漏洞规避安全校验,生成违规内容。从行业影响来看,此次事件进一步推动了大模型行业的安全合规建设,促使企业加强源码加密、权限分级管理,同时也让开发者意识到,在依赖开源工具、借鉴头部模型技术的同时,需注重安全风险防控,避免因源码泄露、技术滥用引发合规问题。此外,该事件也间接推动了大模型技术的透明化讨论,平衡技术创新与安全合规的关系,成为行业健康发展的重要议题。
后续相关面试内容我会再写一篇笔记

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)