
GPUStack × MaxKB:打造强大易用的开源企业级智能体平台(上)
如果你同时在寻找这两个问题的解决方案,那么的组合非常值得尝试。:专注于 GPU 资源管理与模型部署,支持多节点集群和多模型服务。:一个开源的企业级知识库与 AI 应用平台,可以快速构建知识库问答和 AI Agent。通过将,就可以非常方便地构建一个。本文将从零开始,完整演示整个流程。
随着企业内部 AI 应用越来越多,越来越多团队开始关注两个核心问题:
如何高效管理和部署本地大模型
如何快速构建企业知识库与 AI Agent
如果你同时在寻找这两个问题的解决方案,那么 GPUStack + MaxKB 的组合非常值得尝试。
GPUStack:专注于 GPU 资源管理与模型部署,支持多节点集群和多模型服务。
MaxKB:一个开源的企业级知识库与 AI 应用平台,可以快速构建知识库问答和 AI Agent。
通过将 GPUStack 提供的模型服务接入 MaxKB,就可以非常方便地构建一个 可落地的企业 AI 知识助手。
本文将从零开始,完整演示整个流程。
本文内容
-
部署最新 GPUStack v2.1.0
-
在 GPUStack 中部署所需模型
-
获取 GPUStack 模型接入信息
-
部署 MaxKB
-
在 MaxKB 中接入 GPUStack 模型
-
实战示例:制作 GPUStack 文档知识库
安装 GPUStack v2.1.0
1. 安装 GPUStack Server
sudo docker run -d --name gpustack-server \
--restart unless-stopped \
-p 80:80 \
-v gpustack-data:/var/lib/gpustack \
-v /data/gpustack_cache:/var/lib/gpustack/cache \
gpustack/gpustack:v2.1.0 \
--bootstrap-password "123" \
--debug
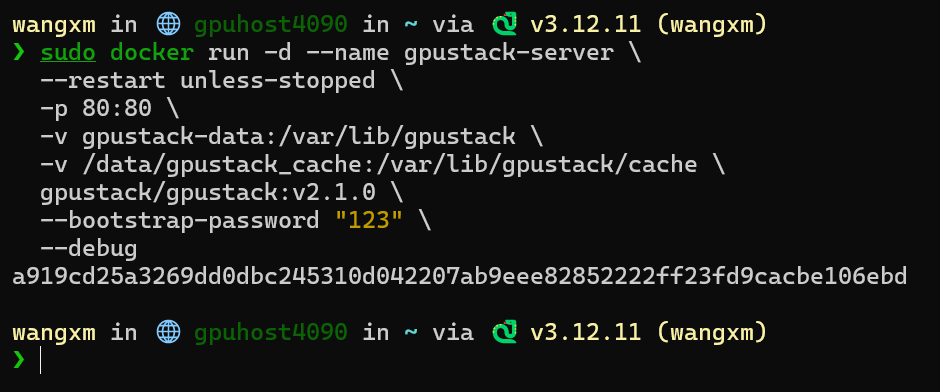
执行如上启动命令后,打开浏览器访问:http://your_host_ip
即可进入 GPUStack UI,用户名密码:admin/123。
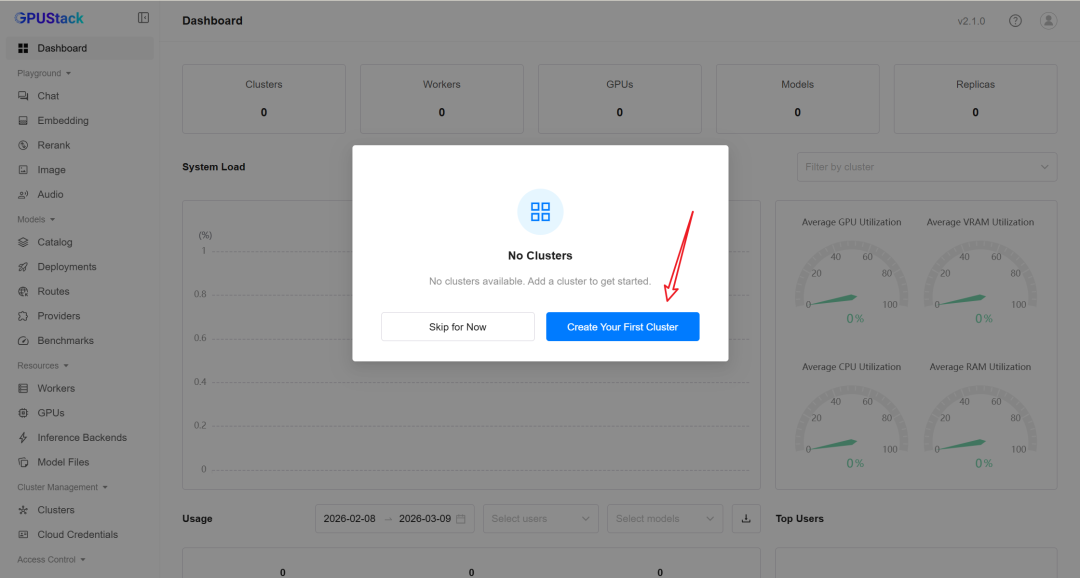
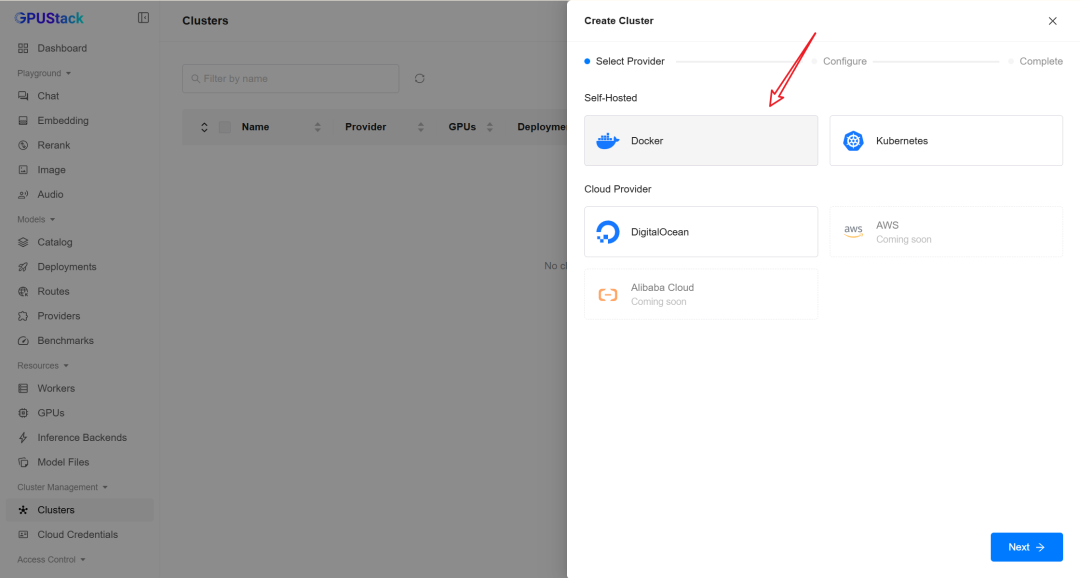
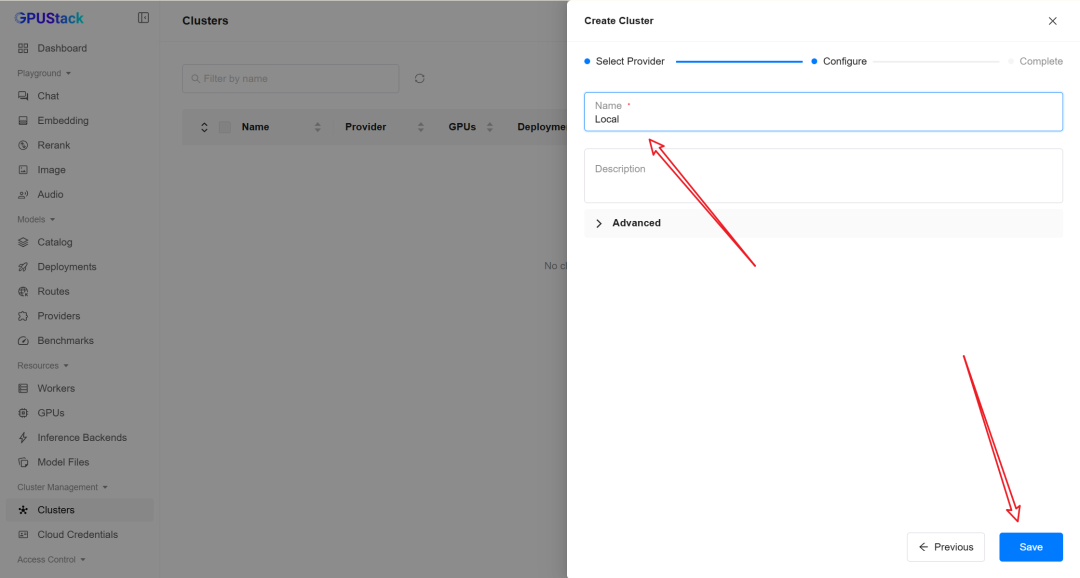
2. 创建集群
GPUStack 以 集群(Cluster) 为单位管理 Worker 节点。
新部署的 GPUStack Server 会提示创建第一个集群,我们点击:
Create Your First Cluster
按照界面提示完成创建即可。
也可以在侧边栏进入 Clusters 页面,点击 Add Cluster 手动创建。
3. 添加 Worker
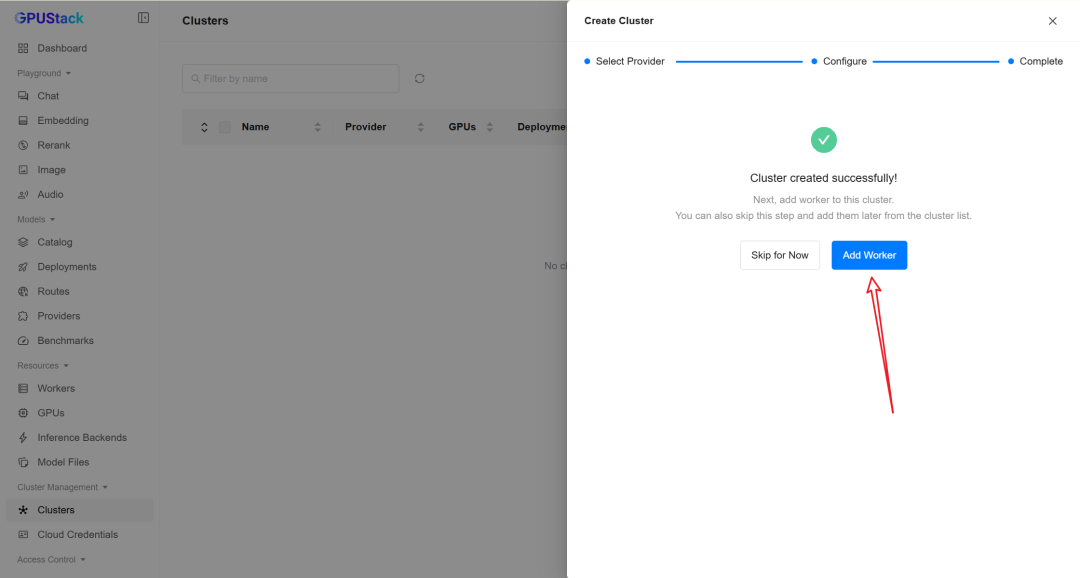
创建完集群后,系统会提示 Add Worker。
我们按照界面提示继续操作即可
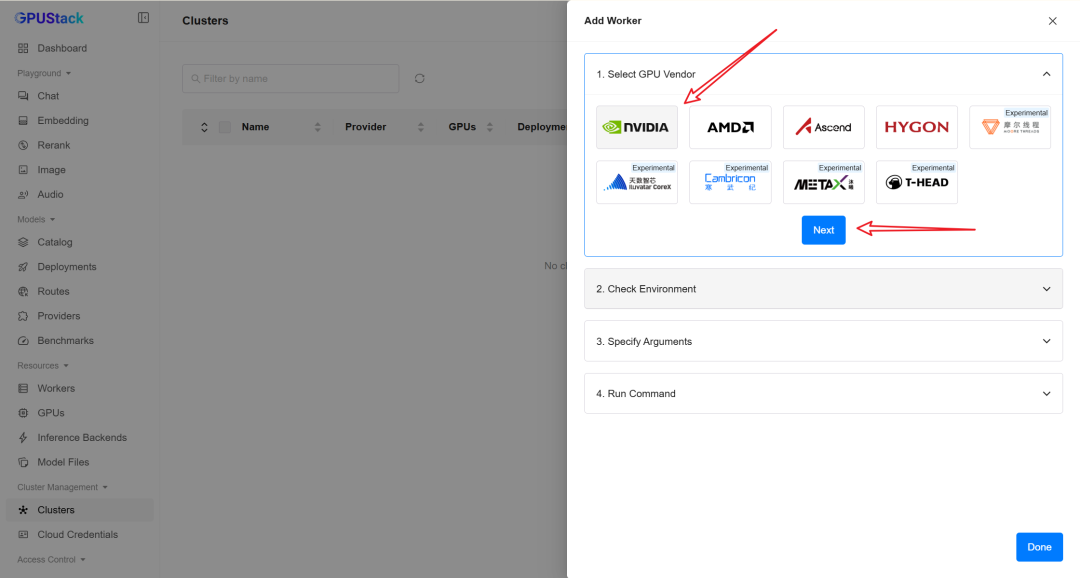
也可以在侧边栏 Workers 页面点击 Add Worker 进行添加。
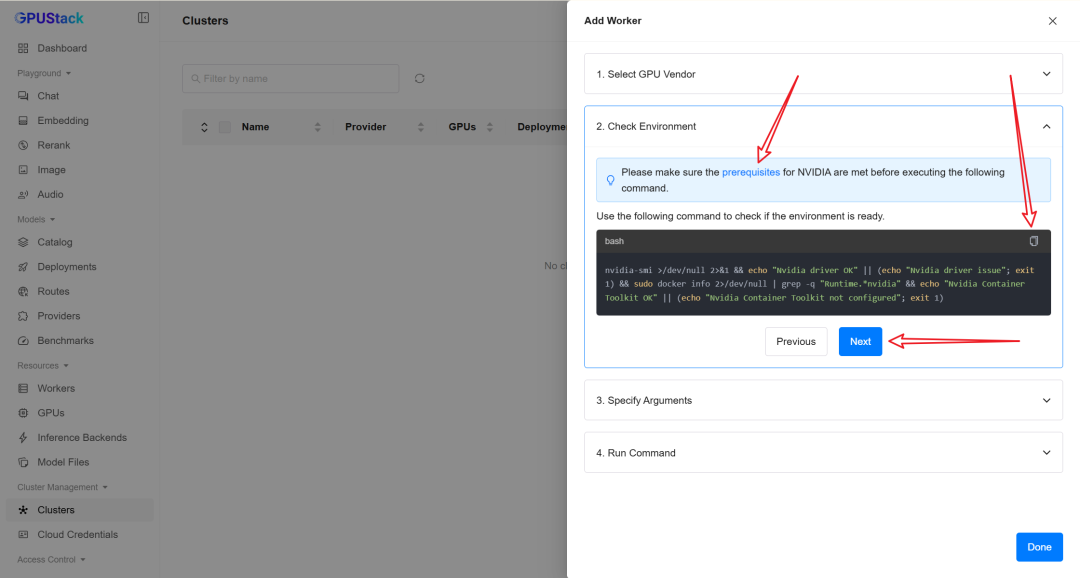
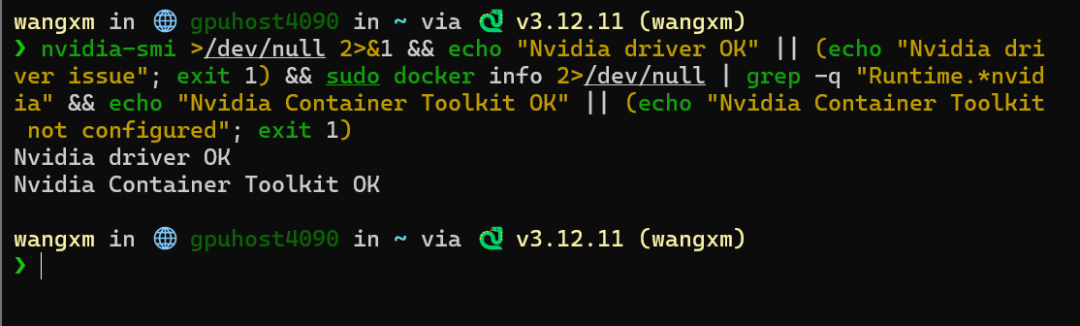
执行引导界面中的检查命令:
如果驱动和容器工具安装正确,将看到两个 OK。
如果显示 not configured,可以点击提示中的链接查看依赖说明,并按实际环境安装缺失组件
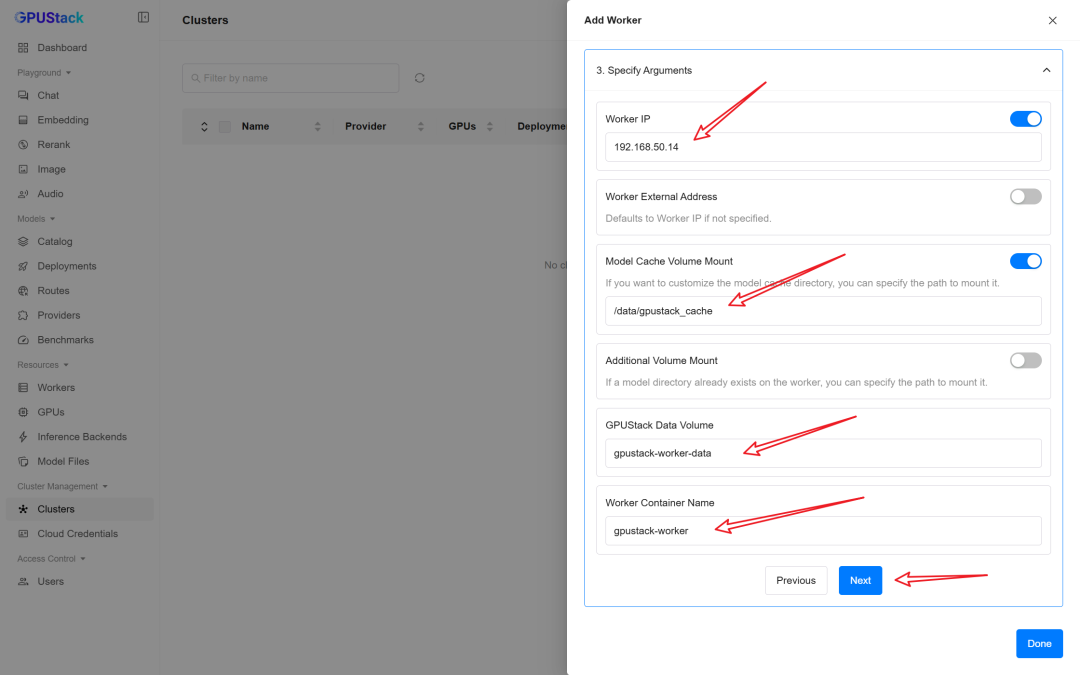
1. Model Cache Volume Mount:将该目录挂载到模型缓存目录 /var/lib/gpustack/cache。
2. GPUStack Data Volume:将该目录挂载到数据目录 /var/lib/gpustack。
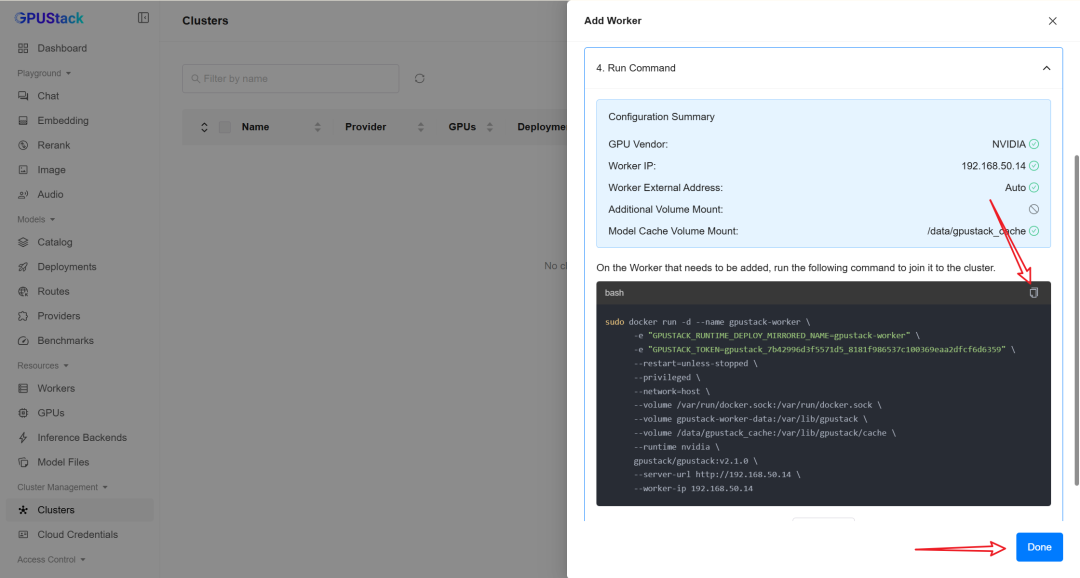
随后执行 Worker 启动命令:
sudo docker run -d --name gpustack-worker \
-e "GPUSTACK_RUNTIME_DEPLOY_MIRRORED_NAME=gpustack-worker" \
-e "GPUSTACK_TOKEN=gpustack_7b42996d3f5571d5_8181f986537c100369eaa2dfcf6d6359" \
--restart=unless-stopped \
--privileged \
--network=host \
--volume /var/run/docker.sock:/var/run/docker.sock \
--volume gpustack-worker-data:/var/lib/gpustack \
--volume /data/gpustack_cache:/var/lib/gpustack/cache \
--runtime nvidia \
gpustack/gpustack:v2.1.0 \
--server-url http://192.168.50.14 \
--worker-ip 192.168.50.14

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)