
vue展现pdf文件
vue展现pdf文件
·
小小吐槽
接到一个小小需求,在pc端和手机端展现pdf,要求是完美展现pdf,pdf不能让用户下载,网上很多pdf的,我这里pc端用的是
iframe,在pc端没有问题,然后到了手机端如果是pdf文件就直接跳到下载去了,无法实现我的效果,手机端采用的是pdfjs-dist(强烈建议),在这期间我还用了其他的方法(具体的忘记了)反正效果没有实现,展现了pdf,但是效果不是很好(k可能是我当时没有看懂其他实现pdf的方法),我这里强烈建议pdfjs-dist
安装 pdfjs-dist
npm install --save pdfjs-dist@2.0.943
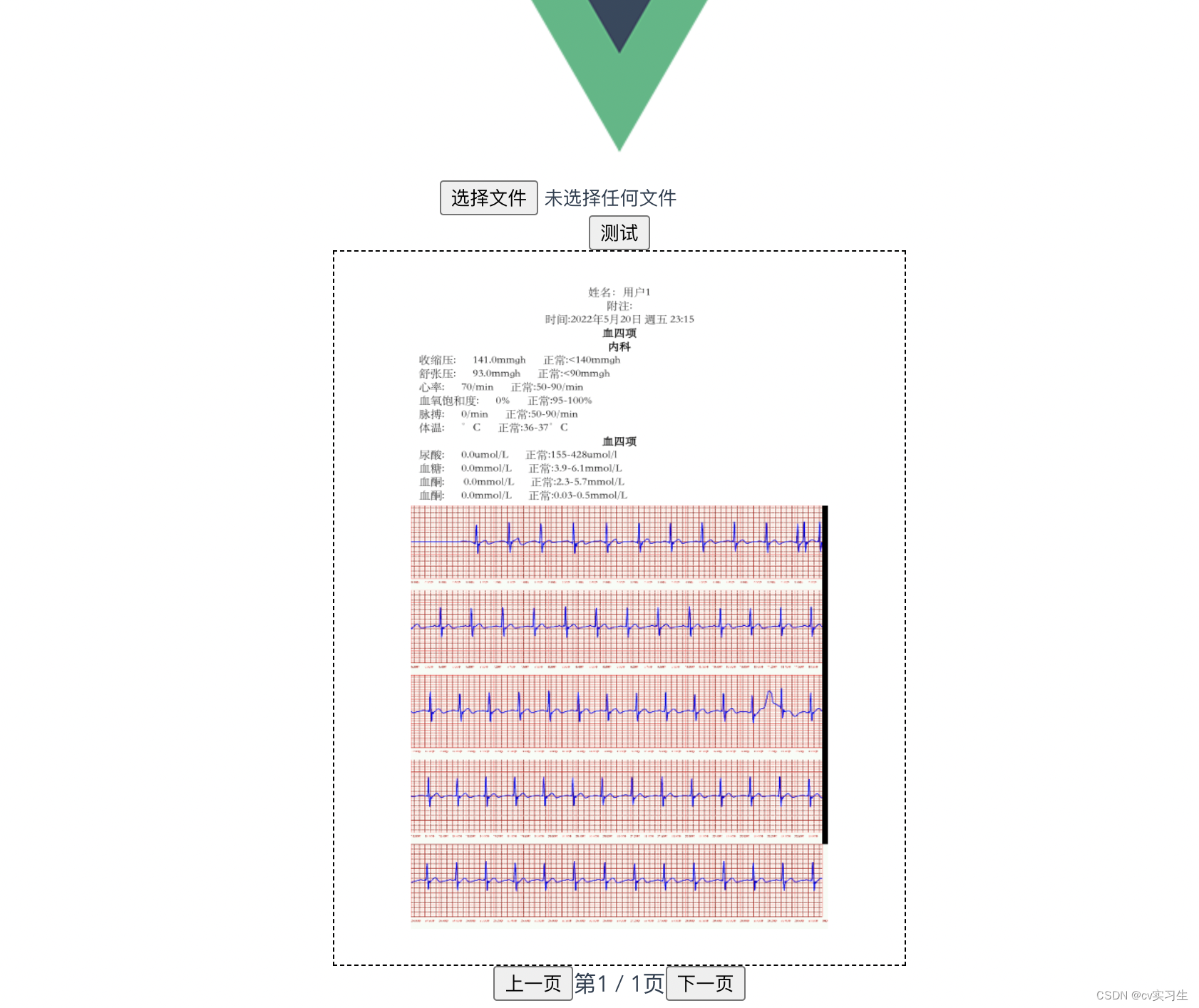
vue代码实现(图片展示)
<template>
<div class="main-container">
<input type="file" ref="fielinput" @change="uploadFile" />
<button @click="previous">测试</button>
<div class="canvas-container">
<canvas ref="myCanvas" class="pdf-container"> </canvas>
</div>
<div class="pagination-wrapper">
<button @click="clickPre">上一页</button>
<span>第{{ pageNo }} / {{ pdfPageNumber }}页</span>
<button @click="clickNext">下一页</button>
</div>
</div>
</template>
<script>
import * as pdfJS from 'pdfjs-dist';
//这里的文件在踩坑目录下,注意看下
import { getUint8Array } from "../baese64/getFile.js";
pdfJS.GlobalWorkerOptions.workerSrc = pdfJS;
export default {
mounted() {},
data() {
return {
pageNo: null,
pdfPageNumber: null,
pdfTotalPages: 1,
renderingPage: false,
pdfData: null, // PDF的base64
scale: 1, // 缩放值
};
},
methods: {
//这个是我本地测试将文件转换为base64
uploadFile() {
let inputDom = this.$refs.fielinput;
console.log("inputDom",inputDom);
let file = inputDom.files[0];
let reader = new FileReader();
reader.readAsDataURL(file);
reader.onload = () => {
let data = atob(
reader.result.substring(reader.result.indexOf(",") + 1)
);
this.loadPdfData(data);
};
},
previous() {
// 请求参数
this.$ajax
.post("http://172.28.233.159:8081/getBase?fileName=" + "测试")
.then((res) => {
var data = getUint8Array(res.data.data);
this.loadPdfData(data);
});
},
loadPdfData(data) {
// 引入pdf.js的字体,如果没有引用的话字体会不显示
let CMAP_URL = "https://unpkg.com/pdfjs-dist@2.0.943/cmaps/";
//读取base64的pdf流文件
this.pdfData = pdfJS.getDocument({
data: data, // PDF base64编码
cMapUrl: CMAP_URL,
cMapPacked: true,
});
console.log(this.pdfData);
this.renderPage(1);
this.renderScrollPdf();
},
// 根据页码渲染相应的PDF
renderPage(num) {
this.renderingPage = true;
this.pdfData.promise.then((pdf) => {
this.pdfPageNumber = pdf.numPages;
pdf.getPage(num).then((page) => {
// 获取DOM中为预览PDF准备好的canvasDOM对象
let canvas = this.$refs.myCanvas;
let viewport = page.getViewport(this.scale);
canvas.height = viewport.height;
canvas.width = viewport.width;
let ctx = canvas.getContext("2d");
let renderContext = {
canvasContext: ctx,
viewport: viewport,
};
page.render(renderContext).then(() => {
this.renderingPage = false;
this.pageNo = num;
});
});
});
},
clickPre() {
if (!this.renderingPage && this.pageNo && this.pageNo > 1) {
this.renderPage(this.pageNo - 1);
}
},
clickNext() {
if (
!this.renderingPage &&
this.pdfPageNumber &&
this.pageNo &&
this.pageNo < this.pdfPageNumber
) {
this.renderPage(this.pageNo + 1);
}
},
renderScrollPdf() {
this.pdfData.promise.then((pdf) => {
this.pdfTotalPages = pdf.numPages;
this.renderScrollPdfPage(1);
});
},
},
};
</script>
<style scoped>
.main-container {
display: flex;
flex-direction: column;
align-items: center;
}
.canvas-container {
width: 400px;
height: 500px;
border: 1px dashed black;
position: relative;
display: flex;
justify-content: center;
}
.scroll-pdf-contanier {
width: 400px;
height: 500px;
border: 1px dashed black;
position: relative;
display: flex;
flex-direction: column;
overflow-y: scroll;
}
.pdf-container {
width: 100%;
height: 100%;
}
.scroll-pdf-container {
width: 350px;
}
.pagination-wrapper {
display: flex;
justify-content: center;
align-items: center;
}
</style>
PC 端点击测试

手机端点击测试

java将pdf转换为base64
JDK8
package com.java.util;
import sun.misc.BASE64Encoder;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
public class PDFFileUtils {
/**
* 方法名: PDFToBase64
* 方法功能描述: 将pdf文件转换为Base64编码
* @param: String sourceFile:源文件路径
* @return: String base64字符串
* @Author: Leiwen
* @Create Date: 2022年12月03日
*/
public static String PDFToBase64(String sourceFile) {
BASE64Encoder encoder = new BASE64Encoder();
FileInputStream fin =null;
BufferedInputStream bin =null;
ByteArrayOutputStream baos = null;
BufferedOutputStream bout =null;
File file = new File(sourceFile);
try {
fin = new FileInputStream(file);
bin = new BufferedInputStream(fin);
baos = new ByteArrayOutputStream();
bout = new BufferedOutputStream(baos);
byte[] buffer = new byte[1024];
int len = bin.read(buffer);
while(len != -1){
bout.write(buffer, 0, len);
len = bin.read(buffer);
}
//刷新此输出流并强制写出所有缓冲的输出字节
bout.flush();
byte[] bytes = baos.toByteArray();
return encoder.encodeBuffer(bytes).trim();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
fin.close();
bin.close();
bout.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
public static String getImgUrlToBase64(String imgUrl) {
InputStream inputStream = null;
ByteArrayOutputStream outputStream = null;
byte[] buffer = null;
try {
// 创建URL
URL url = new URL(imgUrl);
// 创建链接
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5000);
inputStream = conn.getInputStream();
outputStream = new ByteArrayOutputStream();
// 将内容读取内存中
buffer = new byte[1024];
int len = -1;
while ((len = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, len);
}
buffer = outputStream.toByteArray();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (inputStream != null) {
try {
// 关闭inputStream流
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (outputStream != null) {
try {
// 关闭outputStream流
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 对字节数组Base64编码
return new BASE64Encoder().encode(buffer);
}
public static void main(String[] args) {
// String s = PDFToBase64("/Users/leiwen/Downloads/测试011.pdf");
// System.out.println(s);
String imgUrlToBase64 = getImgUrlToBase64("/Users/leiwen/Downloads/测试011.pdf");
System.out.println(imgUrlToBase64);
}
}
注意点
JDK如果是8的话能正常使用BASE64Encoder
JDK11的话这个就被弃用了,我另外一台电脑用的是11,用的maven资源 是如下,效果跟BASE64Encoder一样
<dependency>
<groupId>org.apache.directory.studio</groupId>
<artifactId>org.apache.commons.codec</artifactId>
<version>1.8</version>
</dependency>
JDK11
package com.java.util;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Map;
import org.apache.commons.codec.binary.Base64;
public class PDFFileUtils {
/**
* 方法名: PDFToBase64
* 方法功能描述: 将pdf文件转换为Base64编码
* @param: String sourceFile:源文件路径
* @return: String base64字符串
* @Author: Leiwen
* @Create Date: 2022年11月09日
*/
public static String PDFToBase64(String sourceFile) {
Base64 encoder = new Base64();
FileInputStream fin =null;
BufferedInputStream bin =null;
ByteArrayOutputStream baos = null;
BufferedOutputStream bout =null;
File file = new File(sourceFile);
try {
fin = new FileInputStream(file);
bin = new BufferedInputStream(fin);
baos = new ByteArrayOutputStream();
bout = new BufferedOutputStream(baos);
byte[] buffer = new byte[1024];
int len = bin.read(buffer);
while(len != -1){
bout.write(buffer, 0, len);
len = bin.read(buffer);
}
//刷新此输出流并强制写出所有缓冲的输出字节
bout.flush();
byte[] bytes = baos.toByteArray();
return encoder.encodeBase64String(bytes).trim();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
fin.close();
bin.close();
bout.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
public static void main(String[] args) {
// String s = PDFToBase64("/Users/leiwen/Downloads/测试011.pdf");
// System.out.println(s);
}
}
踩坑
我一开始的思路是将后台的base64转给前端,然后转成文件,再转换成base64,因为前台的文件转base64再转pdf能够实现,然后我后台转的再前台转换失败,好像是因为文件在后台转换的base64和文件在前台转换的base64有一协议啥的,转换不了
/**
* 简介:将base64 格式的字符串转换成 uint8Array (pdf.js 无法直接接受base64 格式的参数)
* 参数:base64_string(pdf格式的电子发票经过base64处理的字符串)
* return:Array
*/
export const getUint8Array = (base64Str) =>{
let data = base64Str.replace(/[\n\r]/g, ''); // 替换多余的空格和换行
var raw = window.atob(data);
var rawLength = raw.length;
var array = new Uint8Array(new ArrayBuffer(rawLength));
for (var i = 0; i < rawLength; i++) {
array[i] = raw.charCodeAt(i)
}
return array
}

基于 Vue 的企业级 UI 组件库和中后台系统解决方案,为数万开发者服务。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)