大语言模型工作原理:从输入到推理生成回答的全过程
大语言模型工作原理:从输入到推理生成回答的全过程
前言
近几年,大语言模型(LLM, Large Language Model)火遍全球。你每天和 ChatGPT、Claude、Gemini 等聊天,都会觉得它们几乎“像人一样会思考”。但其实,它们背后运行的逻辑完全是 数学与概率 的计算。
本文会带你理解:
- 大语言模型的基本推理原理
- RAG(检索增强生成)的工作机制
- 结合 GPT-5 接口调用的实际应用
通过这篇文章,你会理解 当你输入一句话时,机器到底经历了哪些步骤,才能输出合理答案。
一、用户输入内容
当你在聊天框里输入一句话,比如:
用户输入:请解释一下量子计算的基本原理
这句话进入大语言模型时,第一步是 文本编码。
模型不会直接“理解汉字”,而是先把输入转化成 Token(词元)。
例如:
- “量子” 可能被编码为 token id
54213 - “计算” 可能是
38219 - “基本原理” 则拆分成
19581+7210
这样,整句话就变成了一个 数字序列,方便模型做数学计算。
📽 动态图片模拟(输入阶段):
画面可以想象为:
- 左边一个用户输入框输入“量子计算的基本原理”
- 进入机器后,文字逐渐分裂成小方块(token)
- 每个小方块标注着一个数字 id,像一串数据流进入大脑
二、模型内容语义分析
接下来,模型会对这串 token 序列 进行 语义建模。
这里的关键是 Transformer 架构,它通过“自注意力机制(Self-Attention)”分析输入中各个词的关系:
- 它会发现“量子”与“计算”关系紧密
- “基本原理”是对“量子计算”的修饰
这种 语义相关性 会被转化为高维向量(embedding),比如一句话可能被表示为一个 1536维向量。
在这个阶段,模型并不是“理解”文字,而是通过数学把语言转化为语义空间中的点。类似于:
- “苹果”和“水果”的向量很接近
- “苹果”和“汽车”的向量距离较远
📽 动态图片模拟(语义分析阶段):
- 输入的 token 数字进入一个“神经网络大脑”
- 每个词被映射到一个三维空间里的点
- 点之间逐渐连成线,形成语义关系的网络图
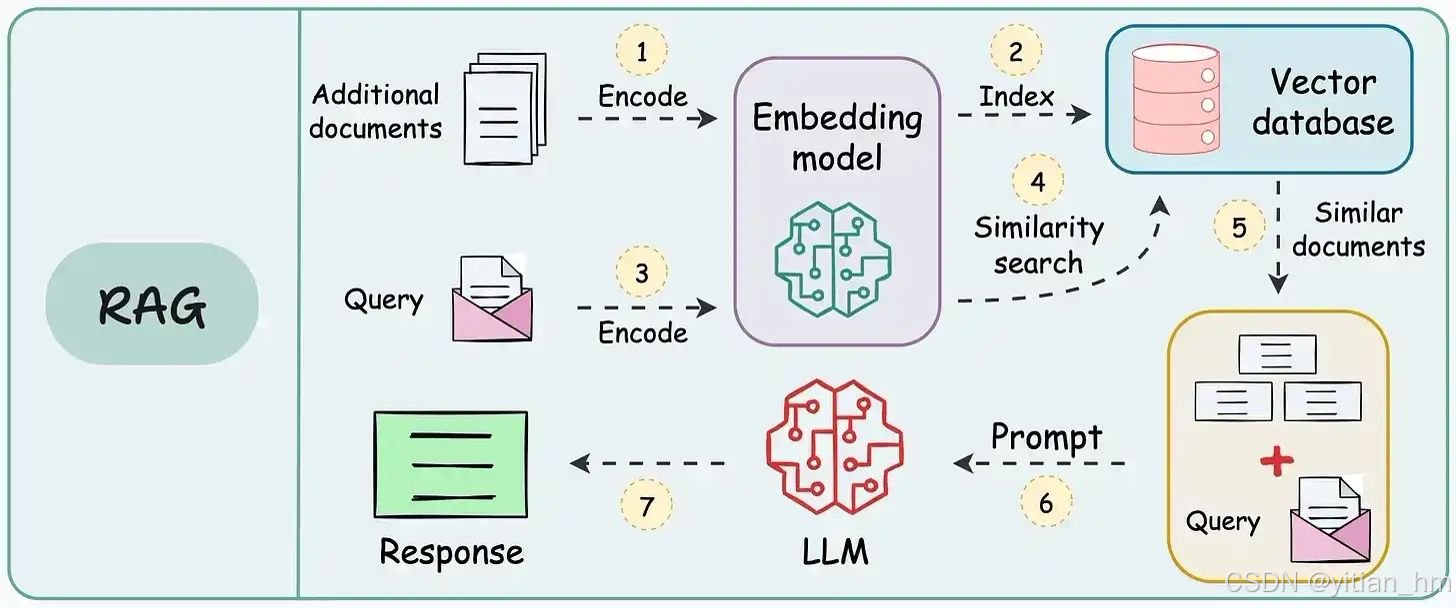
三、问题检索(RAG增强)
在纯大模型推理中,模型仅依赖训练时学到的参数来回答问题。但这会有问题:
- 模型的知识截止到训练时间
- 无法保证专业、实时的准确性
这时,RAG(Retrieval Augmented Generation) 就派上用场了。
RAG 的过程是:
- 将用户问题转化为向量(embedding)
- 在外部知识库里检索最相关的文档(比如数据库、公司资料、维基百科)
- 把检索到的内容拼接到原始问题中,再输入给大语言模型
例如:
- 用户问:“量子计算的基本原理是什么?”
- 系统把这个问题 embedding
- 去知识库里找到“量子叠加”、“量子纠缠”、“量子门操作”的文章
- 拼接后再输入模型,模型就能生成更权威的答案
📽 动态图片模拟(RAG检索阶段):
- 用户的问题变成一个向量点
- 在一个“图书馆”或“数据库”的空间中搜索相似点
- 搜索结果飞向模型大脑,和用户原始问题合并
- 最终形成一条“富含知识”的输入
四、文本生成
最后一步是 文本生成(Text Generation)。
大语言模型的核心逻辑是 预测下一个词的概率分布。
比如:输入 “量子计算的基本”,模型会预测下一个最可能的词:
- “原理” → 概率 0.68
- “应用” → 概率 0.21
- “定义” → 概率 0.07
模型选择概率最大的“原理”,然后继续预测下一个词,直到生成完整的答案。
这就像模型在玩一个“词接龙”的游戏,只不过它接词的方式是统计学上的最优预测。
在 RAG 的加持下,模型不仅依赖训练时的知识,还能用最新的文档来提升答案的准确性。
📽 动态图片模拟(文本生成阶段):
- 模型大脑里不断闪烁概率曲线
- 每次挑选一个最优词,像一颗颗“珠子”掉落
- 最终这些词拼接成一句完整的自然语言回答
五、结合 GPT-5 接口调用的示例
假设我们使用 OpenAI 的 GPT-5 API,来演示上面流程。
1. 普通调用(无 RAG)
from openai import OpenAI
client = OpenAI(api_key="your_api_key")
response = client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "user", "content": "请解释一下量子计算的基本原理"}
]
)
print(response.choices[0].message["content"])
此时,模型会根据内部知识来回答。
2. 加入 RAG 机制
在 RAG 框架下,调用方式通常是:
# Step 1: 用户问题 -> embedding
embedding = client.embeddings.create(
model="text-embedding-ada-002",
input="请解释一下量子计算的基本原理"
)
# Step 2: 检索外部知识库(伪代码)
docs = vector_database.search(embedding.vector, top_k=3)
# Step 3: 拼接文档
prompt = "基于以下资料回答问题:\n" + "\n".join(docs) + "\n\n用户问题: 请解释一下量子计算的基本原理"
# Step 4: 再调用 GPT-5
response = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": prompt}]
)
print(response.choices[0].message["content"])
这样,GPT-5 就能利用外部知识库来增强答案准确性,这就是 RAG 的完整推理过程。
六、总结
我们完整走了一遍大语言模型从 输入 → 语义分析 → 检索增强(RAG) → 文本生成 的过程:
- 用户输入内容:文本被切分成 token,转化为数字序列
- 模型内容语义分析:通过 Transformer 建立语义关系,映射到向量空间
- 问题检索(RAG):在外部知识库检索相关信息,增强模型回答
- 文本生成:预测下一个词的概率,逐步生成自然语言答案
理解了这个流程,你就能更清晰地知道 AI 是如何“思考”的:
它并不是真的有意识,而是通过复杂的概率计算和知识增强,来模拟“人类理解与推理”的过程。
未来,结合更强的 RAG、多模态(图像、语音、视频)和更快的推理引擎,GPT-5 以及后续模型将会更接近人类的认知方式。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐


 54
54 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)