
【ai】AI应用开发课回顾(一)基础知识篇
本文总结了作者参加免费AI应用开发课程后的学习笔记,主要梳理了五个关键技术点:1)提示词工程四要素(角色、指令、背景、限制);2)RAG技术流程(数据准备和应用两阶段);3)FunctionCalling与MCP的结合使用;4)AI Agent的运作机制;5)模型微调方法(SFT、RLHF等)。虽然课程本身存在内容重复和推销问题,但作者系统整理了这些核心概念,为后续实践打下理论基础。文章重点解析了
楔子
报名了一个为期两天的“AI应用技术开发课程“(免费的),希望能够简单的形成个AI应用开发的知识结构的了解,补充一下直接上手摸着石头过河的方式”学习“后缺失的”概念性知识点“。
课程内容号称:让你全面掌握大模型训练、RAG、Agent、Function Calling、Fine-tuning、MCP等大模型相关岗位的核心技能。
上完两节课之后,只是有一个大概的了解(因为大半时间都在“推销收费课程“ and 两节课基本上是换不同的老师把同样的内容以不同的描述方式重新讲一遍)。
然后发了一堆的”自学资料“~
虽然感觉课上的收获不多,但本着不能白上的原则,准备按照课里的知识脉络,把AI应用的相关知识和应都系统的学习和实践一下,同时产出一系列文章。
概况
第一篇文章主要把两节课里老师重复讲的几个知识点都滤一遍,对讲的比较”粗糙“的地方进行”深入“的自学。目的是彻底弄明白AI应用技术开发的核心知识和实现过程。
主要包括:
prompt 提示词工程
RAG 检索增强生成
function calling 与外部工具的能力
agent 智能体
fine tuning 模型微调
提示词工程
提示词可以包含以下任意要素:
指令:想要模型执行的特定任务或指令。
上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
输入数据:用户输入的内容或问题。
输出指示:指定输出的类型或格式。
记住四要素:角色、指令、背景、限制。
角色与背景:为 AI 设定一个身份或场景,引导其使用特定的知识体系和表达方式。
任务与指令:清晰、具体地说明你要 AI 完成什么任务。这是提示词的核心。
步骤与约束:将复杂任务分解为步骤,或添加格式、长度、风格等限制条件。
输出格式:明确指定你希望的回答格式,如 JSON、Markdown、表格、代码块等。
输入示例:提供一两个输入-输出的例子,让 AI 更准确地模仿你想要的模式(少样本学习)。
提示工程指南![]() https://www.promptingguide.ai/zh
https://www.promptingguide.ai/zh
RAG
RAG(Retrieval Augmented Generation,检索增强生成)= 外部知识源的检索 + LLM(大规模语言模型)提示。
原始 RAG 的流程包括索引、检索和生成三个步骤,既把问答内容输入到数据库中,给定query,可以直接去数据库中搜索,搜索完成后把查询结果和query拼接起来送给模型去生成内容。
通过外部资源或数据库中纳入相关信息实现,通过句子or段落的语义相似度比较,检索相关资料,在资料支持下生成回复
数据准备阶段:数据提取—>文本分割—>向量化(embedding)—>数据入库 「离线」
文档切块(外部知识库用的,拆出不同的框架or模块)——向量化(也叫文本嵌入)——存到向量模型;
嵌入也叫向量化,就是将文本内容通过embedding嵌入模型转化为多维向量的过程。
工具:langchain, llama-index……
应用阶段:用户提问—>数据检索(召回)—>注入Prompt—>LLM生成答案 「在线」
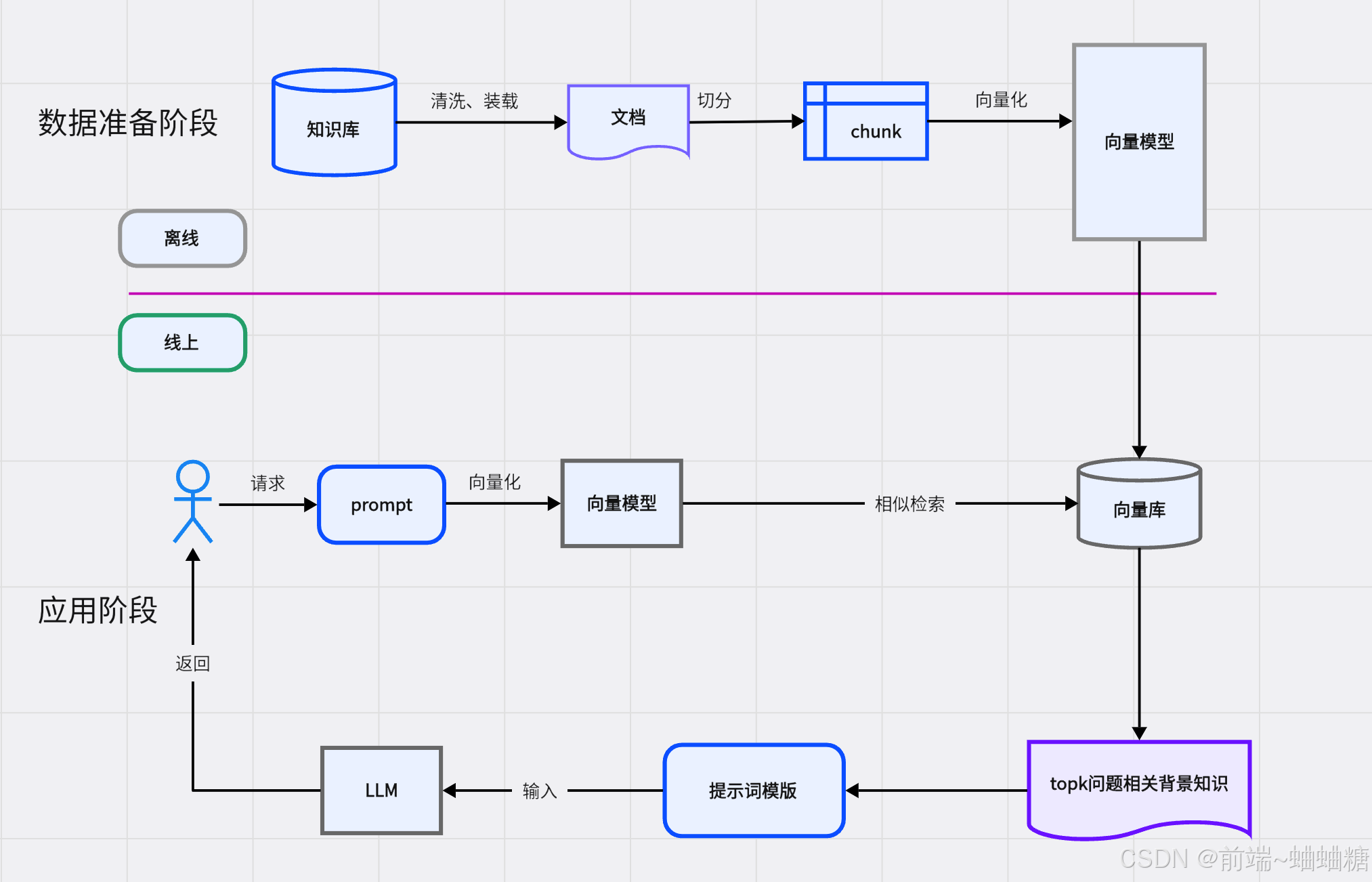
总结:
-
不改动大模型本身,不用重新训练
-
外接一个私有/实时更新的知识库
-
用户提问→先去库里找相关内容→把资料+问题一起给大模型→大模型基于资料生成答案
-
答案有依据、不幻觉、知识实时更新
Function calling 和 MCP
function calling (让模型直接调用函数接口的指令书)
协议MCP(全称 Model-Conditioned Prompting,可以理解为“大模型条件化提示”)

基于LLM语音理解能力,通过理解语义,自主决策使用某项工具,并结构化调用工具(需要结构化信息-填槽:自动填写调用工具得到答案需要的问题,不能自动填空的向用户提问),基于返回的结构化信息,整合生成回复。
实现步骤:
定义函数:首先,开发者需要定义一系列可供模型调用的函数,包括函数名称、描述、参数(参数类型、描述等)。这些定义会作为系统提示的一部分提供给模型。
用户查询:用户提出一个自然语言请求。
模型决策:模型根据用户请求和可用的函数定义,决定是否需要调用函数。如果不需要,则直接生成自然语言回复;如果需要,则选择要调用的函数并生成参数。
执行函数:系统收到模型生成的函数调用请求后,在本地执行相应的函数(或调用API)。
返回结果:将函数执行的结果返回给模型。
生成回复:模型根据函数返回的结果,生成最终的自然语言回复给用户。
与 AI Agent 的关系
AI Agent 可以理解为多能力组合的智能体,本质上是:
• 接收用户输入
• 调用大模型生成指令
• 根据指令调用系统接口(API / 数据库 / 工具)
• 返回结果给用户
在 Agent 架构中:
• MCP:用来优化模型生成策略,让 Agent 更聪明。
• Function Calling:让 Agent 真正去执行操作,不只是生成文本。
也就是说,MCP + Function Calling = AI Agent 的核心能力组合。
fine tuning
预训练模型 (Base Model): 懂很多道理,但不会具体干活。比如它知道什么是“医疗诊断”,但不能像医生一样开处方。
微调模型 (Chat/Instruct Model): 学会了指令遵循(Instruction Following)和特定领域的行话(Domain Knowledge)。
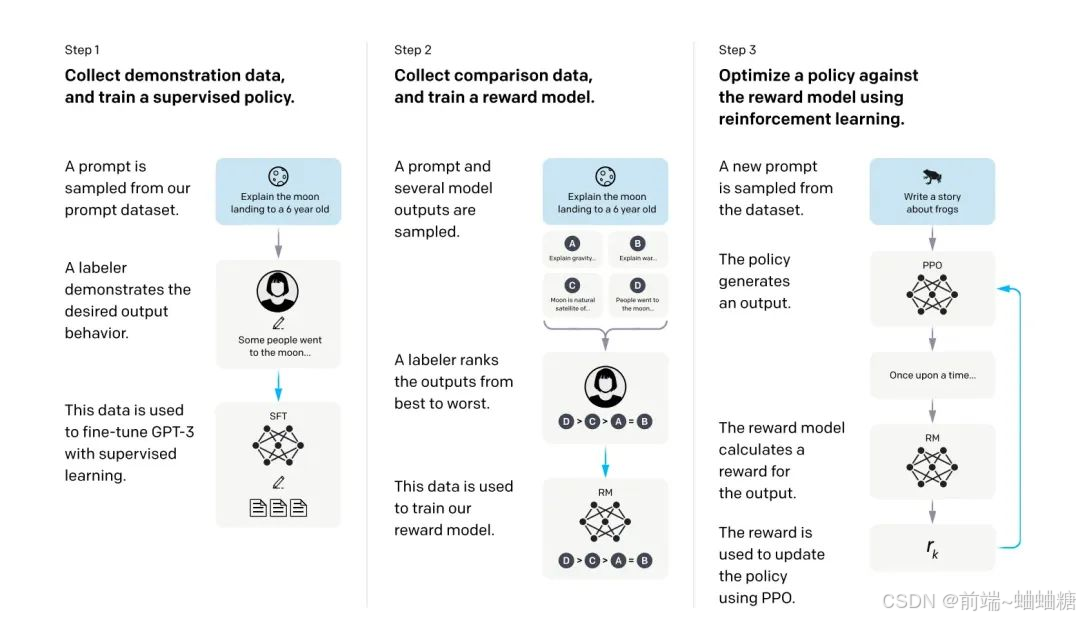
预训练 → 微调(SFT) → 强化学习(RLHF) → 模型修剪与优化。
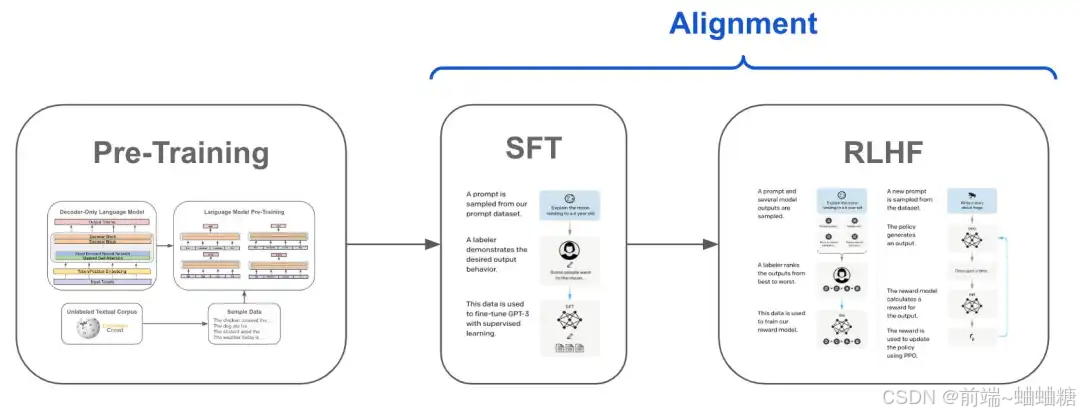
1.在大规模文本数据集上进行预训练,形成基础的语言能力(GPT3)。
2.通过监督微调,让模型适应对话任务,使其生成的文本更符合人类对话习惯。
3.使用基于人类反馈的强化学习(使用用户反馈数据,如赞踩、评分),进一步优化模型的输出质量,使其在多轮对话中表现得更连贯和有效。
4.通过持续的微调和更新,适应新需求并确保输出的安全性和伦理性。
微调分类:
SFT(Supervised Fine-Tuning,监督微调)是一种微调的类型。
无监督微调(Unsupervised Fine-Tuning),在没有明确标签的情况下,对预训练模型进行微调
自监督微调(Self-Supervised Fine-Tuning),模型通过从输入数据中生成伪标签(如通过数据的部分遮掩、上下文预测等方式),然后利用这些伪标签进行微调。
监督微调(SFT)
定义:在新任务的小规模标注数据集上,使用有监督学习的方法对预训练模型进行微调,以使其适应新任务。
步骤:加载预训练模型 → 准备新任务的数据集 → 调整模型输出层 → 在新任务数据集上训练模型。
应用:适用于那些有明确标注数据集的任务,如文本分类、命名实体识别等。
基于人类反馈的强化学习微调(RLHF)
定义:在SFT的基础上,通过强化学习和人类反馈来进一步微调模型,使其输出更加符合人类的偏好或期望。
步骤:首先进行SFT → 收集人类反馈数据 → 训练奖励模型 → 使用奖励模型指导强化学习过程来微调模型。
应用:适用于那些需要高度人类判断或创造力的任务,如对话生成、文本摘要等。
全面微调(Full Fine-tuning)
定义:在新任务上调整模型的全部参数,以使其完全适应新任务。
步骤:加载预训练模型 → 在新任务数据集上训练模型,调整所有参数。
应用:当新任务与预训练任务差异较大,或者想要充分利用新任务数据集时,可以选择全面微调。
部分/参数高效微调(PEFT)
定义:仅调整模型的部分参数,如添加一些可训练的适配器(adapters)、前缀(prefixes)或微调少量的参数,以保持模型大部分参数不变的同时,实现对新任务的适应。
步骤:加载预训练模型 → 在模型中添加可训练的组件或选择部分参数 → 在新任务数据集上训练这些组件或参数。
应用:当计算资源有限,或者想要快速适应新任务而不影响模型在其他任务上的性能时,PEFT是一个很好的选择。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)