
零成本“养虾”攻略:本地部署 Qwen3.5 & Gemma 4,把大模型装进 WorkBuddy
模型部署好后,需要告诉 WorkBuddy 如何找到它。WorkBuddy左侧-claw设置-模型-添加模型关键配置说明。
·
零成本养虾,在本地零成本部署 Qwen3.5 和 Gemma 4 大模型,并将其连接到 WorkBuddy 中使用,主要分为三个步骤:首先使用 Ollama 部署模型,然后在 WorkBuddy 中配置自定义模型,最后进行连接验证。
🦙 第一步:使用 Ollama 部署本地模型
Ollama 是一个便捷的工具,可以帮你轻松下载、管理和运行开源大模型。
-
安装 Ollama,安装教程可以看上篇教程。也可以直接在WorkBuddy 对话框输入
-
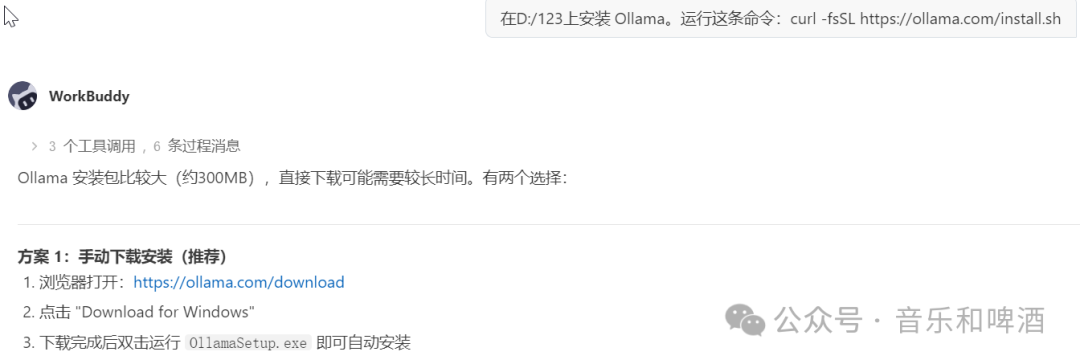
- 安装成功后,菜单栏右上角会出现一个 🦙 图标,表示 Ollama 已在后台运行。
- 下载并运行模型
-
运行 Qwen3.5 (7B 版本):适合大多数电脑,对硬件要求相对较低。
-
ollama run qwen3.5:4b-q4_K_M -
****运行ollama run qwen3.5(9B版本):约 6.6GB,适合高配电脑,对硬件要求相对较高。
ollama run qwen3.5:latest -
运行 Gemma 4 (26B MoE 版本):这是一个混合专家(MoE)模型,推理速度更快,显存占用更低,但整体性能强大。
ollama run gemma4:26b-moe
 - 在终端中,你可以根据需求选择并运行模型。如果没有成功可以多重复几次。
- 在终端中,你可以根据需求选择并运行模型。如果没有成功可以多重复几次。
- 运行命令(同样可以直接在WorkBuddy对话框输入运行)时,Ollama 会自动下载模型文件。下载完成后,你就可以在终端里直接与模型对话了。完成后记得在这里,是模型的选项:

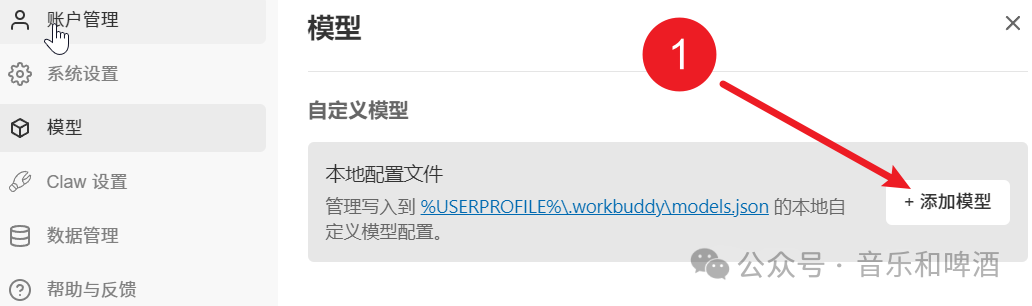
⚙️ 第二步:在 WorkBuddy 中配置自定义模型
模型部署好后,需要告诉 WorkBuddy 如何找到它。
WorkBuddy左侧-claw设置-模型-添加模型
- 关键配置说明:
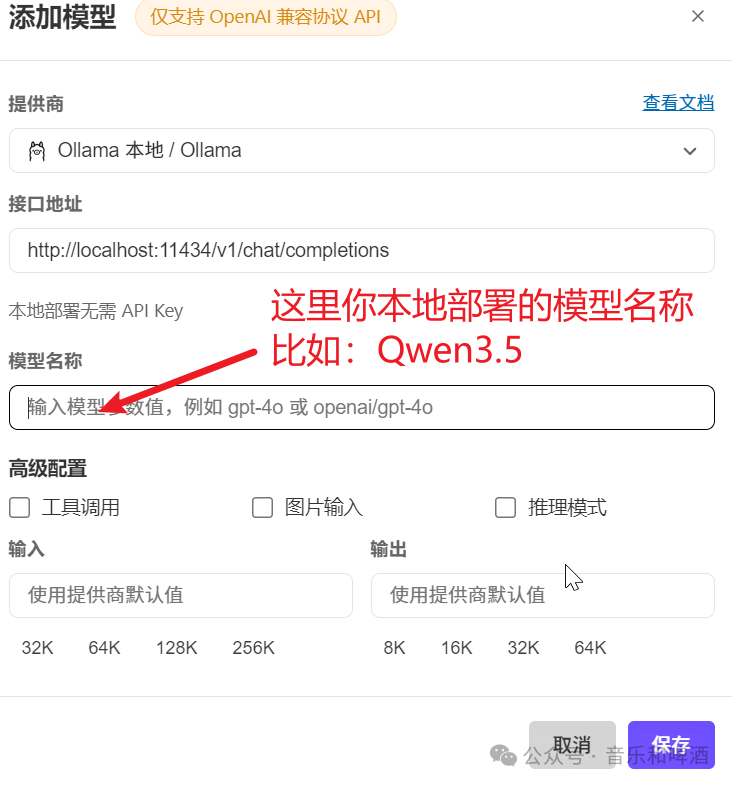
✅ 第三步:重启并验证
- 重启 WorkBuddy
- 完全退出 WorkBuddy 应用,然后重新启动它,以使新的配置生效。
- 选择模型
- 重启后,在 WorkBuddy 的模型选择器中,你应该能看到刚刚添加的 “
- Qwen3.5 7B (Ollama)” 和 “Gemma 4 26B (Ollama)” 选项。
- 选择其中一个,即可开始零成本、完全本地的 AI 对话。同时,在需要的时候你也可以切换网络模型。
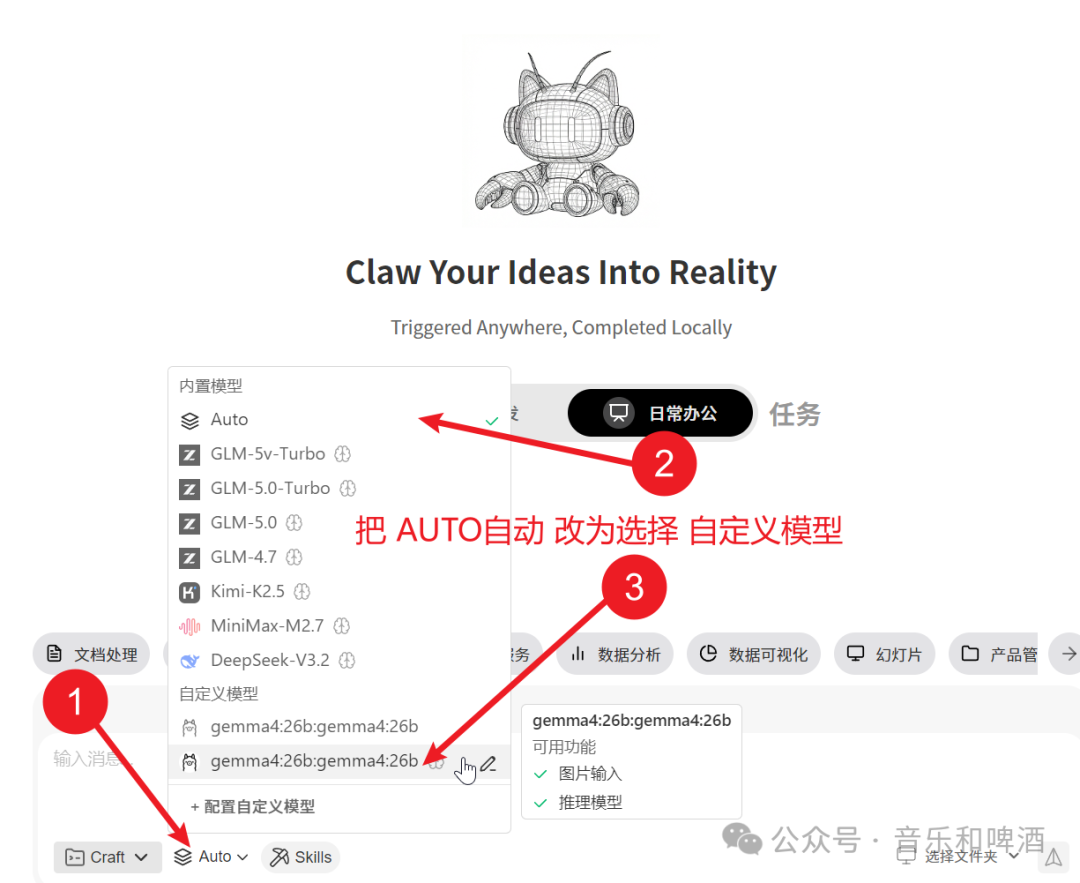
对话验证一下。

💡 补充:关于完全离线和联网使用
如果你希望在完全断网的环境下使用,WorkBuddy 也提供了相应功能。关于积分的消耗,大家也不用担心,很省的,每天敞开了用,大概 500 积分足够用了,具体的积分消耗也可以通过 WorkBuddy 左下角【用户名】-【积分余额】-【用量管理】看到。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)