
AI代理网关快速入门:Clawdbot整合Qwen3:32B完整教程
本文介绍了如何在星图GPU平台上自动化部署Clawdbot整合qwen3:32b代理网关与管理平台镜像。该平台简化了本地大模型的管理与API化,用户可快速搭建一个带Web界面的AI代理服务,典型应用场景包括为团队提供统一的AI对话界面或集成到现有应用中进行代码审查与文档编写。
AI代理网关快速入门:Clawdbot整合Qwen3:32B完整教程
1. 从零开始:为什么你需要Clawdbot
想象一下这个场景:你刚在本地部署了Qwen3:32B大模型,通过Ollama跑起来了,也能用curl命令测试了。但接下来呢?
- 想给团队其他成员用,难道要每人教一遍命令行?
- 想看看模型响应速度怎么样,是不是得自己写个监控脚本?
- 想同时管理多个模型,是不是要开一堆终端窗口?
- 想集成到自己的应用里,是不是要自己封装API接口?
这些问题,我都遇到过。以前的做法是:写个Flask服务,加个简单的Web界面,再配个Nginx反向代理。听起来不复杂,但实际做起来,光是处理并发、流式输出、会话管理这些细节,就能耗掉大半天时间。
Clawdbot的出现,就是为了解决这些“最后一公里”的问题。它不是一个新的大模型,而是一个AI代理网关与管理平台。简单说,它帮你把本地部署的模型(比如Qwen3:32B)包装成一个标准化的、可管理的、带界面的服务。
最吸引我的一点是:它开箱即用。你不需要懂Go语言,不需要配数据库,甚至不需要写配置文件(镜像已经预置好了)。只要你的机器上有Ollama在跑Qwen3:32B,Clawdbot就能自动发现并接入。
这篇文章,我会带你从零开始,一步步完成Clawdbot的部署、配置和使用。目标很简单:让你在30分钟内,拥有一个功能完整的AI代理管理平台。
2. 环境准备:确保一切就绪
2.1 硬件与软件要求
在开始之前,先确认你的环境满足以下要求:
- 显存:至少24GB(Qwen3:32B在24G显存上可以运行,但体验不是最佳。如果追求更好的交互体验,建议使用更大的显存资源)
- 内存:32GB以上
- 存储:至少50GB可用空间(用于存放模型权重和系统文件)
- 操作系统:Linux(Ubuntu 20.04+或CentOS 7+)或macOS
- 已安装:Docker或直接使用CSDN星图平台的预置镜像
2.2 检查Ollama服务
Clawdbot需要连接本地的Ollama服务。先确认你的Ollama已经正确运行:
# 检查Ollama服务状态
systemctl status ollama # 如果是systemd管理
# 或者
ps aux | grep ollama
# 确认Qwen3:32B模型已下载
ollama list
你应该能看到类似这样的输出:
NAME ID SIZE MODIFIED
qwen3:32b xxxxxxxxxxx 32.4GB 2 days ago
如果还没有下载Qwen3:32B,先执行:
ollama pull qwen3:32b
下载时间取决于你的网络速度,模型大约32GB,请耐心等待。
2.3 获取Clawdbot镜像
如果你使用CSDN星图平台,可以直接搜索“Clawdbot 整合 qwen3:32b”镜像并一键部署。
如果是本地Docker环境,可以这样启动:
# 拉取镜像(如果平台未提供直接拉取方式,请参考镜像文档)
docker run -d \
--name clawdbot \
-p 3000:3000 \
-v /path/to/config:/app/config \
clawdbot-image:latest
不过,我强烈建议直接使用CSDN星图平台的预置镜像,因为它已经帮你做好了所有配置优化,包括Qwen3:32B的模型连接配置。
3. 首次启动与访问配置
3.1 启动Clawdbot服务
启动命令非常简单:
clawdbot onboard
执行后,你会看到类似这样的输出:
🚀 Starting Clawdbot Gateway...
✅ Gateway server started on http://127.0.0.1:3000
🔍 Detecting Ollama backend...
✅ Ollama backend found at http://127.0.0.1:11434
📦 Loading model configurations...
✅ Model 'qwen3:32b' registered successfully
🌐 Web UI available at: http://localhost:3000
关键信息解读:
Gateway server started on http://127.0.0.1:3000- 网关服务已启动,监听3000端口Ollama backend found at http://127.0.0.1:11434- 成功检测到本地Ollama服务Model 'qwen3:32b' registered successfully- Qwen3:32B模型已成功注册到网关
3.2 解决“未授权访问”问题
这是新手最容易卡住的地方。第一次访问Clawdbot时,你可能会看到这样的错误:
disconnected (1008): unauthorized: gateway token missing
别担心,这不是系统故障,而是Clawdbot的安全机制在起作用。它要求首次访问必须携带有效的token。
解决方法很简单,只需要修改一下URL:
-
复制你当前的访问地址(通常在浏览器地址栏),它看起来像这样:
https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/chat?session=main -
删除末尾的
/chat?session=main,得到:https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/ -
在末尾添加
?token=csdn,最终URL应该是:https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/?token=csdn
把这个修改后的URL粘贴到浏览器,回车,你就能看到Clawdbot的控制台界面了。
重要提示:这个token配置在镜像中是预设的。在生产环境中,你应该修改这个token以提高安全性。修改方法是在Clawdbot的配置文件中更改token值。
3.3 后续访问的快捷方式
第一次成功登录后,Clawdbot会在你的浏览器中保存会话信息。之后,你可以直接通过控制台提供的快捷方式访问,或者直接访问基础URL(不带token),系统会自动识别已认证的会话。
这意味着:你只需要在第一次访问时处理token问题,之后就像使用普通Web应用一样方便。
4. 理解Clawdbot的核心架构
在深入使用之前,我们先花几分钟理解Clawdbot是怎么工作的。这能帮你更好地利用它的功能。
4.1 三层架构:网关、模型、代理
Clawdbot的架构可以理解为三层:
-
网关层(Gateway):所有请求的统一入口。它负责:
- 接收来自Web界面或API的请求
- 验证token和权限
- 将请求路由到正确的模型后端
- 记录日志和监控指标
-
模型层(Model Backend):实际运行AI模型的地方。在这个例子中,就是本地的Ollama服务。Clawdbot通过配置文件知道如何连接它:
{
"my-ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama",
"api": "openai-completions",
"models": [
{
"id": "qwen3:32b",
"name": "Local Qwen3 32B",
"reasoning": false,
"input": ["text"],
"contextWindow": 32000,
"maxTokens": 4096,
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
}
}
]
}
}
这个配置告诉Clawdbot:“本地有一个Ollama服务在127.0.0.1:11434,它提供了一个兼容OpenAI API的接口,里面有一个叫qwen3:32b的模型。”
- 代理层(Agent):这是你实际交互的对象。一个代理可以:
- 绑定特定的模型(比如Qwen3:32B)
- 有自定义的系统提示词(System Prompt)
- 集成各种工具(搜索、计算、文件读取等)
- 设置不同的参数(温度、最大token数等)
4.2 为什么需要这样的架构?
你可能想问:我直接调用Ollama的API不行吗?为什么要加一层Clawdbot?
几个实际的好处:
- 统一管理:如果你有多个模型(比如Qwen3:32B、Llama3、DeepSeek),Clawdbot可以统一管理它们,你不需要记住每个模型的地址和端口
- 监控观测:Clawdbot提供了详细的请求日志、响应时间、token用量等监控数据
- 权限控制:你可以为不同用户设置不同的访问权限
- 扩展性:未来可以轻松添加新的功能,比如缓存、限流、负载均衡等
5. 实战:与Qwen3:32B进行第一次对话
现在,让我们开始实际使用Clawdbot。
5.1 访问聊天界面
成功登录Clawdbot后,你会看到类似这样的界面:
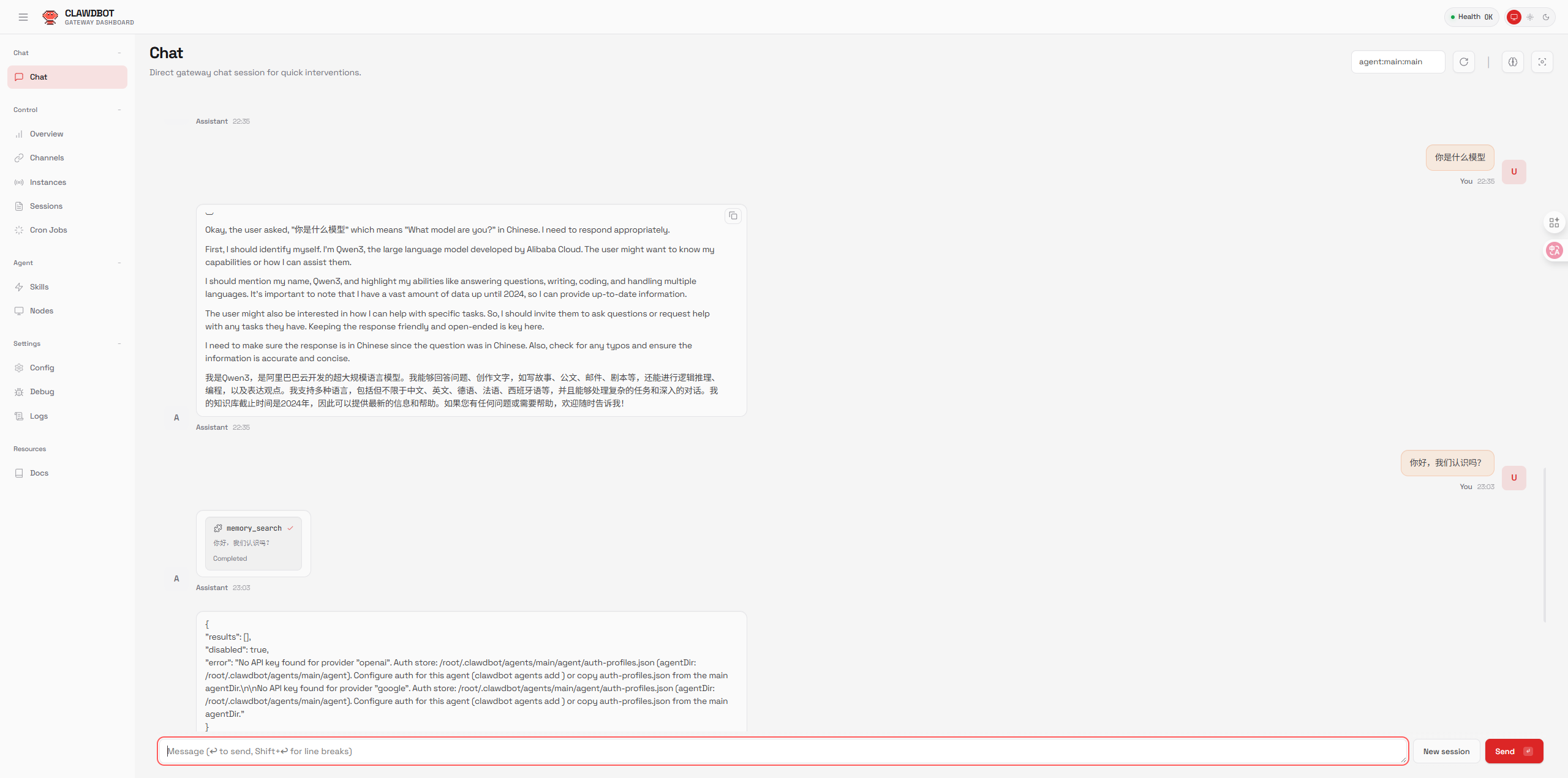
界面主要分为几个区域:
- 左侧:代理列表和会话历史
- 中间:聊天主区域
- 右侧:模型信息和设置面板
- 顶部:导航栏(Chat、Agents、Settings等)
点击顶部的「Chat」标签,进入聊天界面。
5.2 选择代理并开始对话
在左侧的代理列表中,你会看到一个名为「main」的默认代理。点击它,右侧聊天窗口会显示「Using Local Qwen3 32B」,表示这个代理使用的是我们配置的Qwen3:32B模型。
现在,输入你的第一个问题。我建议从一个简单但能体现模型能力的问题开始:
请用中文解释一下什么是注意力机制,用比喻的方式让初学者也能理解。
按下回车,你会看到响应开始逐字出现——这是流式输出(Streaming)的效果。对于Qwen3:32B这样的模型,第一次响应可能需要几秒钟时间,因为模型需要加载到显存中。
5.3 理解响应过程
当你在Clawdbot中发送消息时,背后发生了这些事情:
- 你的消息被发送到Clawdbot网关(http://localhost:3000)
- 网关验证token和权限
- 网关将请求转发到Ollama后端(http://127.0.0.1:11434/v1/chat/completions)
- Ollama调用Qwen3:32B模型生成响应
- 响应以流式方式返回给网关
- 网关将流式响应转发给你的浏览器
整个过程对你是透明的,你只需要在界面上输入和查看结果。
5.4 查看请求详情
Clawdbot的一个强大功能是请求详情查看。点击聊天窗口右上角的「Debug」或「Details」按钮,你可以看到这次请求的完整信息:
| 字段 | 示例值 | 说明 |
|---|---|---|
| model | qwen3:32b | 实际调用的模型 |
| prompt_tokens | 28 | 输入文本的token数量 |
| completion_tokens | 156 | 输出文本的token数量 |
| total_duration_ms | 4230 | 总耗时(毫秒) |
| tokens_per_second | 36.8 | 生成速度(token/秒) |
| backend_url | http://127.0.0.1:11434/v1/chat/completions | 实际的后端地址 |
这些数据对于优化和调试非常有用。比如,如果你发现响应时间特别长,可以检查是网络延迟还是模型推理速度问题。
6. 通过API调用Clawdbot
除了Web界面,Clawdbot还提供了完整的API接口,这意味着你可以从自己的程序调用它。
6.1 基本的API调用
Clawdbot的API完全兼容OpenAI的格式,这意味着你可以使用任何支持OpenAI API的客户端库。
使用curl进行测试:
curl -X POST "http://localhost:3000/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer csdn" \
-d '{
"model": "qwen3:32b",
"messages": [
{"role": "system", "content": "你是一个有帮助的AI助手"},
{"role": "user", "content": "用Python写一个快速排序的实现"}
],
"temperature": 0.7,
"max_tokens": 1000,
"stream": false
}'
关键参数说明:
model: 指定要使用的模型,这里必须是"qwen3:32b"messages: 对话历史,包含系统提示和用户消息temperature: 控制输出的随机性(0.0-2.0)max_tokens: 限制响应长度stream: 是否使用流式输出
6.2 在Python项目中使用
如果你在Python项目中使用,可以这样集成:
import openai
# 配置客户端
client = openai.OpenAI(
base_url="http://localhost:3000/v1", # Clawdbot的API地址
api_key="csdn" # 你的token
)
# 调用聊天接口
response = client.chat.completions.create(
model="qwen3:32b",
messages=[
{"role": "user", "content": "解释一下机器学习中的过拟合现象"}
],
stream=False
)
print(response.choices[0].message.content)
6.3 与LangChain集成
如果你使用LangChain,集成更加简单:
from langchain_openai import ChatOpenAI
# 创建LangChain的ChatOpenAI实例
llm = ChatOpenAI(
base_url="http://localhost:3000/v1",
api_key="csdn",
model="qwen3:32b",
temperature=0.7
)
# 现在你可以像使用OpenAI一样使用它
response = llm.invoke("什么是Transformer架构?")
print(response.content)
这种兼容性意味着:你现有的基于OpenAI API的代码,几乎不需要修改就能切换到Clawdbot + Qwen3:32B。
7. 创建自定义代理
默认的「main」代理适合快速测试,但在实际使用中,你可能需要针对不同场景创建专门的代理。
7.1 创建技术文档编写代理
假设你需要一个专门用于编写技术文档的AI助手:
-
在Clawdbot界面中,点击「Agents」标签
-
点击「Create New Agent」按钮
-
填写代理信息:
- Name:
tech-writer - Description:
专门用于编写技术文档和API参考 - Model: 选择
qwen3:32b
- Name:
-
在System Prompt中输入:
你是一位资深技术文档工程师。请遵循以下准则:
1. 使用清晰、准确的技术术语
2. 提供完整的代码示例
3. 解释复杂概念时使用类比
4. 保持语气专业但友好
5. 所有输出使用中文
- 点击「Save」保存
现在,当你使用tech-writer代理时,它会自动带上这个系统提示,输出风格会更加符合技术文档的要求。
7.2 创建代码审查代理
再创建一个用于代码审查的代理:
-
同样点击「Create New Agent」
-
填写:
- Name:
code-reviewer - Description:
用于审查代码质量和安全性 - Model:
qwen3:32b
- Name:
-
System Prompt:
你是一个严格的代码审查助手。请:
1. 检查代码中的潜在bug和安全漏洞
2. 指出不符合最佳实践的地方
3. 建议性能优化方案
4. 评估代码的可读性和可维护性
5. 用中文输出,分点列出问题和建议
- 保存后,你可以将代码粘贴给这个代理,它会给出详细的审查意见。
7.3 代理的管理与切换
创建多个代理后,你可以在聊天界面左侧轻松切换:
- 点击不同的代理名称,聊天上下文会自动切换
- 每个代理有独立的对话历史
- 系统提示词和模型配置相互独立
这意味着你可以在同一个界面中,用同一个Qwen3:32B模型,实现完全不同的“人格”和功能。
8. 监控与运维
8.1 实时监控面板
Clawdbot提供了内置的监控面板,你可以在「Dashboard」或「Monitoring」页面查看:
- 请求速率:当前每秒处理的请求数
- 平均延迟:请求从发起到收到响应的平均时间
- 错误率:失败请求的比例
- 活跃会话:当前正在进行的对话数量
- Token使用:输入和输出的token数量统计
对于Qwen3:32B在24G显存上的表现,你可以关注这些指标:
- 正常情况下的延迟:5000-8000毫秒
- 高峰期的延迟:可能达到10000-15000毫秒
- 如果延迟持续过高,可能需要优化提示词或考虑升级硬件
8.2 日志查看
Clawdbot记录了详细的请求日志,包括:
- 请求时间
- 用户标识(如果有)
- 使用的模型
- 输入输出的token数
- 响应时间
- 任何错误信息
你可以通过界面查看这些日志,也可以配置将日志导出到外部系统。
8.3 性能优化建议
基于我的使用经验,这里有一些优化Qwen3:32B在Clawdbot中性能的建议:
-
提示词优化:
- 保持提示词简洁明确
- 在系统提示中明确输出格式要求
- 避免过于开放的问题
-
参数调整:
- 适当降低
temperature(如0.3-0.7)以获得更稳定的输出 - 设置合理的
max_tokens限制,避免生成过长的响应
- 适当降低
-
硬件考虑:
- 如果响应速度是关键,考虑使用量化版本的Qwen3模型
- 确保有足够的系统内存作为显存的补充
- 使用SSD而不是HDD,加快模型加载速度
9. 常见问题与解决
9.1 连接问题
问题:Clawdbot无法连接到Ollama服务
解决:
- 确认Ollama服务正在运行:
ollama serve - 检查Ollama的API地址:默认是
http://127.0.0.1:11434 - 在Clawdbot配置中确认baseUrl设置正确
9.2 模型加载失败
问题:Clawdbot显示模型不可用
解决:
- 确认Qwen3:32B已下载:
ollama list - 如果未下载,执行:
ollama pull qwen3:32b - 检查显存是否足够:至少需要24GB
9.3 响应速度慢
问题:Qwen3:32B响应时间过长
可能原因和解决:
- 首次加载:模型第一次加载到显存需要时间,后续请求会快很多
- 提示词过长:减少不必要的上下文
- 硬件限制:24G显存对于32B模型确实有些紧张,考虑:
- 使用量化版本(如qwen3:32b-q4_K_M)
- 升级到更大显存的GPU
- 调整并发请求数,避免同时处理多个请求
9.4 Token限制问题
问题:收到"context length exceeded"错误
解决:
- Qwen3:32B的上下文窗口是32K token,但实际使用时建议留有余量
- 在Clawdbot代理设置中调整
max_tokens参数 - 对于长文档处理,考虑分段处理
10. 总结:从工具到平台
通过这个教程,你应该已经掌握了Clawdbot的基本使用。让我们回顾一下关键点:
- 快速启动:一条命令启动服务,简单修改URL解决首次访问问题
- 核心理解:Clawdbot是网关,Ollama是后端,Qwen3:32B是模型,代理是你的使用界面
- 实际使用:通过Web界面直接对话,通过API集成到现有系统
- 高级功能:创建自定义代理实现不同功能,监控系统运行状态
Clawdbot的价值在于它把复杂的AI服务管理变得简单。你不需要成为系统管理员,也不需要写大量的胶水代码,就能拥有一个功能完整的AI代理平台。
对于Qwen3:32B这样的本地大模型,Clawdbot提供了一个生产级的部署方案。它解决了权限控制、监控观测、API标准化等问题,让你可以专注于应用开发,而不是基础设施维护。
最后,记住这个工作流程:
- 确保Ollama运行并加载了Qwen3:32B
- 启动Clawdbot:
clawdbot onboard - 用带token的URL首次访问
- 开始创建代理、对话、集成API
随着你对Clawdbot的熟悉,你可以探索更多高级功能,比如插件系统、多模型路由、自动化工作流等。但最重要的是先让系统跑起来,解决实际的问题。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 5
5 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)