
Clawdbot+Qwen3:32B行业落地:企业内部AI助手搭建案例
本文介绍了如何在星图GPU平台上自动化部署Clawdbot整合qwen3:32b代理网关与管理平台镜像,快速构建企业内部AI助手系统。该方案支持本地化部署Qwen3:32B大模型,通过Clawdbot提供统一API网关和会话管理,典型应用于企业客服工单处理、合同审核等场景,确保数据安全与业务高效协同。
·
Clawdbot+Qwen3:32B行业落地:企业内部AI助手搭建案例
1. 企业AI助手需求背景
在数字化转型浪潮中,越来越多的企业开始寻求构建自己的AI助手系统。这类系统需要满足几个核心需求:
- 数据安全性:处理企业内部敏感数据时,必须确保数据不离开企业网络
- 专业领域知识:需要针对行业术语和业务流程进行定制优化
- 稳定可控:7×24小时稳定运行,响应速度符合业务要求
- 易于管理:提供统一的管理界面,降低运维复杂度
传统方案通常面临两个困境:要么使用公有云API存在数据泄露风险,要么自建大模型基础设施成本过高。Clawdbot与Qwen3:32B的组合恰好提供了平衡点——在本地部署高性能大模型的同时,通过轻量级管理平台实现便捷操作。
2. 技术方案概述
2.1 架构设计
本方案采用三层架构设计:
- 模型层:基于Ollama框架本地化部署Qwen3:32B大模型
- 网关层:Clawdbot提供统一的API网关和会话管理
- 应用层:Web界面或企业现有系统通过标准API接入
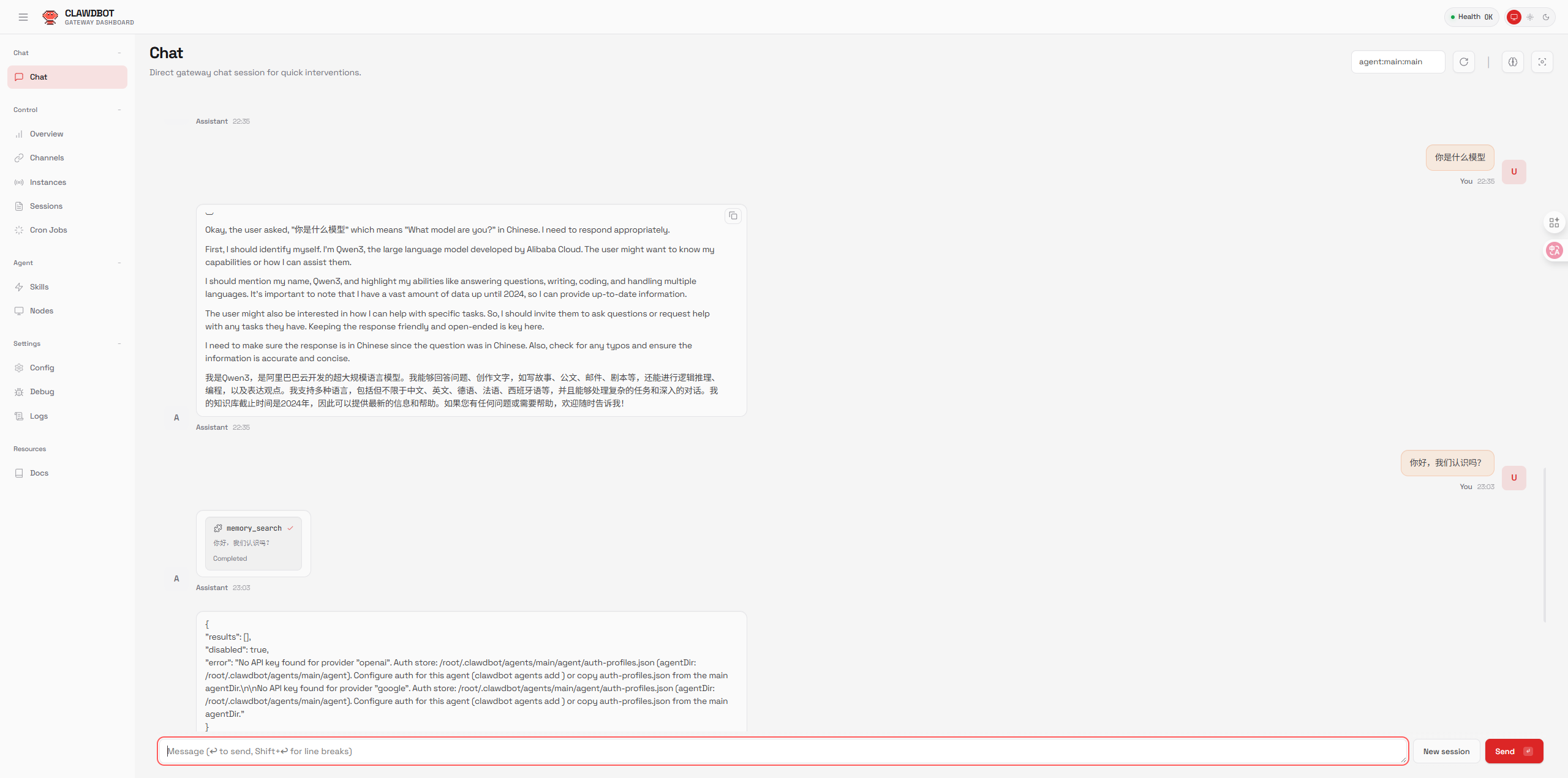
2.2 核心组件介绍
2.2.1 Qwen3:32B模型优势
- 中文能力突出:在C-Eval、CMMLU等中文评测中表现优异
- 长上下文支持:32K tokens上下文窗口,适合处理复杂文档
- 多轮对话稳定:对话状态保持能力强,不易出现逻辑混乱
- 量化版本高效:4-bit量化后仅需18GB显存,24G显卡即可流畅运行
2.2.2 Clawdbot核心功能
- 统一API网关:标准化不同模型的调用接口
- 会话管理:维护多轮对话上下文
- 权限控制:基于token的访问鉴权
- 监控看板:实时展示请求量、响应时间等指标
3. 部署实施步骤
3.1 基础环境准备
硬件配置建议
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| CPU | 8核 | 16核+ |
| 内存 | 32GB | 64GB+ |
| GPU | RTX 3090 | A100 40G |
| 存储 | 100GB | 200GB+ |
软件依赖
# Ubuntu系统基础依赖
sudo apt update && sudo apt install -y \
curl git python3-pip \
nvidia-driver-535 nvidia-utils-535
3.2 Ollama与模型部署
# 下载Ollama
curl -L https://ollama.com/download/ollama-linux-amd64 -o ollama
chmod +x ollama
# 安装服务
sudo ./ollama service install
# 拉取Qwen3模型(需先配置镜像加速)
OLLAMA_HOST=0.0.0.0 ./ollama pull qwen3:32b
# 启动服务(后台运行)
OLLAMA_HOST=0.0.0.0 ./ollama serve &
3.3 Clawdbot配置与启动
配置文件示例
# config.yaml
server:
port: 8080
auth_token: "your_secure_token"
models:
- name: "qwen3-32b"
backend: "ollama"
endpoint: "http://localhost:11434"
params:
temperature: 0.7
max_tokens: 2048
启动命令
./clawdbot onboard --config config.yaml
3.4 访问配置
初次访问需要添加token参数:
- 获取初始访问URL(控制台输出)
- 修改URL格式:
原始URL: https://your-domain.com/chat?session=main 修改后: https://your-domain.com/?token=your_secure_token - 首次成功访问后,后续可直接使用快捷入口
4. 企业级功能实现
4.1 知识库集成
通过Clawdbot的扩展系统接入企业知识库:
# 知识库插件示例
from clawdbot.extensions import BaseExtension
class KnowledgeBaseExtension(BaseExtension):
def handle_query(self, query):
# 调用内部知识库API
results = internal_kb_search(query)
return format_as_markdown(results)
4.2 业务流程对接
典型集成场景:
- 客服工单处理:自动分析用户问题并生成初步回复
- 合同审核:提取关键条款并提示风险点
- 数据分析:自然语言查询转换为SQL语句
- 培训考试:自动生成岗位知识测试题
4.3 权限管理方案
# 多租户配置示例
tenants:
- name: "finance"
models: ["qwen3:32b"]
access_token: "finance_token"
rate_limit: 10/分钟
- name: "hr"
models: ["qwen3:32b"]
access_token: "hr_token"
rate_limit: 30/分钟
5. 性能优化实践
5.1 GPU资源调配
# 限制GPU内存使用比例
CUDA_VISIBLE_DEVICES=0 OLLAMA_GPU_MEMORY_UTILIZATION=0.8 ./ollama run qwen3:32b
# 多GPU负载均衡
CUDA_VISIBLE_DEVICES=0,1 OLLAMA_GPU_SPLIT=50 ./ollama run qwen3:32b
5.2 缓存策略优化
启用对话缓存减少重复计算:
# config.yaml
caching:
enabled: true
ttl: 3600 # 1小时缓存
strategy: "semantic" # 语义相似匹配
5.3 监控与告警
Prometheus监控指标示例:
# HELP clawdbot_requests_total Total number of API requests
# TYPE clawdbot_requests_total counter
clawdbot_requests_total{model="qwen3:32b",status="success"} 1423
clawdbot_requests_total{model="qwen3:32b",status="error"} 27
# HELP clawdbot_response_time_seconds Response time in seconds
# TYPE clawdbot_response_time_seconds histogram
clawdbot_response_time_seconds_bucket{model="qwen3:32b",le="0.5"} 893
6. 安全加固措施
6.1 网络隔离方案
- 模型服务仅监听内网IP
- Clawdbot网关配置IP白名单
- 敏感接口启用双向TLS认证
6.2 数据过滤机制
# 敏感数据过滤器示例
def sanitize_input(text):
patterns = [
r'\b\d{4}-\d{4}-\d{4}-\d{4}\b', # 银行卡号
r'\b\d{18}\b' # 身份证号
]
for pattern in patterns:
text = re.sub(pattern, '[REDACTED]', text)
return text
6.3 审计日志配置
logging:
level: info
format: json
rotation:
max_size: 100MB
keep_days: 30
audit_fields: ["timestamp", "user", "model", "input_length", "output_length"]
7. 总结与展望
本方案通过Clawdbot+Qwen3:32B的组合,实现了:
- 成本可控:单台服务器即可部署,无需大规模GPU集群
- 安全合规:数据全程不离开企业内网
- 易于扩展:支持后续接入更多模型和业务系统
- 维护简单:提供统一的管理界面和监控指标
未来可进一步优化方向:
- 结合LoRA进行领域适配微调
- 实现多模型自动路由
- 开发移动端管理应用
- 增强自动化运维能力
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 7
7 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)