
播客内容如何高效转Skills以及87个抽取的Lenny‘s Product Skills
播客内容如何高效转Skills以及87个抽取的Lenny's Product Skills
文章目录
- Lenny 播客skills
-
- 第一部分:这 86 个 skills 从哪来?以及如何写 skills
- 第二部分:86 skills 开源仓库怎么用(分类 + 示例 + playbook)
-
- 2.1)仓库结构:一个 skill 就是一套可复用工作流
- 2.2)安装与调用:让它进入你的工作流
- 2.3)86 个 skills 的分类概览(README 里的 9 大类)
- 2.4)不同分类的 skills 示例:它能做什么、怎么用、需要什么材料
- 2.5)一个完整 playbook:用 skills 做“AI 导购”从 0 到 1
- 2.6)快速演示:加载“技能包”前后的巨大差异
- 场景一:写一份 PRD(产品需求文档)
- 场景二:制定 AI 产品策略
- 2.7)SKILL.md 是怎么“编程” AI 的?(结构化提示的固定模块)
- 2.8)怎么用:从安装到调用(按 README)
- 关键细节:怎么控制上下文长度、只投喂最相关的 skill?
- 总结与链接
Lenny 播客skills
TL;DR:它是什么:把 Lenny 播客的产品经验,蒸馏成可安装的 86 个 SKILL.md(给 Claude Code/Cursor 用)。
解决什么:把“文章/访谈里的经验”变成可复用工作流,让 AI 输出更像资深产品顾问。
怎么看/怎么用:第一部分讲来源与制作方法;第二部分讲仓库内容、分类、技能示例与 playbook。
我们都习惯了向 ChatGPT 或 Claude 提问。但你是否发现,当你问一些深度的垂直领域问题时,AI 给出的答案往往是“正确的废话”?
比如你问:“如何写一份高质量的 PRD?”
AI 会告诉你:“包含背景、目标、功能列表……” —— 这没错,但这是实习生水平的答案,不是专家级的洞见。
今天推荐的这个 GitHub 开源项目 Lenny’s Product Skills,正是为了解决这个问题。它主要开源的是一套可直接加载的 Skills(结构化认知与方法论);至于这些 skills 怎么被“蒸馏”出来,也有人公开了复盘(含部分代码与数据细节)。它能让你的 AI 更像一个有产品方法论的顾问,而不是只会套模板。
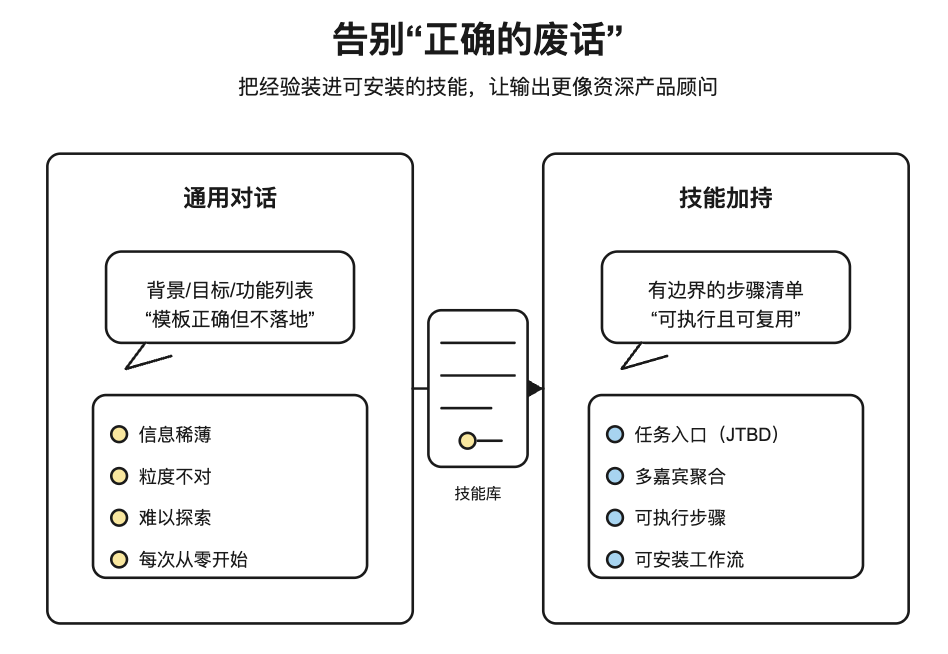
第一部分:这 86 个 skills 从哪来?以及如何写 skills
1.1)项目介绍:不仅是知识库,更是思维插件
- 项目名称:Lenny’s Product Skills
- GitHub 地址:RefoundAI/lenny-skills
- 核心内容:86 个结构化的 Markdown 文件(Skills)。
这个项目的核心逻辑是:Context is King(上下文即王道)。
作者将全球最火的产品播客 Lenny’s Podcast 的 297 期播客转写内容,提炼成 AI 可读的结构化数据。这里面包含了 Marty Cagan(《启示录》作者)、Shreyas Doshi 等大神的实战经验。
当你把这些文件投喂给 AI 时,你不是在和一个通用大模型对话,而是在和一个学习了上百位顶级专家经验的超级顾问对话。
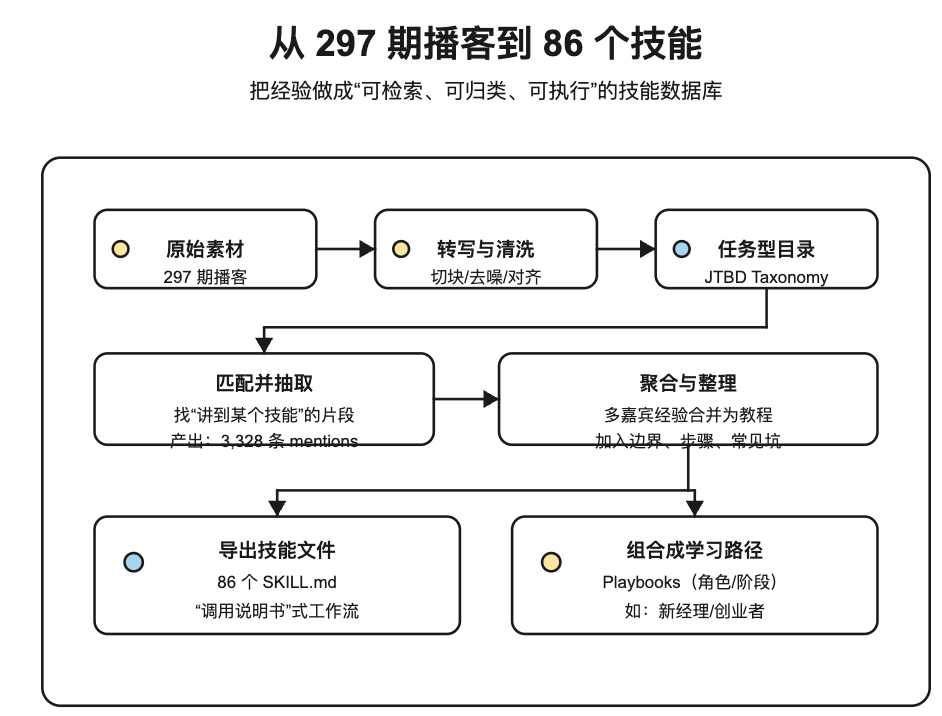
1.2)幕后揭秘:从 297 期播客到 86 个 Skills,到底怎么做出来的?
这项目最硬核的部分,其实不是最终那 86 个 SKILL.md,而是把 Lenny Podcast 全部 297 期转写变成“可检索、可归类、可执行”的技能数据库的过程。
下面这段流程,主要参考了 Refound 团队对外公开的复盘文章:How We Built a Skills Database from Lenny’s Podcast Episodes。它解释了为什么“随便抽取金句/框架”会失败,以及他们最终怎么把它做成真正能用的东西。
1)先想清楚:我们要做 Skills,不是再做一个 Chatbot
他们一开始就明确不想做另一个聊天机器人,因为 chat 形态天然有两个痛点:
- Discovery:你不知道自己不知道什么,很难问对问题。
- Repeat use:每次对话都从零开始,无法把经验沉淀成可复用的“工作插件”。
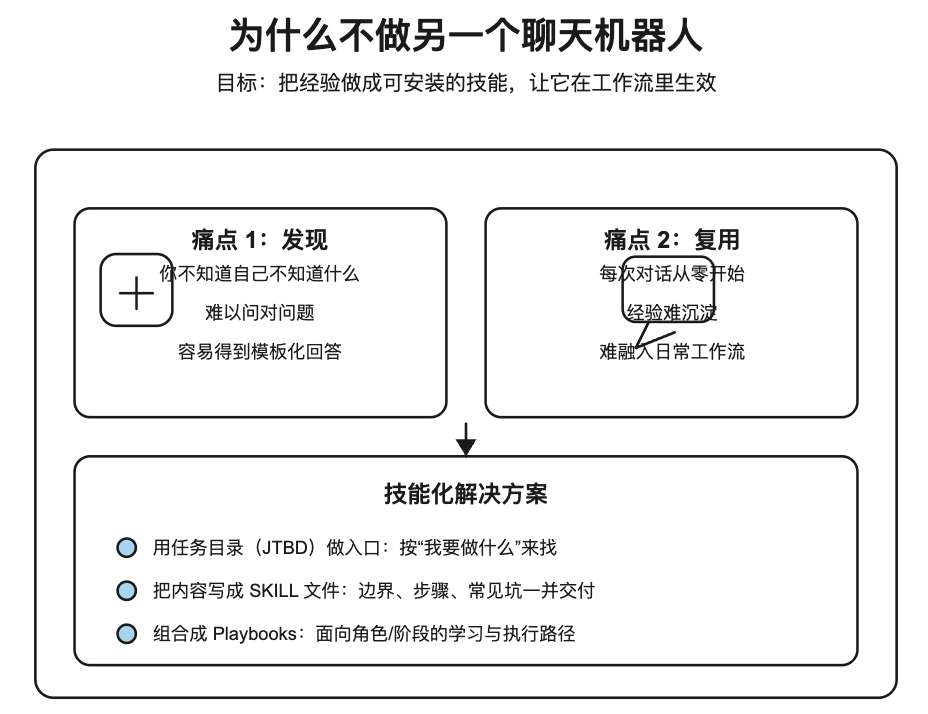
所以他们把目标定成:做一套可以被安装/加载的 Agent Skills(Claude Skills),让这些经验在你写文档、做面试准备、规划 roadmap 时,直接在“工作流里生效”。
2)第一次失败:自底向上抽 3,163 个 Frameworks,看起来多但没用
第一版做法很直觉:让模型读每一份转写,抽取所有“可命名的框架/心智模型/战术建议”,并要求可归因到具体引用。
结果数据非常“壮观”:
| 指标 | 数值 |
|---|---|
| 处理转写数 | 297 |
| 抽取 frameworks | 3,163 |
| 平均每期 | 10.6 |
| 成本 | 约 $50 |
| 耗时 | 约 5 小时 |
但他们很快发现它在产品层面是坏的:
- 内容太薄:绝大多数 framework 只被 1 个嘉宾提到,页面只剩一句 quote,没法指导行动。
- 粒度不对:用户不会搜索“XX Support Framework”,用户想问的是“我该怎么做用户支持/怎么做 roadmap”。
- 发现性更差:3,000+ 条目让“探索”本身变成负担。
一句话:抽得再多,抽象层级错了,就会变成“看起来很牛的垃圾输出”。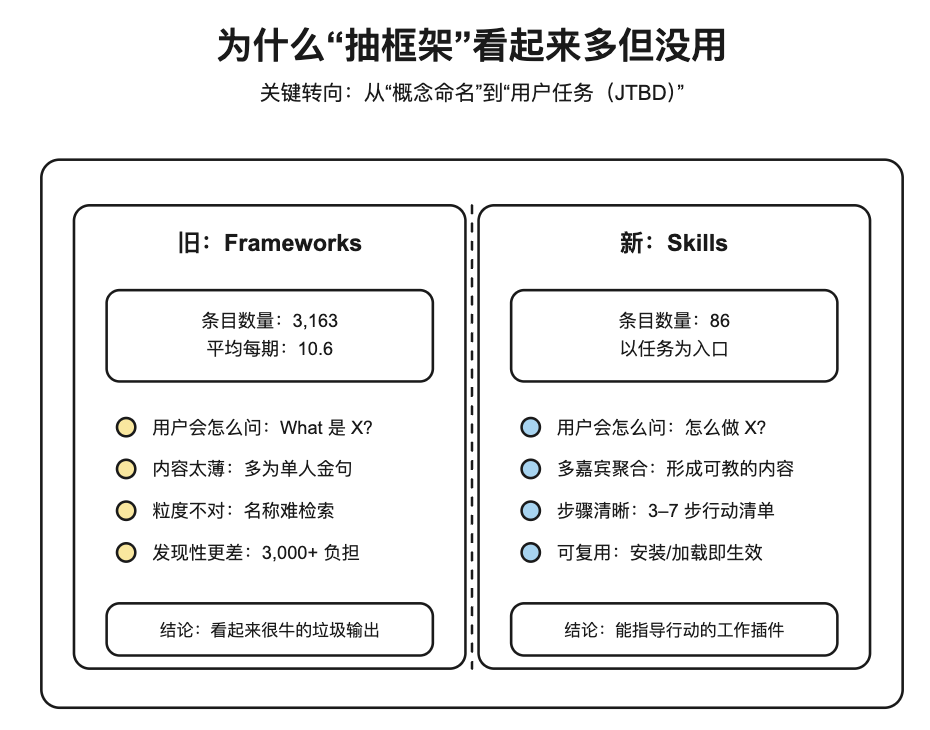
3)关键转向:用 JTBD(Jobs To Be Done)做顶层 Taxonomy
他们把思路从“找框架”改成“找任务”。不是问“这个概念叫什么”,而是问:
- 用户真正要完成的 job 是什么?(例如:Prioritizing Roadmap / Writing PRDs / Difficult Conversations)
- 这些 job 才是可复用的“技能入口”,框架只是技能里的工具。
| 维度 | 旧:Frameworks | 新:Skills |
|---|---|---|
| 条目数量 | 3,163 | 86 |
| 用户提问 | “What is X?” | “How do I do X?” |
| 内容深度 | 多数只 1 个嘉宾 | 每个 skill 聚合多嘉宾经验 |
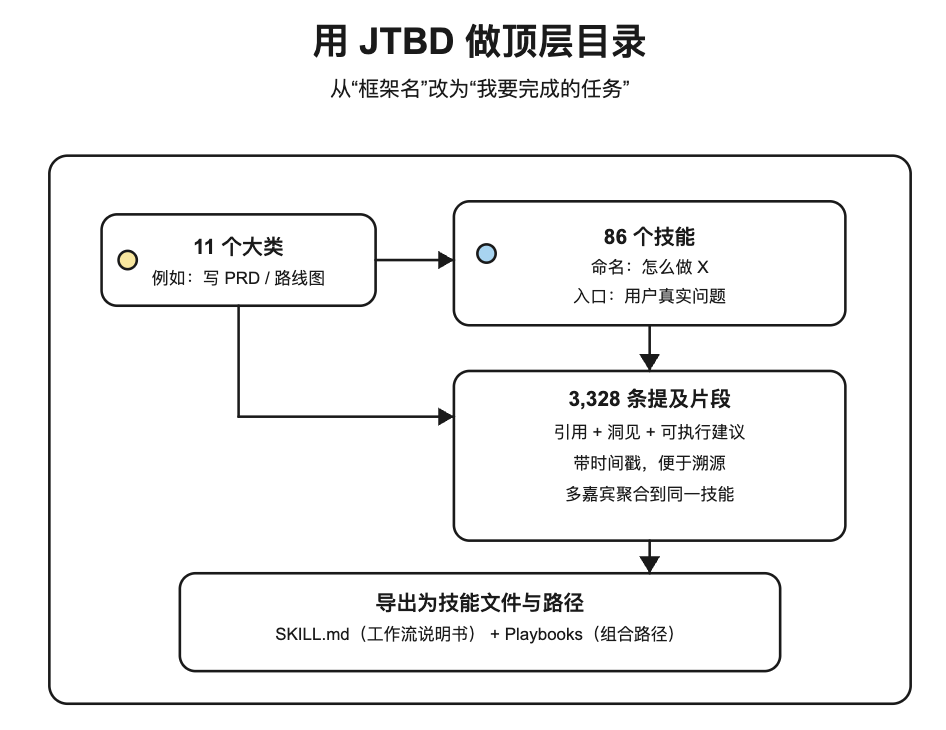
他们先用已有数据做标签频次分析与聚类,定义出 11 个大类、86 个 skills,然后让模型做“按 taxonomy 匹配内容”的抽取。
4)第二次抽取:并行匹配 86 个 skills,拿到 3,328 条 mentions
新流程的核心是:给模型一个明确的 taxonomy,让它在每份转写里找出“哪些段落在讲某个 skill”,并抽取 quote + 一句话洞见 + 可执行建议 + 时间戳;如果发现 taxonomy 没覆盖,还可以建议新 skill。
他们公开的结果:
| 指标 | 数值 |
|---|---|
| Skills | 86 |
| Total mentions | 3,328 |
| Episodes processed | 297 |
| 耗时 | 约 15 分钟 |
注意这里的本质变化:不是“生成一堆结论”,而是先把信息结构化成数据库,再从数据库生成可用的技能页。
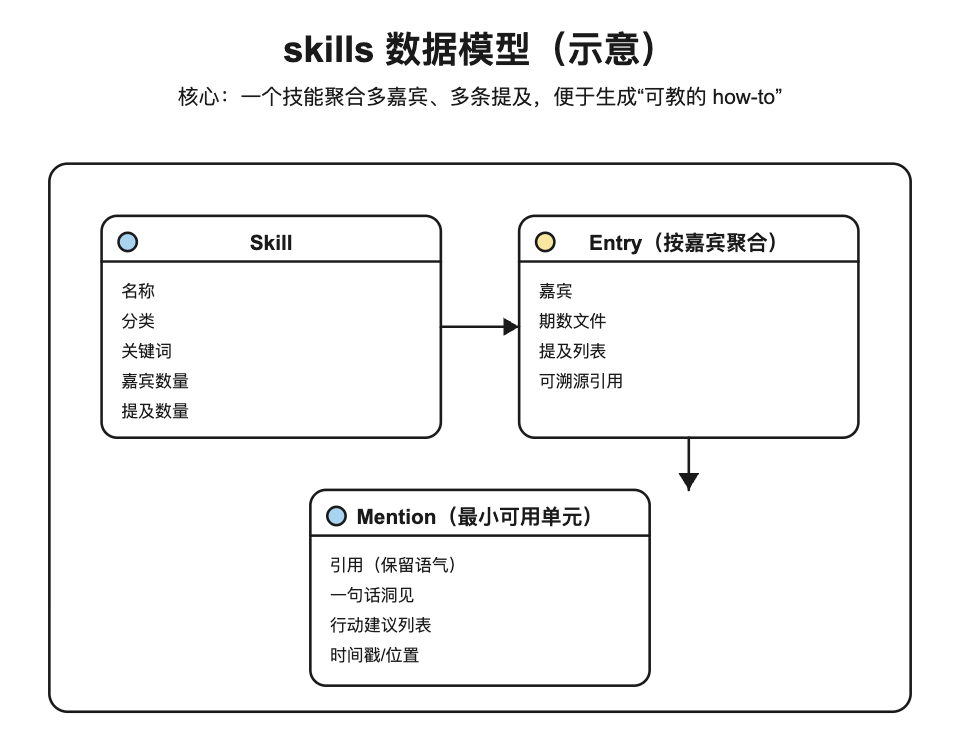
4.5)数据模型:skills.json 大概长什么样?
他们把抽取结果落成一个结构化文件(文章里用 skills.json 举例),核心就是“一个 skill 聚合多嘉宾、多条 mentions”,每条 mention 都带可执行建议与时间戳,便于溯源。
interface Skill {
name: string
category: string
keywords: string[]
guest_count: number
mention_count: number
entries: Array<{
guest: string
episode_file: string
mentions: Array<{
quote: string
insight: string
tactical: string[]
timestamp: string
}>
}>
}
5)从“引语合集”到“可执行技能”:再做一次整理与产品化
即使聚合完 quotes,直接展示也会变成“引语墙”。所以他们又做了两件事:
- 把每个 skill 再跑一次整理:从 quotes 里合成更像教程的“how-to guide”。
- 做 Playbooks:把多个 skills 组合成面向角色/阶段的学习路径(比如 First-Time Manager、Startup Founder)。
最终每个 skill 会被导出为可下载的 Agent Skill 文件(也就是你在仓库里看到的 SKILL.md):它既是知识,也是“调用说明书”。
1.3)如果你也想做自己的“技能库”,可以怎么复刻?
这套方法不仅适用于播客,也适用于 YouTube、课程库、内部 Wiki,尤其适合你这种“有很多技术类公众号文章”的场景:材料够多、主题重复、但分散在一篇篇文章里。
下面给一套更可操作的复刻流程(从 0 到 1 做出能用的 skills 库)。
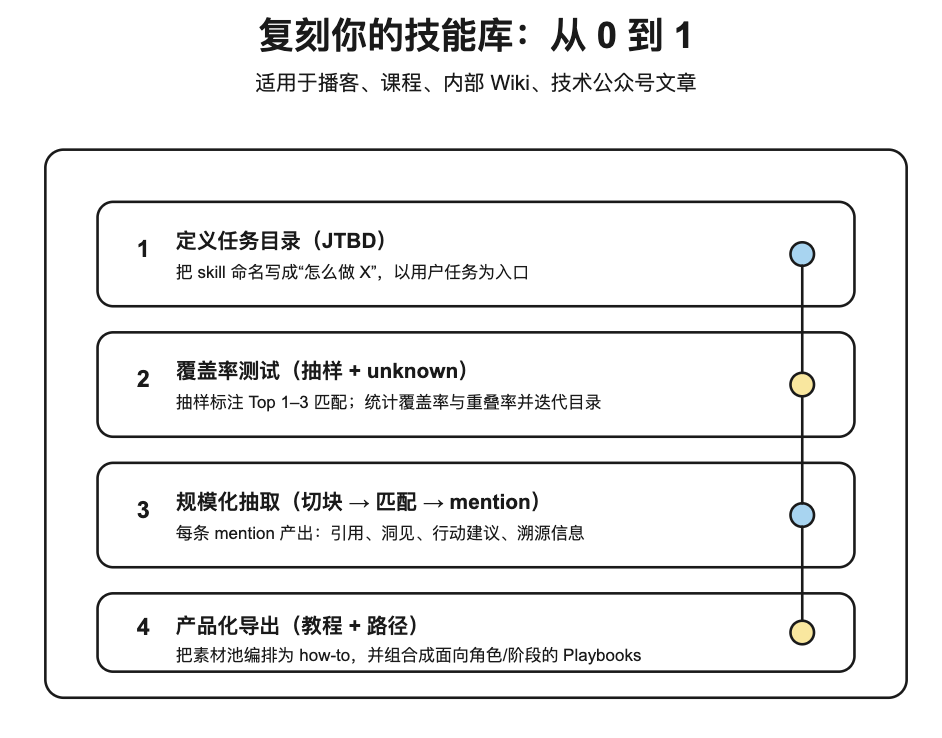
1.3.1)怎么定义 taxonomy:用 JTBD 把“文章主题”变成“用户任务”
taxonomy 的目标不是把文章分类得很漂亮,而是让读者/团队能用“我现在要做什么”来找到可执行的指导。
做法:从你读者的高频问题出发,把技能写成“怎么做 X”的动词短语。
技术类公众号常见的技能 taxonomy 示例(仅示意,你会按内容调整):
| 大类 | skills 示例(JTBD 形式) |
|---|---|
| 工程基础 | 写出可维护的模块边界、写出可测试的代码、设计 API 契约 |
| 调试与排障 | 定位线上问题、写出可复现用例、构建排障 checklist |
| 性能与成本 | 定位性能瓶颈、做容量评估、做成本优化(cache/并发/IO) |
| 系统设计 | 做架构权衡、拆分服务、设计数据一致性与容错 |
| DevOps | 设计 CI/CD、做灰度发布、做可观测性(metrics/log/trace) |
| 安全与合规 | 做鉴权设计、做数据脱敏、做安全基线检查 |
| AI/数据(可选) | 做 RAG 评估、做 prompt 迭代、做线上反馈闭环 |
一个好 skill,至少要写清楚 4 件事:
- 用户会怎么问:例如“怎么定位接口偶发 500?”
- 适用边界:什么时候适用、什么时候不适用
- 可执行步骤:3–7 步的行动清单
- 常见坑:避免把“经验贴”写成“口号贴”
如果你不知道从哪下手,可以用一轮 prompt 先“起草 taxonomy”,再人工收敛:
你是一个技术内容编辑+知识库架构师。
我有一批技术公众号文章(标题+摘要+标签)。请基于 JTBD 为它们设计一个 skills taxonomy。
要求:
1) skill 命名必须是“怎么做 X”的动词短语
2) 输出 8–12 个大类,每类 6–12 个 skills
3) 每个 skill 给出:slug、1 句定义、3 条包含范围、3 条不包含范围、5 个关键词、3 个读者提问示例
4) 避免重叠(两个 skill 不能回答同一个问题)
输入文章列表:
- {标题}|{一句话摘要}|{标签}
- ...
1.3.2)怎么确认 taxonomy 能覆盖主要问题:用“抽样标注 + Unknown 桶”做覆盖率测试
最常见的坑是:taxonomy 看起来很全,但一跑就发现大量内容“无处安放”或“多处都能放”。
一个简单可量化的方法:
- 抽样 30–50 篇文章(覆盖不同年份/栏目/技术栈)。
- 对每篇文章做两件事:
- 选出 Top 1–3 个最匹配 skills
- 如果没有匹配,必须落到
unknown,并说明“缺了哪个 skill”。
- 计算两类指标:
- 覆盖率:落到已存在 skills 的比例(目标先到 80–90%)
- 重叠率:同一篇文章被“同等合理”地分到很多 skills 的比例(越低越好)
这一步可以人工做,也可以用 LLM 辅助做“初标注”,再由你复核。
覆盖率测试 prompt 模板:
你是 taxonomy 评审官。给定 skills taxonomy 与一篇技术文章的摘要/小标题,请完成:
1) 选择最匹配的 1–3 个 skill_slug(按相关性排序)
2) 对每个匹配给出匹配理由(引用文章中的关键信息)
3) 给出信心分 0-100
4) 如果没有任何一个 skill 合适,输出 unknown,并提出 1 个你建议新增的 skill(含名称+定义)
输出必须是 JSON。
当你看到 unknown 经常出现、或某两个 skills 经常“抢同一批文章”,就说明 taxonomy 需要合并/拆分/改名。
1.3.3)规模化抽取是怎么做的:把文章切块 → 匹配 skill → 抽出结构化 mentions
“规模化抽取”不是让模型把整篇文章总结一遍,而是把内容变成数据库可用的最小单元(mentions)。
一个典型 pipeline 是:
- 清洗与切块:按标题层级切分(
##/###),再按长度把段落切成 chunks。 - 匹配 skill:对每个 chunk 判断它讲的是哪个 skill(允许 none/unknown)。
- 抽取 mention:每个匹配 chunk 输出结构化字段:
quote:原文关键句(保留语气)insight:一句话洞见tactical:可执行建议列表(动作化)trace:溯源信息(文章标题/URL/小节标题/段落序号)
- 聚合:把同一个
skill_slug下的 mentions 聚合起来,形成一个“技能页”的素材池。 - 再整理:对每个 skill 的素材池做一次“how-to 编排”(步骤、诊断问题、常见坑、边界条件)。
抽取 prompt(面向“单个 chunk”)示例:
你在为一个 skills 数据库做抽取。
输入:
- taxonomy(skills 列表,包含 skill_slug 与定义)
- article_meta(标题、URL)
- section_path(例如:"2.3 性能优化 / 2.3.1 缓存")
- chunk_text(正文片段)
任务:
1) 判断该 chunk 是否属于某个 skill_slug(不属于则返回 null)
2) 若属于:抽取 1–3 条 mentions,每条 mention 必须包含 quote/insight/tactical/trace
3) tactical 必须是动词开头、可执行、且不超过 15 个字
4) trace 必须能让人回到原文定位(title/url/section_path)
输出:严格 JSON。
提示:文章很多时,你通常会把“匹配 skill”与“抽取 mention”拆成两步,先分类再抽取,整体会更稳。
1.3.4)playbooks 一般怎么定义:把 skills 组合成“角色/阶段/目标”的作业路径
skills 是原子能力,但读者往往需要的是一条“能照着走”的路线。
playbook 不是“技能列表拼盘”,而是一个面向特定人群的任务流,通常包含:
- persona:适用对象(例如:新上手的后端工程师 / 小团队技术负责人)
- when:触发时机(例如:准备做一次大改造 / 准备上线一个新服务)
- goal & success:目标与成功标准(可量化更好)
- phases/sections:按阶段组织(诊断 → 设计 → 实施 → 验证 → 复盘)
- skills 组合:每个阶段选 2–5 个关键 skills,并说明先后顺序
- deliverables:每阶段要产出的交付物(文档/脚本/Checklist/PR 模板)
- anti-patterns:最常见的失败方式(让读者避坑)
playbook 的一个最小 JSON 模板(你也可以用 Markdown 写):
{
"slug": "incident-response",
"name": "线上故障响应 Playbook",
"persona": {"who": "后端/平台工程师", "stage": "已上线服务", "when": "出现 P0/P1 故障"},
"success": ["30 分钟内止血", "2 小时内给出初步 RCA", "24 小时内补齐复盘"],
"sections": [
{"phase": "诊断", "skills": ["triage-incident", "observability-basics"], "deliverables": ["故障时间线", "影响面评估"]},
{"phase": "止血", "skills": ["rollback-and-mitigation"], "deliverables": ["回滚/降级方案"]},
{"phase": "复盘", "skills": ["write-postmortem"], "deliverables": ["RCA + Action Items"]}
],
"anti_patterns": ["没有时间线就开始争论责任", "只修症状不补监控", "Action Items 没有 owner/截止时间"]
}
1.3.5)最后产品化:从数据库生成 SKILL.md,让它真的进入工作流
当你有了每个 skill 的 mentions 素材池,就可以生成 SKILL.md(或你现在用的 Skill 规范格式)。建议至少包含:
description+ 触发条件(什么时候用)Diagnostic Questions(先问后答)How to Help(输出结构与动作)Common Mistakes(护栏)Examples(至少 1 段可复用输出片段)References/Trace(能回到你的文章原文)
第二部分:86 skills 开源仓库怎么用(分类 + 示例 + playbook)
这一部分对应的是开源仓库内容本身(本地样例路径:/home/pyDeepSearch/write/sample/lenny-skills-main,GitHub 仓库:RefoundAI/lenny-skills)。
链接:
https://refoundai.com/lenny-skills/
2.1)仓库结构:一个 skill 就是一套可复用工作流
仓库的结构很克制:
skills/<skill-slug>/SKILL.md:技能本体(可被 Claude Code 识别/调用)skills/<skill-slug>/references/guest-insights.md:可选的引用素材(更长、更细的访谈摘录)
每个 SKILL.md 基本都包含:
name/description(尤其是Use when someone is...的触发条件)How to Help(你希望 AI 怎么帮你、输出怎么组织)Core Principles(方法论与引用)Questions to Help Users(诊断问题:先问后答)Common Mistakes to Flag(护栏:常见坑)
2.2)安装与调用:让它进入你的工作流
仓库 README 给了 3 种常见安装方式(这里按“离你最近的工作流”理解):
- CLI 安装(推荐):用
npx skills把 skills 下载安装到项目的.claude/skills/。 - Clone/Copy:直接把
skills/*复制到.claude/skills/。 - Submodule:把仓库当子模块引入,便于更新。
调用方式也很直接:
- 自然语言触发:你说“帮我写 PRD”,Claude Code 可能自动选择
writing-prds。 - 显式调用:直接输入
/writing-prds、/stakeholder-alignment这类命令。
2.3)86 个 skills 的分类概览(README 里的 9 大类)
README 把技能按 9 个工作流大类组织(每类列出代表技能;完整 86 个技能清单在 README 的 Available Skills 表格里):
| 分类 | 代表技能(部分) |
|---|---|
| Hiring & Team Building | evaluating-candidates、conducting-interviews、onboarding-new-hires、building-team-culture |
| User Research & Discovery | conducting-user-interviews、analyzing-user-feedback、usability-testing、designing-surveys |
| Strategy & Planning | writing-prds、prioritizing-roadmap、working-backwards、problem-definition |
| Shipping & Execution | shipping-products、scoping-cutting、managing-tech-debt、post-mortems-retrospectives |
| Leadership & Alignment | stakeholder-alignment、running-effective-1-1s、having-difficult-conversations、giving-presentations |
| Growth & Monetization | designing-growth-loops、retention-engagement、pricing-strategy、user-onboarding |
| Sales & Go-to-Market | founder-sales、enterprise-sales、launch-marketing、positioning-messaging |
| Career Development | building-a-promotion-case、career-transitions、negotiating-offers、finding-mentors-sponsors |
| AI & Technology | ai-product-strategy、building-with-llms、ai-evals、vibe-coding |
2.4)不同分类的 skills 示例:它能做什么、怎么用、需要什么材料
下面按分类各选 2–3 个代表技能,写清楚三件事:功能是什么、需要什么材料、怎么触发/调用。
Hiring & Team Building
| Skill | 功能是什么 | 你需要提供的材料 | 怎么用 |
|---|---|---|---|
evaluating-candidates |
做候选人决策与校准,避免纯直觉 | 岗位目标、面试反馈、作业/作品、reference 线索 | 输入“帮我评估候选人/对比 finalist”,或 /evaluating-candidates |
conducting-interviews |
设计面试结构与问题、提高信号密度 | 岗位画像、你担心的风险点、面试时间分配 | 输入“帮我设计面试题/面试流程”,或 /conducting-interviews |
User Research & Discovery
| Skill | 功能是什么 | 你需要提供的材料 | 怎么用 |
|---|---|---|---|
conducting-user-interviews |
把“访谈”变成可验证结论 | 目标用户、研究问题、访谈提纲、已有假设 | 输入“帮我做用户访谈/提纲/追问”,或 /conducting-user-interviews |
analyzing-user-feedback |
把反馈归因、聚类、转成行动项 | 反馈原文(工单/评论/访谈摘录)、产品版本与场景 | 输入“帮我分析用户反馈并给行动建议”,或 /analyzing-user-feedback |
Strategy & Planning
| Skill | 功能是什么 | 你需要提供的材料 | 怎么用 |
|---|---|---|---|
working-backwards |
用 PR/FAQ 逼清楚价值与可行性 | 目标用户、要解决的问题、候选方案、约束 | 输入“帮我用 working backwards 写 PR/FAQ”,或 /working-backwards |
writing-prds |
把需求写成能推动团队行动的 PRD | 问题定义、成功指标、范围边界、依赖与风险 | 输入“帮我写 PRD/补全大纲”,或 /writing-prds |
Shipping & Execution
| Skill | 功能是什么 | 你需要提供的材料 | 怎么用 |
|---|---|---|---|
scoping-cutting |
在不确定下砍范围、保住交付 | 目标、必须/可选清单、时间窗口、风险 | 输入“帮我砍 scope/做 MVP 方案”,或 /scoping-cutting |
post-mortems-retrospectives |
复盘事故/延误并形成改进闭环 | 时间线、影响面、决策点、日志/证据 | 输入“帮我做复盘/形成 action items”,或 /post-mortems-retrospectives |
Leadership & Alignment
| Skill | 功能是什么 | 你需要提供的材料 | 怎么用 |
|---|---|---|---|
stakeholder-alignment |
做预对齐、准备反对意见、拿到 buy-in | 利益相关方名单、决策点、主要阻力 | 输入“帮我做 stakeholder 对齐/准备提案”,或 /stakeholder-alignment |
running-effective-1-1s |
把 1:1 变成管理与对齐工具 | 你和对方的目标/痛点、近期事件 | 输入“帮我准备 1:1 议程/跟进”,或 /running-effective-1-1s |
Growth & Monetization
| Skill | 功能是什么 | 你需要提供的材料 | 怎么用 |
|---|---|---|---|
pricing-strategy |
定价与包装的框架化讨论 | 用户分层、价值主张、竞品价格、成本结构 | 输入“帮我做定价策略/包装方案”,或 /pricing-strategy |
retention-engagement |
围绕留存做诊断与实验 | 漏斗数据、关键行为定义、分群 | 输入“帮我提升留存/设计实验”,或 /retention-engagement |
Sales & Go-to-Market
| Skill | 功能是什么 | 你需要提供的材料 | 怎么用 |
|---|---|---|---|
positioning-messaging |
把“我们是谁”讲清楚并落到文案 | 目标客户、竞品、差异化证据、典型用例 | 输入“帮我做定位/一句话价值主张”,或 /positioning-messaging |
launch-marketing |
计划发布节奏与资源 | 发布时间点、渠道、目标人群、指标 | 输入“帮我做发布计划/launch checklist”,或 /launch-marketing |
Career Development
| Skill | 功能是什么 | 你需要提供的材料 | 怎么用 |
|---|---|---|---|
building-a-promotion-case |
把影响力与成果结构化成晋升材料 | 项目清单、影响指标、反馈证据 | 输入“帮我写晋升材料/impact narrative”,或 /building-a-promotion-case |
negotiating-offers |
谈 offer 时的策略与护栏 | 当前 offer 条款、目标区间、备选方案 | 输入“帮我谈薪/谈 offer”,或 /negotiating-offers |
AI & Technology
| Skill | 功能是什么 | 你需要提供的材料 | 怎么用 |
|---|---|---|---|
ai-product-strategy |
定义 AI 机会点与边界,避免“为了 AI 而 AI” | 目标用户与痛点、现有流程、失败容忍度、数据来源 | 输入“帮我做 AI 产品策略/路线图”,或 /ai-product-strategy |
building-with-llms |
落地 LLM 应用:prompt、RAG、架构、评估 | 用例、示例输入输出、现有失败样本、可用上下文 | 输入“帮我改 prompt/RAG/输出质量”,或 /building-with-llms |
ai-evals |
把“质量”变成可运行的评估 | golden cases、评分标准、失败模式样本 | 输入“帮我设计 eval/rubric/test cases”,或 /ai-evals |
2.5)一个完整 playbook:用 skills 做“AI 导购”从 0 到 1
用一个你前面提到的场景:电商 App 做 AI 导购。下面是一个“可照着走”的 playbook(模拟)。
目标:两周内做出可内测的 AI 导购 MVP,并用 evals 控质量。
- 定义问题(避免伪需求)
- 用的 skill:
problem-definition+ai-product-strategy - 你要给的材料:目标用户(新客/老客)、当前链路(搜索/推荐/客服)、3 个最高频问题、可接受的失败上限
- 你会得到:问题陈述、成功指标、human-AI 边界、首发场景建议
- 示例调用:
/ai-product-strategy然后贴上“用户痛点 + 现有链路 + 成功指标草案”
- 用的 skill:
- 写 PRD(让团队能开干)
- 用的 skill:
writing-prds+working-backwards - 你要给的材料:Why now、Success metrics、out of scope、依赖(数据/端上/法务)
- 你会得到:PRD 大纲、待决策清单、风险与护栏、原型优先建议
- 用的 skill:
- 设计方案(先跑通工作流再优化)
- 用的 skill:
building-with-llms - 你要给的材料:10–20 条真实对话用例、期望回复、失败案例(幻觉/胡编/不合规)
- 你会得到:prompt 结构、few-shot 示例、RAG/上下文工程建议、失败重试与分解策略
- 用的 skill:
- 把 PRD 变成 eval(让质量可控)
- 用的 skill:
ai-evals - 你要给的材料:golden set(用例集)、pass/fail 标准、rubric、LLM-as-judge 校验思路
- 你会得到:评估维度、测试集结构、迭代节奏(先人工 review→再自动化)
- 用的 skill:
- 拿到 buy-in 并对齐节奏
- 用的 skill:
stakeholder-alignment+scoping-cutting - 你要给的材料:stakeholder 名单、主要反对点、时间/资源约束
- 你会得到:预对齐策略、备选方案与 trade-offs、MVP 砍法
- 用的 skill:
- 上线后复盘形成闭环
- 用的 skill:
post-mortems-retrospectives+analyzing-user-feedback - 你要给的材料:日志与对话样本、投诉/差评、指标波动
- 你会得到:时间线、根因假设、action items、下一轮 taxonomy(新增/调整 skills)
- 用的 skill:
2.6)快速演示:加载“技能包”前后的巨大差异
为了展示它的威力,我们来做两个直观的对比演示。
场景一:写一份 PRD(产品需求文档)
测试题目:“我要为一个电商 App 做一个 AI 导购功能,请帮我写一份 PRD 大纲。”
❌ 未加载技能包(普通模式)
AI 通常会列出一个标准的模板:
- 项目背景
- 功能需求(对话框、推荐算法…)
- 数据埋点
- UI/UX 设计
(评价:中规中矩,像个执行层员工写的。)
✅ 加载 writing-prds 技能包后
AI 会立即引用 Amazon 的 “Working Backwards” 理念和 Maggie Crowley 的原则,反过来“逼问”你:
AI 顾问:在开始写功能列表之前,我们需要先明确几个核心问题(引用自 Skill):
- Why Now? 为什么是现在做?如果不做会有什么后果?(帮你过滤伪需求)
- Success Criteria:不要只写“提升体验”,请定义具体的成功指标。
- Demos before Memos:对于 AI 功能,写文档不如做原型。建议先用 Prompt 跑通几个 Case。
下面是一段你可以直接复用的示例输出片段(节选),用来感受“先诊断、后给大纲”的风格(不依赖某个具体模型版本):
AI 顾问:我会先问 5 个问题,再给 PRD 大纲。
- 你的 AI 导购主要解决哪类用户的哪种决策?(找货 / 比价 / 搭配 / 售后)
- 你希望它提升的首要指标是什么?(转化率、客单价、退货率、客服成本)
- 你能接受的“错误率/幻觉”上限是多少?兜底策略是什么?
- 现有推荐/搜索链路的输入信号有哪些?(浏览、加购、收藏、尺码、偏好)
- 首版必须覆盖的 3 个高频场景是什么?
AI 顾问:在你回答前,我先给一个 PRD 大纲骨架(你答完我会把每节补全):
- 背景与 Why Now(明确不做的代价)
- 目标与成功指标(3 个可量化指标 + 1 个 guardrail)
- 用户与场景(Top 3 场景 + 失败场景)
- 方案概述(对话流 + 置信度/引用依据展示)
- 风险与护栏(幻觉、偏置、合规;人工兜底/可撤销)
- 试点与迭代(原型优先:先跑 20 条对话用例)
(评价:这才是 Senior PM 的思维。它不仅帮你写文档,更是在帮你梳理战略。)
场景二:制定 AI 产品策略
测试题目:“老板想在 App 里加个 AI,怎么规划?”
✅ 加载 ai-product-strategy 技能包后
AI 会引用 Aishwarya Naresh Reganti 的金句 “Start with the problem, not the AI”,并警告你避开 “AI for AI’s sake”(为了 AI 而 AI)的陷阱。
它会建议你:
- Design for squishiness:AI 一定会犯错,你的 UI 流程里设计好“容错机制”了吗?
- Flywheels beat first-mover:不要抢首发,要设计数据飞轮。
同样给一段示例输出片段(节选),你会看到它更像“战略顾问 + 评审官”,而不是功能许愿机:
AI 顾问:先把“加个 AI”翻译成业务问题。我需要你给 3 个输入:
- 目标用户是谁?他现在卡在哪一步?
- 你们的北极星指标是什么?这次要推动哪条因果链?
- 你们现有的数据/内容/工作流里,哪一块最适合形成飞轮?
AI 顾问:在信息不足的情况下,我给一个策略框架(你补完信息我会落到路线图):
- 选 1 个“高频 + 可控”场景做首发(避免全链路 AI)
- 设计容错:引用来源、置信度、可撤销、人工兜底
- 设计飞轮:用户交互 → 数据回流 → 质量提升 → 使用率提升
- 设 guardrails:成本上限、错误上限、合规边界
2.7)SKILL.md 是怎么“编程” AI 的?(结构化提示的固定模块)
作为技术博主,我们必须看看它的源码(Markdown 文件)。你可以把它理解成把“技能数据库”产品化成 Agent Skill 文件的方式:用一套稳定的结构,把引用、方法论和动作清单封装成可重复调用的提示。
- How to Help:明确定义 AI 的角色边界。(“你是一个严格的导师,而不是只会点头的助手”)
- Core Principles:这是灵魂。它把非结构化的访谈金句整理成可执行的启发式清单 / 评审标准(Heuristics),让模型有一致的判断框架。
- Common Mistakes:这是护栏。它列出了新手常犯的错误,让 AI 主动进行负面约束检查。
## Common Mistakes to Flag
- **Only negotiating salary** - The resources... are often more valuable...
- **Starting with the solution** - The document should lead with the problem...
2.8)怎么用:从安装到调用(按 README)
你不需要安装 Python,也不需要 Docker。你只需要把 skills 放进你的工作目录(常见是 .claude/skills/)。
- 安装(推荐):用
npx skills add RefoundAI/lenny-skills安装全部 skills。 - 安装(按需):只装你要的,比如
--skill evaluating-candidates writing-prds。 - 调用:
- 自然语言:比如“帮我写 PRD / 评估候选人 / 对齐 stakeholder”。
- 显式命令:比如
/writing-prds、/stakeholder-alignment。
- 在其它工具里用(非 Claude Code 也能借鉴):
- Cursor/VS Code:把
SKILL.md加入上下文(@File)再提问。 - Claude/ChatGPT 网页版:直接粘贴
SKILL.md(更适合临时使用)。
- Cursor/VS Code:把
关键细节:怎么控制上下文长度、只投喂最相关的 skill?
大多数人用不好,并不是 skill 不行,而是“上下文太杂 / 太长”。给你一套简单可复用的规则:
- 一次只带 1–3 个 skill:优先带“最接近问题类型”的那个,其次带一个补充视角(比如
writing-prds+ai-product-strategy)。 - 先问诊再投喂:如果你不确定选哪个 skill,先让 AI 用一句话复述你的目标 + 给 3 个澄清问题;你根据回答再决定带哪个 skill(避免一上来塞一堆)。
- 只带“可执行段落”:如果
SKILL.md很长,先复制粘贴How to Help、Diagnostic Questions、Common Mistakes这三块;这三块通常对输出质量提升最大。 - 做“预摘要”再带全文:当你必须带很多材料时,先让 AI 生成一个 10–15 条的要点摘要(保留术语与关键约束),下一轮只带摘要再推进。
- 按任务拆轮次:不要试图“一次生成完整 PRD”。先用 skill 产出“问题定义 + 成功指标 + 风险护栏”,再单独开一轮写功能与埋点。
总结与链接
lenny-skills 这个项目给我们的启示是:在 AI 时代,优质的知识整理(Curated Knowledge)比代码更值钱。
如果你是产品经理,这是你的外挂;如果你是开发者,这是你学习 Prompt Engineering 的最佳范本。
建议大家 Star 这个项目,并尝试 Fork 一份,建立属于你自己的“技能库”。
参考文献与链接:

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)