机器学习——NLP
机器学习的几个基本概念在机器学习和模式识别等领域中,一般需要将样本分成独立的三部分训练集(train set),验证集(validation set ) 和测试集(test set)。其中训练集用来估计模型,验证集用来确定网络结构或者控制模型复杂程度的参数,而测试集则检验最终选择最优的模型的性能如何。一个典型的划分是训练集占总样本的50%,而其它各占25%,三部分都是从样本中随机抽取。训练集:..
机器学习的几个基本概念
在机器学习和模式识别等领域中,一般需要将样本分成独立的三部分训练集(train set),验证集(validation set ) 和测试集(test set)。其中训练集用来估计模型,验证集用来确定网络结构或者控制模型复杂程度的参数,而测试集则检验最终选择最优的模型的性能如何。一个典型的划分是训练集占总样本的50%,而其它各占25%,三部分都是从样本中随机抽取。训练集:
确定模型后,用于训练参数,注意训练的是普通参数(每多加入一个数据对模型进行训练,模型中就会受到影响的参数,通过多次迭代不断更新,是一个梯度下降的过程)而不是超参数(超参数是指训练开始之前设置的参数,超参数的选择与训练过程实际上是独立的,训练过程不会影响超参数。但是训练结束后可以根据训练结果考虑超参数是否可优化,可优化的话就调整超参数的值开始下一次训练)
验证集(交叉验证集CV):
用训练集对模型训练完毕后,再用验证集对模型测试,测试模型是否准确而不是训练模型的参数。
测试集:
虽然验证集没有对模型的参数产生影响,但是我们却根据验证集的测试结果的准确度来调整参数,所以验证集对结果还是有影响的,即使得模型在验证集上达到最优。就是在很多个模型中,验证集选择了代价函数最小的一个模型。虽然在这个模型上代价很小,但并不代表在其他数据上代价也小。所以需要一个完全没有经过训练的测试集来再最后测试模型的准确率。
那么机器学习的简单流程如下:

加入测试集后,流程如下:

加入验证集后,流程如下:

机器学习分为监督学习、无监督学习、半监督学习,其中半监督学习相当于监督学习和无监督学习的有机结合。主要看一下什么时监督学习,以及什么是无监督学习。
监督学习:
监督学习是指用带有label的样本数据训练model的一种机器学习模式。这里的label其实很好理解,就是某个样本数据的类别,也就是说每个样本数据属于哪一类是已知的,model学习的是数据和它的label。而监督学习要做的工作是,对没有label的测试样本数据赋予label或者赋予其属于某label的概率。
监督学习一般应用在专家经验丰富、可以人为对训练数据贴label的场合,比如要做一个区别苹果和橙子的识别系统就可以用监督学习,因为我们知道苹果和橙子长什么样,区别是什么,自然可以轻易贴label。监督学习的算法主要有SVM、KNN、神经网络、逻辑回归logistic regression等。
无监督学习:
无监督学习则与监督学习相反,它是指用无label的样本数据训练model的一种机器学习模式。也就是说在训练model前每个样本数据属于哪一类是不知道的,但是无监督学习同样可以进行测试数据的分类工作,model可以度量每个无label数据间的差异从而根据其差异大小进行分类,至于分成几类、每类是什么model不关心,但是可以人为设置。
无监督学习一般应用在缺乏专家经验的场合,最经典的算法就是聚类,而我们平时常见的推荐系统、信息检索就是用聚类做成的。
NLP
自然语言处理(Natural Language Processing,NLP)是一门集语言学,数学及计算机科学于一体的科学。它的核心目标就是把人的自然语言转换为计算机可以阅读的指令,简单来说就是让机器读懂人的语言。 NLP是人工智能领域一个非常重要的分支,其它重要分支包括计算机视觉,语音及机器学习和深度学习等。那么,NLP与机器学习,深度学习有什么关系呢?我们可以用下面的图来表示。可以看出,深度学习是机器学习的其中一个分支,而自然语言处理与机器学习之间是并行的,机器学习为自然语言处理提供了解决问题的许多模型和方法。所以,二者之间具有密不可分的关系。
下面看以下NLP的应用场景
文本相似度分析
文本相似度分析:从海量数据(文章,评论)中,把相似的数据挑选出来。
其具体步骤如下:
- 把评论翻译成机器看的懂的语言
- 使用机器看的懂得算法轮询去比较每一条和所有评论的相似程度
- 把相似的评论挑出来
首先如何把文字翻译成机器看的懂的语言呢?
- 分词
- 制作词袋模型(bag-of-word)
- 用词袋模型制作语料库(corpus)
- 把评论变成词向量
分词就是把一个完整的句子分成好多个词汇。Python中有一个jieba库,就是专门用来处理中文的库,其中的cut方法就可以实现分词。如下图所示:

下面看一个利用jieba库分词的例子代码, 代码如下:
#encoding: utf-8
import jieba
"""
结巴中文分析支持的三种分词模式包括
(1)精确模式:试图将句子最精确的切开,适合文本分析(默认模式)
(2)全模式:把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义问题
(3)搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜素引擎分词
"""
# 全模式
text = "我来到北京清华大学"
seg_list = jieba.cut(text, cut_all=True)
print("全模式:", "/ ".join(seg_list))
# 精确模式
seg_list = jieba.cut(text, cut_all=False)
print("精确模式: ", "/ ".join(seg_list))
# 搜索引擎模式
seg_list = jieba.cut_for_search(text)
print("搜索引擎模式: ", "/ ".join(seg_list))
"""
添加自定义词典
"""
jieba.load_userdict('./mydict.txt')
text2 = "故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
seg_list = jieba.cut(text2, cut_all=True)
print("全模式:", "/ ".join(seg_list))
seg_list = jieba.cut(text2, cut_all=False)
print("精确模式: ", "/ ".join(seg_list))
seg_list = jieba.cut_for_search(text2)
print("搜索引擎模式: ", "/ ".join(seg_list))
输出结果如下:

制作词袋模型就是把分开的词汇分别编号,转成字典的形式,其中关键字是分词,value值是对应的编号,如下图所示:

然后再制作语料库。就是将所有的句子都专成词袋模型,就是将词汇变成元组的形式,元组中的第一个数表示编号,第二个数表示该词汇出现的次数,如下图所示:

然后再将句子变成词向量,即列表中都是分词出现的次数,这样就将句子转成了机器可以识别的语言了,如下图所示:

然后是文本相似度分析的第二步,使用机器看的懂得算法轮询去比较每一条和所有评论的相似程度。
这里用到了TF-IDF寻找关键词,TF代表词频,IDF代表逆文本频率。
- 不考虑停用词(就是没什么意义的词),找出一句话中出现次数最多的单词,来代表这句话,这个就叫做词频(TF – TermFrequency),相应的权重值就会增高
- 如果一个词在所有句子中都出现过,那么这个词就不能代表某句话,这个就叫做逆文本频率(IDF -Inverse Document Frequency)相应的权重值就会降低
- TF-IDF = TF * IDF
TF公式:
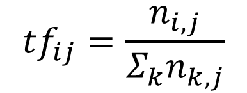
其中ni,j是该词在一份文件(或评论)中出现的次数,分母则是一份文件(或评论)中所有词汇出现的次数总和。
也就是:

IDF公式:
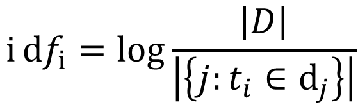

也就是:

下面编写一个文本相似度分析的代码,其中用到了测试评论库,代码如下:
#encoding: utf-8
import jieba
from gensim import corpora, models, similarities
import csv
limitLine = 10
count = 0
all_doc_list = []
with open("./ChnSentiCorp_htl_all.csv", 'r', encoding='UTF-8') as f:
reader = csv.reader(f)
for row in reader:
if count == 0:
count += 1
continue
if count > limitLine: break
comment = list(jieba.cut(row[1], cut_all=False))
all_doc_list.append(list(comment))
count += 1
# print(all_doc_list)
"""
制作语料库
"""
# 制作词袋(bag-of-words)
dictionary = corpora.Dictionary(all_doc_list)
print(dictionary.keys())
print(dictionary.token2id)
# 制作语料库
corpus = [dictionary.doc2bow(doc) for doc in all_doc_list]
print(corpus)
# 测试文档转化:
# doc_test = "服务很热情,交通也很便利,下次如果去北京我还会选择这家酒店!"
doc_test = "商务大床房,房间很大,床有5M宽,整体感觉经济实惠不错!"
dic_test_list = [word for word in jieba.cut(doc_test)]
doc_test_vec = dictionary.doc2bow(dic_test_list)
print("doc_test_vec: ", doc_test_vec)
"""
相似度分析
"""
tfidf = models.TfidfModel(corpus)
# 获取测试文档中,每个词的TF-IDF值
print("tf_idf 值: ", tfidf[corpus])
# 对每个目标文档,分析要测试文档的相似度
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=len(dictionary.keys()))
print("index: ", index)
sim = index[tfidf[doc_test_vec]]
print("sim:", sim)
sim_sorted = sorted(enumerate(sim), key=lambda item: -item[1])
print(sim_sorted)
输出结果如下:


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)