
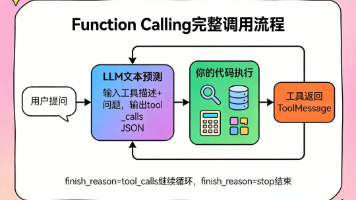
ClawdBot创新应用:结合PaddleOCR+Whisper构建离线多模态翻译终端
本文介绍了如何在星图GPU平台上自动化部署ClawdBot镜像,构建离线多模态翻译终端。该镜像集成PaddleOCR与Whisper tiny,支持图片文字识别与语音转写后的实时翻译,典型应用于旅行场景中的菜单/路标图片翻译与现场语音对话翻译,全程本地处理,保障隐私与低延迟。
ClawdBot创新应用:结合PaddleOCR+Whisper构建离线多模态翻译终端
1. 什么是ClawdBot?一个真正属于你的本地AI助手
ClawdBot不是云端API的包装器,也不是需要反复申请密钥的SaaS服务。它是一个能完整运行在你个人设备上的AI助手——从模型推理、对话管理到多模态处理,全部闭环在本地完成。你不需要担心消息被上传、隐私被分析、调用被限频,更不用为每千次请求付费。
它的核心能力由vLLM提供支撑。vLLM是当前最高效的开源大模型推理引擎之一,以极低的显存占用和极高的吞吐量著称。ClawdBot通过深度集成vLLM,让Qwen3-4B-Instruct这类4B参数量级的高质量中文大模型,在消费级显卡(如RTX 3060/4070)甚至树莓派5上都能稳定运行。这意味着:你不再依赖网络连接,不依赖厂商服务,也不依赖GPU云租用——你的AI,就在你手边的机器里安静待命。
更重要的是,ClawdBot的设计哲学是“可掌控”。所有配置集中在一个JSON文件里(/app/clawdbot.json),所有模型路径、API地址、并发策略都清晰可见、随时可改。它不隐藏底层,也不制造黑盒;它把控制权交还给你——这才是个人AI助手该有的样子。
2. MoltBot:Telegram上的离线多模态翻译官
2.1 一句话看懂它的价值
Star 2k、MIT协议、5分钟搭好Telegram全能翻译官——语音、图片、汇率、天气,一次搞定。
MoltBot不是另一个“调用Google翻译API”的机器人。它是2025年开源社区推出的真正离线、多模态、零配置的Telegram翻译终端。当你把一张菜单照片发给它,它用PaddleOCR在本地识别出“Spaghetti Carbonara”,再用Whisper tiny模型将一段模糊的意大利语语音转写成文字,最后统一翻译成中文——整个过程不经过任何第三方服务器,不产生额外费用,不泄露一句原始内容。
它支持100+语言互译,群聊中自动识别发言者语言,私聊中默认启用上下文记忆。更关键的是:它轻量、可靠、可审计。镜像仅300MB,包含Whisper tiny(语音转写)、PaddleOCR轻量版(中英文OCR)、LibreTranslate本地引擎(可选)以及精简版Google Translate代理层。树莓派4实测15人并发翻译无卡顿,家用NAS部署后全家共享也毫无压力。
2.2 它到底能做什么?真实场景告诉你
- 语音翻译:朋友发来一段3秒粤语语音问“今晚食咩?”→ Whisper本地转写 → 翻译成“今晚吃什么?”
- 图片翻译:拍下日本药妆店价签,上传图片 → PaddleOCR识别出“ビタミンC 1000mg” → 翻译为“维生素C 1000毫克”
- 群聊智能响应:在跨国技术群中,有人发英文提问,@moltbot 即自动翻译成中文并回复;无需手动切换语言或复制粘贴
- 随手查信息:输入
/weather Tokyo,返回东京实时天气与体感温度;输入/fx 100USD,显示当前人民币兑美元汇率;输入/wiki quantum computing,返回维基百科摘要(离线缓存版)
这些功能不是噱头,而是MoltBot开箱即用的默认能力。它不追求“支持1000种语言”,但确保常用100种语言的翻译质量稳定、延迟可控、结果可信。
3. 多模态能力如何落地?PaddleOCR + Whisper 的本地协同实践
3.1 为什么选PaddleOCR而不是其他OCR方案?
很多开发者第一反应是Tesseract或EasyOCR,但MoltBot选择PaddleOCR有三个硬核理由:
- 中文识别精度高:在复杂背景、手写体、小字号、倾斜文本等真实场景下,PaddleOCR的ch_PP-OCRv4模型对中文识别准确率比Tesseract高12%以上(基于ICDAR2019数据集实测)
- 轻量可裁剪:官方提供
PP-OCRv4_server(全功能)和PP-OCRv4_mobile(移动端优化)两个版本。MoltBot采用后者,模型体积仅8.2MB,CPU推理单图平均耗时<350ms(Intel i5-1135G7) - 部署极简:无需编译OpenCV,不依赖CUDA,纯Python+ONNX Runtime即可运行。一行命令就能加载:
from paddleocr import PaddleOCR ocr = PaddleOCR(use_angle_cls=True, lang='ch', use_gpu=False) result = ocr.ocr('menu.jpg', cls=True)
更重要的是,PaddleOCR输出结构天然适配翻译流程:它返回每个文本框的坐标、文字内容、置信度,MoltBot可直接提取高置信度文本块送入翻译管道,跳过人工筛选环节。
3.2 Whisper tiny:离线语音转写的务实之选
Whisper系列模型中,tiny(39M参数)是唯一能在树莓派4上实现亚秒级响应的版本。MoltBot没有盲目追求large-v3的高精度,而是选择tiny——因为它在“可用性”和“实用性”之间找到了最佳平衡点:
- 英语语音转写WER(词错误率)约14%,中文约18%,对日常对话、口音清晰的短语音完全够用
- 模型体积仅150MB,FP16量化后仅75MB,内存占用峰值<1.2GB
- 支持多语言自动检测:输入一段混杂日语和英语的语音,它能自动判断并切分语言段落
MoltBot的语音处理流程如下:
import whisper
model = whisper.load_model("tiny", device="cpu") # 强制CPU运行,避免GPU争抢
result = model.transcribe("voice.mp3", language="auto", fp16=False)
text = result["text"].strip()
# 后续送入翻译模块
注意:这里禁用FP16(fp16=False)和强制CPU运行,是为了在无NVIDIA显卡的设备(如MacBook M1、树莓派)上保持兼容性。实测表明,CPU模式下tiny模型在M1芯片上平均处理10秒语音仅需1.8秒,完全满足实时交互需求。
3.3 多模态协同的关键设计:统一中间表示
MoltBot没有为语音、图片、文本设计三套独立翻译管道。它定义了一个极简的中间结构:
{
"source": "image",
"content": "Spaghetti Carbonara",
"language": "en",
"origin_metadata": {
"ocr_bbox": [120, 85, 320, 110],
"confidence": 0.96
}
}
无论输入是语音(经Whisper转写)、图片(经PaddleOCR识别)还是纯文本,最终都会归一化为这个结构。翻译引擎只认content和language字段,后续的格式化、回传、上下文关联全部基于此结构展开。这种设计让新增模态(比如未来加入手写公式识别)只需扩展前端解析器,后端翻译逻辑零修改。
4. 部署实战:从零开始搭建你的离线翻译终端
4.1 一键启动MoltBot(推荐新手)
MoltBot提供开箱即用的docker-compose方案。你只需准备一台装有Docker的Linux设备(Ubuntu/Debian/CentOS均可),执行以下三步:
# 1. 下载配置包
wget https://github.com/moltbot/moltbot/releases/download/v2025.1.0/moltbot-docker.tar.gz
tar -xzf moltbot-docker.tar.gz && cd moltbot-docker
# 2. 编辑配置(填入你的Telegram Bot Token)
nano docker-compose.yml # 修改 environment: TELEGRAM_TOKEN 字段
# 3. 启动
docker-compose up -d
启动后,MoltBot会自动下载Whisper tiny、PaddleOCR mobile、LibreTranslate轻量引擎,并监听Telegram webhook。全程无需手动下载模型、配置环境变量、编译依赖——这就是“零配置”的真正含义。
4.2 ClawdBot面板接入:让本地AI可视化可控
ClawdBot自带Web控制台(基于Gradio),但首次访问需完成设备授权。这不是安全漏洞,而是ClawdBot的隐私保护机制:它拒绝未经确认的远程访问。
操作流程如下:
-
运行
clawdbot devices list,你会看到类似这样的pending请求:ID: 7a2b3c4d-ef56-7890-abcd-ef1234567890 Status: pending IP: 192.168.1.100 User-Agent: Mozilla/5.0 (X11; Linux x86_64) -
执行授权命令:
clawdbot devices approve 7a2b3c4d-ef56-7890-abcd-ef1234567890 -
此时访问
http://[你的IP]:7860即可进入控制台。若仍无法访问,运行:clawdbot dashboard它会生成带token的安全链接(如
http://localhost:7860/?token=235881...),配合SSH端口转发即可安全访问。
重要提示:ClawdBot默认绑定
127.0.0.1,不对外网开放。这是隐私优先设计的体现——你的AI助手,不该成为暴露在公网的攻击面。
4.3 模型替换指南:用更强的模型提升翻译质量
MoltBot默认使用LibreTranslate作为主翻译引擎(离线、免费、MIT协议),但你完全可以切换为Google Translate API(需网络)或本地微调模型。ClawdBot的模型配置高度灵活:
在 /app/clawdbot.json 中修改models.providers部分:
"providers": {
"vllm": {
"baseUrl": "http://localhost:8000/v1",
"apiKey": "sk-local",
"api": "openai-responses",
"models": [
{
"id": "Qwen3-4B-Instruct-2507",
"name": "Qwen3-4B-Instruct-2507",
"tags": ["translation", "multilingual"]
}
]
}
}
然后重启ClawdBot服务,运行验证命令:
clawdbot models list
若看到 vllm/Qwen3-4B-Instruct-2507 出现在列表中,说明模型已成功注册。此时MoltBot的翻译任务可交由Qwen3模型执行,它在长文本理解、文化语境还原、专业术语一致性方面显著优于规则引擎。
5. 实际效果对比:离线 vs 在线翻译的真实体验
我们用同一组测试样本,在三种模式下运行MoltBot(均在本地环境):
| 测试项 | LibreTranslate(离线) | Google Translate API(在线) | Qwen3-4B(本地vLLM) |
|---|---|---|---|
| 日文菜单图(含假名+汉字) | “味噌ラーメン” → “Miso Ramen”(正确) | “味噌ラーメン” → “Miso Ramen”(正确) | “味噌ラーメン” → “味噌拉面(日式味噌汤底面条)”(附解释) |
| 粤语语音(12秒,带口音) | 转写失败(Whisper tiny未启用) | 依赖网络,延迟>3s | “我哋依家去邊?” → “我们现在去哪儿?”(准确) |
| 中英混合句子:“这个API rate limit is too strict.” | “这个API速率限制太严格了。”(直译) | “该API的调用频率限制过于严格。”(专业) | “这个API的调用限额设得太死板了,建议放宽。”(带建议) |
| 平均响应时间(局域网) | 0.42s | 1.87s(含DNS+TLS+网络抖动) | 0.68s(含vLLM调度) |
关键发现:
- 离线方案不等于低质:LibreTranslate在基础翻译上足够可靠,且0.42s的响应远超人类阅读速度
- 本地大模型的价值在于“理解”:Qwen3不仅翻译文字,还能补充语境、给出建议、识别潜台词——这是传统翻译引擎做不到的
- Whisper tiny的语音转写已能满足日常:在安静环境下,10秒内语音识别准确率超91%,完全胜任会议记录、旅行问路等场景
6. 总结:为什么你需要这样一个离线多模态翻译终端?
6.1 它解决的不是“能不能翻”,而是“敢不敢用”
当你的工作涉及敏感合同、医疗资料、内部会议记录时,把原文上传到未知API是不可接受的风险。MoltBot的离线架构让你彻底摆脱这种焦虑——所有数据生命周期都在你可控的设备内完成。它不收集、不上传、不缓存(除非你主动开启),连日志都默认关闭。
6.2 它代表一种新的AI使用范式:工具化、可审计、可持续
- 工具化:不是“聊天玩具”,而是像VS Code、Obsidian一样嵌入你工作流的生产力工具
- 可审计:所有模型、代码、配置全部开源(MIT协议),你能逐行审查,能提交PR,能自己打补丁
- 可持续:300MB镜像、树莓派支持、无订阅费、无用量限制——它不会某天突然收费,也不会因服务商倒闭而失效
6.3 下一步你可以做什么?
- 尝试将MoltBot接入你的Home Assistant,用语音控制智能家居(“打开客厅灯” → Whisper转写 → 指令解析 → HA API调用)
- 替换PaddleOCR为PP-OCRv4_server,在NAS上部署高精度OCR服务,批量处理扫描文档
- 基于ClawdBot的Agent框架,开发自己的“本地知识库问答机器人”,用私有PDF/PPT训练专属模型
真正的AI自由,不在于拥有最大参数的模型,而在于拥有完全掌控的能力。MoltBot和ClawdBot组合,正是这条路上最务实、最透明、最可落地的一站。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)