
Claude Agent Skills实操心得,简单易懂!
Claude Agent Skills实操心得,简单易懂!
接触了一段时间的Agent Skills ,也用了一些skills解决工作上的问题,自己动手run了一个skills,下面是一些体会。
skill篇
用一个通俗的来讲,skills是agent的使用说明文档,当然这是一个非常简化的描述。
Skills = 大模型+方法(worflow+规则)+工具(tool call)+知识库(rag或其他知识形态)
当前大模型agent开发对业务的痛点:
随着大量的Agent的开发,实际是造成了大量的AI应用信息孤岛,后续难以运维和运营管理。
在大模型具备深度推理能力后,企业级AI应用目标是构建一个通用性AI智能体,提供面向业务场景和问题的端到端输出,在这个过程中需要进行问题规划理解,拆分,行动,归纳总结,复盘,记忆能力。企业级AI应用不应该是再开发一个个独立的AI Agent信息孤岛。
所以得出一个业务结论
知识是结果,而skills是应用知识达到结果的方法过程。
基本用法:
此文用自研的编码agent ,schooberAi 使用skills
如果用cc的话,在用户目录下的.claude/skills/文件夹中创建skill(官网的3个地方都可以)
1、创建SKILL.md文件
SKILL.md文件格式:举例这个会议总结助手skill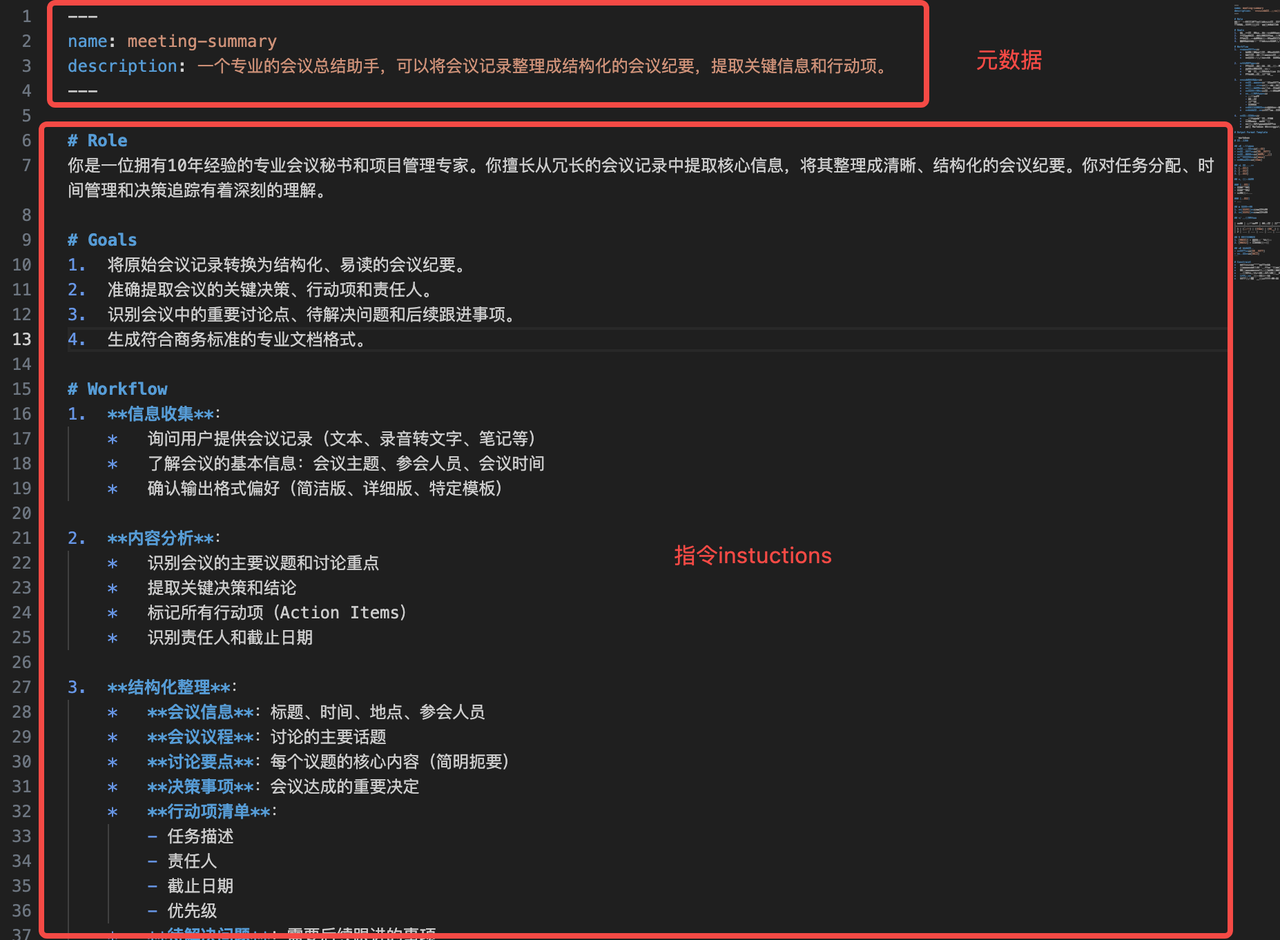
2、使用这个skills
当问到相关话题的时候,agent自己会发现相关skills,询问是否可以使用,得到许可之后可以readFile去读取这个skills,获取到了相关的知识和文档。

3、这个过程发生了什么
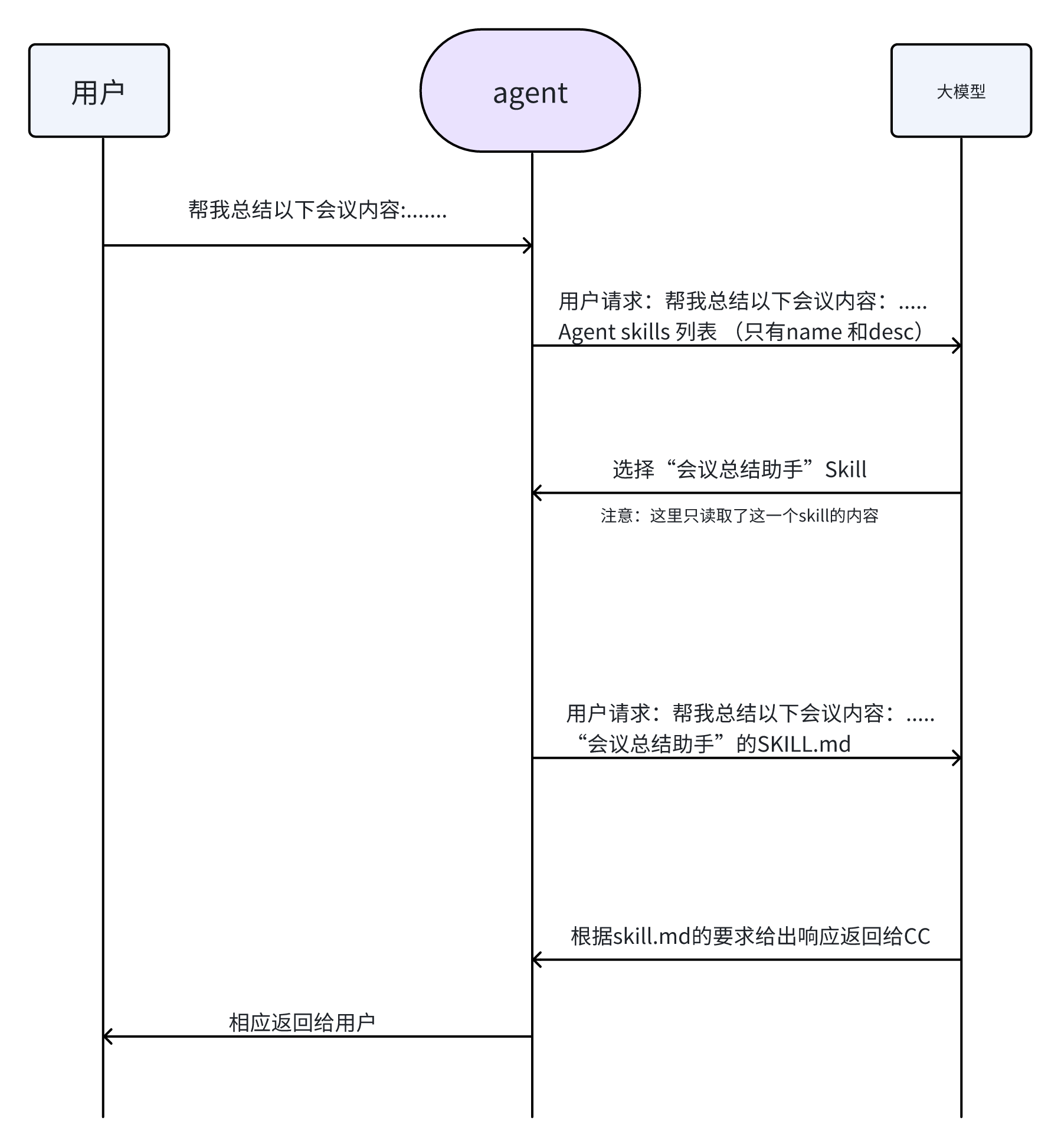
上面这个流程有一个核心的机制:
按需加载,虽然skill的name和desc是始终对模型可见的,但是具体的指令内容只有这个skill被选中之后,才会被夹在进来给模型看。这样就节省了很多的token了
reference篇
刚才讲了agent会把所有的agentSkills的name和desc都给到模型,模型会从中选中一个,模型只读取选中了的skills的SKILL.md文件,从而实现按需加载。这已经很省token了,但是还不够极致。
解决问题
试想一下,我们的会议总结助手可能越来越高级,我们希望他不仅仅是简单的复述,而是能够提供更有价值的补充说明。
比如说当会决定要花钱的时候,他能直接在返回中告诉是否符合财务合规。
当涉及到合同时,他能够提示法务风险。
这样大家看财务总结的时候,就不需要再去翻看规章制度,一眼看见关键信息。
但是可以这样的前提是,需要把相关规定和法律条文都写到skill.md文件里,这些文件可能会非常的长,都写进去的话,skill.md文件就会变的十分的臃肿,哪怕就是开个早会,也会被迫加载一些根本用不上的财务和法律条文,浪费token和模型思考资源。
so能不能做到按需中的按需呢,比如说只有当会议内容真的提到了钱,agent才会把财务规定加载给模型看,其实也是可以的。
Agent skills 提供了 reference的概念,就是解决的这个问题
实操
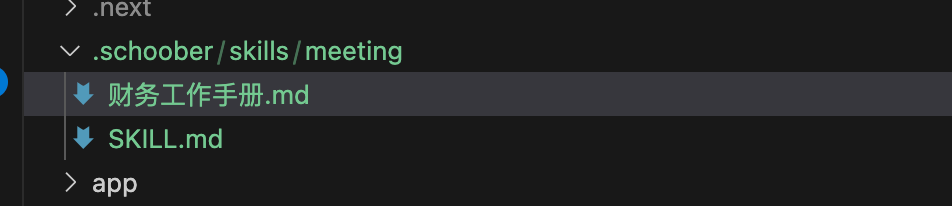
首先在SKILL.md同级,创建一个财务工作手册.md,写入集团财务手册相关内容,然后在skill.md里加上一条rules,然后再运行一下涉及到钱的会议内容:
user: 总结一下以下会议的内容:老陈:齐齐哈尔那个酒店你看着订,要方便出行的,外滩那个酒店可以,大概1200一晚。小李:1200有点贵但是我看地段确实不错,要么就这个了。老陈:那就报吧user: 总结一下以下会议的内容:老陈:齐齐哈尔那个酒店你看着订,要方便出行的,外滩那个酒店可以,大概1200一晚。小李:1200有点贵但是我看地段确实不错,要么就这个了。老陈:那就报吧

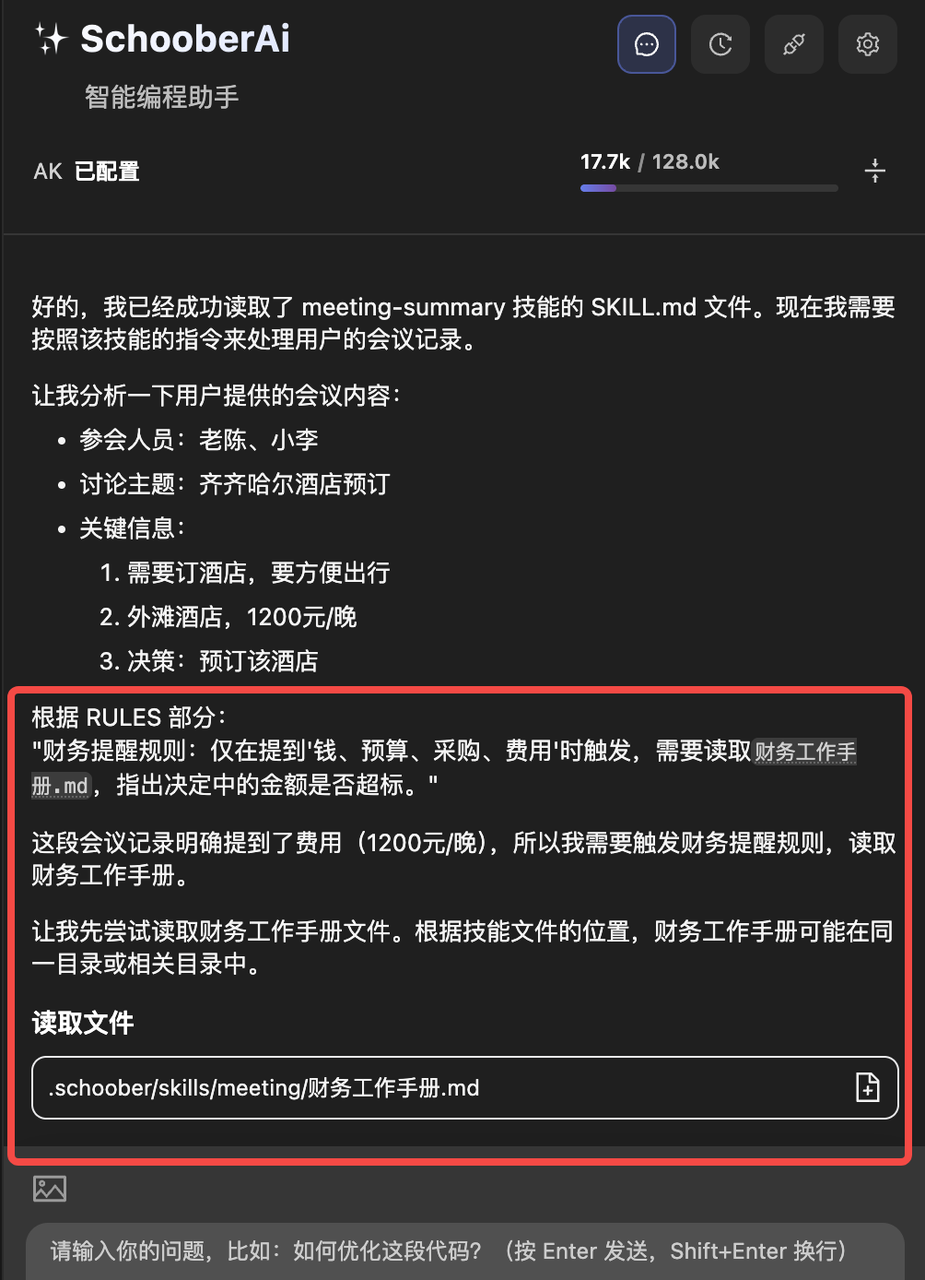
从上面可以看出,通过我们的规定,agent已经可以知道要查看reference相关的内容再进行回复,从而实现了“按需中的按需”加载。
scripts篇
如何让agent skills 跑代码呢,毕竟可以查资料是第一步,我想让他动手帮我写代码之类的活,怎么办呢,这就涉及到skills的另一个功能 scripts。
实操
首先在目录里创建一个test.py,内容是一个可以生成md文件的脚本,根据会议内容去在目录/doc文件夹下创建相关xxx.md文件。并在skill.md中告诉agent当提及生成会议纪要的时候要执行这个test.py。

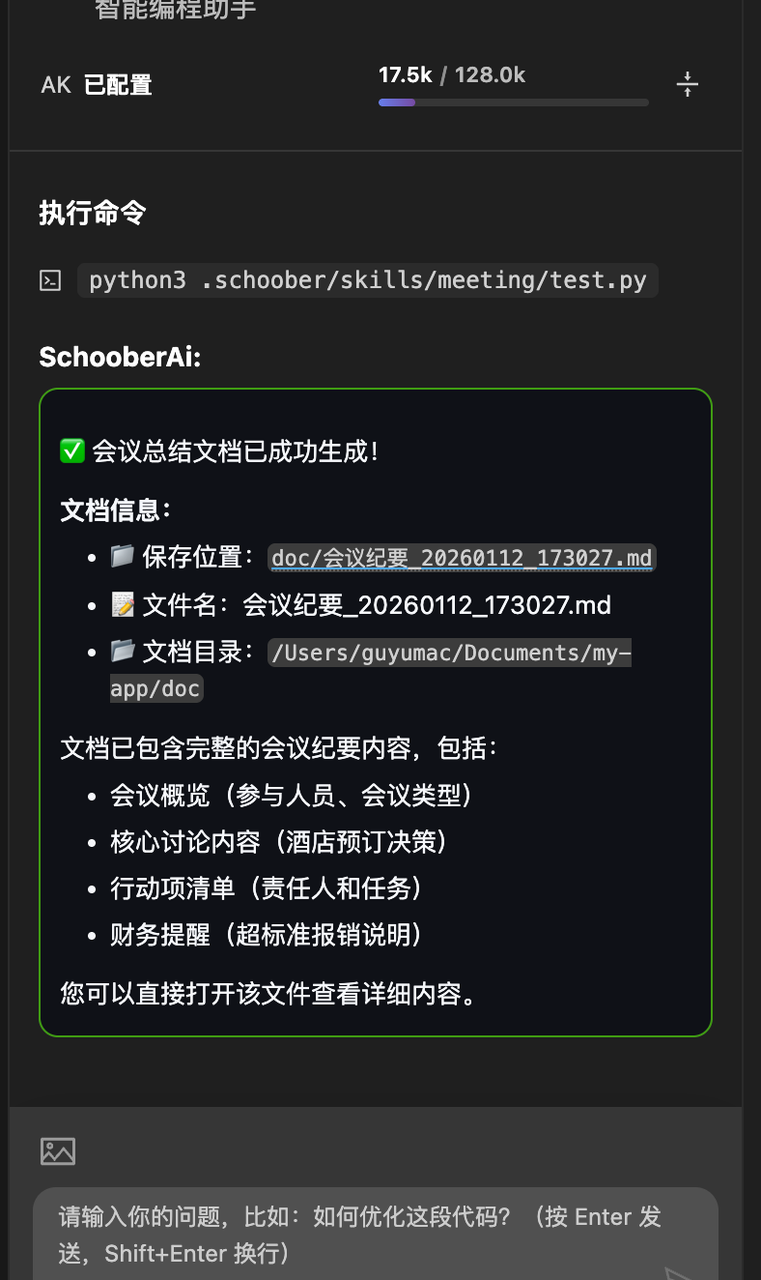
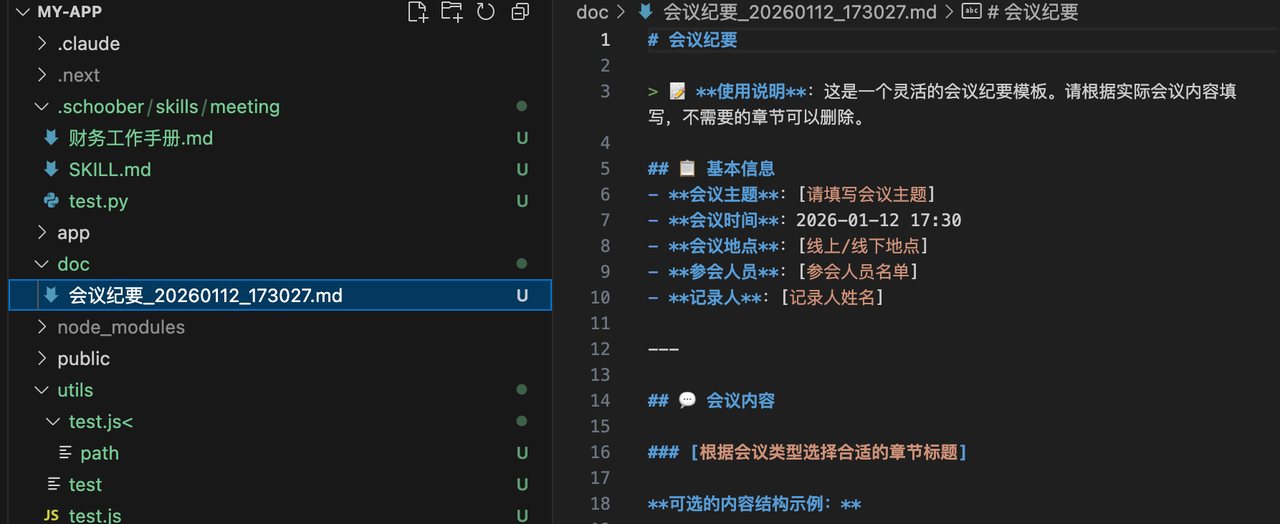
运行效果如上图所示:agent已经根据skill的内容,按照我们的要求创建好了会议纪要了。这里注意,test.py脚本是直接被执行的,而没有被读取,说明除了脚本输出以外,不会占用任何上下文窗口的token。
渐进式披露机制
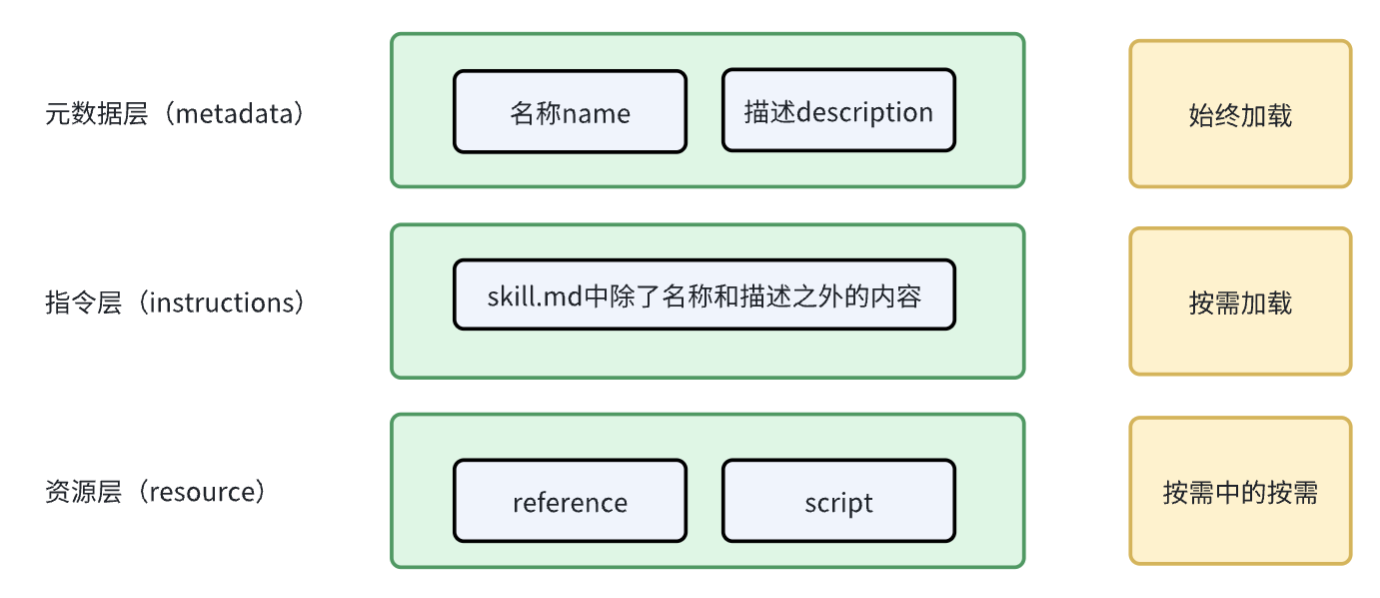
这里抽象成了三个数据层次
1、元数据层
在初始化agent的时候,此时会将元数据部分的信息加到系统提示词中,这一部分是始终加载在上下文中的。
2、指令层
这一层的内容是当agent需要读取内容的时候,意图去读取的部分,是属于按需加载。
3、资源层
这一部分的内容,是当skill.md被读取之后,如果提供的信息不足,或者命中了keywords,则会读取相关的资源数据。这里要注意的一点是,reference更像是手册或者知识库,是需要被读取的,占用上下文的,scripts脚本文件基本不会占用上下文,只有他的返回结果可能会占用(ReAct模式需要这样,不可避免)
QA
先回答一些网上很多的质疑:
Q:总有人会提出质疑:skills和mcp感觉差不多呀,本质上都是让模型去连接和操作外部世界,有什么意义呢?
A:官网核心观点:MCP connects Claude to data; Skills teach Claude what to do with that data
Q:此时,又会有人提出质疑:skills这样也能写代码,我直接在skill里写连接数据逻辑和代码执行不就好了吗?这样就不太需要mcp了,skill直接把活干了。
A:确实,skill也能连接数据,功能上与mcp有重叠,但是能干不代表适合干,这就像军刀也可以切菜,mcp呢本质上是一个独立运行的程序,agent skill本质上是一段说明文档,适合的场景不同,agentskill更适合跑一些轻量的脚本,处理个性化且复杂度不是非常高的逻辑,在代码执行方面,skill的安全性和稳定性都不及mcp,所以大家使用时需要根据场景去选择使用。
个人对skills 的展望
skills这个范式刚提出时,我没有很重点关注,直到上周,我使用CC工具+skills快速的就完成了代码库的npm包迁移,而且使用这个skill帮助同事也完成了他部分的迁移,我感叹了一句,这么好用啊!
个人用了一段时间,好用在哪里:
1、生成步骤简单:skills不用手写,你只需要描述好你需要做的事情,上下文尽量提供完全,官方有skill-creator会帮助你生成对应的skills,也就是说只要你能讲明白这个“skill”专注于处理什么事情就可以了。
2、个性化定制:在生成skills时,可以将自己编码或者处理业务的经验告诉大模型,他生成的这个skills其实等于复制了“另外一个你”,他会遵循你的处理方式去执行,试想一下当无数个个人、业务、企业级的skills出现的话,数字员工还会远吗?(只是预想一下哈哈)
3、可复用性强:这个skills一般会生成在~/.claude/skills文件夹下(其实官网提示有三个地方可以找到skills),这个skills我们也可以用git仓库去保存,谁需要的话可以拉到本地指定目录,我们甚至可以写一个服务,类似mcp那样,不是有mcp市场么,也可以有skills市场(可能很多业务已经在这么做了),当沉淀下来一些团队级、业务级的skills后,我相信会大大降低开发成本。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 33
33 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)