
LangChain DeepAgents 完全指南:从源码到自定义 SkillsMiddleware
本文深入剖析 LangChain DeepAgents 的 Skills 加载机制,从源码层面解析 create_deep_agent、SkillsMiddleware、_list_skills 等核心组件的工作原理。通过完整的时序图和流程图,展示从目录扫描、YAML 解析到系统提示词注入的完整链路。针对开发中常见的全局变量污染、Windows 路径兼容性等痛点问题,提供三种渐进式优化方案:闭包消
一、简介
翻了一圈,官网都没有详细介绍create_deep_agent中skils参数具体该怎么用
本文将使用langchain中间件完成skills,一个个人信息查询工具,以及HTML文件助手SKILS

官方API https://reference.langchain.com/python/deepagents/graph/#deepagents.graph.create_deep_agent
❤本系列文章,配套项目源码地址❤
https://github.com/wenwenc9/langgraph-tutorial-wenwenc9

Langgraph系列文章
01|Langgraph | 从入门到实战 | 基础篇
02|Langgraph | 从入门到实战 | workflow与Agent
03|Langgraph | 从入门到实战 | 进阶篇 | 持久化
04|Langgraph | 从入门到实战 | 进阶篇 | 流式传输
05|Langgraph | 从入门到实战 | 进阶篇 | 中断interrupt
langchain的系列文章(相信我把Langchain全部学一遍,你能深入理解AI的开发)
01|LangChain | 从入门到实战-介绍
02|LangChain | 从入门到实战 -六大组件之Models IO
03|LangChain | 从入门到实战 -六大组件之Retrival
04|LangChain | 从入门到实战 -六大组件之Chain
05|LangChain | 从入门到实战 -六大组件之Memory
06|LangChain | 从入门到实战 -六大组件之Agent
二、概要
本文挑选官方文档部分内容讲解,详细内容见官网
https://docs.langchain.com/oss/python/deepagents/overview
1.1 什么是 Deep Agents?
Deep Agents(深度智能体) 是专门设计用于处理复杂、耗时任务的智能体系统。
典型特征:
- 📊 任务长度约每七个月翻倍
- 🔧 平均包含 50+ 次不同工具调用
- ⏱️ 执行时间可能达到数小时甚至数天
典型案例:
Claude Code:代码生成和重构Deep Research:深度研究报告Manus:复杂任务自动化
1.2 DeepAgents 核心工具特点
设计理念:
- 少量原子工具 + 复杂提示词:不依赖大量不同工具,而是聚焦几个高效的"原子工具"
- 充分利用文件系统:分担语言模型上下文窗口压力
- 子代理委托:处理 token 密集型任务并隔离上下文
1.3 DeepAgents 与其他框架的关系
层级关系:
- LangGraph:底层运行时环境
- LangChain:通用抽象层
- DeepAgents:倾向性智能体框架
1.4 何时使用 Deep Agents?
✅ 适用场景:
- 处理复杂的多步骤任务,需要规划和分解
- 通过文件系统工具管理大量上下文
- 委托工作给专门的子代理,用于隔离上下文
- 需要持久内存,会跨对话和线程
❌ 不适用场景:
- 简单的单次对话
- 轻量级问答任务
- 实时响应要求极高的场景
💡 提示:简单的 Agent 建议使用 LangChain Agents
三、环境安装
2.1 安装依赖
from dotenv import load_dotenv, find_dotenv
import os
# 自动向上查找 .env 文件
load_dotenv(find_dotenv())
modelName = os.getenv('OPENAI_MODEL')
TAVILY_API_KEY = os.getenv('TAVILY_API_KEY')
# 安装核心依赖
uv add deepagents tavily-python
uv add deepagents-cli
2.2 注册 API Key
- Tavily API:官方地址

- OpenAI API:配置在
.env文件中
四、快速开始
3.1 创建第一个 Deep Agent
改自官方文档案例:https://docs.langchain.com/oss/python/deepagents/quickstart
这个案例需要tavily 这个网络检索工具
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
from langchain_openai import ChatOpenAI
# 初始化 Tavily 客户端
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
# 创建网络检索工具
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""执行网络搜索"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
# 系统提示词
research_instructions = """你是一位专业的研究者。你的工作是进行全面的研究,然后撰写一份精致的报告。
你可以使用互联网搜索工具作为主要获取信息的手段。
## `internet_search`
使用此工具根据给定查询进行互联网搜索。你可以指定要返回的最大结果数量、主题以及是否包含原始内容。
"""
# 创建 LLM
llm = ChatOpenAI(model=modelName)
# 创建 Deep Agent
agent = create_deep_agent(
model=llm,
tools=[internet_search],
system_prompt=research_instructions
)
3.2 执行任务
result = agent.invoke({
"messages": [{
"role": "user",
"content": "上海到洛杉矶运输一批服装20gp物流运输解决报告"
}]
})
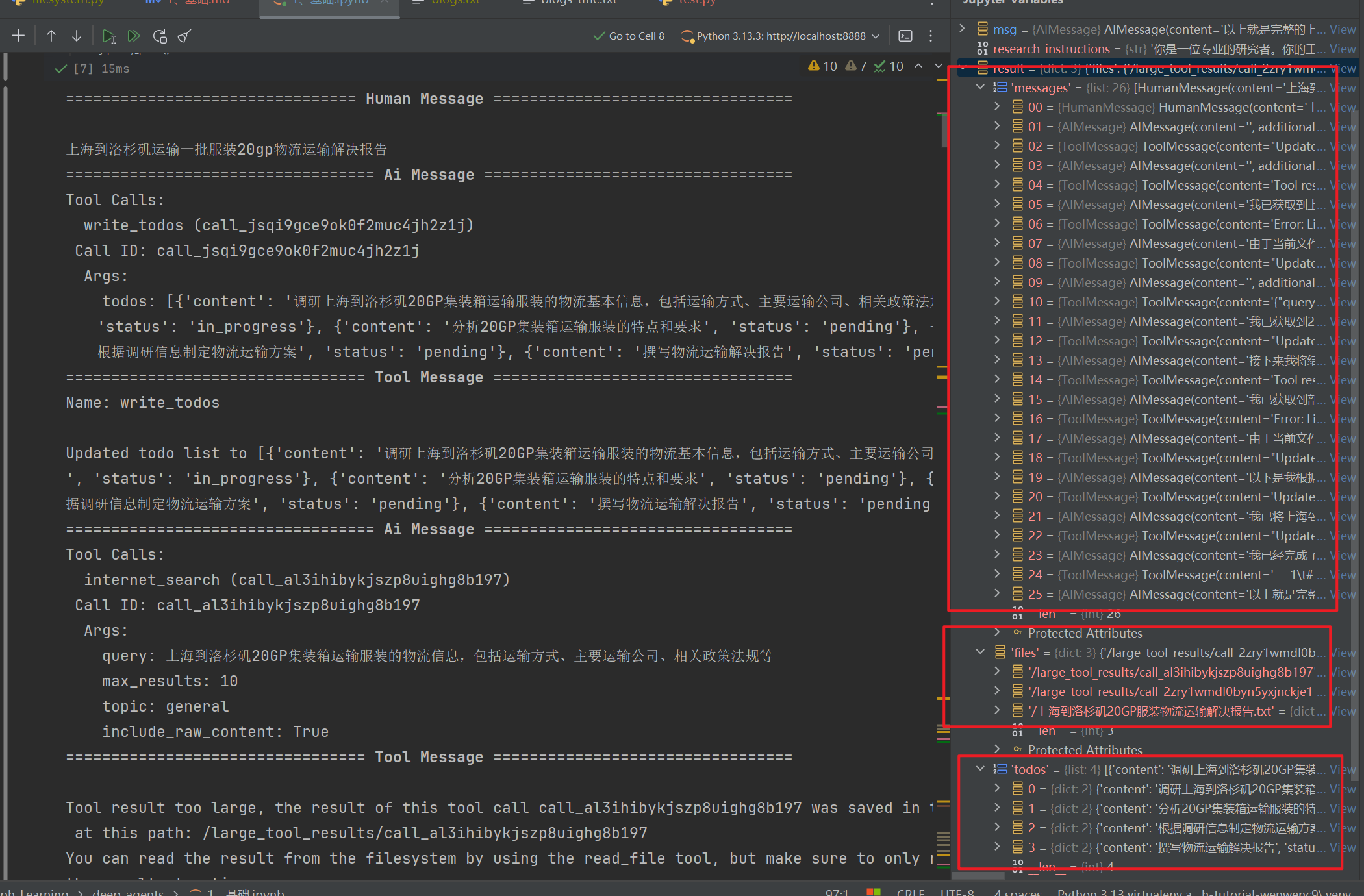
for msg in result["messages"]:
if hasattr(msg, 'pretty_print'):
msg.pretty_print()
我们查看堆栈内容
messages一个用户问题进来 ,AI自我多轮调用的信息载体files生成系列文件的指引todos工作待办内容
由于控制台内容过多,自行到我代码仓库查看,这个任务很好的解决了深度研究的问题,实现的效果内容还挺不错的
这个过程,并且调用了内置的工具,比如write_todos、write_todos、read_file、write_file
以及tavily 的网络搜索工具 internet_search
而我们本地目录并没有写入文件,这是怎么因为没有启用backends的参数,后面会提到
https://docs.langchain.com/oss/python/deepagents/backends

工作流程:
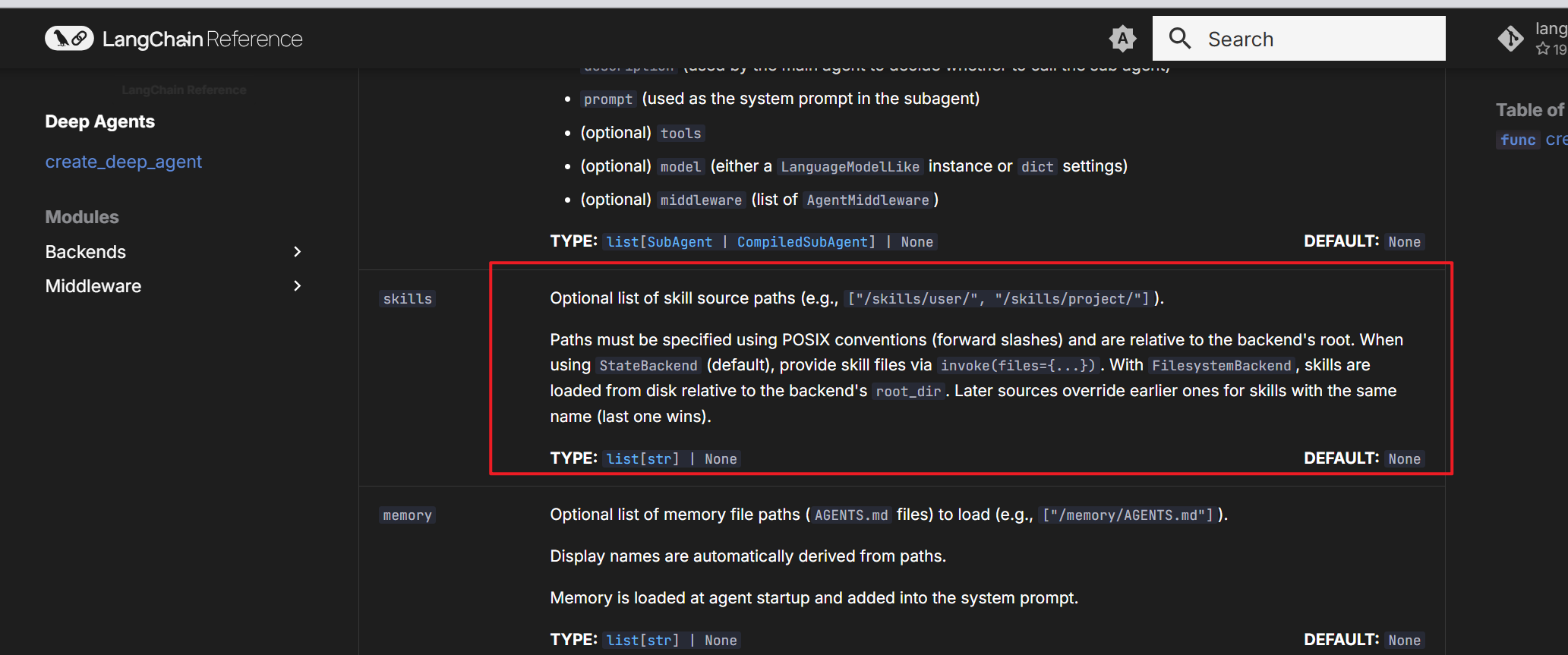
五、skills
关于skills,可以阅读下面资料
想要学习如何开发skills
我当前 deepAgents 版本是 0.3.6 版本
1、创建一个深度代理
使用方法create_deep_agent
1.1 定义一个查询个人信息工具
import os
import uuid
def query_personal_infos(name: str) -> dict:
"""
通过姓名查询个人资料工具
:param name: 姓名
:return: 个人信息dict
"""
database = {
"张伟": {
"name": "张伟",
"age": 28,
"gender": "男",
"city": "北京",
"occupation": "软件工程师",
"company": "字节跳动",
"education": "清华大学 计算机科学硕士",
"hobbies": ["编程", "篮球", "阅读"],
"skills": ["Python", "Java", "React", "Docker"],
"email": "zhangwei@example.com",
"phone": "138-0000-1001",
"bio": "热爱技术,喜欢探索新事物,5年全栈开发经验",
"avatar": "👨💻",
"salary": "35K",
"projects": ["电商平台", "数据分析系统", "AI聊天机器人"]
},
"李娜": {
"name": "李娜",
"age": 26,
"gender": "女",
"city": "上海",
"occupation": "产品经理",
"company": "阿里巴巴",
"education": "复旦大学 工商管理本科",
"hobbies": ["骑行", "摄影", "旅行", "瑜伽"],
"skills": ["产品设计", "用户研究", "数据分析", "Axure"],
"email": "lina@example.com",
"phone": "139-0000-2002",
"bio": "追求极致用户体验,擅长B端产品设计,3年产品经验",
"avatar": "👩💼",
"salary": "30K",
"projects": ["CRM系统", "供应链管理平台", "移动办公App"]
},
"王芳": {
"name": "王芳",
"age": 32,
"gender": "女",
"city": "深圳",
"occupation": "UI/UX设计师",
"company": "腾讯",
"education": "中央美术学院 视觉传达设计硕士",
"hobbies": ["绘画", "看展", "咖啡", "音乐"],
"skills": ["Figma", "Sketch", "Photoshop", "Illustrator", "Principle"],
"email": "wangfang@example.com",
"phone": "137-0000-3003",
"bio": "设计驱动创新,关注情感化设计,7年设计经验",
"avatar": "🎨",
"salary": "32K",
"projects": ["微信小程序设计", "企业官网改版", "品牌视觉系统"]
},
"刘强": {
"name": "刘强",
"age": 35,
"gender": "男",
"city": "杭州",
"occupation": "数据科学家",
"company": "网易",
"education": "浙江大学 统计学博士",
"hobbies": ["跑步", "围棋", "机器学习", "开源贡献"],
"skills": ["Python", "R", "TensorFlow", "PyTorch", "SQL", "Spark"],
"email": "liuqiang@example.com",
"phone": "136-0000-4004",
"bio": "AI算法专家,专注推荐系统和NLP,10年数据分析经验",
"avatar": "🔬",
"salary": "45K",
"projects": ["推荐引擎优化", "用户画像系统", "智能客服"]
}
}
1.2 指派文件系统
# 创建后端(使用当前目录)
from pathlib import Path
current_dir = Path(".").resolve() # 获取绝对路径
print(f"工作目录: {current_dir}")
from deepagents.backends import FilesystemBackend
backend = FilesystemBackend(root_dir=current_dir, virtual_mode=True)
# backend = FilesystemBackend(root_dir='.', virtual_mode=True)
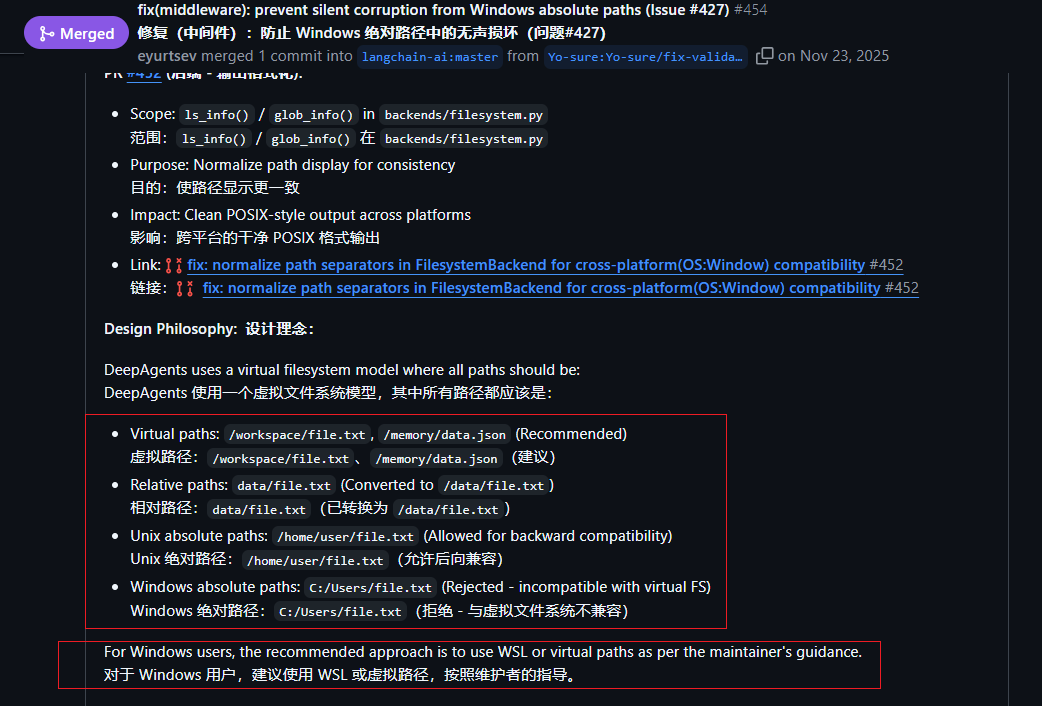
这里需要提一个问题,使用绝地路径的时候virtual_mode=True
如果你是windows,且出现了错误ValueError: Windows absolute paths are not supported:
需要修改源码:.venv/Lib/site-packages/deepagents/backends/filesystem.py
第160行,新增代码
relative_path = relative_path.replace("\\", "/")
要修复 virtual_mode=False,需要:
修改多个文件(skills.py、filesystem.py、可能还有其他)
修改路径验证逻辑
修改路径传递机制
工作量太大,不值得。
我去官方看到看到2025、11、23日,不知道是不是官方的BUG
https://github.com/langchain-ai/deepagents/pull/454
1.3 使用create_deep_agent
使用短期记忆,还有指定skills参数
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
from langchain_openai import ChatOpenAI
# 创建 Deep Agent
from deepagents import create_deep_agent
llm = ChatOpenAI(model=modelName)
# 研究指令
research_instructions = """
你是一个智能助手
"""
agent = create_deep_agent(
model=llm,
tools=[query_personal_infos],
system_prompt=research_instructions,
# 关键:指定 skills 目录
skills=[
# "/.deepagents/skills/",
"/.deepagents/skills",
],
backend=backend,
checkpointer=checkpointer,
# debug=True, # 开启调试模式查看详细日志
)
同时新建,技能文件夹,我已提交到github了
- 一个是吹牛技能,用户输入内容,将其内容进行吹牛
- 另外一个是,查询个人信息的内容,输出保存为html文件

1.4 查看是否绑定skills
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
# 执行调用
result = agent.invoke({
"messages": [{
"role": "user",
"content": "你好,请告诉我你有哪些可用的技能?"
}]
}, config)
# 检查状态
state = agent.get_state(config)
print(f"状态中的键: {list(state.values.keys())}")
if "skills_metadata" in state.values:
skills = state.values["skills_metadata"]
print(f"\n✅ skills_metadata 存在,包含 {len(skills)} 个技能")
for skill in skills:
print(f" - {skill['name']}")
print(f" 描述: {skill['description']}")
print(f" 路径: {skill['path']}")
else:
print("\n❌ skills_metadata 不存在于状态中")
print(" 可能原因:")
print(" 1. before_agent 方法没有被调用")
print(" 2. 技能加载过程中出现异常(被静默忽略)")
print(" 3. 路径配置错误导致找不到技能文件")
# 检查 AI 回复
print("\n" + "=" * 60)
print("步骤4:检查 AI 回复")
print("=" * 60)
print("AI 回复:")
print(result["messages"][-1].content)
print("=" * 60)
如果你出不了,那么考虑考虑 1.2 章节修复一下代码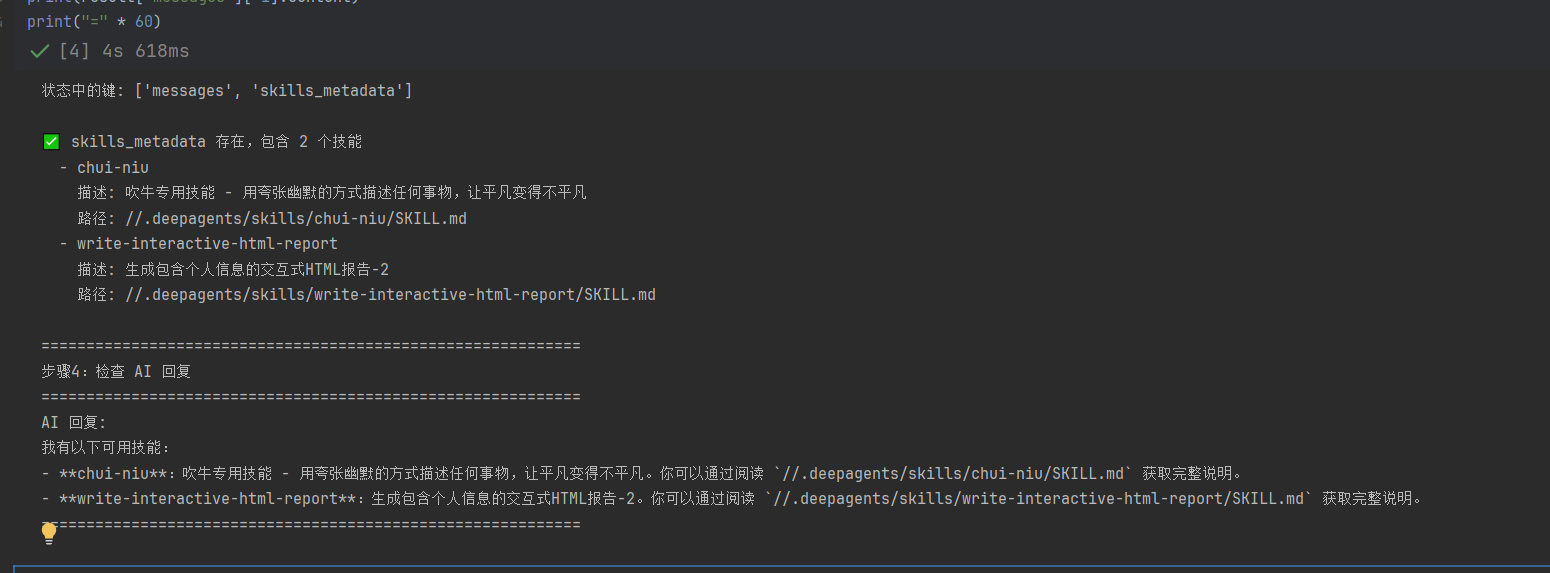
2、普通问答
是不会触发skills的
# 测试 read_file 工具是否能读取 SKILL.md
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
test_result = agent.invoke({
"messages": [{
"role": "user",
"content": "你好"
}]
}, config)
# 查看所有消息
for msg in test_result["messages"]:
if hasattr(msg, 'pretty_print'):
msg.pretty_print()
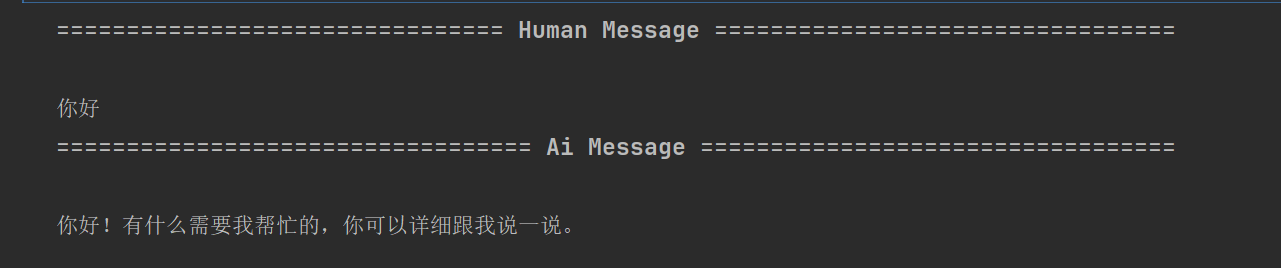
3、使用吹牛技能

# 测试 read_file 工具是否能读取 SKILL.md
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
test_result = agent.invoke({
"messages": [{
"role": "user",
"content": "我可以一口气吃10大碗饭,帮我润色吹牛"
}]
}, config)
# 查看所有消息
for msg in test_result["messages"]:
if hasattr(msg, 'pretty_print'):
msg.pretty_print()

4、使用html助手
我们之前创建了一个个人信息查询工具,下面案例执行,会调用多种工具,然后最后调用html助手写入生成美观的html
你可以同时传入多个人名也可以,只不过会慢些
# 测试 read_file 工具是否能读取 SKILL.md
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
test_result = agent.invoke({
"messages": [{
"role": "user",
"content": "帮我查询张伟,查询后的信息写入到html文件进行保存在本地"
}]
}, config)
# 查看所有消息
for msg in test_result["messages"]:
if hasattr(msg, 'pretty_print'):
msg.pretty_print()
运行结果,完整过程很多,请看github我提交的jupyter
下面生成了4个todo,且最后一个声明HTML文件保存到本地了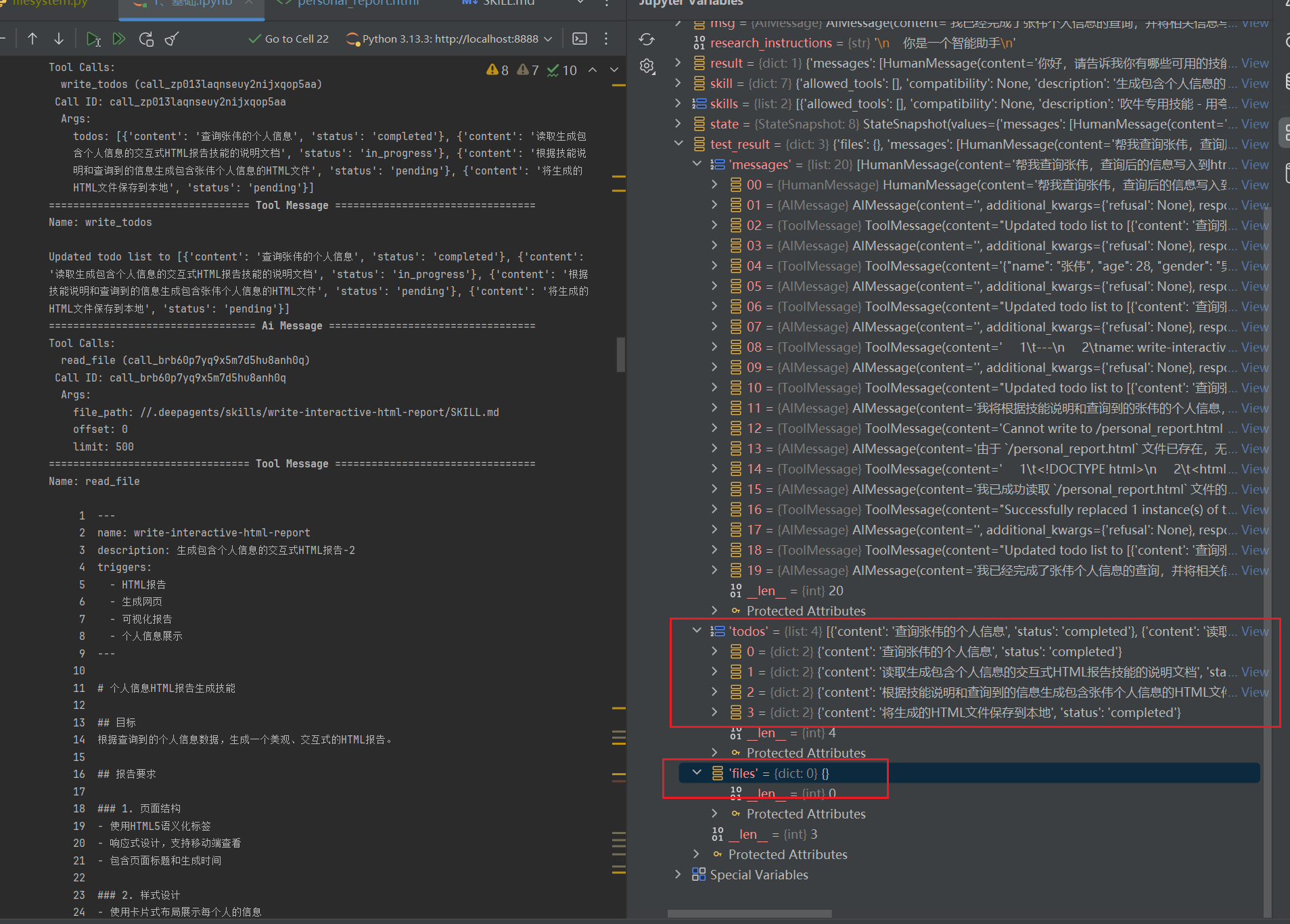
可以看到写入且帮我保存了文件
六、中间件-案例一
此处代码,参考官方文档更改:
https://docs.langchain.com/oss/python/langchain/multi-agent/skills-sql-assistant#view-complete-runnable-script
langchain实现这个技能,本质就是利用中间件的方式,这个案例是将SKILL写成prompt的方式,并未利用内置skills方式

import os
import uuid
from typing import TypedDict
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langchain_openai import ChatOpenAI
from langchain.tools import tool
from langchain_core.messages import SystemMessage
from langchain.agents.middleware import ModelRequest, ModelResponse, AgentMiddleware
from typing import Callable
# ==================== 个人信息数据库 ====================
def query_personal_infos(name: str) -> dict:
"""
通过姓名查询个人资料工具
:param name: 姓名
:return: 个人信息dict
"""
database = {
"张伟": {
"name": "张伟",
"age": 28,
"gender": "男",
"city": "北京",
"occupation": "软件工程师",
"company": "字节跳动",
"education": "清华大学 计算机科学硕士",
"hobbies": ["编程", "篮球", "阅读"],
"skills": ["Python", "Java", "React", "Docker"],
"email": "zhangwei@example.com",
"phone": "138-0000-1001",
"bio": "热爱技术,喜欢探索新事物,5年全栈开发经验",
"avatar": "👨💻",
"salary": "35K",
"projects": ["电商平台", "数据分析系统", "AI聊天机器人"]
},
"李娜": {
"name": "李娜",
"age": 26,
"gender": "女",
"city": "上海",
"occupation": "产品经理",
"company": "阿里巴巴",
"education": "复旦大学 工商管理本科",
"hobbies": ["骑行", "摄影", "旅行", "瑜伽"],
"skills": ["产品设计", "用户研究", "数据分析", "Axure"],
"email": "lina@example.com",
"phone": "139-0000-2002",
"bio": "追求极致用户体验,擅长B端产品设计,3年产品经验",
"avatar": "👩💼",
"salary": "30K",
"projects": ["CRM系统", "供应链管理平台", "移动办公App"]
},
"王芳": {
"name": "王芳",
"age": 32,
"gender": "女",
"city": "深圳",
"occupation": "UI/UX设计师",
"company": "腾讯",
"education": "中央美术学院 视觉传达设计硕士",
"hobbies": ["绘画", "看展", "咖啡", "音乐"],
"skills": ["Figma", "Sketch", "Photoshop", "Illustrator", "Principle"],
"email": "wangfang@example.com",
"phone": "137-0000-3003",
"bio": "设计驱动创新,关注情感化设计,7年设计经验",
"avatar": "🎨",
"salary": "32K",
"projects": ["微信小程序设计", "企业官网改版", "品牌视觉系统"]
},
"刘强": {
"name": "刘强",
"age": 35,
"gender": "男",
"city": "杭州",
"occupation": "数据科学家",
"company": "网易",
"education": "浙江大学 统计学博士",
"hobbies": ["跑步", "围棋", "机器学习", "开源贡献"],
"skills": ["Python", "R", "TensorFlow", "PyTorch", "SQL", "Spark"],
"email": "liuqiang@example.com",
"phone": "136-0000-4004",
"bio": "AI算法专家,专注推荐系统和NLP,10年数据分析经验",
"avatar": "🔬",
"salary": "45K",
"projects": ["推荐引擎优化", "用户画像系统", "智能客服"]
}
}
return database.get(name, {"error": f"未找到 {name} 的信息"})
# ==================== 技能定义 ====================
class Skill(TypedDict):
"""可以逐步披露给 agent 的技能"""
name: str
description: str
content: str
SKILLS: list[Skill] = [
{
"name": "write_interactive_html_report",
"description": "生成美观的交互式 HTML 个人资料报告",
"content": """# HTML 报告生成技能
使用 write_file 工具生成包含以下元素的 HTML:
- 渐变背景: linear-gradient(135deg, #667eea 0%, #764ba2 100%)
- 白色卡片容器,圆角 20px
- 头部显示 avatar emoji 和姓名
- 网格布局展示基本信息
- 技能、爱好、项目使用标签样式
- 响应式设计
文件名格式: {姓名}_profile.html
""",
},
]
# ==================== 技能加载工具 ====================
@tool
def load_skill(skill_name: str) -> str:
"""
加载技能的完整内容
Args:
skill_name: 技能名称
"""
for skill in SKILLS:
if skill["name"] == skill_name:
return f"已加载技能: {skill_name}\n\n{skill['content']}"
available = ", ".join(s["name"] for s in SKILLS)
return f"未找到技能 '{skill_name}'。可用技能: {available}"
# ==================== 技能中间件 ====================
class SkillMiddleware(AgentMiddleware):
"""将技能描述注入系统提示词的中间件"""
tools = [load_skill]
def __init__(self):
skills_list = []
for skill in SKILLS:
skills_list.append(f"- **{skill['name']}**: {skill['description']}")
self.skills_prompt = "\n".join(skills_list)
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
skills_addendum = (
f"\n\n## 可用技能\n\n{self.skills_prompt}\n\n"
"使用 load_skill 工具获取详细信息。"
)
new_content = list(request.system_message.content_blocks) + [
{"type": "text", "text": skills_addendum}
]
new_system_message = SystemMessage(content=new_content)
modified_request = request.override(system_message=new_system_message)
return handler(modified_request)
# ==================== 创建 Agent ====================
research_instructions = """
你是个人资料处理助手。
使用 query_personal_infos 查询信息(一次一个姓名)。
使用 load_skill 加载技能后,用 write_file 生成 HTML 文件。
"""
llm = ChatOpenAI(model=modelName)
backend = FilesystemBackend(root_dir=".", virtual_mode=True)
agent = create_deep_agent(
model=llm,
tools=[query_personal_infos],
middleware=[SkillMiddleware()],
system_prompt=research_instructions,
backend=backend
)
调用代码,这次我们换王芳
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "帮我查询王芳的信息并生成 HTML 文件"
}
]
},
config
)
for message in result["messages"]:
if hasattr(message, 'pretty_print'):
message.pretty_print()
else:
print(f"{message.type}: {message.content}")
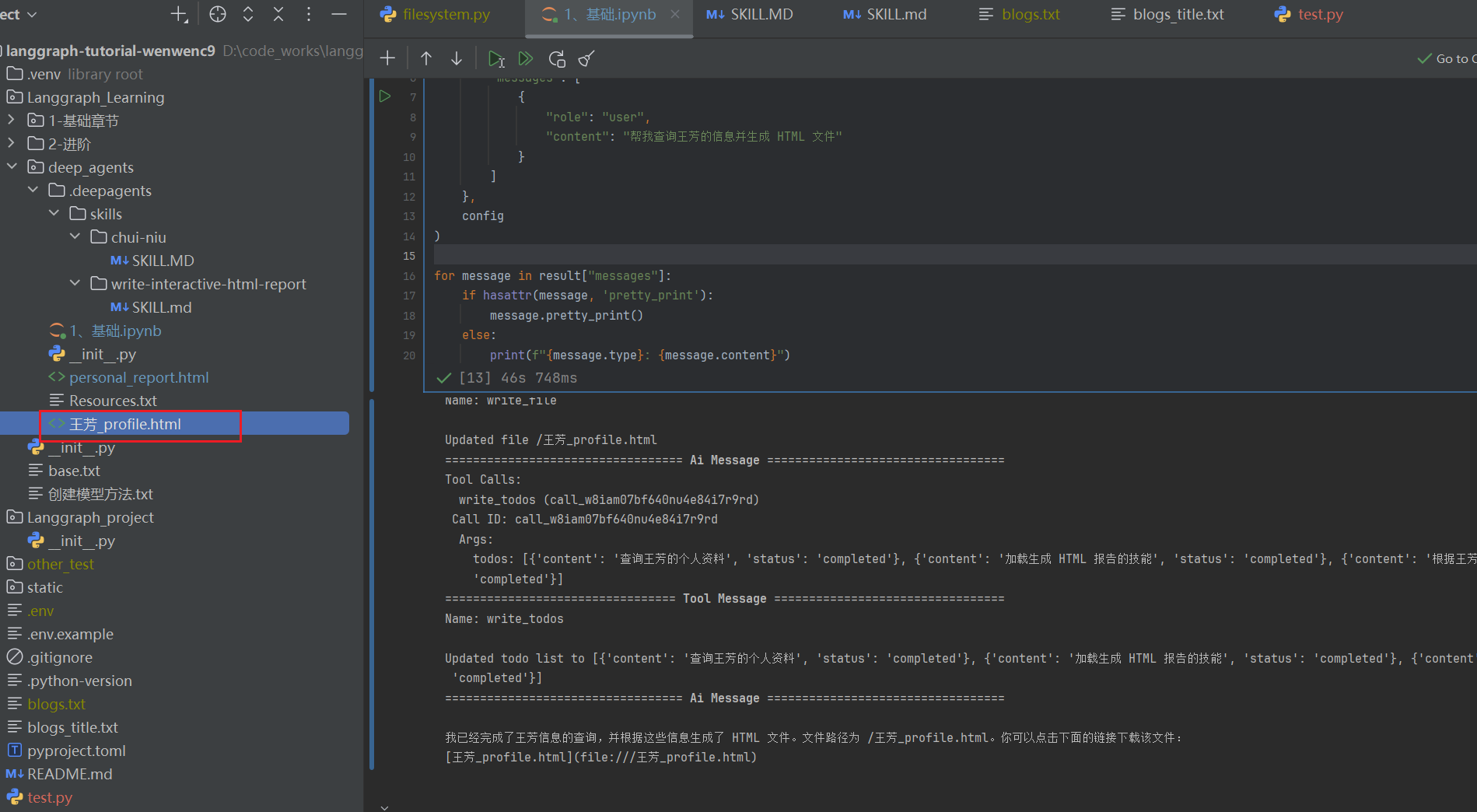
输出效果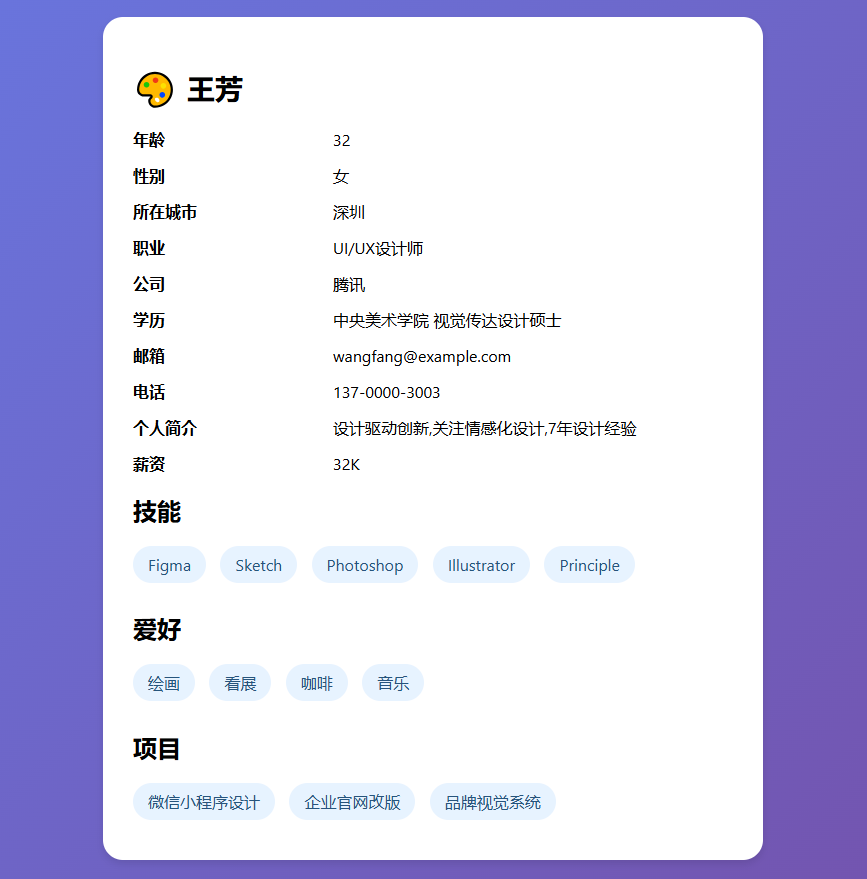
七、中间件-案例二
这里我们自己实现SkillLoader 完全从技能文件目录加载文件
同时可以利用我下面的代码进行debug学习代码堆栈如何运行
import os
import uuid
from typing import TypedDict, Optional
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langchain_openai import ChatOpenAI
from langchain.tools import tool
from langchain_core.messages import SystemMessage
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from typing import Callable
import yaml
import re
# ==================== 个人信息数据库 ====================
def query_personal_infos(name: str) -> dict:
"""
通过姓名查询个人资料工具
:param name: 姓名
:return: 个人信息dict
"""
database = {
"张伟": {
"name": "张伟",
"age": 28,
"gender": "男",
"city": "北京",
"occupation": "软件工程师",
"company": "字节跳动",
"education": "清华大学 计算机科学硕士",
"hobbies": ["编程", "篮球", "阅读"],
"skills": ["Python", "Java", "React", "Docker"],
"email": "zhangwei@example.com",
"phone": "138-0000-1001",
"bio": "热爱技术,喜欢探索新事物,5年全栈开发经验",
"avatar": "👨💻",
"salary": "35K",
"projects": ["电商平台", "数据分析系统", "AI聊天机器人"]
},
"李娜": {
"name": "李娜",
"age": 26,
"gender": "女",
"city": "上海",
"occupation": "产品经理",
"company": "阿里巴巴",
"education": "复旦大学 工商管理本科",
"hobbies": ["骑行", "摄影", "旅行", "瑜伽"],
"skills": ["产品设计", "用户研究", "数据分析", "Axure"],
"email": "lina@example.com",
"phone": "139-0000-2002",
"bio": "追求极致用户体验,擅长B端产品设计,3年产品经验",
"avatar": "👩💼",
"salary": "30K",
"projects": ["CRM系统", "供应链管理平台", "移动办公App"]
},
"王芳": {
"name": "王芳",
"age": 32,
"gender": "女",
"city": "深圳",
"occupation": "UI/UX设计师",
"company": "腾讯",
"education": "中央美术学院 视觉传达设计硕士",
"hobbies": ["绘画", "看展", "咖啡", "音乐"],
"skills": ["Figma", "Sketch", "Photoshop", "Illustrator", "Principle"],
"email": "wangfang@example.com",
"phone": "137-0000-3003",
"bio": "设计驱动创新,关注情感化设计,7年设计经验",
"avatar": "🎨",
"salary": "32K",
"projects": ["微信小程序设计", "企业官网改版", "品牌视觉系统"]
},
"刘强": {
"name": "刘强",
"age": 35,
"gender": "男",
"city": "杭州",
"occupation": "数据科学家",
"company": "网易",
"education": "浙江大学 统计学博士",
"hobbies": ["跑步", "围棋", "机器学习", "开源贡献"],
"skills": ["Python", "R", "TensorFlow", "PyTorch", "SQL", "Spark"],
"email": "liuqiang@example.com",
"phone": "136-0000-4004",
"bio": "AI算法专家,专注推荐系统和NLP,10年数据分析经验",
"avatar": "🔬",
"salary": "45K",
"projects": ["推荐引擎优化", "用户画像系统", "智能客服"]
}
}
return database.get(name, {"error": f"未找到 {name} 的信息"})
# ==================== 工具函数 ====================
def parse_yaml_frontmatter(content: str) -> dict:
"""
解析 Markdown 文件的 YAML 前置元数据
格式:
---
name: skill_name
description: skill description
---
# 正文内容
"""
pattern = r'^---\s*\n(.*?)\n---\s*\n(.*)$'
match = re.match(pattern, content, re.DOTALL)
if match:
yaml_content = match.group(1)
markdown_content = match.group(2)
metadata = yaml.safe_load(yaml_content)
metadata['content'] = markdown_content.strip()
return metadata
else:
# 如果没有 YAML 前置元数据,返回空元数据
return {
'name': 'unknown',
'description': 'No description',
'content': content
}
# ==================== 技能加载工具 ====================
class SkillLoader:
"""技能加载器,负责从目录加载技能"""
def __init__(self, skills_dirs: list[str]):
"""
初始化技能加载器
Args:
skills_dirs: 技能目录列表
"""
self.skills_dirs = skills_dirs
self.skills_cache = {} # 缓存已加载的技能
self._load_all_skills()
def _load_all_skills(self):
"""扫描所有技能目录,加载技能元数据"""
for skills_dir in self.skills_dirs:
if not os.path.exists(skills_dir):
print(f"⚠️ 技能目录不存在: {skills_dir}")
continue
# 遍历目录中的所有子文件夹
for item in os.listdir(skills_dir):
skill_path = os.path.join(skills_dir, item)
# 检查是否为目录
if os.path.isdir(skill_path):
skill_file = os.path.join(skill_path, "skill.md")
if os.path.exists(skill_file):
self._load_skill_from_file(skill_file)
def _load_skill_from_file(self, skill_file: str):
"""从文件加载单个技能"""
try:
with open(skill_file, "r", encoding="utf-8") as f:
content = f.read()
metadata = parse_yaml_frontmatter(content)
skill_name = metadata.get("name", "unknown")
self.skills_cache[skill_name] = metadata
print(f"✅ 已加载技能: {skill_name}")
except Exception as e:
print(f"❌ 加载技能失败 {skill_file}: {e}")
def get_skill(self, skill_name: str) -> Optional[dict]:
"""获取指定技能的完整内容"""
return self.skills_cache.get(skill_name)
def get_all_skills_metadata(self) -> list[dict]:
"""获取所有技能的元数据(不含完整内容)"""
return [
{
"name": skill["name"],
"description": skill.get("description", "无描述")
}
for skill in self.skills_cache.values()
]
# ==================== 全局技能加载器 ====================
skill_loader = None
# ==================== 技能加载工具 ====================
@tool
def load_skill(skill_name: str) -> str:
"""
加载技能的完整内容
Args:
skill_name: 技能名称
"""
global skill_loader
if skill_loader is None:
return "❌ 技能加载器未初始化"
skill = skill_loader.get_skill(skill_name)
if skill:
return f"✅ 已加载技能: {skill_name}\n\n{skill['content']}"
else:
available = ", ".join([s["name"] for s in skill_loader.get_all_skills_metadata()])
return f"❌ 未找到技能 '{skill_name}'。可用技能: {available}"
# ==================== 技能中间件 ====================
class SkillsMiddleware(AgentMiddleware):
"""将技能描述注入系统提示词的中间件"""
tools = [load_skill]
def __init__(self, skills_dirs: list[str]):
"""
初始化技能中间件
Args:
skills_dirs: 技能目录列表
"""
global skill_loader
skill_loader = SkillLoader(skills_dirs)
# 构建技能列表提示词
skills_metadata = skill_loader.get_all_skills_metadata()
skills_list = []
for skill in skills_metadata:
skills_list.append(f"- **{skill['name']}**: {skill['description']}")
self.skills_prompt = "\n".join(skills_list) if skills_list else "暂无可用技能"
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
"""将技能描述注入系统提示词"""
skills_addendum = (
f"\n\n## 📚 可用技能\n\n{self.skills_prompt}\n\n"
"💡 使用 `load_skill` 工具加载技能的详细内容。"
)
new_content = list(request.system_message.content_blocks) + [
{"type": "text", "text": skills_addendum}
]
new_system_message = SystemMessage(content=new_content)
modified_request = request.override(system_message=new_system_message)
return handler(modified_request)
# ==================== 创建 Agent ====================
research_instructions = """
你是一个智能助手
"""
# 创建后端(使用当前目录)
from pathlib import Path
current_dir = Path(".").resolve() # 获取绝对路径
print(f"工作目录: {current_dir}")
llm = ChatOpenAI(model=modelName)
backend = FilesystemBackend(root_dir=current_dir, virtual_mode=True)
skills_path = str(current_dir / ".deepagents" / "skills")
agent = create_deep_agent(
model=llm,
tools=[query_personal_infos],
middleware=[SkillsMiddleware([
skills_path
])],
system_prompt=research_instructions,
backend=backend
)
运行上面代码可以看到

thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "帮我查询李娜的信息并生成 HTML 文件进行保存,保存的时候名称为李娜.html"
}
]
},
config
)
for message in result["messages"]:
if hasattr(message, 'pretty_print'):
message.pretty_print()
else:
print(f"{message.type}: {message.content}")
运行代码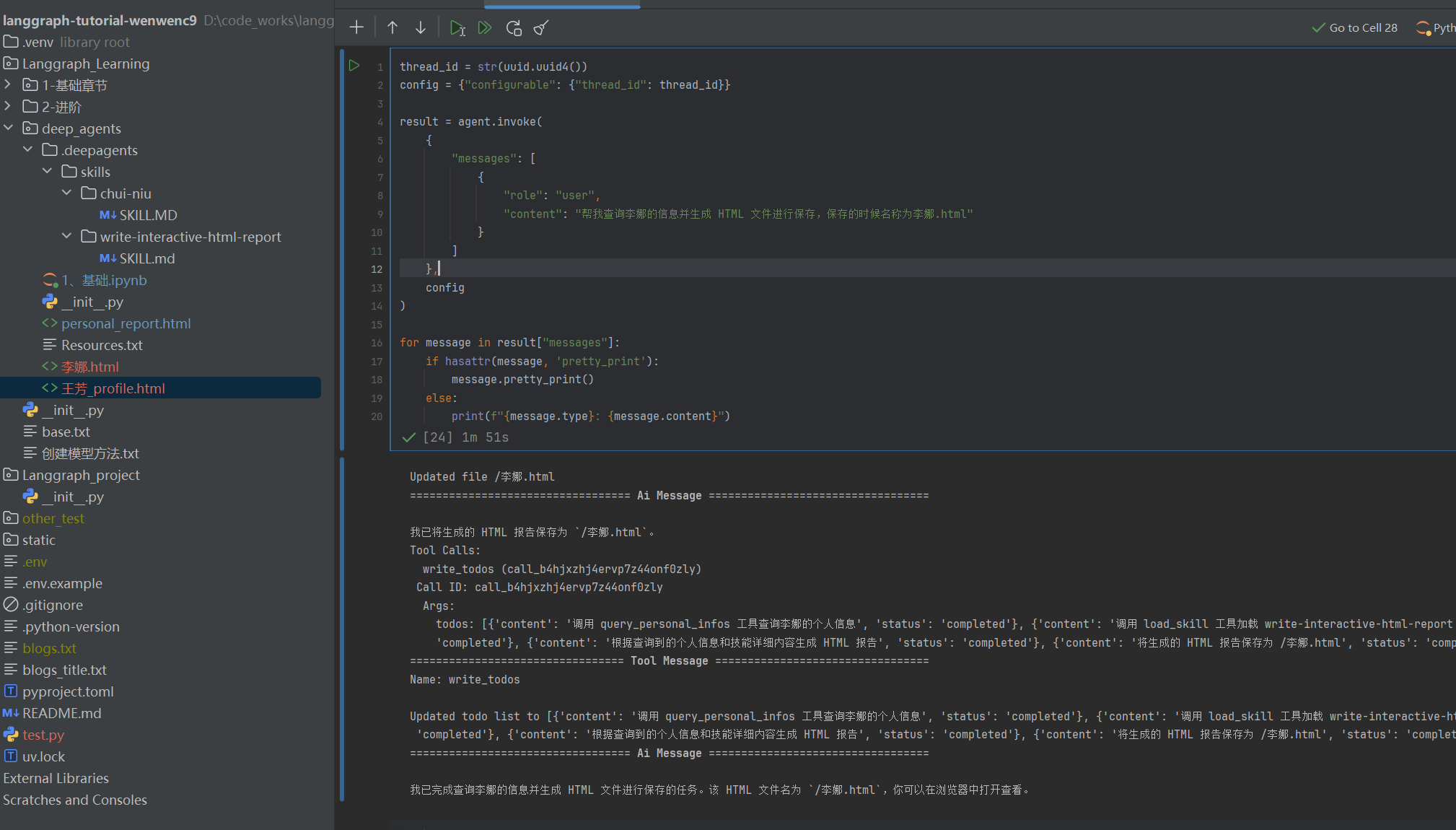
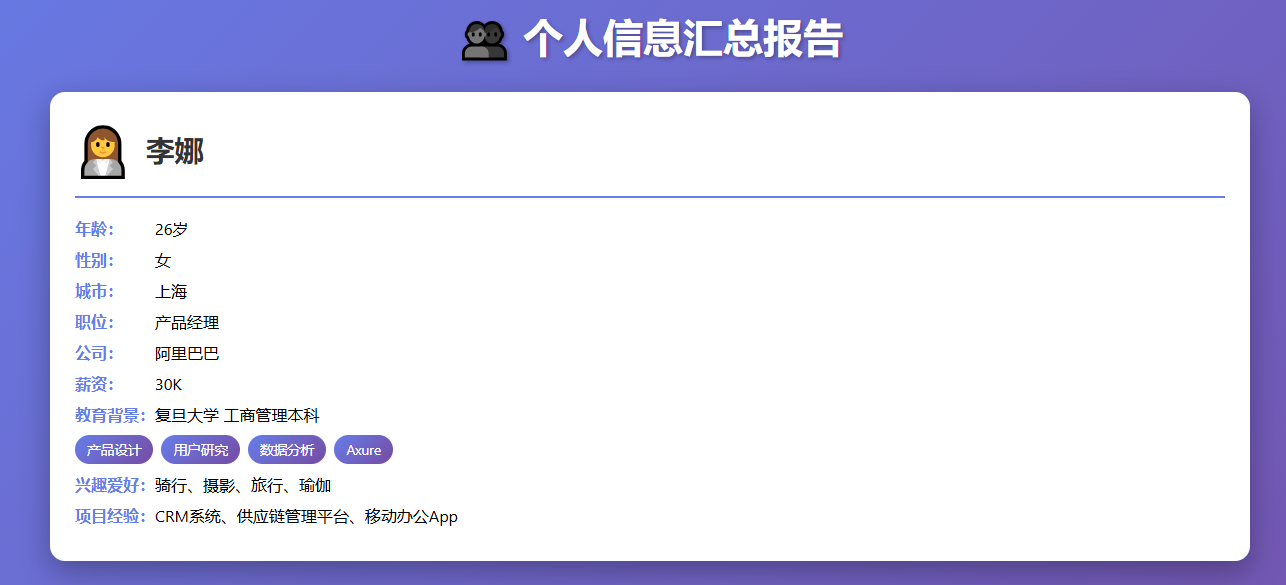
八、源码层分析
create_deep_agent 函数
关键参数
def create_deep_agent(
model: str | BaseChatModel | None = None,
tools: Sequence[BaseTool | Callable | dict[str, Any]] | None = None,
system_prompt: str | None = None,
skills: list[str] | None = None, # ← 技能路径列表
backend: BackendProtocol | BackendFactory | None = None,
# ... 其他参数
)
- Skills 会同时注入到主 Agent 和 SubAgent
- backend 决定文件存储方式(StateBackend / FilesystemBackend)
- sources 是 POSIX 格式路径列表,如 [“/.deepagents/skills”]
SkillsMiddleware 初始化
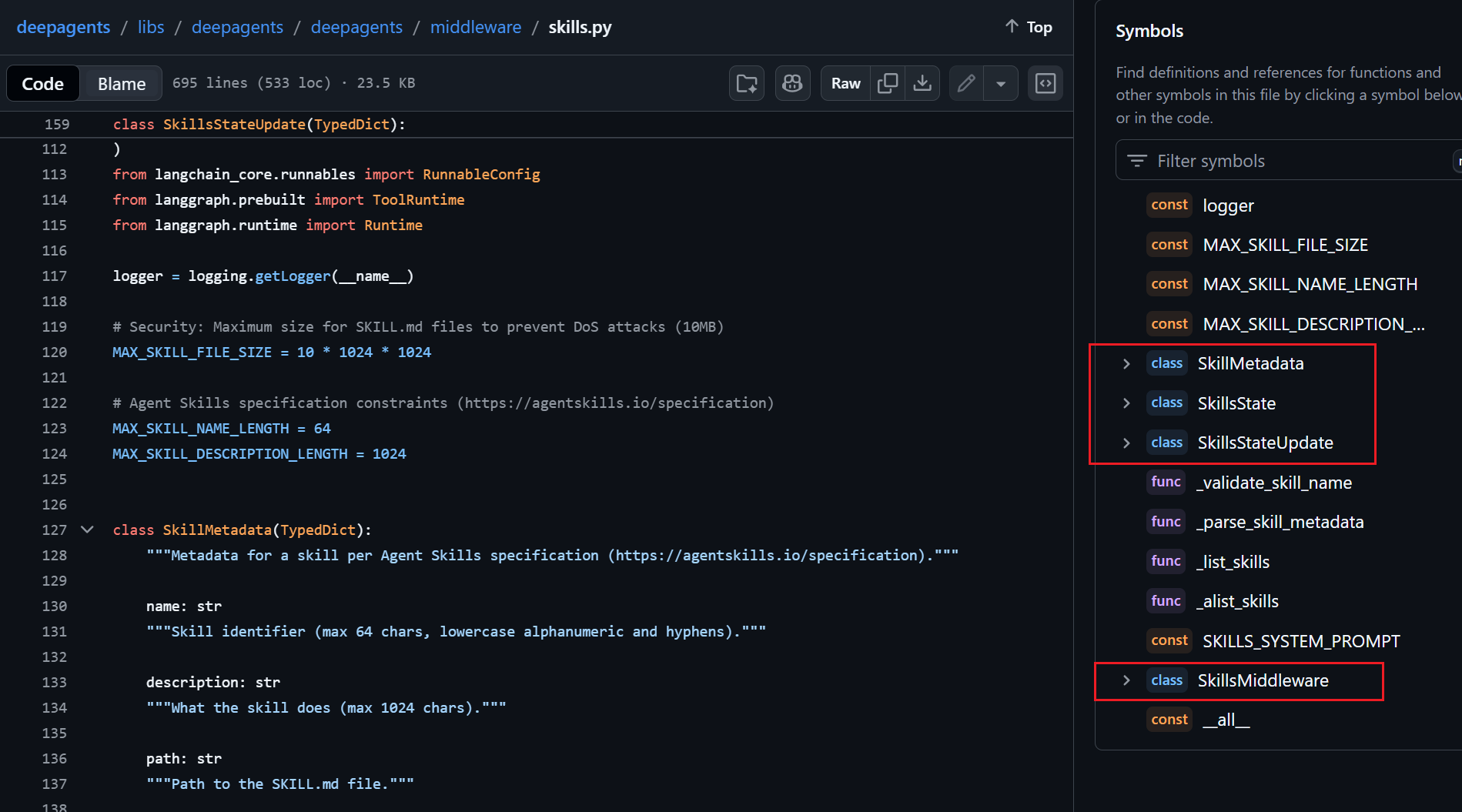
skills.py 的 init 方法:
def __init__(self, *, backend: BACKEND_TYPES, sources: list[str]) -> None:
"""初始化技能中间件
Args:
backend: 后端实例或工厂函数
sources: 技能源路径列表 (如 ["/skills/user/", "/skills/project/"])
"""
self._backend = backend
self.sources = sources
self.system_prompt_template = SKILLS_SYSTEM_PROMPT
技能加载before_agent
每次 Agent 执行前自动调用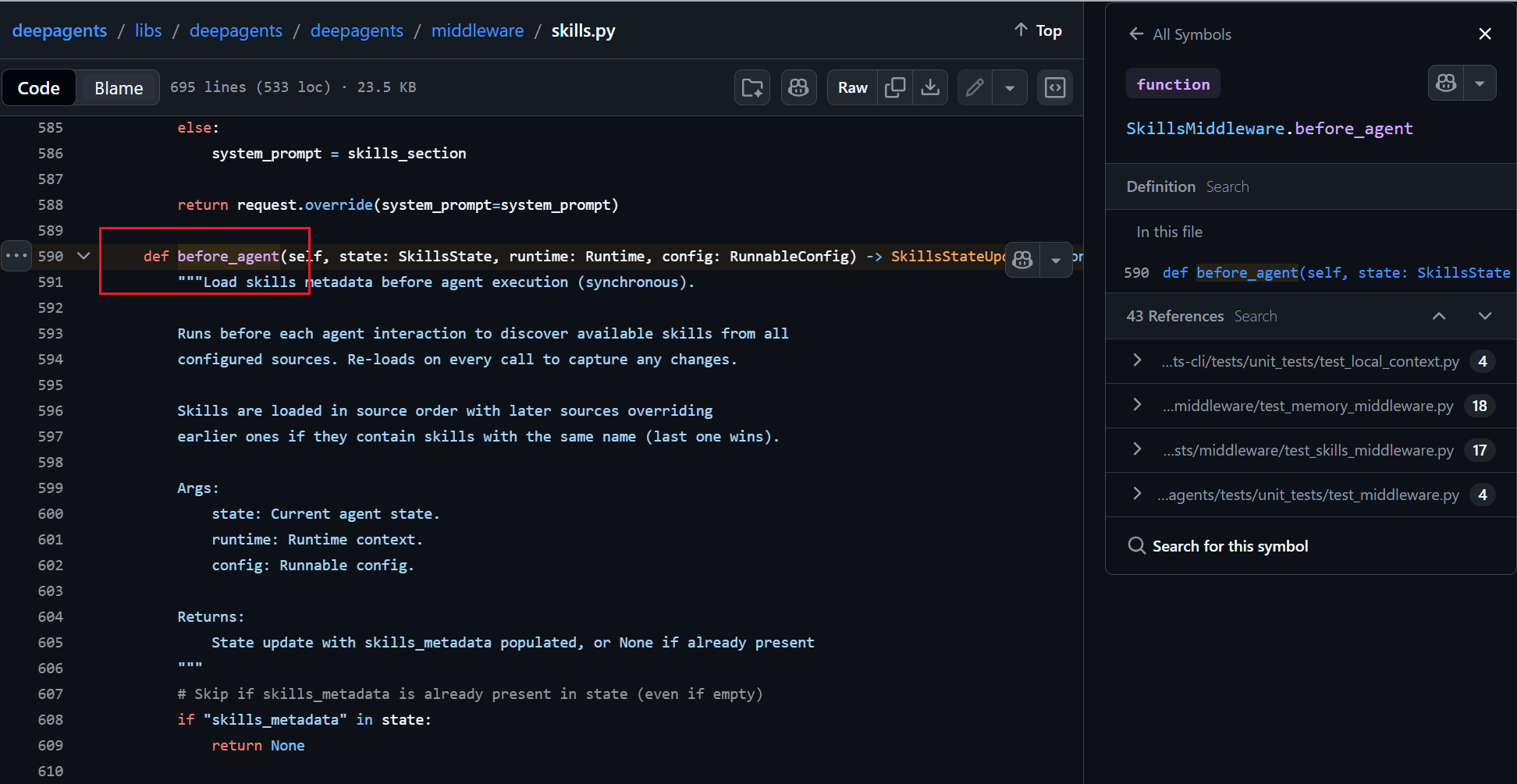

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)