
简明教程:实现OpenCLaw轻量级应用服务器部署及Ollama大模型本地化
因此,创建API Key的时候要指定你所新建的业务空间,以及应用详情页面的模型配置部分就可以随便写一个阿里云的模型了,例如”qwen3.5-plus“,因为反正都没有授权,用哪个都一样,这样的效果就是你的openclaw创建出来后,在对话时他会返回”403 Model access denied.“,这是我们预期之中的。至此,其实整体就搭建完成了,可以看到在正常查询了,但是由于我们的服务器资源很小
本篇内容依赖阿里云的轻量应用服务器搭建openclaw+本地部署ollama模型,实现个人Agent自由。其实主要还是考虑最近爆出的多起隐私安全问题,因此考虑本地openclaw替换为云上openclaw,至于需要给他授予什么权限,尽可能的由自己控制,再考虑到对于担心token费用问题的小伙伴来说,使用本地模型是最保险的选择(云服务器或者本地电脑部署均可)。
01
购买轻量应用服务器(预置openclaw镜像)


阿里云轻量应用服务器,新用户会有一次特价机会,我就是79块钱买了一年的轻量应用云服务器,一年可以省下大几百的费用,其实和普通云服务器一样的使用,可以自己独立部署其他应用。而且可以直接选择openclaw的镜像,免去复杂的安装过程 (如果想要本地自己安装,建议按照官网操作,亲测pnpm安装很快,坑少,遇到依赖什么就安装什么,https://openclaws.io/zh/install)

02
openclaw配置

云服务器创建完成后,点击服务器名称进入详情页面。选择“应用详情”,按照蓝色字体的提示,逐个点击,自动化配置,配置好,就可以通过web ui地址,访问你的小龙虾了。下面还有一些配置的注意事项,此页面的配置可以继续往下看。
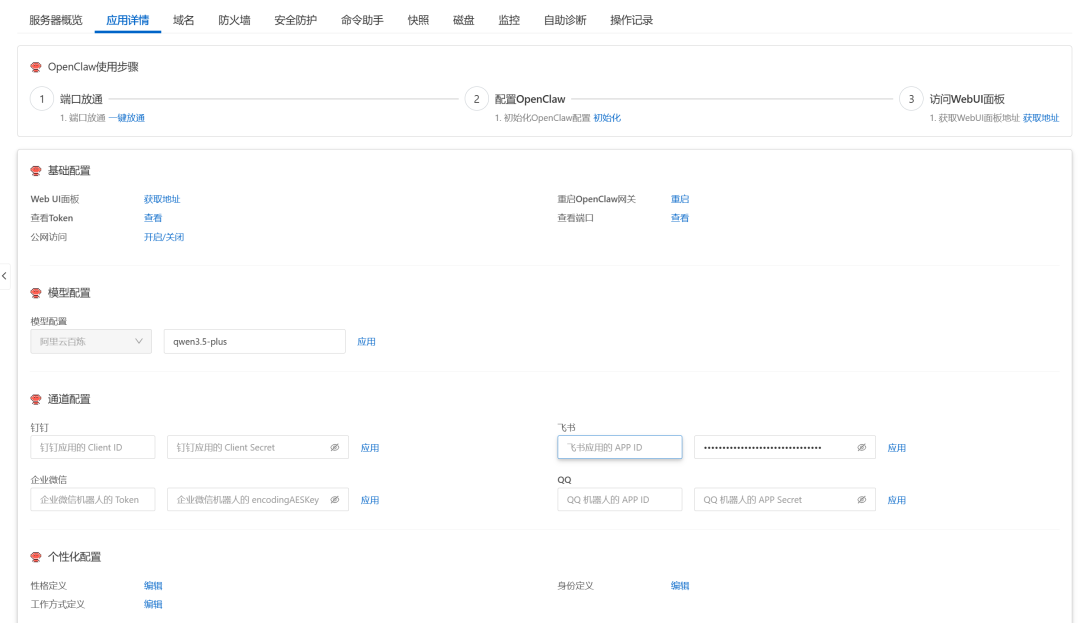
其中初始化位置需要提前创建你的百炼API Key。搜索阿里云百炼,进入百炼服务页面,右上角选择到你的云服务器对应的region,并点击右侧的设置按钮 -> 新增业务空间(因为默认空间权限等于账号权限,不便于控制,为了避免自己的钱被“乱花”,还是要做一些权限管控)。
在新的业务空间右侧的”模型权限流控设置“中,先将所有的模型不授权,仅为配置通整个流程,因为服务界面的初始化必须依赖百炼的API Key。因此,创建API Key的时候要指定你所新建的业务空间,以及应用详情页面的模型配置部分就可以随便写一个阿里云的模型了,例如”qwen3.5-plus“,因为反正都没有授权,用哪个都一样,这样的效果就是你的openclaw创建出来后,在对话时他会返回”403 Model access denied.“,这是我们预期之中的。

以上内容都配置完成之后,就可以通过web ui地址进入界面,如下:
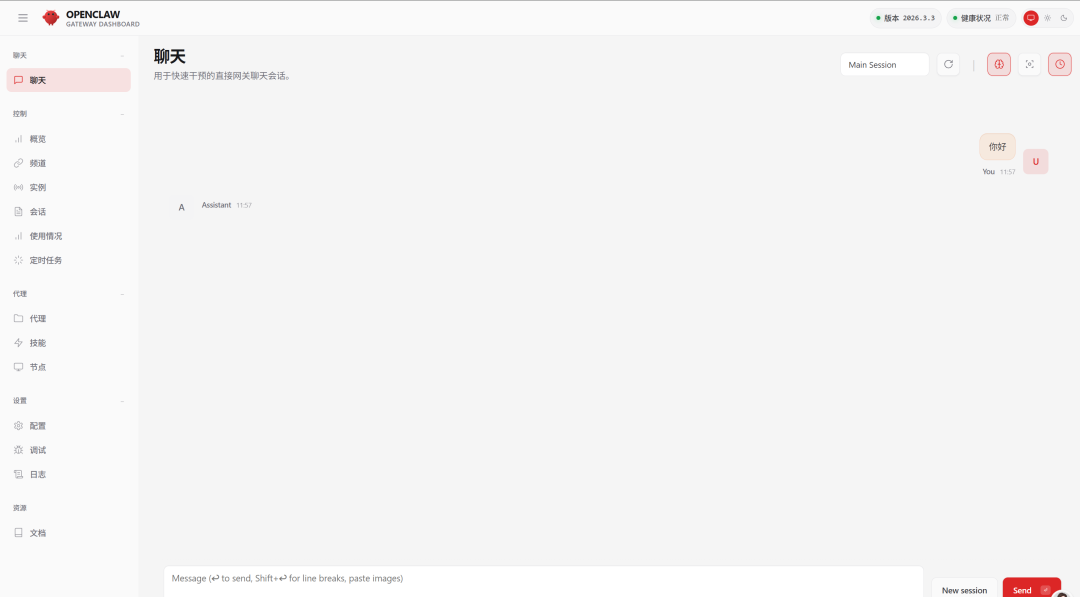
我们的第一部分的小龙虾部署就到此为止了。接下来就是部署本地模型,先说明一下,这篇文章主要是学习从0-1的将自己的Agent跑起来,并不是为了实际投产使用,所以会用尽量小的模型,毕竟服务器资源有限。如果不差钱,可以买更大的规格或者GPU服务器,效果更好,当然,直接用云厂商的大模型最简单。
03
安装ollama

-
前置准备
# 1. 安装依赖(CentOS 缺少会导致 Ollama 启动失败)sudo yum install -y curl wget libstdc++ glib2 openssl# 2. 关闭 SELinux(临时,避免权限拦截)sudo setenforce 0# 3. 关闭防火墙(或放行 11434 端口,二选一)sudo systemctl stop firewalld && sudo systemctl disable firewalld -
执行安装
# 安装 zstd 依赖(解决安装报错核心)sudo yum install -y curl wget libstdc++ glib2 openssl zstd -y# 官方一键安装(自动适配 CentOS)curl -fsSL https://ollama.com/install.sh | sh# 验证安装(出现版本号则成功)ollama -v -
启动 Ollama
# 启动服务sudo systemctl start ollama# 设置开机自启sudo systemctl enable ollama# 检查运行状态(显示 active (running) 则正常)sudo systemctl status ollama --no-pager04
下载 qwen:0.5b 模型

注意:非最终方案,可以按我的踩坑过程来,也可以直接跳到FAQ部分,一步到位,用最终模型
# 拉取最轻量的千问 0.5B 模型(约 500MB,2G 内存足够)ollama pull qwen:0.5b# 测试模型是否能运行(输入 你好 验证回复)ollama run qwen:0.5b# 退出测试:输入 /bye 回车目前本地的模型和openclaw都已经部署好了,其实验证一些基本的对话下来,效果还是不错的。(但是后续对接出现问题,这就是上面所说的FAQ中需要解决的)
接下来就是一些优化,以及最终呈现的问题了。
05
CentOS 专属内存优化

# 编辑 Ollama 服务配置,限制内存占用(给 OpenClaw 留空间)sudo mkdir -p /etc/systemd/system/ollama.service.dsudo tee /etc/systemd/system/ollama.service.d/override.conf > /dev/null <<EOF[Service]Environment="OLLAMA_MAX_LOADED_MODELS=1"Environment="OLLAMA_CPU_ONLY=1"Environment="OLLAMA_MEMORY_LIMIT=800M"MemoryHigh=800MMemoryMax=900MEOF# 重载配置并重启 Ollamasudo systemctl daemon-reloadsudo systemctl restart ollama06
OpenClaw 对接配置

配置文件路径:`/home/admin/.openclaw/openclaw.json`
# 备份原配置文件,避免误操作导致openclaw异常cp openclaw.json openclaw.json.bak.1# 修改配置文件vim openclaw.json# 核心修改点:1、models和agents部分,替换为你本地的模型,模型名字可以通过 ollama list 命令查询,例如:'''"models": { "providers": { "ollama": { "baseUrl": "http://127.0.0.1:11434/v1", "apiKey": "ollama-local", "api": "openai-completions", "models": [ { "id": "qwen2:7b-instruct-q4_K_M", "name": "本地qwen2:7b-instruct-q4_K_M", "api": "openai-completions", "reasoning": false, "input": [ "text" ], "cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 }, "contextWindow": 16000, "maxTokens": 1024 } ] } } }, "agents": { "defaults": { "model": { "primary": "ollama/qwen2:7b-instruct-q4_K_M" }, "models": { "ollama/qwen2:7b-instruct-q4_K_M": { "alias": "qwen2:7b-instruct-q4_K_M" } }, "workspace": "/home/admin/.openclaw/workspace", "compaction": { "mode": "safeguard" }, "maxConcurrent": 4, "subagents": { "maxConcurrent": 8 } } },'''# 核心修改点:2、也就是FAQ中遇到的,contextWindow参数改为16000# 以上修改点,你可以将原文件和你新模型名给AI让他帮你把原模型全部替换掉,但是要主要隐私安全,涉及到aksk的内容先隐藏掉修改完配置文件后,可以在云服务器页面进行重启Openclaw网关,重启后刷新一下openclaw页面即可。
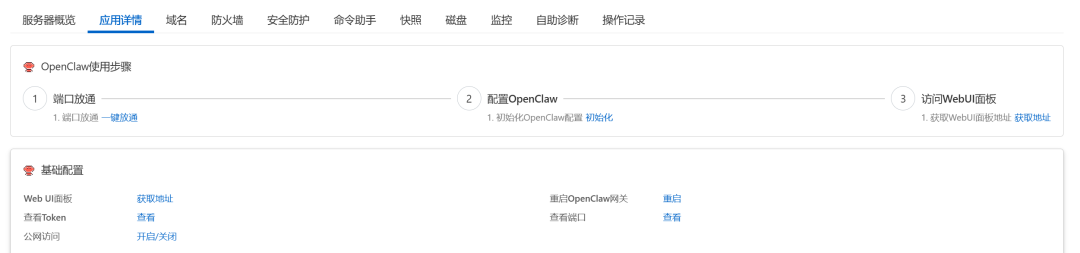
至此,其实整体就搭建完成了,可以看到在正常查询了,但是由于我们的服务器资源很小,跑7b模型会很慢,后续只需要在此基础上就行优化,替换高规格服务器,或者直接使用本地电脑也可以。

07
FAQ

问题一
问题描述:使用qwen0.5b模型,报错如下,原因是当前使用的模型上下文窗口(Context Window)太小(仅 4096 Tokens),但 OpenClaw 要求最小 16000 Tokens.

解决措施:修改 openclaw.json 文件, contextWindow参数改为16000
问题二
修改完contextWindow,报新的错误,该报错表明,qwen0.5b不支持tool功能

解决措施:拉取7b及以上模型(考虑当前服务器规格,选取Qwen7B 极致量化版(Q4KM)),`ollama pull qwen2:7b-instruct-q4KM`.
# 运行7b模型,报错如下:ollama run qwen2:7b-instruct-q4_K_M# Error: 500 Internal Server Error: model requires more system memory (4.3 GiB) than is available (2.6 GiB)明显内存不够用,需要使用虚拟内存。`free -h`查询:

增加虚拟内存,操作步骤如下:
1、先停止并删除原有 Swap
# 1. 关闭当前 Swapsudo swapoff /swapfile# 2. 删除原有 Swap 文件sudo rm -rf /swapfile2、创建更大的 Swap(推荐 6GiB)
# 1. 创建 6GB 的 Swap 文件(数字可以改,比如 4G 就写 4G)sudo fallocate -l 6G /swapfile# 2. 设置权限(必须,否则系统不认)sudo chmod 600 /swapfile# 3. 格式化 Swap 文件sudo mkswap /swapfile# 4. 启用新的 Swapsudo swapon /swapfile# 5. 确认开机自动挂载(防止重启后失效)# 先检查是否已有记录,没有就添加grep -q '/swapfile' /etc/fstab || echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab3、验证扩容是否成功free -h如上显示swap total为6g,说明已修改成功。
这时候可以验证下模型是否可以:`ollama run qwen2:7b-instruct-q4KM`,至此踩坑的点已经都填好了,可以继续配置openclaw了。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)