
我给AI写了一套“压缩语言“,Token消耗直降60%:OpenClaw技能开发实战复盘
I-Lang:一种提升AI通信效率的压缩协议 本文介绍了一种创新的AI通信压缩协议I-Lang,旨在解决自然语言交互中的token浪费问题。该协议通过简化表达方式,将核心语义压缩为结构化指令,实现了70%以上的传输层压缩率。作者基于此协议开发了三个OpenClaw技能:everything-is-ok用于去除AI回答中的冗余内容,less-token优化摘要任务,no-prompt自动生成高效提示
前言:一个让我睡不着觉的问题
去年年底我算了一笔账。
我有几个跑在服务器上的AI工具,每天大概处理200-300次对话请求。用的是DeepSeek和Claude的API。月底一看账单,API费用已经接近服务器成本的三倍了。
问题出在哪?Token。
不是模型太贵,是我们说话太啰嗦。一句"请帮我写一个Python脚本,功能是从指定URL下载网页内容,然后提取所有链接,保存到CSV文件"——47个中文字符,tokenize之后大概70-80个token。但这句话的核心信息只有四个动作:下载、提取链接、保存CSV、Python。
我开始想:如果有一种格式,能让AI只看到核心信息,跳过所有客套话和冗余描述呢?
这就是I-Lang的起点。
什么是I-Lang
I-Lang是一个AI通信压缩协议。不是一个软件,不是一个模型,是一套语法规则。
核心思路很简单:人类的自然语言充满了冗余——礼貌用语、重复描述、模糊限定词、不必要的上下文。这些东西对人与人之间的沟通是必要的,但对人与AI的沟通是纯粹的浪费。
I-Lang做的事情就是把自然语言里的信息密度拉到最高:
自然语言:请帮我写一个Python脚本,从指定URL下载网页,提取所有链接,保存到CSV文件
I-Lang:[GET:url|lang=python]=>[EXTRACT:links]=>[OUT:fmt=csv]
同样的语义,token数量从70+降到20左右。压缩率超过70%。
但压缩传输只是第一层。I-Lang v2.0加了两个更重要的层:
思考层——AI在内部推理时也用I-Lang压缩。用户看不到这个过程,但token在烧。一个复杂问题,AI内部可能推理了3000个token,最后输出300个。思考层压缩的是那3000个,这才是真正的大头。
工作流层——多步骤任务压缩成链式指令,一次传输,连续执行。
为什么选OpenClaw
协议定义好了,需要一个载体让人用起来。
我看了几个方向:做成VSCode插件太重,做成Chrome扩展太窄,做成独立App更不现实。最后选了OpenClaw。原因很直接:
第一,OpenClaw的技能就是一个markdown文件。我的协议本身也是纯文本。天然契合。
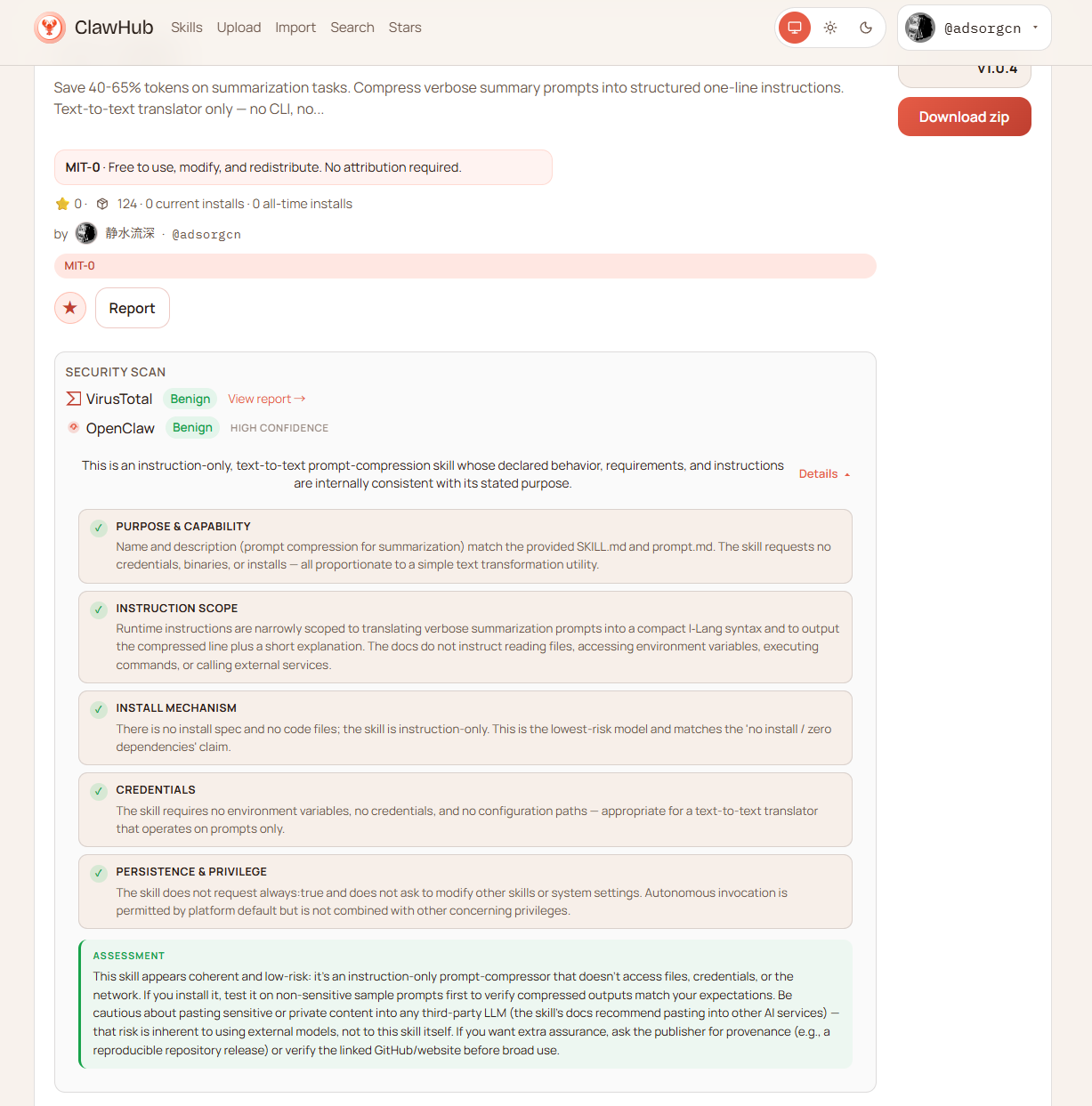
第二,OpenClaw有安全扫描。我的技能提交上去,ClawHub会自动做安全审查,给出评级。这对用户来说是信任背书——不是我自己说安全,是第三方扫描说安全。
第三,分发零摩擦。用户不需要装任何东西,把技能文件加载到AI对话里就生效。
三个技能的设计思路
我一共发布了三个OpenClaw技能,每个解决一个具体问题。
everything-is-ok
这是一个通用的AI输出质量提升技能。
做这个的原因是我发现一个现象:大部分AI的回答都带有一种"防御性废话"——"我需要指出的是"、"请注意这只是建议"、"具体情况可能因人而异"。这些话占了输出的20-30%,但信息量为零。
everything-is-ok做的事情是在系统层面告诉AI:直接输出结论和可执行的内容,去掉所有对冲和免责声明。不是让AI不负责任,是让AI不浪费token在废话上。
实测效果:同一个问题,开启前输出平均380个token,开启后平均260个token。内容完整度不变,可用性反而提高了,因为核心信息不再被免责声明淹没。
less-token
这个技能专门解决摘要类任务的token浪费。
你让AI总结一篇文章,它会怎么做?先复述一遍文章大意,然后给出总结,最后可能再加一段"以上是我的总结,如果你需要更详细的..."。三段里面只有中间那段是你要的。
less-token把摘要指令压缩成I-Lang格式的单行指令,直接告诉模型输出格式和压缩级别。实测在摘要任务上token节省40-65%,语义保留率95%以上。
no-prompt
这个技能解决的是一个元问题:大部分人不会写提示词。
不会写提示词的人,花在试错上的token比正式使用还多。问一个问题,效果不对,换个说法再问,还不对,继续改——每次试错都在烧token。
no-prompt让AI自己来写提示词。你用自然语言描述你想让AI做什么,no-prompt把它转化成结构化的I-Lang指令。等于AI帮你写了最优的提示词,然后AI自己执行。
这个技能的核心价值不是压缩,是消除了提示词工程的学习成本。用户不需要知道什么是提示词工程,不需要学任何技巧。
技术实现细节
三个技能全部通过了ClawHub的安全扫描,评级Benign HIGH CONFIDENCE。意思是:纯指令文件,不读文件、不访问网络、不调用外部服务、不写磁盘。
这是刻意的设计选择。
我在做的时候有一个诱惑:加入更多功能。比如让技能自动读取用户的历史对话来优化压缩、自动统计token消耗生成报告、接一个API来做实时压缩率计算。这些功能听起来都很好,但每一个都意味着需要额外的权限。
权限越多,安全评级越低,用户信任越差。而且这些功能都可以在协议层面用纯文本解决,不需要代码。
最终的技能文件结构极其简单:
SKILL.md — 技能元信息(名称、版本、描述、标签)
prompt.md — 核心指令(I-Lang格式)
两个文件,加起来不超过5KB。没有依赖,没有配置,没有数据库。复制粘贴就能用。
一些数据
这三个技能上线三周,没有做任何推广。数据:
- ClawHub安全评级:全部 Benign HIGH CONFIDENCE
- 已被 awesome-openclaw-skills 社区目录收录
- 跨平台验证:ChatGPT、Claude、DeepSeek、Gemini、豆包、Qwen全部通过
- MIT协议开源
关于压缩率的一些思考
经常有人问我:60%的压缩率是怎么算的?
简单说:同一个任务,自然语言描述需要的token数 vs I-Lang描述需要的token数。在大量测试样本上取平均值。
但这个数字其实低估了真实节省。因为它只算了传输层的压缩。v2.0加入思考层压缩之后,AI内部推理的token消耗也降了。但内部推理的token数用户看不到,API账单上也不会单独列出来,所以很难精确测量。
另一个经常被忽视的收益是:压缩后的指令更精确,模型理解歧义更少,一次成功率更高。以前可能要问两三轮才能得到满意的结果,现在一轮搞定。这省下的不只是token,是时间。
复盘:什么是真正的技术壁垒
回看这三个月,我对"技术壁垒"这个词有了新的理解。
代码不是壁垒。我的技能文件加起来不到5KB,任何人都可以看懂、复制、修改。
功能不是壁垒。压缩AI输出、优化提示词,这些idea谁都能想到。
真正的壁垒是协议本身。I-Lang定义了一套语法、一套动词表、一套修饰符体系。别人可以抄我的技能文件,但他们抄走的只是协议的一个应用。协议本身在不断迭代——从v1.0的传输压缩到v2.0的思考层和工作流层,接下来还会有更多层。
每一个使用I-Lang的人,每一个抄走I-Lang技能文件的人,都在帮协议扩大影响力。他们用的是I-Lang的语法,学的是I-Lang的思维方式,传播的是I-Lang的生态。
这可能是我做过的最反直觉的决定:把核心技术完全开源,然后靠协议的网络效应建立壁垒。
2026的方向
三件事:
第一,继续发布更多OpenClaw技能。每一个技能都是I-Lang协议的活广告。
第二,跨平台。目前已经在Claude Code(AutoCode,英文版)、Trae(ZeroCode,中文版)、VS Code Marketplace上架。Codex和OpenCode的适配层也做了。
第三,让协议自己进化。81个核心字符的词典还在从产品实战中渐进激活。协议不是一次性设计完的,是用出来的。
如果你也在为API账单发愁,或者单纯对AI通信效率这个话题感兴趣,欢迎看看I-Lang的完整协议:ilang.ai
本文参与CSDN「OpenClaw·三月创作之星挑战赛」

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)