吴恩达机器学习笔记(九)——大规模机器学习
大规模机器学习1 大规模机器学习可行性由之前机器学补充里的知识可知,有的时候并不是数据越多对算法越好,当方差偏小的时候,说明此时的拟合度会比较大,数据缺乏泛性,这个时候使用更大的数据集可能会对算法有帮助。这个时候,我们可以绘制学习曲线,根据学习曲线判断是否需要更...
大规模机器学习
1 大规模机器学习可行性
由之前机器学补充里的知识可知,有的时候并不是数据越多对算法越好,当方差偏小的时候,说明此时的拟合度会比较大,数据缺乏泛性,这个时候使用更大的数据集可能会对算法有帮助。
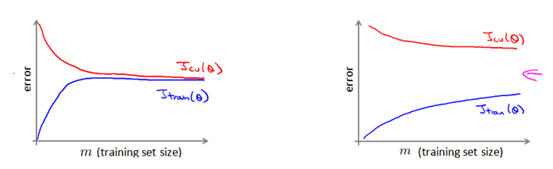
这个时候,我们可以绘制学习曲线,根据学习曲线判断是否需要更加大规模的数据。
2 大规模机器学习

观察线性回归的算法可知,当算法运行的时候,计算量最大的部分往往是对代价函数偏导,尤其是当数据集的大小很大的时候(也就是意味着m很大)其相应的算法的时间复杂度也会增加。也就是说我们针对大规模的机器学习进行优化的时候,主要着手的点也就是这一个环节。
3 随机梯度下降法

由微积分的知识可知,求偏导这一步骤住要就是为了确立,梯度下降的方向,因为最终的代价函数是由所有数据集和其对应的标签决定的。随机梯度下降法则是只选取数据集中的一个数据来进行梯度下降的方向确认。
4 小批度随机下降
由于上述描绘的普通梯度下降以及随机梯度下降的特点,我们综合两者,得出校批量随机下降的方法。
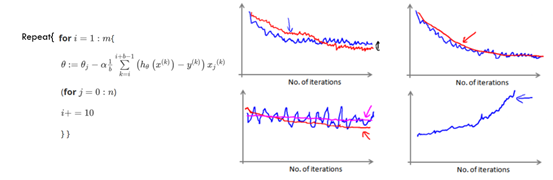
在随机梯度下降中,我们在每一次更新θ之前都计算一次代价,然后每x次迭代后,求出这x次对训练实例计算代价的平均值,然后绘制这些平均值与x次迭代的次数之间的函数图表。
5 在线学习
例:假使我们正在经营一家物流公司,每当一个用户询问从地点A到地点B的快递费用时,我们给用户一个报价,该用户可能选择接受(y=1)或不接受(y=0)。现在希望构建一个模型,来预测用户接受报价使用我们的物流服务的可能性。因此报价是我们的一个特征,其他特征为距离,起始地点,目标地点以及特定的用户数据。模型的输出是:

在线学习和随机梯度下降法比较象,但是不同的是,在线学习是一个动态的、无止境的不断迭代过程。
6 映射化简和数据并行
如果任何学习算法能够表达为,对训练集的函数的求和,那么便能将这个任务分配给多台计算机(或者同一台计算机的不同CPU 核心),以达到加速处理的目的。
例:

这里就是结合硬件出发,对于大规模机器学习的一种解决方法。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)