
<span class=“js_title_inner“>AI那些趣事系列117:从入门到实战:Claude Skills 彻底指南 —— 让 AI 像专业助手一样精准干活</span>
导读:本文是 “数据拾光者” 专栏的第一百一十七篇文章,这个系列聚焦自然语言处理和大模型相关实践。作为一名长期关注AI技术落地的算法架构师,我将结合Anthropic官方文档、开源项目以及一线实战经验,为你系统剖析当前大热的Agent Skills。你将不仅弄懂Skills是什么、为什么重要,更能亲手学会如何开发一个实用的“智能问数”Skill,让你也能为自己的AI助手赋予专业能力。
关键词:Agent Skills, Claude, MCP, 渐进式披露, 智能问数, 低代码开发
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
一、Skills介绍:给AI一本“标准作业程序”手册
相信最近关注AI领域的朋友,都频繁地看到一个词:Skills。各种GitHub上被疯狂star的仓库,很多也都是Skills相关。这股热度,颇有当年全民讨论Prompt Engineering的势头。那么,Skills到底是什么?它为何如此重要?
1.Skills到底是什么?
一句话说清楚:Skill就是一个标准化的文件夹,用来打包AI智能体(Agent)完成特定任务所需的一切知识和工具。
你可以把它理解成给AI的说明书或标准作业程序(SOP)。它不是一次性的对话指令(Prompt),而是一个可复用、可分享的能力包。
举个例子,想象你要带一个绝顶聪明但完全不熟悉公司业务的新人。Prompt就像你站在他旁边,当场口头交代任务:“今天把这个Excel数据整理一下,用折线图展示趋势。” 这个指令只在当前对话有效。
而 Skill 就像你给他一本精心编写的《公司数据分析SOP手册》。这本手册里不仅写了操作步骤,还附带了常用的Python脚本、报表模板、业务指标解释等。以后遇到类似任务,新人自己就会去翻这本手册,稳定地输出符合要求的结果。
这就是Skill的价值:将流程性知识变成可复用的能力包,让AI在需要时随叫随到,稳定发挥。
2.Skill文件夹结构详解
一个标准的Skill文件夹通常包含以下几部分,这是一种“约定优于配置”的组织哲学:

- SKILL.md (核心文件,必需)
:技能的“总说明书”,包含元数据(名称、描述)和详细的指令。
-
-
YAML头部(必需):用---包裹,包含 name和description字段,这是 OpenCode用来识别 Skill 的名片。
-
Markdown 主体(必需):详细的工作流程,输出格式要求,示例等。
-

最核心的就是description这个字段了,就是描述Agent会在何时如何调用你这个skills,一定要始终使用第三人称,比如:处理Excel文件并生成报告。
- scripts/ (脚本目录,可选)
:存放可执行的Python、Shell等脚本。例如,一个PDF处理Skill里可能有
fill_fillable_fields.py这种确定性极强的代码。 - references/ (参考文档,可选)
:存放给AI阅读的知识库,如API文档、数据库Schema、公司政策等。
- assets/ (资源文件,可选)
:存放AI执行任务时直接使用的文件,如PPT模板、公司Logo、项目脚手架等。
关键提醒:文件夹名称必须是「小写字母 + 连字符」格式(比如smart-data-query),不能有空格或大写字母,否则 AI 无法识别。
所以说:一个Skill = 任务说明书(SKILL.md) + 工具代码(scripts) + 专业知识(references) + 素材资源(assets)。它把完成一个特定任务所需的一切都打包好了。
3.实例解析:PPTX creation, editing, and analysis Skill
让我们以Anthropic官方开源的PPTX Skill为例,直观感受一下。其GitHub地址为:https://github.com/anthropics/skills/blob/main/skills/pptx/SKILL.md。
这个PPTX Skill的SKILL.md文件开头是这样的:
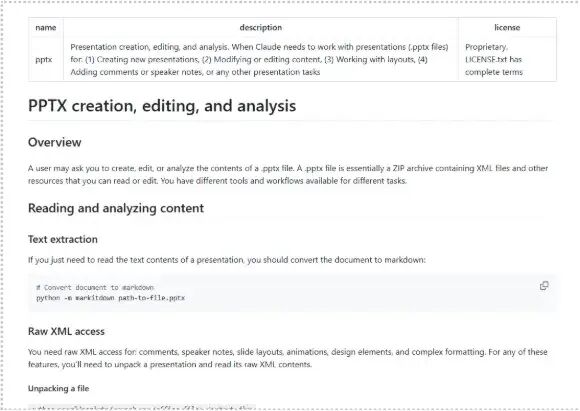
当Claude判断用户任务与PPT相关时,就会加载这个Skill。其正文部分会详细指导AI如何操作PPTX文件,比如如何通过处理原始XML来访问注释、演讲者备注等复杂元素。同时,在 scripts/目录下,可能包含将HTML转换为PPTX的脚本,AI无需临时编写,直接调用即可,高效且可靠。这种组织方式,使得一个复杂的文档处理任务变得模块化、标准化。
Anthropic不仅发布了skills概念,而且开源了一个github仓库,包含很多官方提供的skills源码示例:
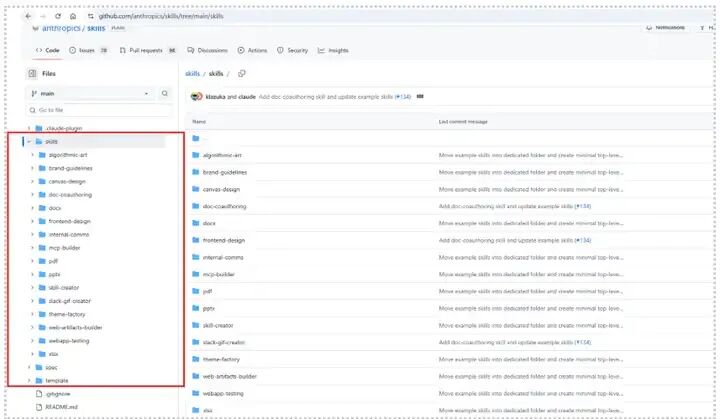
Claude官方自己做的Skills作用介绍:

二、 Skills的精髓:为上下文窗口“减负”的渐进式披露策略
如果只是把指令和脚本打包,Claude Skills 算不上创新。它真正的精髓在于「渐进式披露」(Progressive Disclosure)设计 —— 这是一套为 AI「节省上下文窗口」的智能加载策略,也是它和普通 RAG、Function Calling 的核心区别。
1. 三层加载结构:AI 只拿「当下需要的信息」
我们可以把 Skill 的加载过程想象成「查字典」:先看目录,再看章节,最后查附录,而不是一上来就把整本字典背下来。具体分为三层:
(1)第一层:元数据(Name + Description)——「字典目录」
这部分是 YAML 头部的核心信息,非常简短(通常 1-2 句话),会常驻在 AI 的上下文里。当用户提出需求时,AI 会快速扫描所有 Skill 的元数据,判断哪个技能可能相关。
比如用户说「帮我分析这个 Excel 的数据,生成条形图」,AI 会扫描到smart-data-query的描述包含「分析数据 + 生成条形图」,就会初步锁定这个技能。这一步的优点是「成本极低」,几乎不占用额外上下文。
(2)第二层:SKILL.md 详细指令 ——「字典章节」
当 AI 确定技能相关后,才会加载 SKILL.md 的主体内容,这部分包含完成任务的具体步骤、规则和资源使用方法。比如smart-data-query的 SKILL.md 里会写:「第一步:解析用户问题中的查询意图;第二步:连接指定数据源;第三步:生成 SQL 并执行;第四步:根据数据类型选择图表」。
这一步的上下文消耗「中等」,但因为是按需加载,避免了一次性加载所有内容的浪费。
(3)第三层:脚本和参考文档 ——「字典附录」
只有当 SKILL.md 的指令明确要求时,AI 才会去读取scripts/里的代码或references/里的文档。比如执行 SQL 查询时,AI 会调用scripts/connect-db.py脚本;遇到字段含义不明确时,会查阅references/db-schema.md。
这一步的上下文消耗「按需分配」,比如不需要生成图表时,就不会加载图表渲染脚本,最大程度节省 Token。
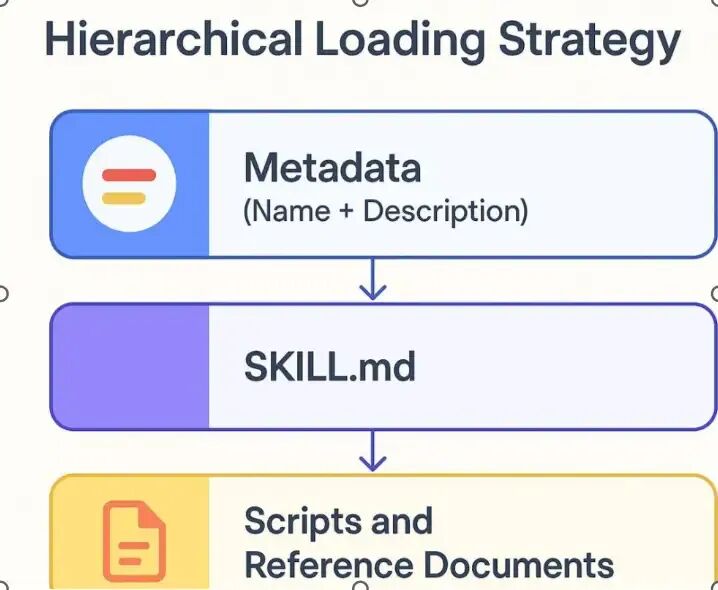
2. 这种结构的 3 大核心好处
(1)解决「上下文溢出」问题
大模型的上下文窗口是有限的(比如 Claude 3 Opus 是 200k Token),如果把所有脚本、文档都一次性加载,很快就会占满窗口,导致 AI「记不住」关键信息。渐进式加载让 AI 只拿当下需要的内容,相当于给上下文「瘦身」。
(2)提升技能调用精准度
元数据的快速筛选的机制,让 AI 不会盲目调用技能。比如用户要处理 PDF,就不会触发 PPTX 技能,避免了「无效劳动」。
(3)降低维护成本
如果需要修改技能流程,只需更新 SKILL.md,不用调整元数据;如果需要优化脚本,直接替换scripts/里的文件即可,各部分解耦,维护起来更灵活。
三、Skills 和 MCP、Function Calling的联系与区别
很多读者会疑惑:Skills 和 MCP、Function Calling 到底有啥区别?是不是只能选一个用?其实它们不是替代关系,而是「互补关系」—— 打个比方,它们就像一个团队里的不同角色:
|
技术 |
核心定位 |
作用类比 |
解决的问题 |
|---|---|---|---|
|
Claude Skills |
能力封装格式 |
操作手册 + 工具包 |
AI「怎么思考、怎么行动」(比如如何一步步完成数据查询) |
|
MCP |
通信协议 |
门禁卡 + 数据线 |
AI「怎么和外部工具对话」(比如如何连接远程数据库) |
|
Function Calling |
函数调用机制 |
工具按钮 |
AI「怎么触发具体操作」(比如执行 SQL 查询、生成图表) |
1. Skills 和 Function Calling:「流程」与「动作」
Function Calling 是 AI 的「单个动作」,比如「执行 SQL」「生成图表」都是独立的函数;而 Skills 是「一系列动作的组合 + 规则」,它会告诉 AI:什么时候执行哪个函数、执行顺序是什么、遇到错误怎么处理。
比如智能问数的流程:「解析问题→连接数据库(调用函数 A)→生成 SQL(调用函数 B)→执行查询(调用函数 C)→生成图表(调用函数 D)」—— 这整套流程由 Skills 定义,而每个具体操作由 Function Calling 实现。
2. Skills 和 MCP:「能力」与「连接」
MCP(Modular Communication Protocol)是一套通信标准,负责让 AI 安全连接外部系统(比如公司内网数据库、云存储)。它不教 AI 怎么干活,只负责「开门」—— 让 AI 有权限访问外部工具。
而 Skills 会告诉 AI:拿到权限后该做什么。比如 MCP 让 AI 连接上公司的 MySQL 数据库,Skills 则指导 AI:如何解析数据库表结构、如何根据用户问题生成合规的 SQL、如何处理查询结果。
3. 三者如何协同工作?
举一个完整的例子:
-
用户需求:「查询公司 2024 年 Q3 的销售额,按区域统计,生成饼图」;
-
Skills:AI 通过
smart-data-query的元数据锁定技能,加载 SKILL.md 的流程; -
MCP:根据 Skills 的指导,通过 MCP 协议连接公司内网 MySQL 数据库(获取访问权限);
-
Function Calling:AI 依次调用「解析查询意图」「生成 SQL」「执行查询」「生成饼图」4 个函数;
-
输出结果:返回查询结果和饼图,完成任务。
简单说:MCP 负责「连接」,Function Calling 负责「执行」,Skills 负责「指挥」,三者协同才能让 AI 完成复杂任务。
四、Skills 的核心优势:为什么值得用?
除了前面提到的「节省上下文」「精准调用」,Claude Skills 还有几个让开发者和普通用户都无法抗拒的优势:
1. 跨平台可移植性
Anthropic 把 Skills 做成了「开放标准」,意味着同一个 Skill 不仅能在 Claude 上用,还能兼容其他 AI 平台(比如 Qwen、Deepseek)和开发工具(OpenCode、Codex、Cursor)。你不用为不同平台重复开发技能,一次编写,多端复用。
2. 模块化管理,告别「巨型 Prompt」
很多人用 AI 处理复杂任务时,会写一个几千行的 System Prompt,包含各种规则、流程和示例,维护起来非常麻烦 —— 改一个步骤就要翻半天,还容易出错。
Skills 用「一个任务一个 Skill」的模块化思路,把复杂能力拆分成多个小技能。比如数据处理相关的技能可以有:data-query(查询)、data-clean(清洗)、data-visualize(可视化),每个技能独立维护,按需组合,大大降低了管理成本。
3. 降低 AI 使用门槛
对于非技术用户来说,Skills 让「复杂操作」变得简单。比如你想把 GitHub 上的 Python 项目做成 Windows 可执行文件,不用懂编程,只需调用repo-packager技能,发送项目链接并说「帮我打包成整合包」,AI 就会自动完成「克隆项目→解析依赖→生成 WebUI→打包成 ZIP」的全流程,你拿到后解压就能用。
4. 支持「自主迭代」
优秀的 Skill 会包含「自检和优化」流程。比如 AI 选题系统的topic-reviewer技能,会审核生成的选题,如果不符合要求,会自动反馈修改意见,让topic-generator技能重新生成,直到通过审核。这种「自主迭代」能力,让 AI 的输出质量更稳定。
五、实战:开发一个智能问数 Skill—— 从 0 到 1 搭建
前面讲了这么多理论,现在我们来动手开发一个实用的 Skill——smart-data-query(智能问数工具),实现「用户输入问题 + 数据源→AI 自动查询→生成图表」的全流程。
1.需求分析:明确技能的核心功能
我们的智能问数 Skill 需要支持:
-
兼容多数据源:MySQL、Excel、CSV;
-
支持多种查询场景:统计、对比、趋势分析;
-
生成多种图表:表格、条形图、折线图、饼图;
-
包含辅助信息:支持用户输入术语解释、SQL 示例,提升查询准确性。
2.文件夹结构设计
首先创建符合规范的文件夹结构:

3.编写核心文件 SKILL.md
这是整个开发过程中最关键的一步,我们按照「YAML 头部 + Markdown 主体」的结构来写:
(1)YAML 头部:技能标识
---
name: smart-data-query
description: 智能问数工具,支持连接MySQL/Excel/CSV数据源,根据用户问题生成SQL、执行查询并生成图表(表格/条形图/折线图/饼图)。当用户输入包含"查询""统计""分析""汇总"等关键词+数据源信息(数据库地址/文件路径)时触发,支持术语解释、SQL示例等辅助信息输入。
---(2)Markdown 主体:详细流程
# 智能问数工具(Smart Data Query)
## 技能概述
本技能用于帮助用户快速查询各类数据源中的数据,无需手动编写SQL,支持自动生成查询语句、执行查询并根据数据特征推荐合适的图表类型。核心价值:降低数据查询门槛,让非技术用户也能快速获取数据洞察。
## 触发条件
当用户输入同时满足以下两个条件时,自动激活:
1. 包含查询意图关键词(任一):查询、统计、分析、汇总、对比、趋势、占比;
2. 包含数据源信息(任一):
- MySQL:数据库地址(如mysql://user:pass@host:port/dbname);
- Excel/CSV:文件路径(如./data/sales.xlsx)或文件内容;
3. 可选辅助信息:术语解释(如"GMV指成交总额")、SQL示例(如"参考查询:SELECT * FROM sales WHERE date BETWEEN '2024-07-01' AND '2024-09-30'")。
## 工作流程(必须严格按顺序执行)
### 第一步:解析用户需求
1. 提取核心查询意图:明确用户要做什么(统计/对比/趋势等);
2. 提取维度和指标:比如"按区域统计销售额"中,维度是"区域",指标是"销售额";
3. 确认数据源类型:判断是MySQL、Excel还是CSV;
4. 处理辅助信息:记录术语解释和SQL示例,用于优化SQL生成。
### 第二步:连接数据源
1. 根据数据源类型调用对应脚本:
- MySQL:调用scripts/connect-db.py,传入数据库地址,建立连接;
- Excel/CSV:调用scripts/connect-db.py,读取文件内容,转换为数据帧;
2. 验证连接有效性:如果连接失败,提示用户检查数据源信息(如数据库地址是否正确、文件是否存在);
3. 读取元数据:获取数据库表结构(字段名、数据类型)或Excel/CSV的列名,用于生成SQL。
### 第三步:生成并执行SQL
1. 根据查询意图和元数据,调用scripts/sql-generator.py生成SQL;
- 统计类查询:使用COUNT/SUM/AVG等聚合函数;
- 对比类查询:使用GROUP BY分组;
- 趋势类查询:按时间字段排序;
2. 优化SQL:参考用户提供的SQL示例,调整字段名和过滤条件;
3. 执行SQL:如果是MySQL,直接执行;如果是Excel/CSV,使用pandas执行等效查询;
4. 处理查询结果:过滤无效数据,整理成结构化格式(如列表、字典)。
### 第四步:生成图表
1. 根据数据类型选择图表:
- 占比数据(如各区域销售额占比):生成饼图;
- 对比数据(如各产品销售额对比):生成条形图;
- 趋势数据(如月度销售额变化):生成折线图;
- 详细数据(如所有订单信息):生成表格;
2. 调用scripts/chart-render.py,使用assets/chart-templates中的模板渲染图表;
3. 优化图表展示:添加标题、坐标轴标签、图例,确保可读性。
### 第五步:返回结果
1. 输出查询结果:包含数据摘要(如"2024年Q3总销售额1000万")和详细数据;
2. 插入图表:以图片形式展示生成的图表;
3. 提供后续操作建议:如"是否需要调整图表类型?是否需要导出数据?"。
## 示例
### 示例1:MySQL数据源
用户输入:"查询2024年Q3(7-9月)各区域的销售额,按从高到低排序,生成条形图。数据库地址:mysql://root:123456@localhost:3306/sales_db。术语说明:销售额指GMV(成交总额)。"
技能执行流程:
1. 解析意图:统计2024年Q3各区域GMV,生成条形图;
2. 连接MySQL数据库sales_db;
3. 读取sales表结构(包含region、gmv、date字段);
4. 生成SQL:SELECT region, SUM(gmv) AS total_sales FROM sales WHERE date BETWEEN '2024-07-01' AND '2024-09-30' GROUP BY region ORDER BY total_sales DESC;
5. 执行SQL,获取结果;
6. 生成条形图;
7. 返回结果:"2024年Q3各区域销售额TOP3:华东350万、华南280万、华北220万" + 条形图。
### 示例2:Excel数据源
用户输入:"分析./data/user.xlsx中的用户年龄分布,生成饼图。参考SQL:SELECT age_group, COUNT(*) FROM user GROUP BY age_group。"
技能执行流程:
1. 解析意图:统计用户年龄分布,生成饼图;
2. 读取Excel文件user.xlsx,转换为数据帧;
3. 按age_group分组统计人数(等效于参考SQL);
4. 生成饼图;
5. 返回结果:"年龄分布:18-25岁占45%、26-35岁占35%、36岁以上占20%" + 饼图。
## 注意事项
1. 数据源连接失败时,需提示用户检查地址/路径、账号密码是否正确;
2. SQL生成失败时,需询问用户补充查询细节(如字段名称、时间范围);
3. 数据量过大(超过10万条)时,自动抽样展示前1000条数据,并提示用户是否需要完整数据;
4. 图表生成后,需允许用户切换类型(如从条形图改为折线图)。4.编写核心脚本(以 Python 为例)
(1)scripts/connect-db.py:数据源连接脚本
import pymysql
import pandas as pd
from typing import Union, DataFrame
def connect_mysql(db_url: str) -> pymysql.connections.Connection:
"""
连接MySQL数据库
:param db_url: 数据库地址,格式:mysql://user:pass@host:port/dbname
:return: 数据库连接对象
"""
# 解析URL
parts = db_url.split('://')[1].split('@')
auth = parts[0].split(':')
user = auth[0]
password = auth[1]
host_port_db = parts[1].split('/')
host_port = host_port_db[0].split(':')
host = host_port[0]
port = int(host_port[1]) if len(host_port) > 1 else 3306
dbname = host_port_db[1]
# 建立连接
connection = pymysql.connect(
host=host,
port=port,
user=user,
password=password,
database=dbname,
charset='utf8mb4'
)
return connection
def read_excel_csv(file_path: str) -> DataFrame:
"""
读取Excel或CSV文件
:param file_path: 文件路径
:return: 数据帧
"""
if file_path.endswith('.xlsx') or file_path.endswith('.xls'):
return pd.read_excel(file_path)
elif file_path.endswith('.csv'):
return pd.read_csv(file_path, encoding='utf-8-sig')
else:
raise ValueError("不支持的文件格式,仅支持Excel(.xlsx/.xls)和CSV(.csv)")
def get_metadata(connection_or_df: Union[pymysql.connections.Connection, DataFrame], source_type: str) -> dict:
"""
获取数据源元数据(表结构/列名)
:param connection_or_df: 数据库连接对象或数据帧
:param source_type: 数据源类型(mysql/excel/csv)
:return: 元数据字典
"""
metadata = {}
if source_type == 'mysql':
# 获取所有表名
with connection_or_df.cursor() as cursor:
cursor.execute("SHOW TABLES")
tables = [table[0] for table in cursor.fetchall()]
# 获取每个表的字段信息
for table in tables:
cursor.execute(f"DESCRIBE {table}")
fields = [{'name': field[0], 'type': field[1]} for field in cursor.fetchall()]
metadata[table] = fields
else:
# Excel/CSV:获取列名和数据类型
df = connection_or_df
metadata['columns'] = [{'name': col, 'type': str(df[col].dtype)} for col in df.columns]
return metadata(2)scripts/sql-generator.py:SQL 生成脚本
def generate_sql(intention: str, dimensions: list, metrics: list, time_range: dict, source_metadata: dict) -> str:
"""
根据用户意图生成SQL
:param intention: 查询意图(统计/对比/趋势)
:param dimensions: 维度列表(如['region'])
:param metrics: 指标列表(如['gmv'])
:param time_range: 时间范围(如{'start': '2024-07-01', 'end': '2024-09-30'})
:param source_metadata: 数据源元数据
:return: 生成的SQL语句
"""
# 简化版SQL生成逻辑,实际可根据元数据优化字段名匹配
table_name = list(source_metadata.keys())[0] if 'mysql' in str(source_metadata) else 'data'
metric_sql = ", ".join([f"SUM({metric}) AS total_{metric}" for metric in metrics])
dimension_sql = ", ".join(dimensions) if dimensions else ""
group_by_sql = f"GROUP BY {dimension_sql}" if dimensions else ""
order_by_sql = ""
# 时间条件
time_condition = ""
if time_range:
time_field = next((field['name'] for field in source_metadata[table_name] if 'date' in field['name'].lower()), None)
if time_field:
time_condition = f"WHERE {time_field} BETWEEN '{time_range['start']}' AND '{time_range['end']}'"
# 意图对应的排序逻辑
if intention == '趋势':
time_field = next((field['name'] for field in source_metadata[table_name] if 'date' in field['name'].lower()), None)
if time_field:
order_by_sql = f"ORDER BY {time_field} ASC"
elif intention == '对比':
if dimensions:
order_by_sql = f"ORDER BY total_{metrics[0]} DESC"
# 拼接SQL
sql = f"SELECT {dimension_sql}{', ' if dimension_sql and metric_sql else ''}{metric_sql} FROM {table_name} {time_condition} {group_by_sql} {order_by_sql}"
return sql.strip()(3)scripts/chart-render.py:图表渲染脚本
import matplotlib.pyplot as plt
import pandas as pd
from typing import DataFrame
import os
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
def render_chart(data: DataFrame, chart_type: str, title: str, x_label: str, y_label: str) -> str:
"""
生成图表并保存为图片
:param data: 数据帧
:param chart_type: 图表类型(table/bar/line/pie)
:param title: 图表标题
:param x_label: X轴标签
:param y_label: Y轴标签
:return: 图片保存路径
"""
# 创建图表目录
if not os.path.exists('../assets/chart-output'):
os.makedirs('../assets/chart-output')
# 生成图表
fig, ax = plt.subplots(figsize=(10, 6))
if chart_type == 'bar':
data.plot(kind='bar', ax=ax, color='#1f77b4')
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
elif chart_type == 'line':
data.plot(kind='line', ax=ax, marker='o', color='#ff7f0e')
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
elif chart_type == 'pie':
data.plot(kind='pie', ax=ax, subplots=True, autopct='%1.1f%%', startangle=90, colors=['#ff9999','#66b3ff','#99ff99','#ffcc99'])
ax.set_ylabel('')
elif chart_type == 'table':
ax.axis('tight')
ax.axis('off')
table = ax.table(cellText=data.values, colLabels=data.columns, loc='center', cellLoc='center')
table.auto_set_font_size(False)
table.set_fontsize(10)
table.scale(1.2, 2)
plt.title(title, fontsize=14, fontweight='bold')
plt.tight_layout()
# 保存图片
img_path = f'../assets/chart-output/{title.replace(" ", "_")}.png'
plt.savefig(img_path, dpi=300, bbox_inches='tight')
plt.close()
return img_path5.编写参考文档
(1)references/db-schema.md:数据库表结构说明
# 数据源表结构说明
## MySQL数据库(sales_db)
### sales表
| 字段名 | 数据类型 | 说明 |
|--------|----------|------|
| id | INT | 订单ID |
| region | VARCHAR(20) | 区域(华东/华南/华北/西南/西北) |
| product | VARCHAR(50) | 产品名称 |
| gmv | DECIMAL(10,2) | 成交总额(单位:万元) |
| date | DATE | 订单日期 |
| channel | VARCHAR(20) | 销售渠道(线上/线下) |
### user表
| 字段名 | 数据类型 | 说明 |
|--------|----------|------|
| id | INT | 用户ID |
| age_group | VARCHAR(10) | 年龄组(18-25/26-35/36-45/46+) |
| gender | VARCHAR(10) | 性别(男/女/未知) |
| register_date | DATE | 注册日期 |
| city | VARCHAR(20) | 所在城市 |
## Excel/CSV文件格式要求
### 销售数据文件
必须包含列:region(区域)、gmv(销售额)、date(日期)
### 用户数据文件
必须包含列:age_group(年龄组)、gender(性别)、register_date(注册日期)(2)references/term-glossary.md:业务术语解释
# 业务术语解释
| 术语 | 英文 | 说明 |
|------|------|------|
| GMV | Gross Merchandise Volume | 成交总额,包含所有订单金额(含退款) |
| 区域 | Region | 华东(上海/江苏/浙江/安徽/福建)、华南(广东/广西/海南)、华北(北京/天津/河北/山东/山西)、西南(四川/重庆/贵州/云南)、西北(陕西/甘肃/青海/宁夏/新疆) |
| 销售渠道 | Channel | 线上(电商平台/小程序/APP)、线下(门店/经销商) |
| 年龄组 | Age Group | 18-25岁(Z世代)、26-35岁( millennial)、36-45岁(中青年)、46岁以上(中老年) |6.测试技能
-
把
smart-data-query文件夹放到对应平台的技能目录(比如 Claude Code 的~/.claude/skills); -
在 Claude Code 中输入测试指令:「查询 2024 年 Q3 各区域的销售额,按从高到低排序,生成条形图。数据库地址:mysql://root:123456@localhost:3306/sales_db。术语说明:销售额指 GMV(成交总额)。」;
-
观察 AI 是否触发
smart-data-query技能,是否按流程连接数据库、生成 SQL、执行查询并生成图表; -
若出现问题(如 SQL 生成错误、图表无法显示),修改 SKILL.md 或脚本,反复测试直到正常运行。
六、如何安装开发好的Skills?
不同平台的安装方法略有差异,以下是主流平台的详细步骤:
1. Claude Code(推荐,支持热重载)
(1)安装自定义技能
-
打开 Claude Code,点击左侧「Skills」面板;
-
点击「Add Skill」,选择「Import Local Folder」;
-
选择你开发的 Skill 文件夹(如
smart-data-query),点击「Import」; -
安装完成后,Skill 会自动加载,无需重启。
(2)安装开源技能(如 Anthropic 官方技能)
在 Claude Code 的终端中输入命令:
/plugin marketplace add anthropics/skills然后安装具体技能:
/plugin install document-skills@anthropic-agent-skills # 安装文档处理技能(pdf/pptx/docx/xlsx)验证安装:输入「帮我分析这个 PPTX 文件」,AI 会自动调用pptx技能。
2. OpenCode
(1)安装自定义技能
手动创建技能目录:
-
-
Windows:
C:\Users\你的用户名\.config\opencode\skill -
Mac:
/Users/你的用户名/.config/opencode/skill
-
把 Skill 文件夹(如smart-data-query)复制到该目录;
重启 OpenCode,技能即可生效。
(2)安装开源技能(如 Superpowers)
在 OpenCode 中输入命令:
Fetch and follow instructions from https://raw.githubusercontent.com/obra/superpowers/refs/heads/main/.opencode/INSTALL.md按照提示完成安装,重启 OpenCode;
验证安装:输入/help,若看到/superpowers:brainstorm等命令,说明安装成功。
3. Codex
(1)安装自定义技能
-
手动创建技能目录:
~/.codex/skills; -
把 Skill 文件夹复制到该目录;
-
重启 Codex 即可。
(2)安装开源技能
-
在 Codex 中输入命令:
Fetch and follow instructions from https://raw.githubusercontent.com/obra/superpowers/refs/heads/main/.codex/INSTALL.md关键提醒:
-
技能目录必须严格按照平台要求创建,否则 AI 无法识别;
-
自定义技能的文件夹名称必须是「小写字母 + 连字符」,不能有特殊字符;
-
Claude Code 支持技能热重载,修改技能后无需重启;其他平台需要重启才能生效。
七、值得关注的 Claude Skills 开源项目
除了自己开发,还有很多优秀的开源项目可以直接使用,节省开发时间。以下是两个最受欢迎的项目:
1. Anthropics 官方技能仓库:50 + 实用技能,开箱即用
项目地址:https://github.com/anthropics/skills
Star 数:38.3k+
核心特点:Anthropic 官方开源,包含 50 + 技能,覆盖文档处理、创意设计、技术开发、企业协作等多个场景,质量有保障。
必装技能推荐
|
技能名称 |
功能描述 |
适用场景 |
|---|---|---|
|
docx |
创建 / 编辑 / 分析 Word 文档,支持修订、批注 |
文档处理 |
|
|
PDF 文本提取、合并拆分、表单处理 |
文档处理 |
|
pptx |
PPT 创建、编辑、分析,支持布局设计 |
演示文稿制作 |
|
xlsx |
Excel 表格创建、数据分析、可视化 |
数据处理 |
|
skill-creator |
帮助你创建新的 Skill,堪称「技能生成器」 |
技能开发 |
|
frontend-design |
生成高品质前端界面和组件 |
开发设计 |
使用方法
-
克隆仓库:
git clone https://github.com/anthropics/skills.git; -
把需要的技能文件夹(如
skills/pdf)复制到对应平台的技能目录; -
重启平台即可使用。
2. Superpowers:基于 Skills 的开发工作流框架
项目地址:https://github.com/obra/superpowers
Star 数:18k+
核心特点:不是单个技能,而是一套「技能组合 + 开发流程」,专为编码任务设计,支持 TDD(测试驱动开发)、子代理协作、批量执行等高级功能。
核心工作流程
- 头脑风暴
:AI 会先询问用户需求,细化设计方案,生成可验证的规格说明书;
- 制定计划
:把开发任务拆分成 2-5 分钟就能完成的小任务,明确文件路径、代码要求和验证步骤;
- 执行计划
:启动子代理协作开发,每个任务由专门的子代理完成,包含「开发 - 审核 - 优化」流程;
- 测试交付
:遵循 TDD 原则,先写测试用例,再编写代码,确保功能可用。
安装方法(以 Claude Code 为例)
-
注册市场:
/plugin marketplace add obra/superpowers-marketplace; -
安装插件:
/plugin install superpowers@superpowers-marketplace; -
验证:输入
/help,若看到/superpowers:brainstorm等命令,说明安装成功。
适用场景
-
快速开发小型应用(如 Web 工具、脚本);
-
批量处理编码任务(如重构代码、添加测试用例);
-
非技术用户快速实现编程需求(如生成 API 接口、开发简单前端)。
总结:Claude Skills 的未来 —— 让 AI 成为你的「标准化助手」
Claude Skills 的本质,是把「隐性经验」变成「显性能力」—— 不管是你个人的工作流程,还是公司的业务规范,都能通过 Skill 封装成可复用的工具,让 AI 精准执行。
它不像大模型那样需要高深的算法知识,也不像传统工具那样有陡峭的学习曲线,普通人只要懂基本的流程逻辑,就能开发自己的 Skill;而非技术用户,也能直接使用开源技能,解决工作中的实际问题。
随着 Skills 生态的完善,未来我们可能会看到:
-
企业级 Skill 市场:公司可以发布自己的行业技能(如金融数据分析、医疗报告生成),供内部员工或外部用户使用;
-
技能组合平台:用户可以像搭积木一样,组合多个 Skill 完成复杂任务(如「数据采集→数据清洗→数据分析→报告生成」);
-
跨模型兼容:同一个 Skill 可以在所有主流 AI 模型上使用,真正实现「一次开发,多端复用」。
如果你是开发者,不妨从一个简单的 Skill 开始(比如批量处理文件、自动生成报告),把自己从重复劳动中解放出来;如果你是非技术用户,不妨试试本文推荐的开源技能,感受 AI 精准干活的乐趣。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小伙伴们关注和分享。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)