

GMM及EM算法
标签(空格分隔): 机器学习
前言:
- EM(Exception Maximizition) -- 期望最大化算法,用于含有隐变量的概率模型参数的极大似然估计;
- GMM(Gaussian Mixture Model) -- 高斯混合模型,是一种多个高斯分布混合在一起的模型,主要应用EM算法估计其参数;
- 本篇博客首先从简单的k-means算法给出EM算法的迭代形式,然后用GMM的求解过程给出EM算法的宏观认识;最后给出EM的标准形式,并分析EM算法为什么收敛。
K-Means Clustering
目标函数(损失函数)
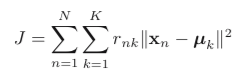
EM过程
- 随机初始化样本中心点,即均值\(\mu_{k}\).
- E step: 固定均值\(\mu_{k}\),用\(r_{n}k\)最小化目标函数J。
- M step: 固定\(r_{n}k\),用\(\mu_{k}\)最小化目标函数J。
- 不断迭代,直至收敛。
Gaussian Mixture Model
将高斯混合模型看成是高斯分量的简单线性叠加,目标是提供一类比单独高斯分布更强大的概率模型。
- 假设有K个高斯分布构成了数据X,则其概率分布为:
\(p(x) = \sum_{k=1}^{K}\pi_{k}N(x|\mu_{k},\Sigma_{k})\).
其中,数据点x属于第k个高斯分布的概率为\(\pi_{k}\),则有$0\leq \pi_{k} \leq 1, \sum_{k=1}^{K}\pi_{k} = 1 $ - x的边缘概率分布为\(p(x) = \sum_{k=1}^{K}\pi_{k}N(x|\mu_{k},\Sigma_{k})\)
对数似然函数为:
\(\ln P(X|\pi,\mu,\Sigma) = \sum_{n=1}^{N}\ln\{\sum_{k=1}^{K}\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k})\}\)
其中,\(N(x_{n}|\mu_{k},\Sigma_{k}) =\frac{1}{(2\pi)^{\frac{D}{2}}|\Sigma|^{\frac{1}{2}}}exp\{-\frac{1}{2}(x_{n}-\mu_{k})^{T}\Sigma_{k}^{-1}(x_{n}-\mu_{k})\}\)
关于\(\mu_{k}\)使对数似然函数最大:
\(\frac{\partial P(X|\pi_{k},\mu_{k},\Sigma_{k})}{\partial\mu_{k}} = \sum_{n=1}^{N}\frac{\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k})(-\frac{1}{2}*2*\Sigma_{k}^{-1}(x_{n}-\mu_{k}))}{\sum_{j}\pi_{j}N(x_{n}|\mu_{j},\Sigma_{j})} \\ = -\sum_{n=1}^{N}\frac{\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|\mu_{j},\Sigma_{j})}\Sigma_{k}^{-1}(x_{n}-\mu_{k}) = 0\)
两边同时乘以\(\Sigma_{k}\),
记\(\gamma(z_{n}k) = \frac{\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|\mu_{j},\Sigma_{j})}\)得:
\(\mu_{k} = \frac{1}{\sum_{n=1}^{N}\gamma(z_{n}k)}\sum_{n=1}^{N}\gamma(z_{n}k)·x_{n}\)
关于\(\Sigma_{k}\)使对数似然最大:
\(\Sigma_{k} = \frac{1}{\sum_{n=1}^{N}\gamma(z_{n}k)}\sum_{n=1}^{N}\gamma(z_{n}k)(x_{n}-\mu_{k})(x_{n}-\mu_{k})^{T}\)
关于混合系数\(\pi_{k}\)使对数似然函数最大:
由于所有混合系数的和为1,即满足\(\sum_{k=1}^{K}\pi_{k} = 1\),则原来的最大似然问题变为带约束条件的似然函数最大化,使用Lagrange乘子法:
\(max \ln P(X|\pi,\mu,\Sigma) + \lambda(\sum_{n=1}^{N}\pi_{k} - 1)\)
对\(\pi_{k}\)求偏导,令导数为0:
$0 = \sum_{n=1}^{N}\frac{N(x_{n}|\mu_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|\mu_{j},\Sigma_{j})} + \lambda $
两边同乘\(\pi_{k}\),得
\(0 = \sum_{n=1}^{N}\frac{\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|\mu_{j},\Sigma_{j})} + \lambda·\pi_{k}\ \ \ \ (*)\)
对k = 1,..,K求和,得:
\(\sum_{n=1}^{N}\sum_{k=1}^{K}\gamma(z_{n}k) + \lambda = 0\),
所以\(\lambda = -N\),代入(*)式,得:
\(\pi_{k} = \frac{\sum_{n=1}^{N}\gamma(z_{n}k)}{N}\)
Exception Maximizition
期望最大化EM算法的标准形式:
- E-step:来自第j个组份的概率
- \(x_{j}^{i} = Q_{i}(z_{i} = j) = p(z^{i} = j | x^{i};\Phi, \mu, \Sigma)\)
- S-step:估计每个组份的参数。
- \(\sum_{i=1}^{m}\sum_{z^{(i)}}Q_{i}(z^{(i)})log\frac{P(x^{i},z^{i};\Phi,\mu\Sigma)}{Q_{i}(z^{(i)})}\)
EM process:
Initilization:
First, choose some initial values for the means \(\mu\{\mu_{1}, \mu_{2},...,\mu_{K}\}\), covariances \(\Sigma\{\Sigma_{1},\Sigma_{2},...,\Sigma_{K}\}\), and mixing coefficients \(\pi\{\pi_{1},\pi_{2},...,\pi_{K}\}\).
E-Step:
Use the current values for the parameters \(\mu, \Sigma, \pi\) to evaluate the posterior probabilities, or responsibilities \(\gamma(z_{n}k) = \frac{\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|\mu_{j},\Sigma_{j})}\);
M-step:
Re-estimate the means \(\mu\), covariances \(\Sigma\), and mixing coefficients \(\pi\) using the results:
\(\mu_{k} = \frac{1}{\sum_{n=1}^{N}\gamma(z_{n}k)}\sum_{n=1}^{N}\gamma(z_{n}k)·x_{n}\)
\(\Sigma_{k} = \frac{1}{\sum_{n=1}^{N}\gamma(z_{n}k)}\sum_{n=1}^{N}\gamma(z_{n}k)(x_{n}-\mu_{k})(x_{n}-\mu_{k})^{T}\)
\(\pi_{k} = \frac{\sum_{n=1}^{N}\gamma(z_{n}k)}{N}\)
Evaluate the log likelihood
\(\ln P(X|\pi,\mu,\Sigma) = \sum_{n=1}^{N}\ln\{\sum_{k=1}^{K}\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k})\}\)
and check for convergence of either the parameters or the log likelihood.
隐变量的视角解释GMM
有时模型内既存在观测变量(observable variable),又存在隐变量(latent variable). 当存在隐变量时,直接使用极大似然法或者贝叶斯估计模型参数就比较困难。而EM算法的目标是找到具有潜在变量的模型的最大似然解。
图模型:
- 记所有的观测数据的集合为\(X = {x_{1}, x_{2}, ..., x_{n}}\), 所有隐变量的集合为\(Z = {z_{1}, z_{2}, ..., z_{k}}\),模型所有参数的集合为\(\theta\).
则对数似然函数为:
\(\ln p(X|\theta) = \ln\{\sum_{z} p(X, Z|\theta) \}\); - 但是由于对数似然内部存在求和符号,所以一般情况下边缘概率分布\(p(X|\theta)\)一定不是指数族函数,从而使得对数似然的形式变复杂了;
- 将\(\{X, Z\}\)数据集称为完全(complete)数据集,称实际观测数据集\(\{X\}\)为不完全(incomplete)数据集.一般我们所拥有的数据集只有不完全数据集。
- E-step: 使用当前的参数\(\theta^{old}\)计算隐变量的后验概率\(p(Z|Z, \theta^{old})\),然后计算完全数据(X,Z)对数似然对于参数值\(\theta\)的期望:
\(Q(\theta, \theta^{old}) = \sum_{z}p(Z|X,\theta^{old})\ln p(X, Z|\theta)\); - M-step: 通过最大化Q函数更新模型参数\(\theta\):
\(\theta^{new} = argmax_{\theta}Q(\theta, \theta^{old})\)
### 引入隐变量z
用1-of-K的形式表示K维的二元随机变量z,\(z_{k} \in \{0, 1\} 并且 \sum_{k=1}^{K} = 1\),则\(p(z_{k} = 1) = \pi_{k}\),
- z的概率分布可以表示为:\(p(z) = \Pi_{k=1}^{K}\pi_{k}^{z_{k}}\);
- 在给定隐变量z的条件下x的条件概率分布为:\(p(x|z) = \Pi_{k=1}^{K}N(x|\mu_{k}, \Sigma_{k})^{z_{k}}\)
- 完全数据(X,Z)的似然函数为:\(p(X,Z|\pi,\mu,\Sigma) = P(X|Z,\pi,\mu,\Sigma)·P(Z|\pi,\mu,\Sigma)\\ = \Pi_{n=1}^{N}\Pi_{k=1}^{K}\pi_{k}^{z_{n}k}N(x_{n}|\mu_{k},\Sigma_{k})^{z_{n}k}\)
- 完全数据(X,Z)取对数,得到对数似然:
\(\ln P(X,Z|\pi,\mu,\Sigma) = \sum_{n=1}^{N}\sum_{k=1}^{K}z_{nk}(\ln\pi_{k} + \ln N(x_{n}|\mu_{k}, \Sigma_{k})) \ \ \ \ \ (1)\) 不完全数据(X)的对数似然为:
\(\ln P(X|\pi,\mu,\Sigma) = \sum_{n=1}^{N}\ln\{\sum_{k=1}^{K}\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k})\} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (2)\)对比完全数据的对数似然函数(1)式和不完全数据的对数似然(2)式,可以发现,对于(1)式,log运算放到了里面,而高斯分布是指数族函数,所以大大简化了计算量。
- 计算隐变量z的条件概率:\(p(Z|X,\pi,\mu,\Sigma) = \frac{p(Z,X|\pi,\mu,\Sigma)}{p(X|\pi,\mu,\Sigma)} \\ = \Pi_{n=1}^{N}\Pi_{k=1}^{K}[\pi_{k}N(x_{n}|\mu_{k},\Sigma_{k})]^{z_{n}k}\)
对\(z_{n}k\)求期望:

Exception Maximizition Algorithm
Input: Observed variables X, latent variables Z, parameters \(\theta\), and joint distribution \(p(X,Z|\theta)\).
Goal: maxizimize the likelihood function \(p(X|\theta)\).
Output: parameters \(\theta\).
- Choose an initial setting for the parameters \(\theta^{old}\).
- E step Calculate \(Q(\theta, \theta^{old}) = \sum_{z}p(Z|X,\theta^{old})\ln p(X,Z|\theta)\).
- M step Evaluate \(\theta^{new}\) given by \(\theta^{new} = argmax_{\theta}Q(\theta, \theta^{old})\).
- Check for convergence of either the log likelihood or the parameter values.
GMM与K-Means的关系
K-Means对数据点进行了硬分配,即每个数据点只属于唯一的聚类;
而GMM应用EM算法,进行了软分配。
- 考虑一个GMM,设所有混合分量的协方差矩阵为\(\epsilon I\),则
\(p(x|\mu_{k},\Sigma_{k}) = \frac{1}{(2\pi\epsilon)^{\frac{D}{2}}}exp\{-\frac{1}{2\epsilon}||x - \mu_{k}||^{2} \}\) - 一个数据点属于一个分量的responsibility为:
- 当\(\epsilon \to 0\), 分子分母中只有当某项\(||x_{n} - \mu_{j}||^{2} \to 0\)时,整个式子的极限才存在。因此在这种极限情况下,GMM会将一个数据点分配给距它最近的那个中心点所在的簇类中。
- 当\(\epsilon \to 0\),完全数据的对数似然函数为:
- 这就退化为K-means的损失函数(目标函数)。
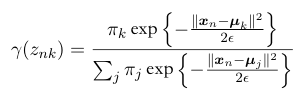
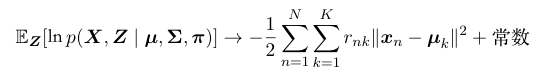
因此,K-means没有估计聚类的协方差,只是估计了聚类的均值。当GMM的方差取极限时,就退化成了k-means算法。
K-means是GMM的方差取为0的极限情况。
Exception Maximizition
期望最大化EM算法的标准形式:
- E-step:来自第j个组份的概率
- \(x_{j}^{i} = Q_{i}(z_{i} = j) = p(z^{i} = j | x^{i};\Phi, \mu, \Sigma)\)
- S-step:估计每个组份的参数。
- \(\sum_{i=1}^{m}\sum_{z^{(i)}}Q_{i}(z^{(i)})log\frac{P(x^{i},z^{i};\Phi,\mu\Sigma)}{Q_{i}(z^{(i)})}\)
为什么EM算法是可以收敛的
EM算法,是寻找具有潜在变量的概率模型的最大似然解的一种通用的方法.所以,在含有隐变量z的情况下,我们的目标是:最大化似然函数:
\(p(X|\theta) = \sum_{z}p(X, Z|\theta)\)
- 直接优化\(p(X|\theta)\)是困难的,但是优化完整数据的似然\(p(X, Z|\theta)\)就容易的多。
所以,我们引入隐变量的分布\(q(z)\),将似然函数取对数,总能化简成如下形式:
因为KL散度总是大于等于0,所以\(L(q,\theta)\)可以看做是对数似然的下界。因此EM算法的思想就是:找到似然函数的一个下界,用这个简单的下界来逼近最终的对数似然。
E step: 保持\(\theta\)固定,\(L(q,\theta^{old})\)关于q(z)的最大化。实际是求对z的期望。如下图所示,期望为:当\(KL(q||p) = 0\)(即p = q)时,\(L(q,\theta^{old})\)与对数似然相等。
M step: 保持\(q(z)\)固定,更新参数\(\theta\),使得\(L(q,\theta^{old})\)关于\(\theta\)求最大值。对每个参数求偏导,然后令偏导为0. 由于\(KL(q||p) > 0\), 因此\(\ln p(X|\theta)\)增加量一定大于其下界\(L(q,\theta)\)的增大量。
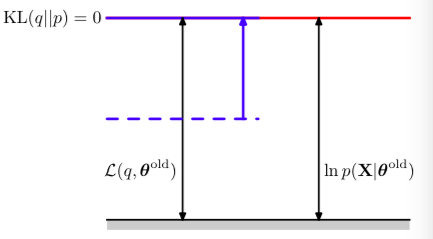
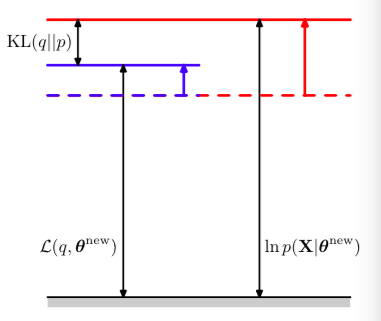
- 通过E step 和 M step不断迭代的过程,如果目标不完全数据的对数似然\(\ln p(X|\theta)\)存在最大值,则EM算法一定能够找到。
- EM算法对参数初值的选择是敏感的,不同的参数往往会收敛到不同的结果。因此在实际应用中,应该设置几组参数,然后选择一组最好的结果。
关于EM算法导出的几点说明
- 在[李航,2012]中,使用\(\ln(\theta) - \in(\theta^{old})\)推导出似然函数的下界。然后每次迭代用下界逼近似然的极大值;
- 在PRML中,将完全数据的似然函数\(L(Z,X|\theta)\)拆分为 下界 + \(KL(q||p)\)的形式,依然是使用下界逼近目标函数的极大值。
[参考文献]
1 M. Jordan, J. Kleinberg, ect. Pattern Recognition and Machine Learning. 2006
2 李航,统计学习方法,清华大学出版社,2012.







 已为社区贡献2条内容
已为社区贡献2条内容

{kind=link}
所有评论(0)