
Skills 之后是什么?Google 刚补上 Agent 生态最后一块拼图!Anthropic未来规划预测 !
Google 刚发了个东西叫 A2UI——让 AI 能画界面。A2UI 官方介绍什么意思?我举个例子。
Google 刚发了个东西叫 A2UI——让 AI 能画界面。

什么意思?我举个例子。
假如豆包用了 A2UI,你说"帮我叫个车去机场",它直接弹出一张地图——你在地图上点一下确认上车点,再选个时间和车型,下单。
全在对话里完成。
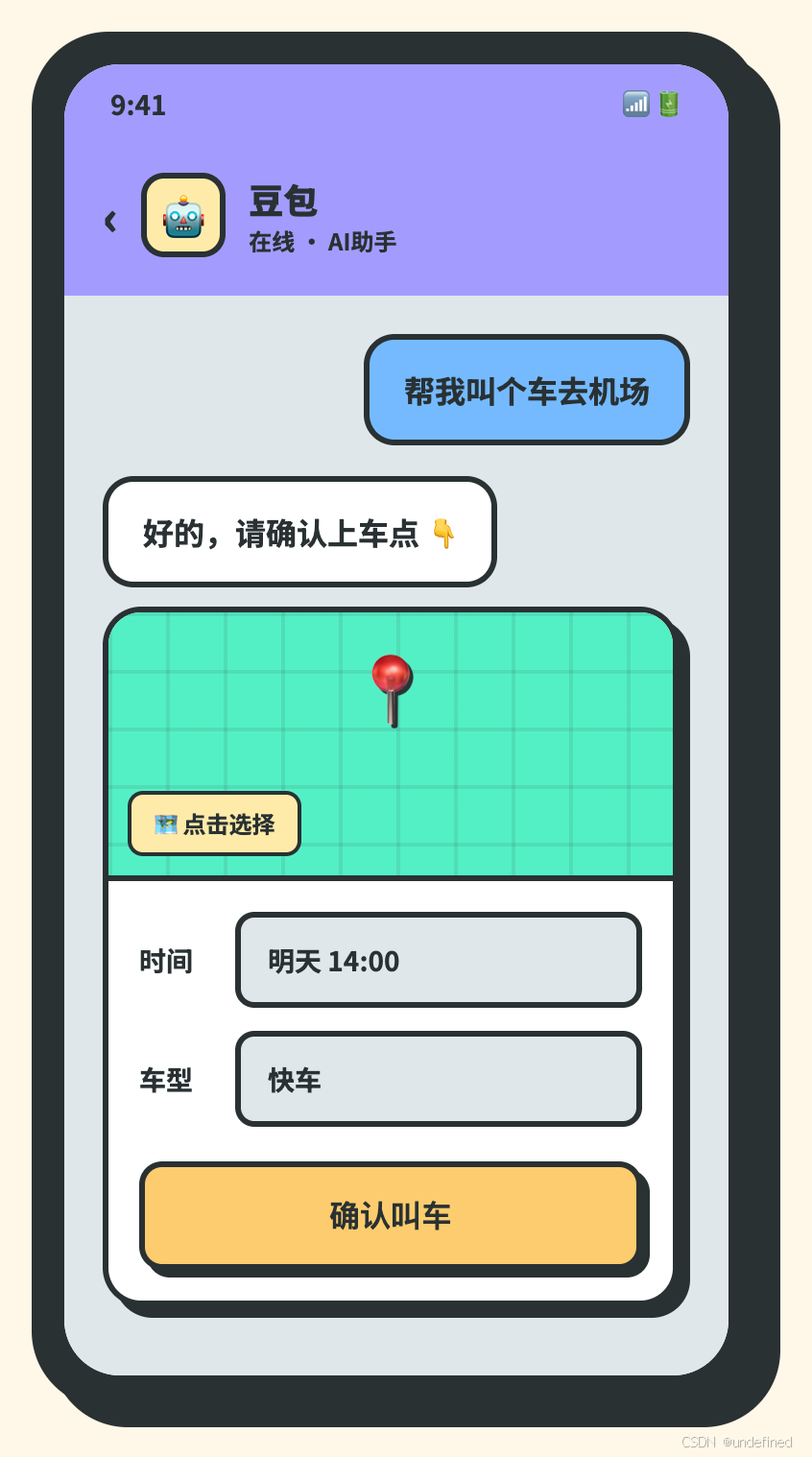
MCP、Skills 都搞不定的事,它能搞定——让 AI 不光会说,还会画界面。
如果你用 Claude,这事儿跟你有关——
Anthropic 下一步要干嘛,可能就藏在你天天用的 Artifacts 里。
纯数据流:MCP/Skills 的局限
你可能想:MCP 和 Skills 不是够用了吗?
不够。
因为它们都是纯数据流——
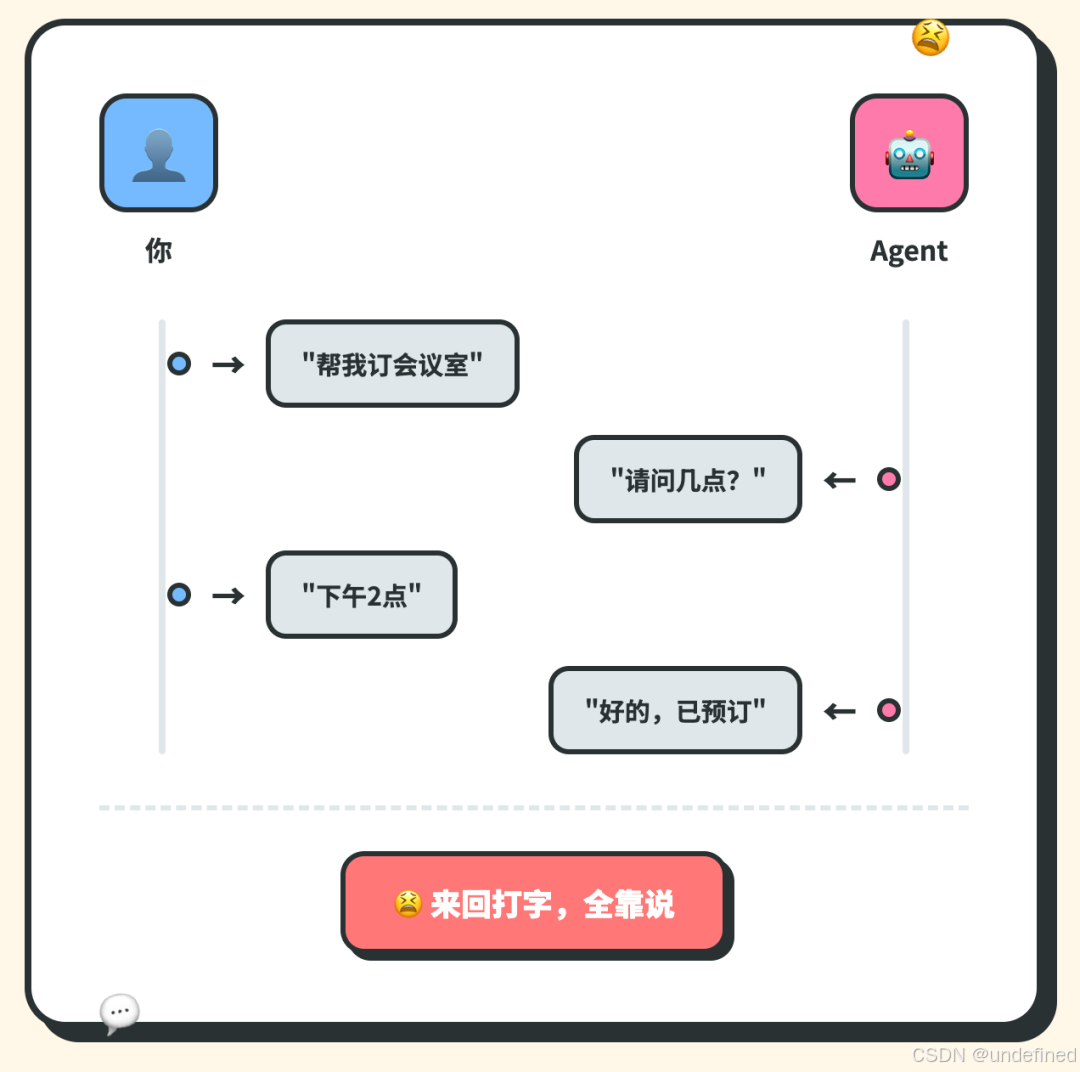
MCP 让 Agent 能调工具,但结果只能用文字告诉你。
Skills 让 Agent 有专业能力,但也只能用文字告诉你。
对话 vs UI:不是偏好,是大脑决定的
举个例子:选航班。
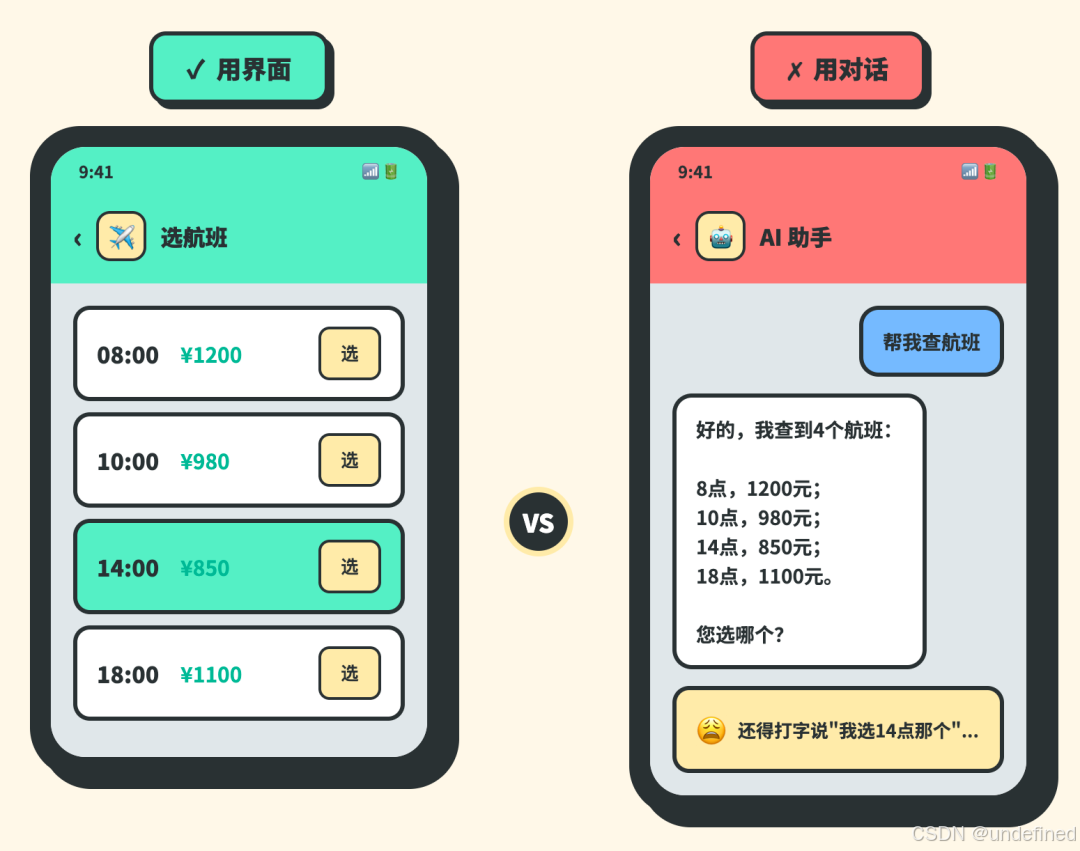
用对话选?你得打字说"我选14点那个850块的"。
用界面?点一下就行。
有些事,对话压根做不到:
想看酒店实拍?对话只能说"房间很大",界面能直接甩图
想选上车地点?对话得打字"东门左边50米",界面点一下就行
纯数据流的问题,就在这。
A2UI:交互补上的一环
回到开头豆包的例子——你说"帮我叫车",它弹出地图让你点。
背后咋回事?
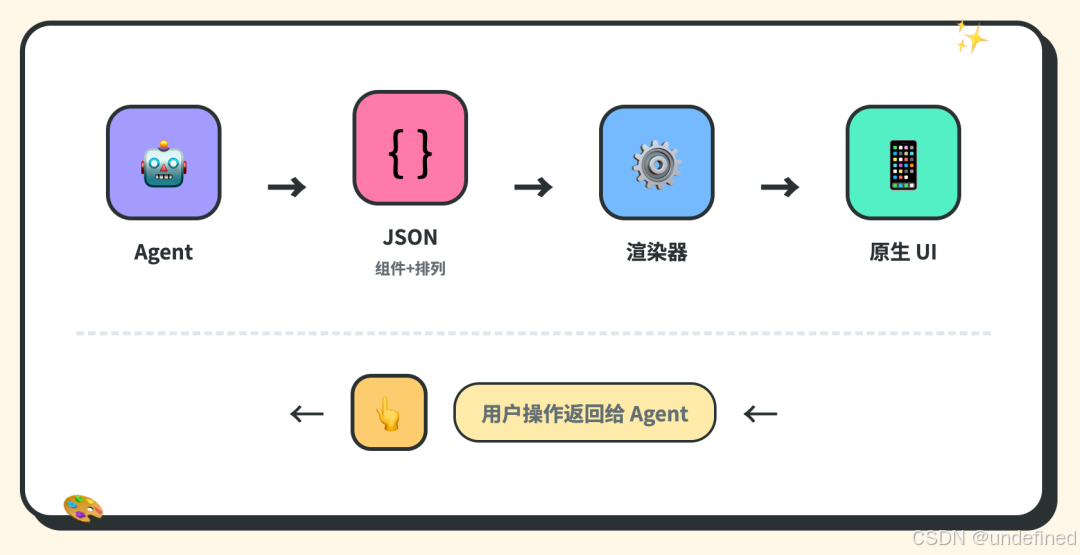
1.Agent 输出一段 JSON,描述要显示什么组件、怎么排列
2.这段数据发给渲染器
3.渲染器有一套组件库(地图、按钮、日历…),从库里找到对应的,画出来
4.你点了确认,渲染器把结果告诉 Agent
5.Agent 收到,继续干活
对Agent的改变
以前:Agent 返回 “请问几点?” → 你打字回答
现在:Agent 返回 { 日历组件 } → 你点一下
等等,你可能会问:既然能画界面,为啥不直接让 Agent 写代码?
为什么不直接写代码?
代码能干的事太多了——能读文件、能发请求、能删东西。
让 Agent 写代码 = 把你的电脑交给它。
A2UI 的做法:给 Agent 一套受限的组件库。
能用:日历选择器、地图选点、表单输入、列表选择、确认按钮、图片展示
不能:读写文件、执行代码、发送请求、访问系统
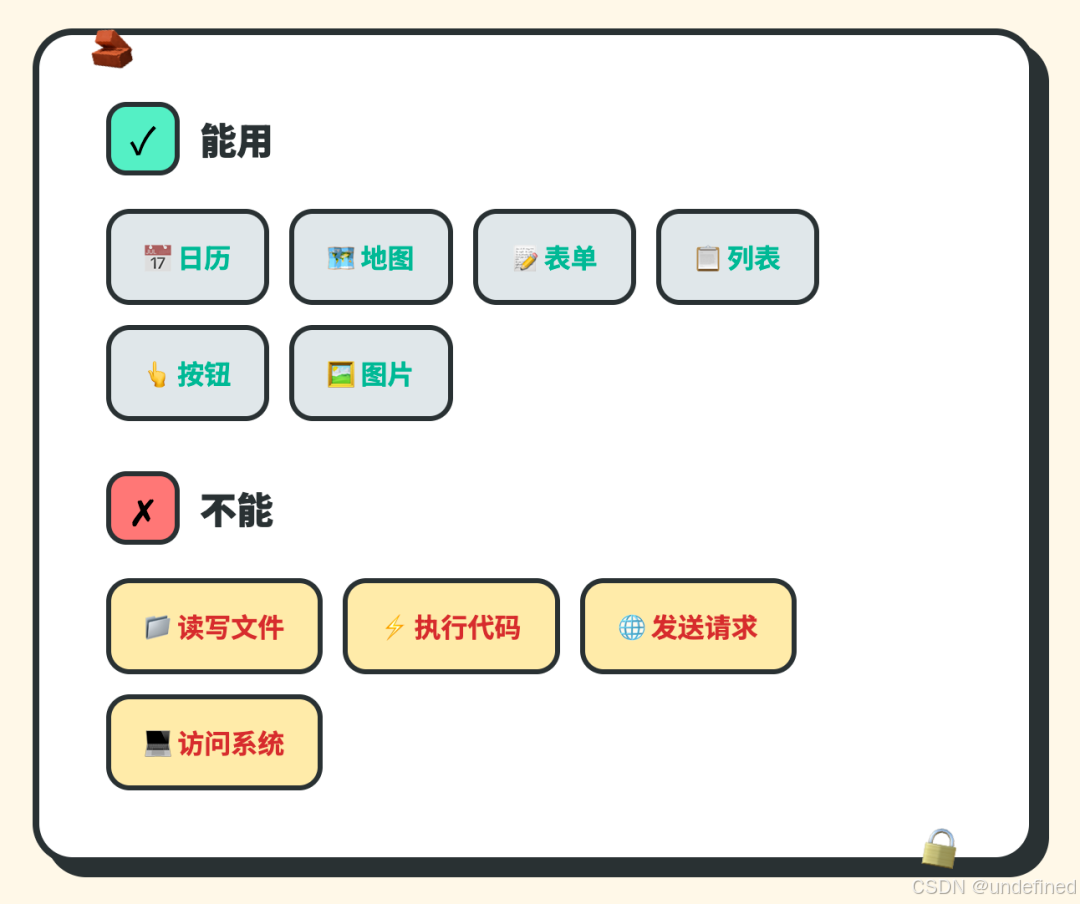
就像给小孩一盒乐高——能拼出各种形状,但不会伤到人。
A2UI 干的事:Agent 不光会"说",还能"画"——而且画得安全。
三大产品特性
安全 → Agent 只能画你允许的组件,不会执行恶意代码
实时 → 界面边生成边显示,不用等 AI 想完
跨端 → 手机/网页/桌面都能用,体验一致
一句话:A2UI = 数据安全 + 界面丰富。
三层生态:更大的图景
A2UI 只是拼图的一块。
Agent 要真正好用,得有三层基础设施:
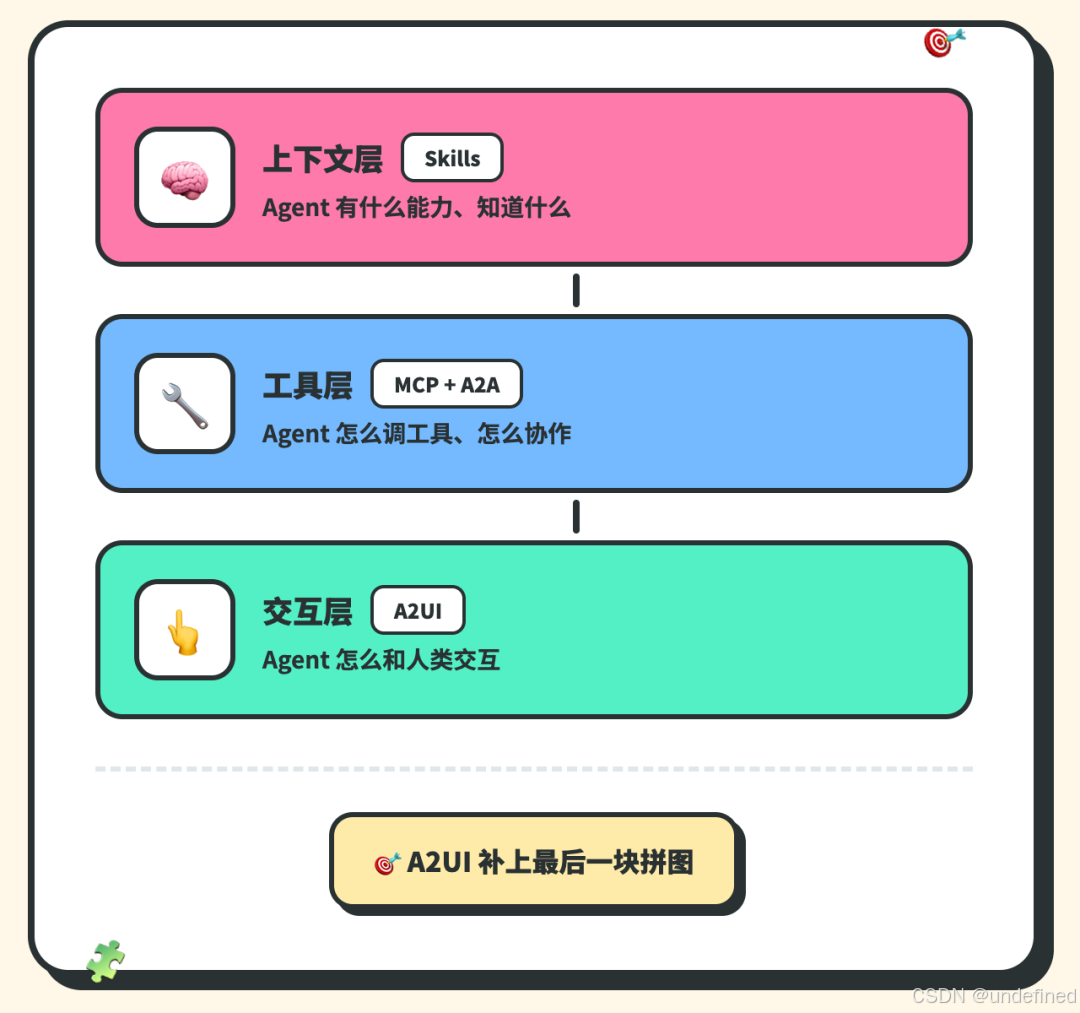
上下文层 Skills → Agent 有什么能力
工具层 MCP + A2A → Agent 怎么调工具、怎么协作
交互层 A2UI → Agent 怎么和人类交互
Skills 定义能力,MCP+A2A 连接工具和 Agent,A2UI 连接人类。
三层生态齐了,Agent 世界才完整。
Artifacts 2.0:Anthropic 的下一步
说完三层生态,回到开头的问题:这跟 Claude 用户有啥关系?
为啥我觉得 Anthropic 会往这走?
Artifacts 已经是动态内容的雏形了。
用户习惯了这个形态。
只差一步——加上交互能力。
Artifacts 1.0(现在)
↓ 能跑代码、能预览,但你点了啥 Agent 不知道
Artifacts 2.0(预判)
↓ 你点了啥,Agent 能收到,还能接着帮你干活
对你意味着啥?
想象一下:你在 Claude 里说"帮我对比这三个方案",它直接弹出一个表格,你边看边勾选,选完它继续帮你分析。
对话中直接弹出交互界面。
不用离开 Claude 就能完成复杂操作。
Claude 从"对话工具"变成"对话式操作系统"。
最后说两句
A2UI 本质就一件事:给纯数据流补上交互层。
它的价值 = 要比好几个选项的时候,不用靠脑子记了。
读完记住这四个词:
纯数据流 → MCP/Skills 的局限
A2UI → 交互补上的一环
三层生态 → 上下文 + 工具 + 交互
Artifacts 2.0 → Anthropic 的下一步
Agent 交互的下一步,已经在路上了。
原文:https://developers.googleblog.com/introducing-a2ui-an-open-project-for-agent-driven-interfaces/

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)