
仅用数天部署电商Agent,处理百万级并发咨询不在话下!
这是AgentCore的核心组件,它使您能够使用“任何框架和模型”,安全、大规模地部署和运行高效的Agent。在未来的工作中,我们将进一步深度解析不同的快时尚电商领域的复杂Agent场景的架构设计,并展示基于AgentCore Runtime开发测试部署复杂Agent的具体实现。中的每个用户会话都获得自己专用的microVM,具有隔离的计算、内存和文件系统资源。从双十一的流量洪峰到日常的海量客服咨

序言
在快时尚电商行业,速度就是一切。从新款上架到库存周转,从个性化推荐到智能客服,每一个环节都需要快速响应市场变化。随着AI技术的飞速发展,越来越多的快时尚电商企业开始探索如何将AI Agent全面应用于各类业务场景——无论是智能穿搭推荐、实时库存查询、退换货处理,还是潮流趋势分析。
然而,将AI Agent从概念验证推向生产环境,往往面临着巨大的技术挑战:如何处理促销季的流量洪峰?如何确保数百万用户的个性化体验?如何在保证响应速度的同时维护数据安全?
本文将介绍AgentCore Runtime,这是AgentCore的核心组件,它使您能够使用“任何框架和模型”,安全、大规模地部署和运行高效的Agent。对于快时尚电商企业而言,这意味着您可以快速构建智能客服Agent处理海量咨询、部署穿搭推荐Agent提升转化率、运行库存管理Agent优化供应链,所有这些都具备实际部署所需的规模、可靠性和安全性。
AgentCore Runtime提供使Agent更加有效和强大的工具和功能,提供专门构建的基础设施以安全地扩展Agent,并提供控制措施以运行可信赖的Agent。AgentCore Runtime服务可与流行的开源框架和任何模型配合使用,因此您无需在开源灵活性和企业级安全性及可靠性之间做出选择。
AgentCore Runtime
托管Agent或工具
AgentCore Runtime是托管您的AI Agent或工具代码的基础组件。它代表一个“容器化应用程序”,可以处理用户输入,维护上下文,使用AI功能执行操作。
当您创建Agent时,您定义其行为、功能以及它可以访问的工具。例如,快时尚电商的智能客服Agent可能回答商品尺码问题、处理退换货申请。
当您作为开发者使用AgentCore时,您编写自己的代码并使用各种装饰器为应用程序添加功能和特性。一旦实现完成,您只需几行代码即可将Agent或工具部署到AgentCore Runtime。
AgentCore自动将您的代码打包成Docker镜像,将其推送到Amazon ECR(弹性容器注册表)存储库,并将其部署到Serverless运行时环境。此环境根据需求自动扩展您的Agent。每个部署的Agent都包含一个端点,允许客户端调用它。
AgentCore Runtime使用类似于Amazon Lambda的模型托管您的Agent或工具。当发出请求时,运行时会配置一个轻量级microVM,为其分配先前构建的Docker镜像,并调用您的请求处理程序。microVM在会话期间(用户与Agent之间的完整对话)保持活动状态,允许在该会话期间高效执行和更快的后续调用。一旦会话完成或需求减少,运行时会自动释放资源。
+----------------------------------------+ | | | AWS EC2 INSTANCE | +----------+ | +---------+ +-----------------------+ | | | | | | | microVM (Container) | |---+ | | | | | | [ Docker Image ] | | | | | | | | +-----------------------+ | | | | User 1 | | | | | microVMs | |--------->| | | +-----------------------+ | | stayUsers | | User 2 | | | | microVM (Container) | | | alive& | ENDPOINT |--------->| | GATEWAY | | [ Docker Image ] | | | untilTraffic | | User 3 | | | +-----------------------+ | | session | |--------->| | | | | timeout | | | | | +-----------------------+ | | | | | | | | microVM (Container) | | | | | | | | | [ Docker Image ] | |---+ +----------+ | +---------+ +-----------------------+ | | | +----------------------------------------+左右滑动查看完整示意
AgentCore Runtime为客户端请求配置资源的方式:
-
按需配置:当客户端调用Agent时,运行时动态配置计算资源。
-
会话管理:每个请求在隔离的microVM内运行,以确保安全性和可靠性。
-
自动扩展:运行时根据并发请求和工作负载强度自动水平扩展。
-
资源优化:在执行阶段实现高资源利用率与弹性伸缩,在保证性能的前提下降低整体计算成本。
理解AgentCore Runtime
服务契约
AgentCore Runtime服务契约定义了一套标准化的通信协议,用户的Agent应用必须实现该协议,才能与Amazon Bedrock的Agent托管基础设施集成。
契约的目标是确保用户的自定义Agent代码,与亚马逊云科技托管运行环境之间能够无缝通信。
协议支持
AgentCore Runtime服务契约支持以下通信协议:
-
HTTP:直接的REST API端点,适用于传统的请求/响应模式。
-
MCP(Model Context Protocol):用于工具和Agent Server的模型上下文协议。
-
A2A(Agent-to-Agent):用于多Agent之间通信与发现的Agent2Agent协议。
协议对比
您可以参考下表,对比HTTP和MCP和A2A这三种协议,以理解它们各自的差异以及适用的使用场景。
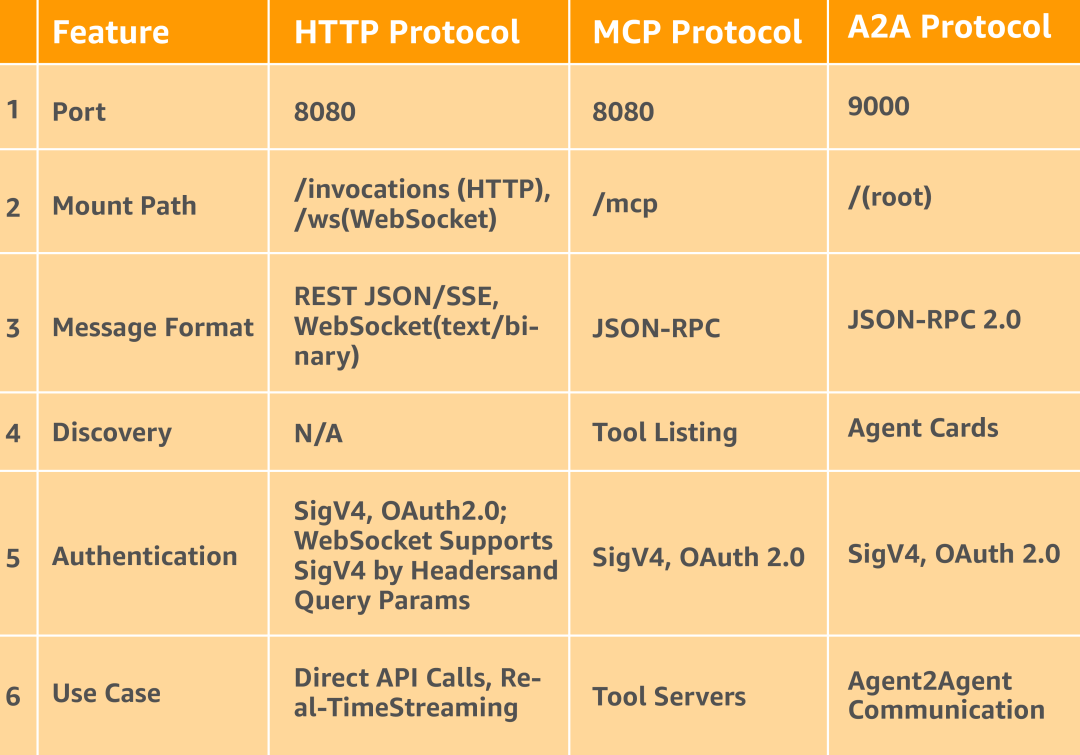
快时尚电商在不同协议下的
Agent应用场景
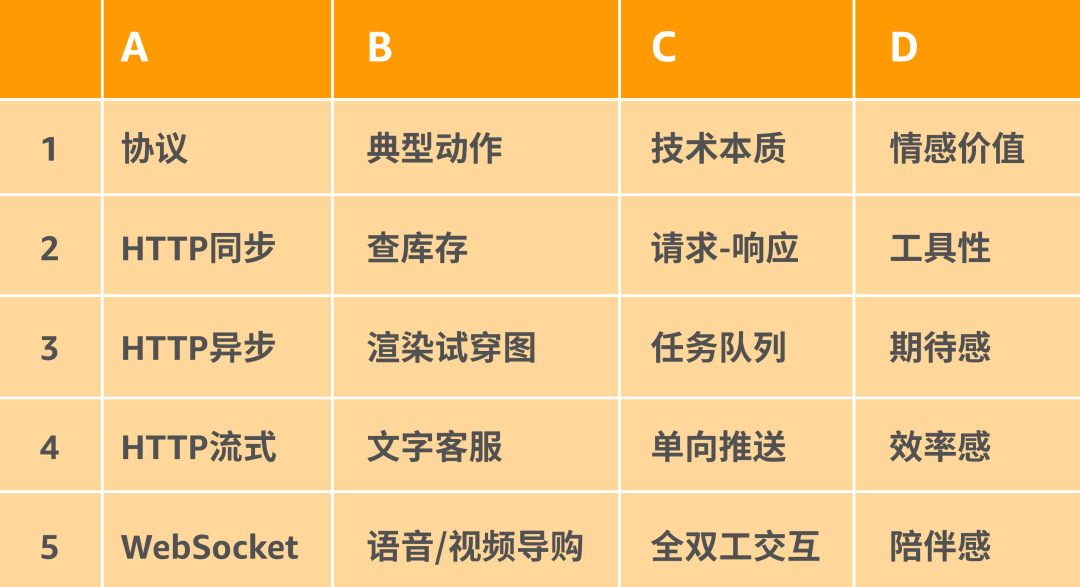
1.HTTP同步
场景:尺码推荐助手。
当用户在浏览一件针织连衣裙时,点击“智能建议尺码”,这是一个典型的请求–响应模式。
-
流程:用户发送当前身高、体重、偏好(紧身或宽松)。
-
Agent动作:Agent立即调用内部尺码数据库和该款式的缩水率数据,计算出最匹配的尺码。
-
体验:用户在点击后1秒内直接收到“建议购买M码”的明确结果。这种场景不需要等待,结果单一且明确。
2.HTTP异步
场景:个性化“穿搭画册”生成。
用户上传一张自己的生活照,要求Agent根据店内新品生成10张该用户试穿不同风格衣服的AI效果图。
-
流程:用户提交照片和风格偏好。
-
Agent动作:由于生成高质量AI图片(Stable Diffusion渲染)耗时较长(可能需要30秒到1分钟),Agent先返回一个Job ID。
-
体验:用户看到“正在为您生成专属画册,完成后将通过App推送通知”,随后用户可以继续逛街,无需留在当前页面等待。
3.HTTP流式
场景:导购智能客服(文字对话)。
用户咨询:“我想参加下周的草地音乐节,能帮我推荐一套波西米亚风格的搭配吗?”
-
流程:Agent开始调用大语言模型(LLM)生成建议。
-
Agent动作:Agent不需要等整段推荐词全部生成完,而是逐字/逐句将内容推送到前端。
-
体验:用户看到屏幕上文字像打字机一样实时跳出:“首先,我建议选择这款白色蕾丝钩花上衣…...(继续显示)…...搭配这条碎花长裙…...”这种实时感能极大降低用户的焦虑感。
4.WebSocket协议
场景:智能语音导购(支持随时插嘴、实时打断)。
用户正通过语音与一个虚拟的快时尚导购进行深度的穿搭讨论。
核心特征:全双工与实时打断
-
Agent正在输出(推):Agent正在详细介绍一款阔腿裤:“这款裤子采用了高腰设计,能很好地拉长腿部线条,面料是…”
-
用户突然打断(拉):用户不等它说完,直接插话:“等等,这个面料容易起球吗?”
-
即时反应:在传统的HTTP模式下,用户必须等Agent说完或者手动切断连接再问。在WebSocket场景下,客户端检测到用户音轨输入,立即通过同一条通道发送一个“打断信号”。Agent会立刻停止当前的文本生成和语音合成,转而解析用户的新问题并给出回答。
快时尚电商Agent协议矩阵
使用AgentCore Runtime部署Agent
通常,在云上部署Agent是一个多阶段、复杂的操作,有很多要求。AgentCore Runtime允许您以非常简单的方法托管Agent,代码要求最少。
以下示例演示如何创建一个使用Amazon Bedrock上托管的LLM模型的快时尚电商智能助手Agent:
from strands import Agent, toolfrom strands_tools import calculator # 导入计算器工具,用于计算商品折扣价格import argparseimport jsonfrom bedrock_agentcore.runtime import BedrockAgentCoreAppfrom strands.models import BedrockModel
app = BedrockAgentCoreApp()
# 创建自定义工具:查询商品库存@tooldef check_inventory(product_id: str): """ 查询指定商品的实时库存状态 """ # 实际实现中会连接库存管理系统 return {"product_id": product_id, "stock": 150, "warehouse": "华东仓"}
# 创建自定义工具:获取穿搭推荐@tooldef get_outfit_recommendation(style: str, season: str): """ 根据风格和季节获取穿搭推荐 """ # 实际实现中会调用推荐引擎 return f"为您推荐{season}季{style}风格的热门单品组合"
# 创建自定义工具:查询物流状态@tooldef track_shipment(order_id: str): """ 查询订单物流配送状态 """ # 实际实现中会调用物流API return {"order_id": order_id, "status": "配送中", "eta": "明天送达"}
model_id = "global.anthropic.claude-sonnet-4-5-20250929-v1:0"model = BedrockModel(model_id=model_id,)
# 创建快时尚电商智能客服Agentagent = Agent( model=model, tools=[calculator, check_inventory, get_outfit_recommendation, track_shipment], system_prompt="你是一个专业的快时尚电商智能助手。你可以帮助顾客查询商品库存、计算折扣价格、提供穿搭推荐、追踪物流状态,以及处理退换货咨询。请用友好专业的语气与顾客交流。")
@app.entrypointdef fashion_ecommerce_agent(payload): """处理来自顾客的咨询请求""" user_input = payload.get("prompt") print("顾客咨询:", user_input) response = agent(user_input) return response.message['content'][0]['text']
if name == "main": app.run()左右滑动查看完整示意
Amazon Bedrock AgentCore Python SDK提供了一个轻量级包装器,帮助您将Agent函数部署为与Amazon Bedrock兼容的HTTP服务。它处理所有HTTP服务器细节,因此您可以专注于Agent的核心功能。
您只需使用@app.entrypoint装饰器装饰您的函数,并使用SDK的配置和启动功能将Agent部署到AgentCore Runtime,上述代码将为您配置以下架构:
+--------------------------------------------------------------+| USER |+----+---------------------------------------------------------+ | ^ | (1) User question | (4) Agent response v |+-----------------------------------+--------------------------+| Local Environment or AWS Cloud(Strands Agents) || || +-----------+ (2) task +----------+ || | | <----------------------------> | Tool 1 | || | AGENT | | Tool 2 | || | | | Tool 3 | || +-----+-----+ +----------+ || ^ |+---------|----------------------------------------------------+ | | (3) Invokes LLM and Processes Outputs v+--------------------------------------------------------------+| AWS Cloud || || +-----------------------+ || | Amazon Bedrock LLMs | || +-----------------------+ || |+--------------------------------------------------------------+左右滑动查看完整示意
当您使用Amazon BedrockAgentCoreApp时,它会自动:
-
创建一个监听端口8080的HTTP服务器
-
实现处理Agent需求所需的/invocations端点
-
实现用于健康检查的/ping端点(对异步Agent非常重要)
-
处理正确的内容类型和响应格式
-
根据亚马逊云科技标准管理错误处理
1./invocations—POST
这是主要的Agent交互端点,具有JSON输入和JSON/SSE输出。该端点接收来自用户或应用程序的传入请求,并通过Agent的业务逻辑处理它们。
/invocations端点服务于几个关键目的:
-
直接用户交互和对话
-
与外部系统的API集成
-
批量处理多个请求
-
长时间运行操作的实时流式响应
示例请求格式:
Content-Type: application/json{ "prompt": "这款连衣裙还有M码吗?"}左右滑动查看完整示意
Agent可以根据场景需要,使用以下任一格式响应:
JSON响应(非流式)
为可以快速处理的请求提供完整响应,JSON响应适用于:
-
简单的问答场景
-
确定性计算
-
快速数据查找
-
状态确认
Content-Type: application/json{ "response": "完整响应", "status": "success"}左右滑动查看完整示意
SSE响应(流式)
服务器发送事件(SSE)让您能够提供实时流式响应。它支持长时间运行操作的增量响应传递和改进的用户体验。SSE响应适用于:
-
实时对话体验
-
渐进式内容生成
-
具有中间结果的长时间运行计算
-
实时数据馈送和更新
Content-Type: text/event-streamdata: {"event": "部分响应 1"}data: {"event": "部分响应 2"}data: {"event": "部分响应 3"}data: {"event": "最终响应"}左右滑动查看完整示意
2./ping—GET
验证您的Agent是否正常运行并准备好处理请求。
/ping端点服务于几个关键目的:
-
服务监控以检测和修复问题
-
通过亚马逊云科技托管基础设施进行自动恢复
如果您的Agent需要处理后台任务,您可以使用/ping状态来指示。如果ping状态是HealthyBusy,则运行时会话被视为活动状态,无法接受新请求。
{ "status": "<status_value>", "time_of_last_update": <unix_timestamp>}左右滑动查看完整示意
状态说明:
-
Healthy:系统准备好接受新任务
-
HealthyBusy:系统正常运行但当前正忙于异步任务
使用AgentCore Runtime
部署“MCP Server”
Amazon Bedrock AgentCore Runtime允许您在AgentCore Runtime中部署和运行模型上下文协议(MCP)服务器。与AI Agent相同,Amazon Web Services Python SDK提供了一个轻量级装饰器@mcp.tool,允许您定义MCP服务器可以使用的工具。
以下代码片段展示了如何创建一个快时尚电商场景的MCP服务器:
from mcp.server.fastmcp import FastMCPfrom starlette.responses import JSONResponse
mcp = FastMCP(host="0.0.0.0", stateless_http=True)
@mcp.tool()def calculate_discount(original_price: float, discount_rate: float) -> float: """计算商品折扣后的价格,用于促销活动""" return original_price * (1 - discount_rate)
@mcp.tool()def check_size_availability(product_id: str, size: str) -> dict: """查询指定商品特定尺码的库存情况""" # 实际实现中会查询库存数据库 return {"product_id": product_id, "size": size, "available": True, "quantity": 25}
@mcp.tool()def get_style_recommendation(customer_id: str, occasion: str) -> str: """根据顾客ID和场合获取个性化穿搭推荐""" return f"根据您的购买历史,为{occasion}场合推荐:简约风格白色衬衫搭配高腰阔腿裤"
@mcp.tool()def process_return_request(order_id: str, reason: str) -> dict: """处理顾客的退换货申请""" return {"order_id": order_id, "status": "已受理", "return_label": "RL-2024-001234"}
if name == "main": mcp.run(transport="streamable-http")左右滑动查看完整示意
MCP是一种允许AI模型安全访问外部数据和工具的协议,主要概念:
-
Tools(工具):AI可以调用以执行操作的函数
-
Streamable HTTP:AgentCore Runtime使用的传输协议
-
Session Isolation(会话隔离):每个客户端通过Mcp-Session-Id头获得隔离的会话
-
Stateless Operation(无状态操作):服务器必须支持无状态操作以实现可扩展性
AgentCore Runtime期望MCP服务器托管在0.0.0.0:8000/mcp作为默认路径。
/mcp—POST
接收MCP RPC消息并通过Agent的工具功能处理它们,完全传递InvokeAgentRuntime API有效负载和标准MCP RPC消息。基于JSON-RPC的请求/响应格式,支持application/json和text/event-stream作为响应内容类型。
/mcp端点服务于几个主要目的:
-
工具调用和管理
-
Agent功能发现
-
资源访问和操作
-
多步骤Agent工作流
使用AgentCore Runtime
部署“A2A Server”
Amazon Bedrock AgentCore Runtime允许您在AgentCore Runtime中部署和运行Agent2Agent(A2A)服务器。A2A协议是一个开放标准,旨在促进独立的、可能不透明的AI Agent系统之间的通信和互操作性。在Agent可能使用不同框架、语言或由不同供应商构建的系统中,A2A提供了通用语言和交互模型。
一旦将服务器部署到AgentCore Runtime,您需要获取Agent Cards,这是描述A2A服务器身份、功能、技能、服务端点和身份验证要求的JSON元数据文档,它们在A2A系统中启用自动Agent发现。
AgentCore的A2A协议支持通过充当透明代理层来实现与A2A服务器的无缝集成。当配置为A2A时,AgentCore期望容器在端口9000的根路径(0.0.0.0:9000/)上运行无状态、可流式HTTP服务器,这与默认的A2A服务器配置一致。
A2A Server在AgentCore Runtime
中的角色
A2A Server是一个基于Agent-to-Agent(A2A)协议的服务,允许多个Agent之间进行直接交互。
这个协议定义了标准的交互机制,包括:
-
使用JSON-RPC 2.0 over HTTP作为通信协议
-
运行在固定端口9000
-
提供一个标准的Agent Card元数据发现端点
-
支持安全认证(OAuth2或SigV4)
-
通过标准格式让其他Agent可以发现和调用服务
AgentCore Runtime核心功能可以概括为:
-
运行和管理Agent服务容器
-
自动提供统一入口和生命周期管理
-
基于Agent Card实现Agent发现与交互桥接
A2A Server的原理核心
A2A协议
A2A Server必须:
-
接收并响应JSON-RPC 2.0消息
包括message/send等方法 -
按协议要求在根路径/上处理消息
-
在/.well-known/agent-card.json提供Agent Card,JSON格式描述自身能力、URL、技能等
典型A2A请求示例如下:
{ "jsonrpc": "2.0", "id": "req-001", "method": "message/send", "params": { "message": { "role": "user", "parts": [ { "kind": "text", "text": "你好!" } ] } }}左右滑动查看完整示意
AgentCore Runtime部署要求
为了被AgentCore识别运行,一个A2A Server需满足:
-
容器暴露0.0.0:9000
-
提供根路径/作为JSON-RPC端点
-
提供标准的Agent Card元数据
-
支持标准授权/会话隔离(如X-Amzn-Bedrock-AgentCore-Runtime-Session-Id)
部署流程原理(从创建到运行)
整体流程可以抽象为五个阶段:
[ 编写 A2A Server 代码 ] ⬇[ 本地启动 A2A Server (JSON-RPC/9000) ] ⬇[ 打包为容器镜像并上传 ECR ] ⬇[ 使用 AgentCore CLI 部署到 Bedrock AgentCore Runtime ] ⬇[ 生成 & 获取 Agent Card / 部署 Endpoint ]左右滑动查看完整示意
其中关键点如下:
代码层面
使用SDK(如Strands Agents、FastAPI等)实现Agent行为。
包装成A2A Server,监听9000 /
AgentCore Runtime
CLI会识别协议A2A并生成对应资源配置
Runtime使用亚马逊云科技服务运行容器,并自动绑定路由。
Agent Card
AgentCard是Agent对外的元数据信息
包含:Endpoint URL、Capabilities、协议版本等
使用它可以被其他A2A Client自动发现
核心原则

快时尚电商A2A多Agent架构示例
+---------------------------+ | User Interface | | (Mobile App / Web Site) | +-------------+-------------+ | v+----------------------------------------------------------------------------------+| Bedrock AgentCore Runtime || || +--------------------------+ (A2A) +------------------------------+ || | Orchestrator Agent |<-------------->| Inventory Agent | || | (The "Brain") | (A2A) | (Check SKU, Stock, Warehouse)| || +------------+-------------+ +------------------------------+ || ^ || | (A2A) +------------------------------+ || +----------------------------->| Trend/Style Agent | || | | (Social Media Trends, Style) | || | (A2A) +------------------------------+ || +----------------------------->| Visual/Outfit Agent | || | (Virtual Try-on, Mix & Match)| || +------------------------------+ || |+---------------------------------------+------------------------------------------+ | v +----------------------------------------------------------------------------------+| Shared Infrastructure(AWS) | | || +-----------------------+ +-----------------------+ +----------------------+ || | Cognito(Auth) | | Bedrock(Models) | | External Tools | || | - Token Exchange | | - Nova / Claude | | - ERP / CRM System | || +-----------------------+ +-----------------------+ +----------------------+ || |+----------------------------------------------------------------------------------+左右滑动查看完整示意
Agent的会话隔离
AgentCore Runtime允许您隔离每个用户会话,并在用户会话中的多次调用之间安全地重用上下文。
+--------------------------------------+ | | data stored session-id=1 | +-----------------------+ | per single session +-------------->| | microVM | | +------------------+ | | +----->| +-----|--->| (O) Disk | | | | | +-----|--->| [|||] Memory | | | | +-----------------------+ | +------------------+ | | | |+--------+ +---+-+----+ || User-1 |----->| Endpoint | |+--------+ +---+-+----+ | | | | | data stored | | | +-----------------------+ | per single session | session-id=2 | | | microVM | | +------------------+ +-------------->| +----->| +-----|--->| (O) Disk | | | +-----|--->| [|||] Memory | | +-----------------------+ | +------------------+ | | | +---------------------|----------------+ | v +----------------------------------+ | microVM lives to serve a single | | session only, and contain the | | conversation history as long as | | the session lives | +----------------------------------+左右滑动查看完整示意
会话隔离对AI Agent工作负载至关重要:
完整的执行环境分离
AgentCore Runtime中的每个用户会话都获得自己专用的microVM,具有隔离的计算、内存和文件系统资源。这防止一个用户的Agent访问另一个用户的数据。会话完成后,整个microVM被终止,内存被清理以删除所有会话数据,消除跨会话污染风险。
有状态推理过程
与无状态函数不同,AI Agent在整个执行周期中维护复杂的上下文状态,超越多轮对话的简单消息历史。AgentCore Runtime在会话内安全地保留此状态,同时确保不同用户之间的完全隔离,实现个性化的Agent体验而不损害数据边界。
特权工具操作
AI Agent通过访问各种资源的集成工具代表用户执行特权操作。AgentCore Runtime的隔离模型确保这些工具操作维护正确的安全上下文,并防止不同用户会话之间的凭证共享或权限升级。
特权工具操作
AI Agent通过访问各种资源的集成工具代表用户执行特权操作。AgentCore Runtime的隔离模型确保这些工具操作维护正确的安全上下文,并防止不同用户会话之间的凭证共享或权限升级。
非确定性过程的确定性安全
由于基础模型的概率性质,AI Agent行为可能是非确定性的。AgentCore Runtime提供一致的、确定性的隔离边界,无论Agent执行模式如何,为企业部署提供所需的可预测安全属性。
临时上下文
虽然AgentCore提供强大的会话隔离,但这些会话本质上是临时的。存储在内存中或写入磁盘的任何数据仅在会话期间持续存在。这包括对话历史、用户偏好、中间计算结果以及Agent维护的任何其他状态信息。
对于需要在会话生命周期之外保留的数据(如用户对话历史、学习的偏好或重要见解),您应该使用AgentCore Memory:此服务提供专门为Agent工作负载设计的持久存储,具有短期和长期记忆功能。
会话状态
会话可以处于以下状态之一:
-
Active(活动):正在处理同步请求或执行后台任务
-
Idle(空闲):未处理任何请求或后台任务。会话已完成处理但仍可用于未来调用
-
Terminated(已终止):为会话配置的执行环境已终止。这可能是由于不活动(15分钟)、达到最大持续时间(8小时)或基于健康检查被认为不健康
如何使用会话
要有效使用会话:
-
为每个用户或对话生成至少33个字符的唯一会话ID
-
为所有相关调用传递相同的会话ID
-
为不同用户或对话使用不同的会话ID
使用会话进行对话的示例:
# 顾客咨询的第一条消息:询问商品信息response1 = agent_core_client.InvokeAgentRuntime( agentRuntimeArn=agent_arn, runtimeSessionId="customer-123456-session-123456789", payload=json.dumps({ "prompt": "这款碎花连衣裙有什么颜色可选?" }).encode())
# 同一对话中的后续消息重用 runtimeSessionId# 顾客继续询问尺码,Agent能够理解上下文response2 = agent_core_client.InvokeAgentRuntime( agentRuntimeArn=agent_arn, runtimeSessionId="customer-123456-session-123456789", payload=json.dumps({ "prompt": "M码还有库存吗?" }).encode())
# 顾客决定下单,Agent仍然记得之前讨论的商品response3 = agent_core_client.InvokeAgentRuntime( agentRuntimeArn=agent_arn, runtimeSessionId="customer-123456-session-123456789", payload=json.dumps({ "prompt": "好的,帮我加入购物车" }).encode())左右滑动查看完整示意
通过为相关调用使用相同的runtimeSessionId,您确保在整个对话中维护上下文,使您的Agent能够提供基于先前交互的连贯响应。
停止运行中的会话
StopRuntimeSession操作允许您立即终止活动的Agent AgentCore Runtime会话,以进行适当的资源清理和会话生命周期管理。调用时,此操作会立即终止指定的会话并停止任何正在进行的流式响应。这使系统资源能够正确释放,并防止孤立会话的累积。
在以下场景中使用StopRuntimeSession:
-
用户发起停止:当用户明确结束对话时
-
应用程序关闭:应用程序终止前的主动清理
-
错误处理:强制终止无响应或停滞的会话
-
配额管理:通过关闭未使用的会话来保持在会话限制内
-
超时处理:清理超过预期持续时间的会话
停止会话可以节省资源,因为底层microVM将被停止和终止。
使用AgentCore Runtime处理
异步和长时间运行的Agent
Amazon Bedrock AgentCore Runtime可以处理异步处理和长时间运行的Agent。异步任务允许您的Agent在响应客户端后继续处理,并处理长时间运行的操作而不阻塞响应。
通过异步处理,您的Agent可以:
-
启动可能需要几分钟或几小时的任务
-
立即响应用户说“已经开始处理”
-
在后台继续处理
-
允许用户稍后检查结果
异步处理模型
Amazon Bedrock AgentCore SDK通过统一的API支持同步和异步处理,这为客户端和Agent开发者创建了灵活的实现模式。Agent客户端可以使用相同的API,而无需在客户端区分同步和异步。
通过跨系统调用同一会话的能力,Agent开发者可以重用上下文,并在此上下文上增量构建,而无需实现复杂的任务管理逻辑。
运行时会话生命周期管理
Agent代码使用“/ping”健康状态来传达其处理状态。“HealthyBusy”表示Agent正忙于处理后台任务,而“Healthy”表示它处于空闲状态(等待请求)。处于空闲状态15分钟的会话会自动终止。当会话状态为HealthyBusy时,运行时不会为同一会话接受新消息或入口点调用。
异步任务装饰器
Amazon Bedrock AgentCore SDK帮助跟踪异步任务。您只需使用@app.async_task注解您的异步函数即可开始。
# 自动跟踪异步函数:用于处理大批量订单或库存同步等耗时操作@app.async_taskasync def sync_inventory_from_supplier(): """从供应商系统同步最新库存数据,这是一个耗时操作""" await asyncio.sleep(30) # 状态变为 "HealthyBusy" # 实际实现中会调用供应商API同步库存 return "库存同步完成"
@app.async_taskasync def generate_sales_report(date_range: str): """生成指定时间段的销售报表,需要处理大量数据""" await asyncio.sleep(60) # 状态变为 "HealthyBusy" # 实际实现中会查询数据库并生成报表 return f"{date_range} 销售报表已生成"
@app.entrypointasync def handler(event): """处理顾客请求,对于耗时操作启动后台任务""" task_type = event.get("task_type") if task_type == "inventory_sync": asyncio.create_task(sync_inventory_from_supplier()) return {"status": "库存同步任务已启动,请稍后查看结果"} elif task_type == "sales_report": asyncio.create_task(generate_sales_report(event.get("date_range"))) return {"status": "报表生成任务已启动,完成后将通知您"} return {"status": "未知任务类型"}左右滑动查看完整示意
工作原理:
-
@app.async_task装饰器跟踪函数执行
-
当函数运行时,/ping状态变为“HealthyBusy”
-
当函数完成时,状态返回“Healthy”
AgentCore Runtime
生命周期事件
使用AgentCore Runtime时,您可以监听并向Agent运行时添加钩子,这允许您设置一些在会话期间运行的特定操作。当Agent初始化以开始接受新请求时,Agent进入Agent initialized事件,当用户或LLM向聊天上下文添加消息时,Message Added事件被触发。
这些事件可以与HookProvider一起使用,以执行一些操作,如将消息存储在内存中,或从短期或长期记忆中加载消息。
AgentCore Runtime
版本控制和端点
Amazon Bedrock AgentCore为AgentCore Runtime实现自动版本控制,并允许您使用端点管理不同的配置。
Amazon Bedrock AgentCore中的每个AgentCore Runtime都会自动进行版本控制:
-
当您创建AgentCore Runtime时,AgentCore Runtime自动创建版本V1
-
对AgentCore Runtime的每次更新都会创建一个具有完整、自包含配置的新版本
-
版本一旦创建就是不可变的
-
每个版本包含执行所需的所有配置
AgentCore Memory
为Agent添加记忆
记忆是智能的关键组成部分。虽然LLM具有令人印象深刻的能力,但它们缺乏跨对话的持久记忆。Amazon Bedrock AgentCore Memory通过提供托管服务来解决这一限制,使AI Agent能够随时间维护上下文、记住重要事实,并提供一致的、个性化的体验。
AgentCore Memory提供:
-
核心基础设施:具有内置加密和可观测性的Serverless设置
-
事件存储:原始事件存储(对话历史/检查点)支持分支
-
策略管理:可配置的提取策略(SEMANTIC、USER_PREFERENCES、SUMMARY、CUSTOM)
-
记忆记录提取:根据配置的策略自动提取事实、偏好和摘要
-
语义搜索:使用自然语言查询的基于向量的相关记忆检索
记忆类型
AgentCore Memory提供两种类型的记忆,它们协同工作以创建智能、上下文感知的AI Agent:
短期记忆
短期记忆捕获单个会话内的逐轮交互。这使Agent能够维护即时上下文,而无需用户重复信息。
示例:当顾客问“这款白色T恤有M码吗?”然后跟进“那黑色的呢?”时,Agent依赖最近的对话历史来理解“黑色的”指的是同款T恤的黑色版本和M码。
长期记忆
长期记忆自动从多个会话的对话中提取和存储关键见解,包括用户偏好、重要事实和会话摘要,用于跨多个会话的持久知识保留。
示例:如果顾客在之前的购物过程中提到她通常穿S码、偏好简约风格,Agent会将此偏好存储在长期记忆中。在未来的交互中,Agent可以主动推荐S码的简约风格单品,创造个性化购物体验。
记忆术语
以下是理解AgentCore Memory需要了解的几个关键概念和术语:
Actor(参与者)
代表与Agent交互的实体。可以是人类用户、另一个Agent或发起与Agent交互的系统(软件或硬件组件)。唯一的actorId确保记忆记录正确关联到个人或系统。
Session(会话)
代表用户与Agent之间的单个连续交互,例如一次购物咨询对话。唯一的sessionId用于将该对话中的所有事件分组。
Event(事件)
事件是“短期记忆”的基本单位。它代表会话内的离散交互或活动,与特定参与者关联。事件使用CreateEvent操作存储,并按actorId和sessionId组织。每个事件都是不可变的和带时间戳的,捕获实时数据,如用户消息、系统操作或工具调用。
Memory Strategy(记忆策略)
记忆策略是可配置的规则,决定如何将短期记忆中的信息处理成长期记忆。它们决定保留什么类型的信息,将原始对话转换为结构化和有用的知识。
Namespace(命名空间)
命名空间是用于逻辑分组和组织长期记忆的“结构化路径”。通过在记忆策略中定义命名空间,您可以确保所有提取的记忆都组织在可预测的路径下,这有助于检索、过滤和访问控制。
Memory Record(记忆记录)
记忆记录是记忆资源内的结构化信息单元。每个记录与唯一标识符关联,并存储在指定的命名空间内,允许有组织的检索和管理。
记忆架构
Conversation Storage(对话存储)
完整对话以原始形式保存以供即时访问
Strategy Processing(策略处理)
配置的策略在后台自动分析对话
Information Extraction(信息提取)
根据策略类型提取重要数据,通常需要约1分钟
Organized Storage(有组织的存储)
提取的信息存储在结构化命名空间中以便高效检索
Semantic Retrieval(语义检索)
自然语言查询可以使用向量相似性检索相关记忆
[ User ]--------------------> [ Agent ] Conversation Messages | | Events To Memory v +-----------------------+ | Short-Term Memory | | Conversation Storage | +-----------------------+ | ^ | | v | +-----------------------------------------+ | Background Job(Three Steps) | | | | 1. [ Analyze Conversation ] | | | | | v | | 2. [ Information Extraction ] | | | | | v | | 3. [ Writer To Long-Term Memory ] | +-----------------------------------------+ | | v +-----------------------+ | Long-Term Memory | | | +-----------------------+ ^ | Semantic Retrieval | [ Agent ]左右滑动查看完整示意
记忆策略
在AgentCore Memory中,您可以向记忆资源添加记忆策略。这些策略决定从原始对话中提取什么类型的信息。策略是智能捕获和持久化交互中关键概念的配置,作为事件发送。一旦启用,这些策略会自动在与该记忆资源关联的原始对话事件上执行,以提取长期记忆。如果未指定策略,则不会为该记忆提取长期记忆记录。
内置策略
AgentCore Memory允许您添加以下内置记忆策略:
-
Semantic Memory(语义记忆):使用向量嵌入存储事实信息以进行相似性搜索
-
User Preference Memory(用户偏好记忆):跟踪用户特定的偏好和设置
-
Summary Memory(摘要记忆):创建和维护对话摘要以保留上下文
-
Custom Memory(自定义记忆):允许自定义提取和整合逻辑
1.语义记忆策略
SemanticMemoryStrategy旨在从对话数据中识别和提取关键的事实信息和上下文知识。这使您的Agent能够构建关于交互期间讨论的实体、事件和关键细节的持久知识库。
示例:
-
订单号(#ORD-2024-123456)与特定退换货案例关联
-
顾客提到的身高体重信息用于尺码推荐
-
顾客询问的特定商品SKU和颜色
通过引用此存储的知识,您的Agent可以提供更准确、上下文感知的响应,执行依赖于先前陈述信息的多步骤任务,并避免要求用户重复关键细节。
默认命名空间:
/strategies/{memoryStrategyId}/actors/{actorId}
2.用户偏好记忆策略
UserPreferenceMemoryStrategy旨在自动从对话数据中识别和提取用户偏好、选择和风格。这使您的Agent能够从交互中学习,并随时间构建每个用户的持久、动态配置文件。
示例:
-
顾客偏好的服装尺码(如“我一般穿M码”)
-
顾客喜欢的穿搭风格(如简约风、韩系风、复古风)
-
顾客的颜色偏好(如“我不太喜欢亮色”)
-
顾客的价格敏感度(如“200以内的”)
通过利用此策略,您的Agent可以提供高度个性化的体验,如提供定制推荐、根据用户风格调整响应,以及根据过去的选择预测需求。
默认命名空间:
/strategies/{memoryStrategyId}/actors/{actorId}
3.摘要记忆策略
SummaryStrategy负责生成单个会话内对话的压缩、实时摘要。它捕获关键主题、主要任务和决策,提供对话的高级概述。单个会话可以有多个摘要块,每个代表对话的一部分。这些块一起形成整个会话的完整摘要。
示例:
-
购物咨询的摘要,如“顾客咨询了春季新款连衣裙,最终选择了粉色M码,已加入购物车。”
-
售后服务的结果,如“顾客反馈订单#123的裙子尺码偏大,已安排换货处理。”
通过引用此摘要,Agent可以快速回忆长或复杂对话的上下文,而无需重新处理整个历史。这对于维护对话流程和有效管理基础模型的上下文窗口至关重要。
默认命名空间:
/strategies/{memoryStrategyId}/actors/{actorId}/sessions/{sessionId}
AgentCore Memory集成
要将原始事件添加到短期记忆,您可以创建所谓的“Memory Hook”。这负责使用之前展示的AgentCore Runtime生命周期事件自动化记忆操作。钩子是在Agent执行生命周期中特定点运行的特殊函数。
记忆钩子服务于两个主要功能:
-
加载最近对话:使用AgentInitializedEvent钩子在Agent初始化时自动加载最近的对话历史
-
存储最后消息:存储新的对话消息
代码示例:
class MemoryHookProvider(HookProvider): def __init__(self, memory_client: MemoryClient, memory_id: str): self.memory_client = memory_client self.memory_id = memory_id
def on_agent_initialized(self, event: AgentInitializedEvent): """当快时尚电商客服智能体启动时加载最近的顾客对话历史""" try: # 从智能体状态中获取会话信息(如顾客ID、购物会话ID) actor_id = event.agent.state.get("actor_id") session_id = event.agent.state.get("session_id")
ifnot actor_id ornot session_id: logger.warning("智能体状态中缺少 actor_id 或 session_id") return
# 从记忆中加载最近5轮对话(如顾客之前咨询的尺码、颜色偏好等) recent_turns = self.memory_client.get_last_k_turns( memory_id=self.memory_id, actor_id=actor_id, session_id=session_id, k=5 )
if recent_turns: # 格式化对话历史作为上下文 context_messages = [] for turn in recent_turns: for message in turn: role = message['role'] content = message['content']['text'] context_messages.append(f"{role}: {content}")
context = "\n".join(context_messages) # 将上下文添加到智能体的系统提示中,帮助客服了解顾客之前的咨询内容 event.agent.system_prompt += f"\n\n最近对话记录:\n{context}" logger.info(f"✅ 已加载 {len(recent_turns)} 轮对话历史")
except Exception as e: logger.error(f"记忆加载错误: {e}")
def on_message_added(self, event: MessageAddedEvent): """将顾客与客服的对话消息存储到记忆中""" messages = event.agent.messages try: # 从智能体状态中获取会话信息 actor_id = event.agent.state.get("actor_id") session_id = event.agent.state.get("session_id")
if messages[-1]["content"][0].get("text"): # 保存对话消息(如顾客询问的服装款式、尺码、物流等信息) self.memory_client.create_event( memory_id=self.memory_id, actor_id=actor_id, session_id=session_id, messages=[(messages[-1]["content"][0]["text"], messages[-1]["role"])] ) except Exception as e: logger.error(f"记忆保存错误: {e}")
def register_hooks(self, registry: HookRegistry): # 注册记忆钩子,实现快时尚电商场景下的自动记忆管理 registry.add_callback(MessageAddedEvent, self.on_message_added) registry.add_callback(AgentInitializedEvent, self.on_agent_initialized)左右滑动查看完整示意
现在创建Agent时,将MemoryHook关联到Agent,如以下代码所示:
def create_personal_agent(): """创建具有记忆和商品搜索能力的快时尚电商客服智能体""" agent = Agent( name="FastFashionAssistant", model="global.anthropic.claude-sonnet-4-5-20250929-v1:0", # 或您偏好的模型 system_prompt=f"""您是一位专业的快时尚电商客服助手,具备商品搜索和推荐能力。
您可以帮助顾客:- 查询服装款式、尺码、颜色和库存信息- 搜索当季流行单品和新品上架信息- 处理订单查询、物流追踪和退换货咨询- 根据顾客偏好提供个性化穿搭建议
当您需要查询最新商品信息或流行趋势时,请使用商品搜索功能。今日日期: {datetime.today().strftime('%Y-%m-%d')}请保持友好、专业的服务态度,帮助顾客找到心仪的时尚单品。""", hooks=[MemoryHookProvider(client, memory_id)], tools=[websearch], state={"actor_id": ACTOR_ID, "session_id": SESSION_ID} ) return agent
# 创建快时尚电商客服智能体agent = create_personal_agent()logger.info("✅ 已创建具有记忆和商品搜索能力的快时尚电商客服智能体")左右滑动查看完整示意
现在您已经了解了短期记忆的工作原理,假设您已经为记忆分配了特定的策略,使其能够将记录移动到长期记忆中,下面介绍长期记忆的工作原理以及如何使用它。
第一步是为记忆添加策略类型:
from bedrock_agentcore.memory import MemoryClientfrom bedrock_agentcore.memory.constants import StrategyType
# 初始化 Memory 客户端client = MemoryClient(region_name=REGION)memory_name = "FastFashionAgentMemory"
# 为快时尚电商客服定义记忆策略strategies = [ { StrategyType.USER_PREFERENCE.value: { "name": "CustomerFashionPreferences", "description": "捕获顾客的时尚偏好和购物行为(如偏好的风格、常购尺码、喜欢的颜色等)", "namespaces": ["fashion/customer/{actorId}/preferences"] } }, { StrategyType.SEMANTIC.value: { "name": "CustomerFashionSemantic", "description": "存储对话中提取的事实信息(如顾客提到的身材特征、穿搭场景需求等)", "namespaces": ["fashion/customer/{actorId}/semantic"], } }]
# 创建记忆资源try: memory = client.create_memory_and_wait( name=memory_name, strategies=strategies, # 定义记忆策略,用于存储顾客的时尚偏好和购物历史 description="快时尚电商客服智能体的记忆存储", event_expiry_days=90, # 记忆在90天后过期,适合快时尚行业的季节性特点 ) memory_id = memory['id'] logger.info(f"✅ 已创建记忆: {memory_id}")except ClientError as e: if e.response['Error']['Code'] == 'ValidationException'and"already exists" in str(e): # 如果记忆已存在,获取其ID memories = client.list_memories() memory_id = next((m['id'] for m in memories if m['id'].startswith(memory_name)), None) logger.info(f"记忆已存在,使用现有记忆ID: {memory_id}")except Exception as e: # 处理记忆创建过程中的任何错误 logger.info(f"❌ 错误: {e}") import traceback traceback.print_exc() # 出错时清理 - 如果记忆已部分创建则删除 if memory_id: try: client.delete_memory_and_wait(memoryId=memory_id, max_wait=300) logger.info(f"已清理记忆: {memory_id}") except Exception as cleanup_error: logger.info(f"清理记忆失败: {cleanup_error}")左右滑动查看完整示意
因此,您还将使用一个同时使用短期和长期记忆的Hook Provider。
MemoryHookProvider类自动化记忆操作。本例创建的记忆钩子主要有两个功能:
-
检索记忆:当顾客发送消息时,自动获取相关的历史对话记录。
-
保存记忆:在Agent响应后存储新的对话内容。
代码示例:
class MemoryHookProvider(HookProvider): """用于自动记忆管理的钩子提供者,适用于快时尚电商场景"""
def __init__(self, memory_id: str, client: MemoryClient): self.memory_id = memory_id self.client = client
def retrieve_memories(self, event: MessageAddedEvent): """在处理顾客消息前检索相关记忆(如之前咨询过的款式、尺码偏好等)""" messages = event.agent.messages if messages[-1]["role"] == "user"and"toolResult"not in messages[-1]["content"][0]: user_message = messages[-1]["content"][0].get("text", "")
try: # 从智能体状态获取顾客ID actor_id = event.agent.state.get("actor_id") ifnot actor_id: logger.warning("智能体状态中缺少 actor_id") return
# 构建命名空间路径,用于检索该顾客的时尚偏好记忆 namespace = f"/fashion/customer/{actor_id}"
# 检索与当前查询相关的记忆(如顾客之前表达的风格偏好、尺码信息等) memories = self.client.retrieve_memories( memory_id=self.memory_id, namespace=namespace, query=user_message )
# 提取记忆内容 memory_context = [] for memory in memories: if isinstance(memory, dict): content = memory.get('content', {}) if isinstance(content, dict): text = content.get('text', '').strip() if text: memory_context.append(text)
# 将记忆注入到用户消息中,帮助客服了解顾客的历史偏好 if memory_context: context_text = "\n".join(memory_context) original_text = messages[-1]["content"][0].get("text", "") messages[-1]["content"][0]["text"] = ( f"{original_text}\n\n顾客历史偏好: {context_text}" ) logger.info(f"已检索 {len(memory_context)} 条相关记忆")
except Exception as e: logger.error(f"检索记忆失败: {e}")
def save_memories(self, event: AfterInvocationEvent): """在智能体响应后保存对话内容(记录顾客的咨询内容和客服的推荐建议)""" try: messages = event.agent.messages if len(messages) >= 2 and messages[-1]["role"] == "assistant": # 获取最后的用户消息和助手消息 user_msg = None assistant_msg = None
for msg in reversed(messages): if msg["role"] == "assistant" and not assistant_msg: assistant_msg = msg["content"][0]["text"] elif msg["role"] == "user" and not user_msg and "toolResult" not in msg["content"][0]: user_msg = msg["content"][0]["text"] break
if user_msg and assistant_msg: # 从智能体状态获取会话信息 actor_id = event.agent.state.get("actor_id") session_id = event.agent.state.get("session_id")
if not actor_id or not session_id: logger.warning("智能体状态中缺少 actor_id 或 session_id") return
# 保存对话到记忆(包含顾客咨询和客服推荐的服装信息) self.client.create_event( memory_id=self.memory_id, actor_id=actor_id, session_id=session_id, messages=[(user_msg, "USER"), (assistant_msg, "ASSISTANT")] ) logger.info("已将对话保存到记忆")
except Exception as e: logger.error(f"保存记忆失败: {e}")
def register_hooks(self, registry: HookRegistry) -> None: """注册记忆钩子,实现快时尚电商场景下的自动化记忆管理""" registry.add_callback(MessageAddedEvent, self.retrieve_memories) registry.add_callback(AfterInvocationEvent, self.save_memories) logger.info("记忆钩子已注册")左右滑动查看完整示意
AgentCore Memory记忆分支
AgentCore Memory分支是一项强大的功能,使多个专业化Agent能够维护隔离的记忆上下文,同时共享公共记忆资源。这对于多Agent系统至关重要,特别是那些使用“并行执行模式”的系统。在多Agent系统中,不同的Agent通常需要:
-
维护单独的对话上下文:每个Agent专注于其领域而不受干扰
-
并行执行:多个Agent可以同时工作而不会发生记忆冲突
-
共享公共会话:所有Agent贡献到同一用户会话,同时保持其上下文隔离
-
访问相关历史:Agent可以检索自己过去的交互而不混合上下文
AgentCore Memory分支通过允许在单个记忆会话内有多个对话分支来解决这些挑战,类似于代码的Git分支。
场景示例
假设您正在构建一个具有三个Agent的快时尚电商智能购物系统,每个都有自己的记忆分支:
-
Shopping Coordinator:协调整体购物流程,理解顾客需求
-
Style Recommendation Agent:处理穿搭推荐和风格建议
-
Order&Logistics Agent:管理订单查询和物流追踪
协调器可以委托给并行执行的专业化Agent,每个都通过记忆分支维护自己的对话历史。
-
所有Agent共享相同的memory_id和session_id
-
每个Agent获得自己的branch_name以实现隔离上下文
+---------------------------------------------------------------+ | AgentCore Runtime Layer | | | | session_id | | (single conversation / single reasoning lifecycle) | | | | +---------------+ +---------------+ +---------------+ | | | Agent A | | Agent B | | Agent C | | | | | | | | | | | | STM / Msgs | | STM / Msgs | | STM / Msgs | | | | Hooks | | Hooks | | Hooks | | | | | | | | | | | | memory_id | | memory_id | | memory_id | | | | branch = A | | branch = B | | branch = C | | | | | | | | | | | +---------------+ +---------------+ +---------------+ | | | | | +---------------------------------------------------------------+ | | (persistent across sessions) v +---------------------------------------------------------------+ | Organized Storage / LTM Layer | | | | memory_id | | (long-term memory namespace) | | | | +-------------------------------------------------------+ | | | Branch: A ← written/read by Agent A | | | +-------------------------------------------------------+ | | | | +-------------------------------------------------------+ | | | Branch: B ← written/read by Agent B | | | +-------------------------------------------------------+ | | | | +-------------------------------------------------------+ | | | Branch: C ← written/read by Agent C | | | +-------------------------------------------------------+ | | | +---------------------------------------------------------------+左右滑动查看完整示意
核心运行特性
上下文隔离:每个Agent维护自己的对话历史而不受干扰
-
穿搭推荐Agent只看到与风格搭配相关的对话
-
订单物流Agent只看到与订单和配送相关的对话
-
协调器看到主要的编排流程
并行执行安全:多个Agent可以同时执行
-
Agent并行运行时没有记忆冲突
-
每个分支独立可访问
清晰的审计跟踪:每个Agent的交互都是可追踪的
-
检查每个Agent讨论了什么
-
调试Agent特定问题
-
理解多Agent对话的流程
结语
在快时尚电商这个瞬息万变的行业中,速度和个性化体验是制胜的关键。从双十一的流量洪峰到日常的海量客服咨询,从千人千面的穿搭推荐到复杂的供应链协同,AI Agent正在成为快时尚电商企业不可或缺的智能助手。
Amazon Bedrock AgentCore Runtime不仅仅是一个技术框架,它是将AI Agent从实验室带入真实业务场景的桥梁。对于快时尚电商企业而言,这意味着:
-
您可以在几天而非几个月内部署一个能够处理百万级并发咨询的智能客服系统。
-
您可以构建一个真正“懂”顾客的穿搭推荐Agent,它记得每位顾客的尺码偏好、风格喜好,甚至上次购物时提到的那条“想搭配新买的白色阔腿裤”的需求。
-
您可以让多个专业Agent协同工作——一个负责推荐、一个负责库存查询、一个负责物流追踪——它们各司其职又无缝配合。
本文深入探讨展示了AgentCore Runtime如何解决快时尚电商在大规模运营AI Agent时面临的实际挑战:会话隔离确保每位顾客的购物体验独立且安全;自动扩展让您从容应对促销季的流量高峰;长期记忆让您的Agent真正“认识”每一位回头客。
曾经需要数月后端工程才能实现的智能化能力,现在开箱即用。借助AgentCore Runtime,快时尚电商企业获得了快速迭代、敏捷部署的能力,确保AI Agent高效运行,完全符合企业级的安全和可靠性标准。
在这个“快”字当头的行业,AgentCore Runtime让您的AI能力也能跟上快时尚的节奏。在未来的工作中,我们将进一步深度解析不同的快时尚电商领域的复杂Agent场景的架构设计,并展示基于AgentCore Runtime开发测试部署复杂Agent的具体实现。
本篇作者

张羽
亚马逊云科技解决方案架构师

王一凡
亚马逊云科技解决方案架构师,目前专注于为汽车行业客户提供技术咨询与解决方案设计,与此同时,他还积极探索生成式AI的应用,力求将这些创新应用带入实际业务场景,帮助企业提升效率与竞争力。
新用户注册海外区域账户,可获得最高200美元服务抵扣金,覆盖Amazon Bedrock生成式AI相关服务。“免费计划”账户类型,确保零花费,安心试用。



星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)