
Skills
Skills 是一套「让模型在合适的时候,临时学会一项新能力」的机制。合适的时候: 精准触发,不浪费计算资源与上下文空间。临时:按需调用,任务结束后不长期占用模型注意力。新能力:突破模型原生限制,实现如 PDF 解析、代码执行等扩展功能。“裸模型”无法胜任复杂任务模型天生只会“理解和生成文本”,并不具备解析复杂结构(如 PDF、 Excel)的内置能力。面对“总结 PDF 第二页”等任务,模型常因
1 什么是 Skills
Skills 是一套「让模型在合适的时候,临时学会一项新能力」的机制。
- 合适的时候: 精准触发,不浪费计算资源与上下文空间。
- 临时:按需调用,任务结束后不长期占用模型注意力。
- 新能力:突破模型原生限制,实现如 PDF 解析、代码执行等扩展功能。
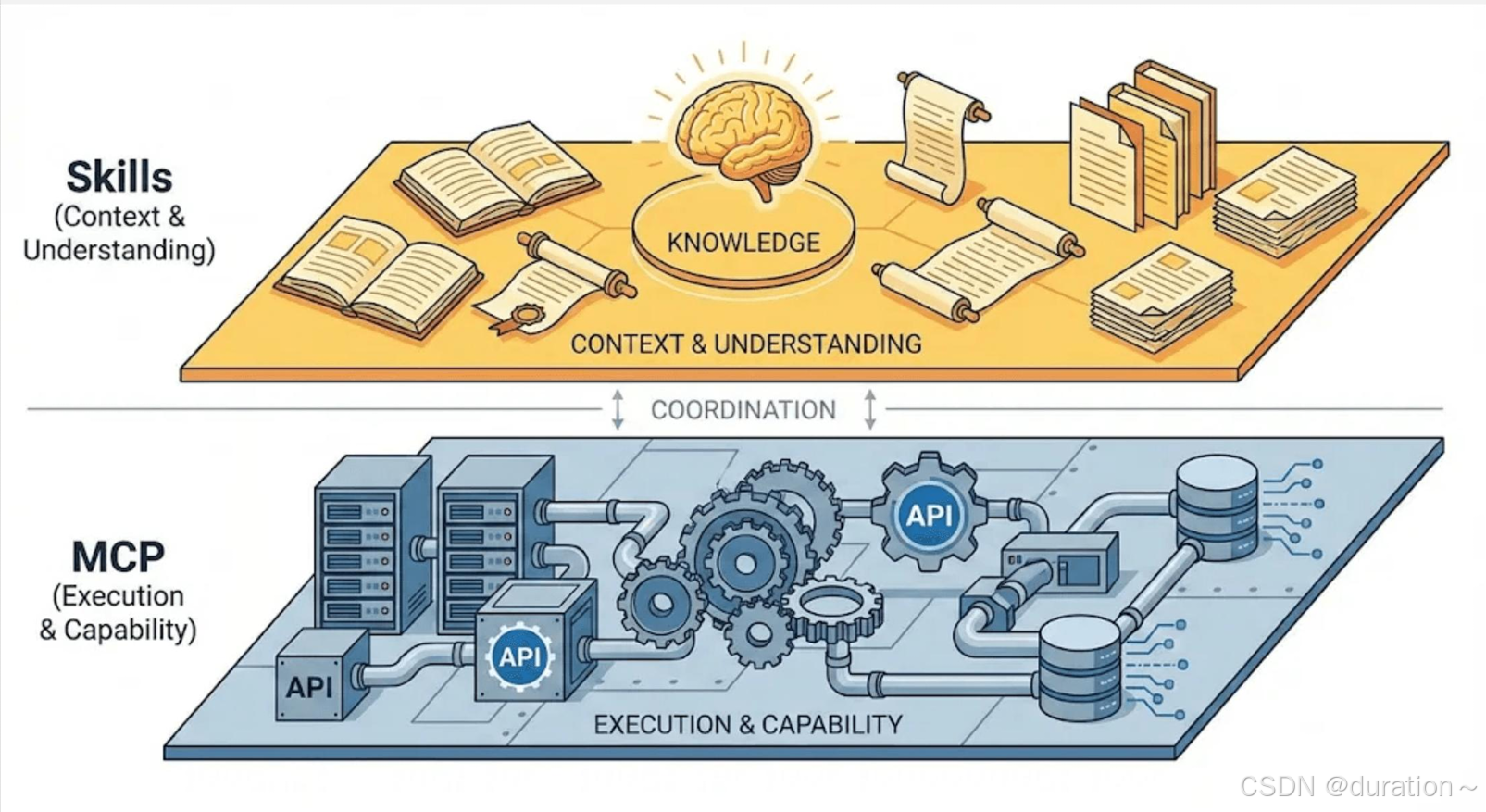
“裸模型”无法胜任复杂任务
模型天生只会“理解和生成文本”,并不具备解析复杂结构(如 PDF、 Excel)的内置能力。
面对“总结 PDF 第二页”等任务,模型常因缺乏工具而回答“我做不到”。
在此之前的解决方法常见为如下三种:
- 硬塞 Prompt 规则:导致上下文过长,注意力稀释,成本飙升。
- 外部代码喂数据:流程繁琐,难以实现真正的自动化与实时交互。
- 全量工具协议 (MCP) :无论是否使用,全量加载规则,导致高延迟与高成本。
从 Prompt 到“按需加载”的进化:
核心创新:将「能力说明」从 Prompt 中彻底拆分:
- 模型可见层:仅包含 Skill 名称与描述。模型平时只知道“我有这项能力”,用于判断何时触发。
- 默认隐藏层:包含具体执行规则、调用方式与细节。只有在任务命中时,才会动态加载到上下文中。
- 进化优势:极大节省 Token 消耗,降低成本,同时避免模型注意力被无关规则稀释。
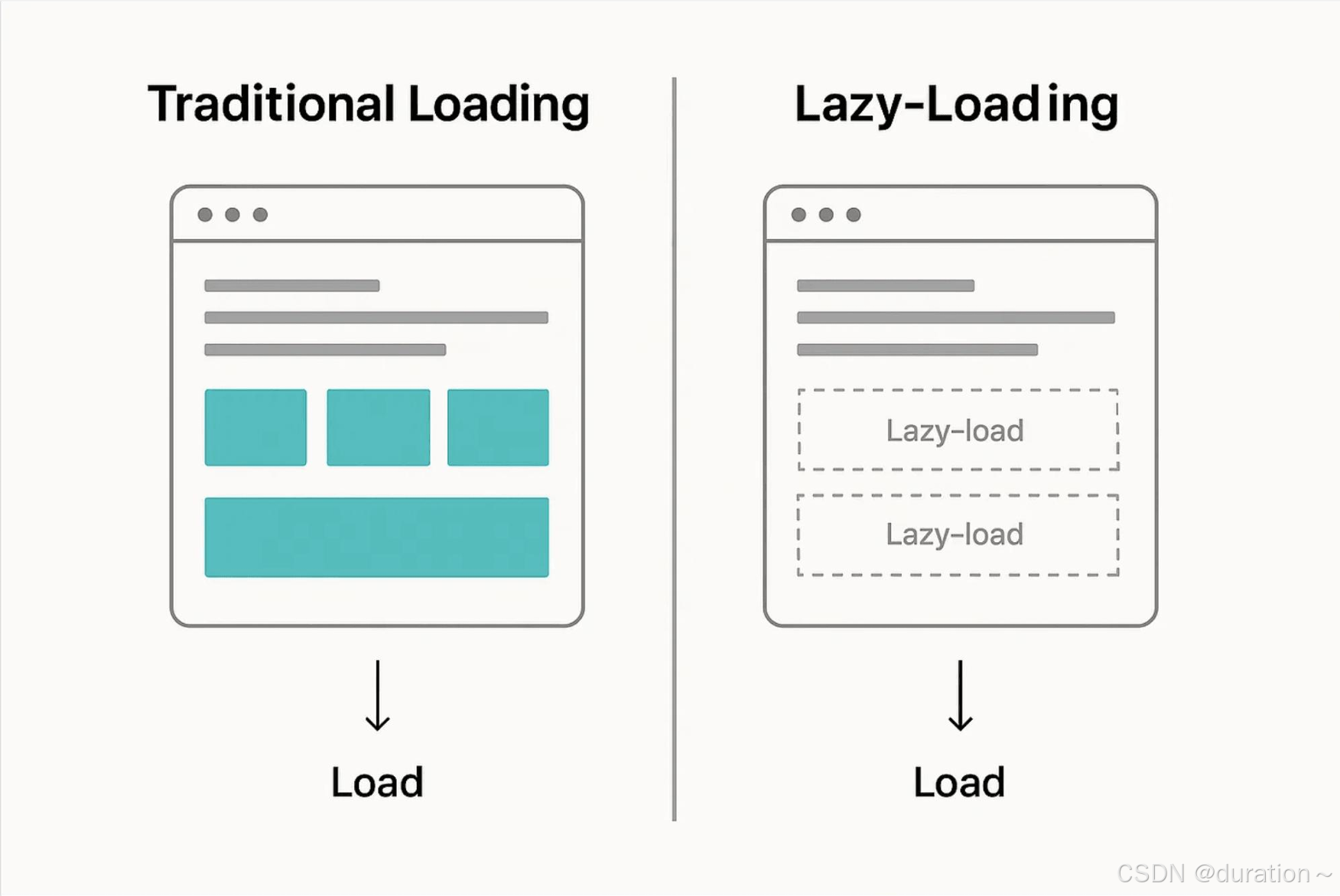
像人类一样:用时才翻说明书。
Skills 采用按需加载(Lazy Load)机制,优化资源占用。
2 Skills 与 MCP
Skills 与 MCP 对比:
- Skills 模式:脑子里“知道有这项技能”,但只有在用的时候,才去翻说明书。
- MCP 模式:每次做事前,先把所有说明书通通摊在桌子上。
Skills 采用渐进式披露(Progressive Disclosure),将复杂度藏在幕后,仅在关键决策点呈现必要信息。
MCP 采用全量暴露策略,依赖模型自身的注意力机制去处理海量规则, 对模型“智商”要求极高。
核心差异:工程思维 vs 协议思维
Skills 关注如何降低模型负担,MCP 关注如何统一接口标准。
加载方式与决策逻辑的降维打击、无限扩展性与工程思维的胜利:
| 分类 | Skills (按需加载) | MCP (全量协议) |
|---|---|---|
| 加载方式 | 只加载“名字 + 描述”,真正用到时才加载执行细节。极大节省上下文空间,降低 Token 成本。 | 每次对话都全量加载所有工具规则。不管用不用,规则始终占据上下文,导致成本线性上涨。 |
| 决策逻辑 | 模型先判断“要不要用”,再决定“用哪一个”。体现了更高级的智能体自主决策特征。 | 工具集强行摆在模型面前。模型只能在已有规则里被动选择,更像是一个传统的“工具箱”。 |
| 可扩展性对比 | 支持无限添加 Skill,模型仅在需要时加载,不会显著拖慢对话速度或增加系统延迟,适合构建复杂的大型 AI 系统。 | 工具数量与成本、延迟呈线性正相关。工具一多,上下文即刻爆炸,难以支撑大规模工业级应用。 |
| 设计哲学差异 | 体现了现代软件工程的模块化思维。将复杂度藏在幕后,仅在关键时刻呈现,让模型注意力始终保持高效聚焦。 | 倾向于一次性暴露所有规则,过度依赖模型自身的处理能力来应对复杂度,缺乏工程上的优雅与灵活性。 |
| 结论 | 更省钱、更高效 | 更像“智能体“ |
3 OpenCode使用skill
安装 OpenCode 需要 Node.js 环境,是运行的基础。
安装命令:
npm install -g opencode-ai
启动:
opencode
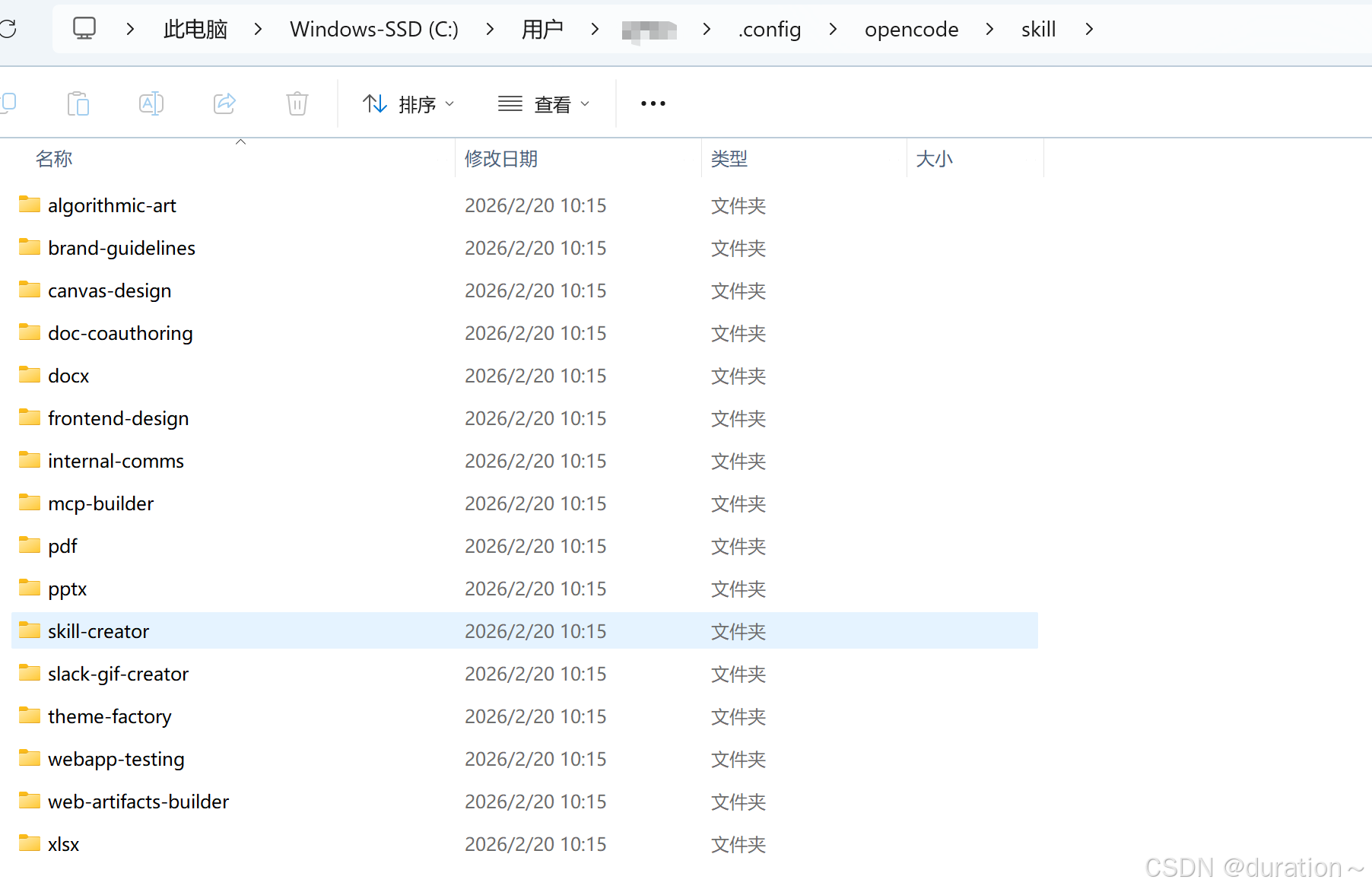
添加官方 skill,GitHub 地址:https://github.com/anthropics/skills。
下载后,在 C:\Users\用户名\.config\opencode\skill 目录下添加所有官方的 skills。
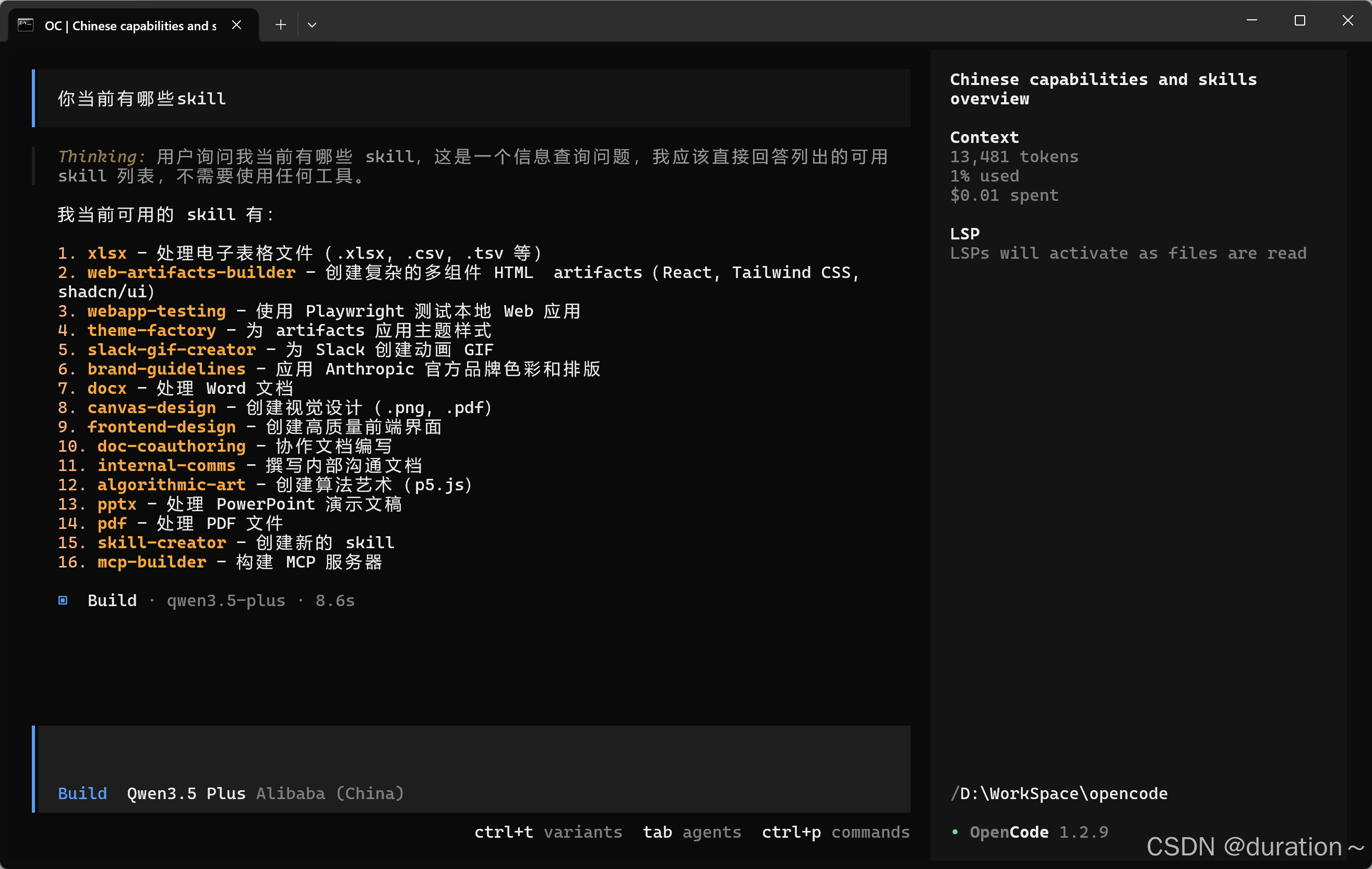
测试
调用 pdf 工具读取 pdf 内容,还可以自己解决读取中出现的乱码等问题(需要先安装python解释器):
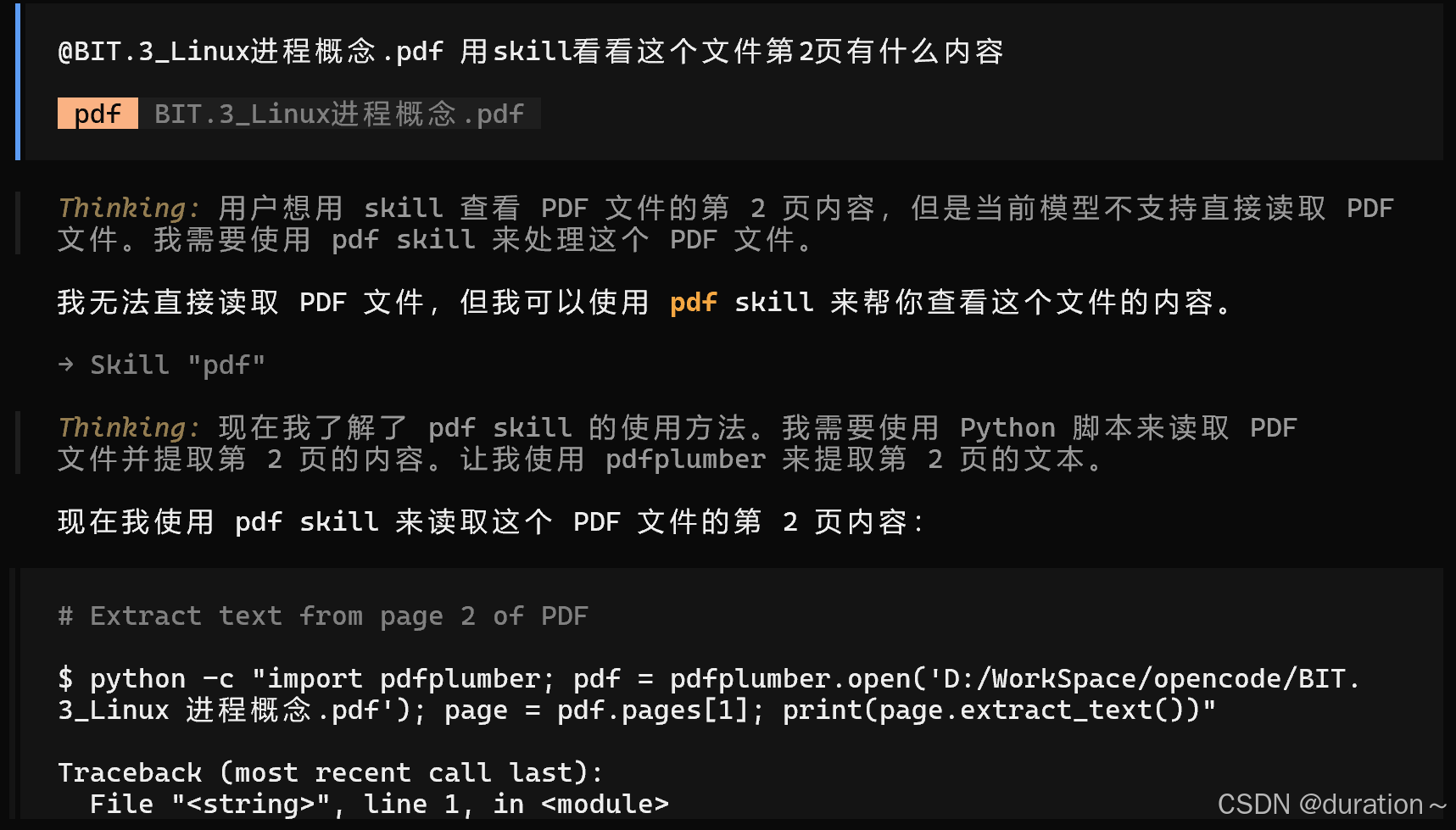
内容如下:

4 Skill规则
首先介绍一下一个标准的 skill 规范。
根据 anthropic 官方描述:一个 skill 就是一个标准的目录结构,必须包含 SKILL.md,格式如下:
your-skill-name/
├── SKILL.md # 必填,主要技能文件
├── scripts/ # 可选,可执行代码
│ ├── process_data.py # 示例
│ └── validate.sh # 示例
├── references/ # 可选,agent 可查阅的文档资料
│ ├── api-guide.md # 示例
│ └── examples/ # 示例
└── assets/ # 可先,相关静态资源文件,图片、文档等
└── report-template.md # 示例
skill 文件夹命名规则:
- 不能有大小写:YourSkillName;
- 不能有空格:your skill name;
- 不能有下划线: your_skill_name;
- 使用驼峰命名法:your-skill-name;
不能存在 README.md 在文件夹下,所有的文献都应该在 references 目录下。
SKILL.md 格式规范:文件 SKILL.md 必须包含 YAML 前置元数据,后置 Markdown 格式的说明内容。
示例:
---
name: skill-name
description: This skill should be used when...
license: Apache-2.0
metadata:
author: example-org
version: "1.0"
allowed-tools: Bash(git:*) Bash(jq:*) Read
---
# 技能名称
正文:功能说明、使用方法、可用资源列表等。
前置元数据内容解释
| 名称 | 是否必需 | 约束条件 |
|---|---|---|
| name | 是 | 最多64个字符,要与 skill 文件夹名称一致。仅限小写字母、数字和连字符。不得以连字符开头或结尾。 |
| description | 是 | 最多 1024 个字符,不然会被截断。 描述技能的效果以及何时使用。 |
| license | 不 | 许可证名称或捆绑许可证文件的引用。 |
| compatibility | 不 | 最多 500 个字符。说明环境要求(目标产品、系统软件包、网络访问等)。 |
| metadata | 不 | 任意键值映射,用于添加元数据。 |
| allowed-tools | 不 | 技能可使用的预先批准工具列表,以空格分隔。(实验性功能,不同 agent 规则可能不同) |
MD 说明部分推荐章节:
- 分步说明
- 输入和输出示例
- 常见边界情况
由于 agent 会在决定激活技能时加载整个文件,因此建议将较长的 SKILL.md 内容拆分成多个引用文件。
文件引用使用相对于技能根目录的相对路径,如 See
[the reference guide](references/REFERENCE.md)for details.
5 OpenCode自定义skill
自定义 Skill 实现 SQL 助手的功能。
首先,在 C:\Users\用户名\.config\opencode\skill 目录下创建 sql-query-helper\Skill.md 目录及文件。
内容如下:
---
name: sql-query-helper
description: |
Help write and optimize SQL queries for the company database.
Use when Claude needs to query the production database or
help with SQL query optimization.
---
# SQL Query Helper
## Database Schema
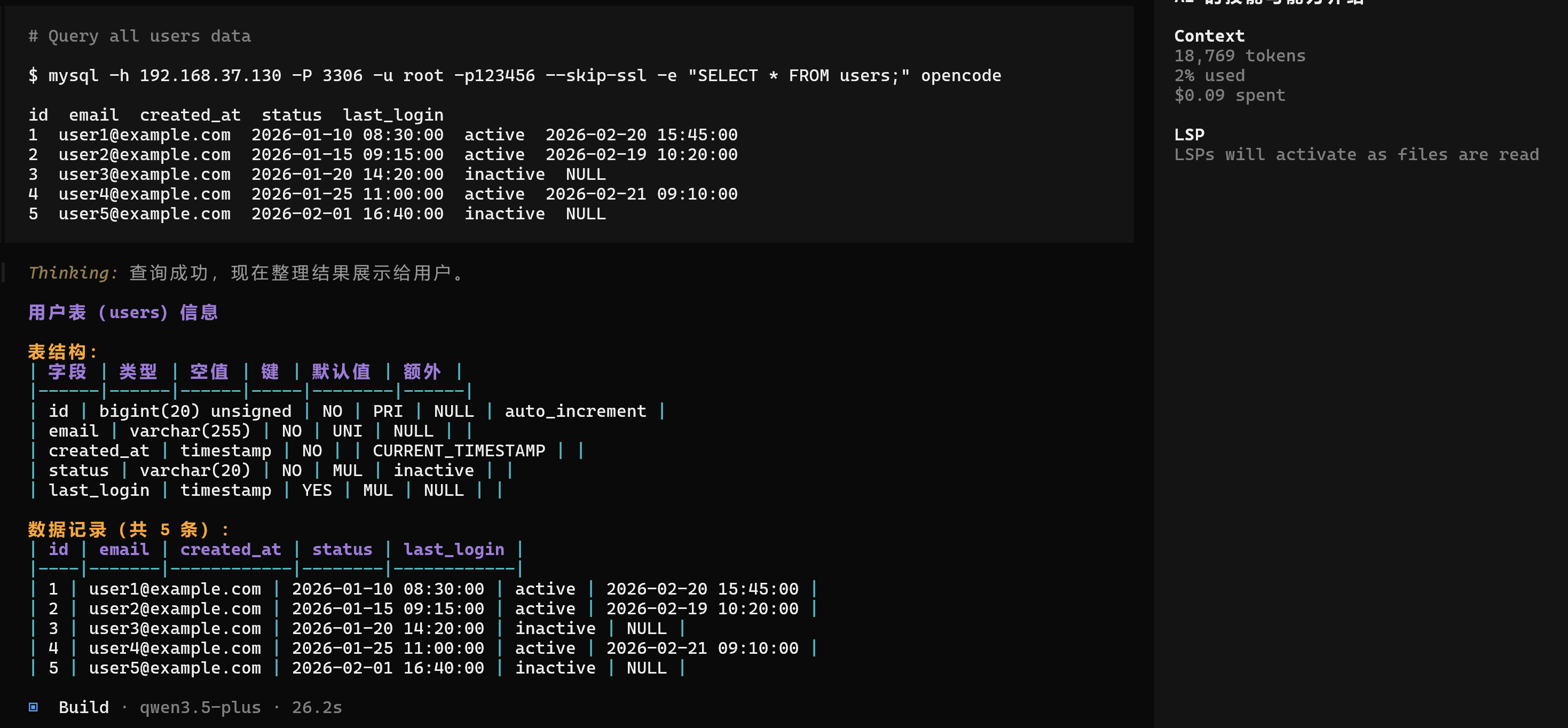
Our main tables:
- `users` (id, email, created_at, status)
- `orders` (id, user_id, amount, created_at, status)
- `products` (id, name, price, category)
## Query Guidelines
1. Always use parameterized queries
2. Include LIMIT clauses for safety
3. Use indexes on WHERE clauses
4. Test queries in staging first
## Common Queries
### Active Users
```sql
SELECT id, email, last_login
FROM users
WHERE status = 'active'
ORDER BY last_login DESC
LIMIT 100;
```
### Revenue by Month
```sql
SELECT
DATE_TRUNC('month', created_at) as month,
SUM(amount) as revenue
FROM orders
WHERE status = 'completed'
GROUP BY month
ORDER BY month DESC;
```
## Note
If you encounter a TLS/SSL error, please use `--skip-ssl` to skip the verification.
用
---分割 skill 描述部分和细节部分,细节部分给出对应的资源配置。
在 opencode 的工作目录下创建 .env 指定 MySQL 连接配置:
DB_HOST:"192.168.37.130"
DB_PORT:3306
DB_NAME:"opencode"
DB_USER:"root"
DB_PASSWORD:"123456"
测试
5 Agent 开发skill
Skills 目前只有 anthropic 支持,但是对于 Agent 开发来说只要知晓了它实现的原理,也可以自己去实现。
首先,Agent 应用会将 Skill 元数据的每一个作用发送给大模型。
之后,比如当用户要进行网络搜索,去百度中搜索最新论文信息,那么它就会进行推理,看哪一个 Skill 能够进行处理。
同样的,LLM-Core 会返回一段交互信息,代表 Agent 需要调用 callSkills("skill-name"),callSkills 就会根据 Skill 的名称来决定读取哪一个文件夹中的 Markdown 文件。
然后 Agent 应用就会把对应的 Skill 的 Markdown 再发给大模型,大模型再进行推理,通知 Agent 应用要调用哪一个 Tool 方法来进行处理网络搜索。
callSkills 其实依然沿用的 Function Call,也就是在应用中会有一个叫做 callSkills 这样的一个 Tool 方法。
由于 Skill 不必像 Workflow Agent 一样将所有的工作流程发送给大模型,只需要发送对应的 Markdown 指令信息即可,所以 Skill 也叫做 Sub-Agent。
Skill 仅仅是大的智能体当中的一环,并且 Skill 也非常方便传输、共享。
重点:Skill 依然的是沿用 Function Call 这一套,只不过它内部提供了一个内置的 Function Call 来去读取对应的 Skill 文本,然后再返回大模型让它进行推理,执行下一步操作。
所以,也必须要由支持 Function Call 的大模型才能去支持 Skill。
这套逻辑是 Claude 提出来的,所以只有 Claude 才支持。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)