
方差分析(1) ——单因素方差分析及Excel示例
文章目录什么是方差分析建立假设[^mcp]检验统计量偏差平方和均方F检验统计量使用Excel进行方差分析结果说明什么是方差分析Wikipedia:Analysis of variance (ANOVA) is a collection of statistical models used to analyze the differences among group means and th...
什么是方差分析
Wikipedia:
Analysis of variance(ANOVA) is a collection of statistical models used to analyze the differences among group means and their associated procedures (such as “variation” among and between groups), developed by statistician and evolutionary biologist Ronald Fisher.
方差分析(Analysis of variance,简称ANOVA,又称变异系数分析)是一类用于分析多组数据之间均值差异的统计方法模型,还涉及一些相关的步骤(比如两组数据之间的“变异”)。
从定义上看,方差分析是分析数据间均值的差异,那为什么叫“方差”分析,而不是“均值分析”?这是因为关于均值差异的结果是通过分析方差推算的,所以前者更合适。下面的具体步骤也将说明这一点。
这里仅对单因子方差方差分析1(one-way ANOVA)假设检验的基本步骤进行说明。
建立假设
设单因子 A A A有 r r r个水平,记为 A 1 , A 2 , . . . , A r A_1, A_2, ..., A_r A1,A2,...,Ar,不同水平( i i i)下,各 m m m次重复试验样本为 y i j ( i = 1 , 2 , . . . , r ; j = 1 , 2 , . . . , m ) y_{ij}(i=1,2,...,r; j=1,2,...,m) yij(i=1,2,...,r;j=1,2,...,m) ,每个水平可看作是一个总体,即水平 A i A_i Ai对应的 m m m个观测样本集 { y i j , j = 1 , 2 , . . . . m } \{y_{ij},j=1,2,....m\} {yij,j=1,2,....m}为一个总体,共 r r r个总体。
假定,这里每个总体均为正态分布
N
(
μ
i
,
σ
i
2
)
N(\mu_i, \sigma_i^2)
N(μi,σi2),各总体方差(
σ
i
2
\sigma_i^2
σi2)相等,所有试验样本之间相互独立。 建立如下一对假设:
H
0
:
μ
1
=
μ
2
=
.
.
.
=
μ
r
v
s
H
1
:
μ
1
,
μ
2
,
.
.
.
,
μ
r
H_0:\mu_1=\mu_2=...=\mu_r \ \ \ vs \ \ \ H_1:\mu_1, \mu_2, ..., \mu_r
H0:μ1=μ2=...=μr vs H1:μ1,μ2,...,μr
若 H 0 H_0 H0成立,则说明因子 A A A的 r r r各水平间无显著差异,否则有显著差异。要检验原假设成立,即各总体均值相等,记总体均值为 μ = ( ∑ i = 1 i = r μ ) / r \mu=(\sum_{i=1}^{i=r}\mu)/r μ=(∑i=1i=rμ)/r,第 i i i水平的均值与总体均值 μ \mu μ的差 a i = μ i − μ a_i=\mu_i-\mu ai=μi−μ作为 A i A_i Ai的水平效应,显然有 ∑ a i = 0 \sum{a_i}=0 ∑ai=0,那原假设可看作是 H 0 : a 1 = a 2 = . . . = a r = 0 H_0: a_1=a_2=...=a_r=0 H0:a1=a2=...=ar=0,备择假设可看作是所以 a i a_i ai不全为0。接着将给出检验 H 0 H_0 H0的统计量。
选择检验统计量
我们将通过偏差平方和建立检验统计量(F统计量)来对原假设( H 0 H_0 H0)进行检验。
首先,给出如下数据表:
| 因子水平 | 重复1 | 重复2 | … | 重复m | 和 | 平均 | |
|---|---|---|---|---|---|---|---|
| A 1 A_1 A1 | y 11 y_{11} y11 | y 12 y_{12} y12 | … | y 1 m y_{1m} y1m | T 1 T_1 T1 | y ˉ 1 ⋅ \bar{y}_{1·} yˉ1⋅ | |
| A 2 A_2 A2 | y 21 y_{21} y21 | y 22 y_{22} y22 | … | y 2 m y_{2m} y2m | T 2 T_2 T2 | y ˉ 2 ⋅ \bar{y}_{2·} yˉ2⋅ | |
| … | … | … | … | … | … | … | |
| A r A_r Ar | y r 1 y_{r1} yr1 | y r 2 y_{r2} yr2 | … | y r m y_{rm} yrm | T r T_r Tr | y ˉ r ⋅ \bar{y}_{r·} yˉr⋅ | |
| T T T | y ˉ \bar{y} yˉ |
其中,(令
i
=
1
,
2
,
…
,
r
,
n
=
r
∗
m
i=1,2,…,r,n = r*m
i=1,2,…,r,n=r∗m)
T
i
=
y
i
1
+
y
i
2
+
…
+
y
i
m
,
y
ˉ
i
⋅
=
T
i
/
m
,
T
=
T
1
+
T
2
+
…
+
T
r
,
y
ˉ
=
(
y
ˉ
1
⋅
+
y
ˉ
2
⋅
+
…
+
y
ˉ
r
)
/
r
=
(
T
1
/
m
+
T
2
/
m
+
…
+
T
r
/
m
)
/
r
=
T
/
(
r
∗
m
)
=
T
/
n
.
\begin{aligned} T_i &= y_{i1} + y_{i2} + … + y_{im}, \\ \bar{y}_{i·} & = T_i / m, \\ T &= T_1 + T_2 + … + T_r, \\ \bar{y} &= (\bar{y}_1· + \bar{y}_2· + … + \bar{y}_r) / r \\ &=(T_1/m + T_2/m + … + T_r/m) / r \\ &=T / (r * m) \\ &=T/n. \end{aligned}
Tiyˉi⋅Tyˉ=yi1+yi2+…+yim,=Ti/m,=T1+T2+…+Tr,=(yˉ1⋅+yˉ2⋅+…+yˉr)/r=(T1/m+T2/m+…+Tr/m)/r=T/(r∗m)=T/n.
偏差平方和
一般在统计学中,
k
k
k个数据
{
y
1
,
y
2
,
.
.
.
,
y
k
}
\{y_1,y_2,...,y_k\}
{y1,y2,...,yk}(记
y
ˉ
\bar{y}
yˉ为该组数据的均值),偏差平方和为
Q
=
∑
i
=
1
i
=
k
(
y
i
−
y
ˉ
)
2
,
Q=\sum_{i=1}^{i=k}{(y_i-\bar{y})^2},
Q=i=1∑i=k(yi−yˉ)2,有时简称平方和。注意到,这
k
k
k个偏差之和为
0
0
0,即有如下恒等式:
∑
i
=
1
k
=
1
(
y
i
−
y
ˉ
)
=
0
,
\sum_{i=1}^{k=1}{(y_i-\bar{y})} = 0,
i=1∑k=1(yi−yˉ)=0, 这说明在
Q
Q
Q中独立(线性无关)的偏差只有个
k
−
1
k-1
k−1个, 在统计学中把
k
−
1
k-1
k−1称为偏差平方和
Q
Q
Q的自由度
d
f
=
k
−
1
df=k-1
df=k−1。偏差平方和常用来度量一组数据的离散程度,对于上表中的数据,将计算如下几种偏差平方和:
-
总体偏差平方和 S T S_T ST
这 n n n个数据之间的差异大小用总体偏差平方和 S T S_T ST表示: S T = ∑ i = 1 i = r ∑ j = 1 j = m ( y i j − y ˉ ) 2 , S_T=\sum_{i=1}^{i=r}{\sum_{j=1}^{j=m}{(y_{ij}-\bar{y})^2}}, ST=i=1∑i=rj=1∑j=m(yij−yˉ)2,自由度为 d f T = n − 1 \ df_T=n-1 dfT=n−1,经推算可得:
S T = ∑ i = 1 i = r ∑ j = 1 j = m y i j 2 − T 2 n . \begin{aligned} S_T=\sum_{i=1}^{i=r}{\sum_{j=1}^{j=m}{y_{ij}^2}} - \frac{T^2}{n}. \end{aligned} ST=i=1∑i=rj=1∑j=myij2−nT2. -
组内偏差平方和 S e S_e Se
仅由随机误差引起各水平(组)内部间的误差,可用组内偏差平方和表示,也称误差偏差平方和: S e = ∑ i = 1 i = r ∑ j = 1 j = m ( y i j − y ˉ i ⋅ ) 2 , S_e=\sum_{i=1}^{i=r}{\sum_{j=1}^{j=m}{(y_{ij}-\bar{y}_{i·})^2}}, Se=i=1∑i=rj=1∑j=m(yij−yˉi⋅)2, 自由度为 d f e = r ( m − 1 ) = n − r df_e=r(m-1)=n-r dfe=r(m−1)=n−r. -
组间偏差平方和 S A S_A SA
组间除了随机误差,还有因子 A A A各水平(各组)之间效应不同产生的差异,用组间偏差平方和表示(也称为因子 A A A的偏差平方和): S A = m ∑ i = 1 i = r ( y ˉ i ⋅ − y ˉ ) 2 , S_A=m\sum_{i=1}^{i=r}{(\bar{y}_{i·}-\bar{y})^2}, SA=mi=1∑i=r(yˉi⋅−yˉ)2,自由度 d f A = r − 1 df_A=r-1 dfA=r−1,经推算可得: S A = 1 m ∑ i = 1 r T i 2 − T 2 n S_A=\frac{1}{m}\sum_{i=1}^r{T_i^2}-\frac{T^2}{n} SA=m1i=1∑rTi2−nT2
从上述几种偏差平方和的表示方式很容易得到: S T = S A + S e , S_T=S_A+S_e, ST=SA+Se, 自由度为 d f T = d f A + d f e df_T=df_A+df_e dfT=dfA+dfe.
F F F检验统计量
根据上面偏差平方和的定义,样本均值间的差异可转化为样本偏差平方和的差异,那么要想知道各水平之间是否有差异,就可以通过组间差与组内偏差进行比较得出。(一般情况下,组间的样本多于组内样本,而样本越多偏差平方和也会越大)
- 若各水平间无差异,也就是各水平间只有随机误差,没有效应不同带来的误差,则组间偏差与组内偏差比较接近,也就是组间偏差与组内偏差的比值比较接近1;
- 若各水平间有差异,也就是各水平间除了随机误差,还有不同效应带来的误差,这时各水平间的误差大于组内误差,则组间偏差与组内偏差的比值会大于1。
那么这个比值达到什么水平,才认为两者之间有显著差异?也就是比值多大,才拒绝原假设?这需要选择一个合适的检验统计量。下面先引入均方的概念。
均方的定义为每个自由度上有多少个平方和,均方
M
S
MS
MS表示为:
M
S
=
Q
d
f
Q
,
MS=\frac{Q}{df_Q},
MS=dfQQ,其中,
Q
Q
Q为偏差平方和,
d
f
Q
df_Q
dfQ为对应偏差平方和的自由度。
由于均方的定义排除自由度不同所产生的干扰,这将有利于各组样本偏差平方和间的比较,所以将组间偏差平方和的均方与组内偏差平方和的均方的比值F作为检验
H
0
H_0
H0的统计量:
F
=
M
S
A
M
S
e
=
S
A
/
d
f
A
S
e
/
d
f
e
F=\frac{MS_A}{MS_e}=\frac{S_A/df_A}{S_e/df_e}
F=MSeMSA=Se/dfeSA/dfA
其中,
S
A
,
S
e
S_A, S_e
SA,Se分别是组间偏差平方和与组内偏差平方和,
d
f
A
,
d
f
e
df_A, df_e
dfA,dfe为对应的自由度。
给出拒绝域并做出判断
这里的检验统计量 F F F就服从自由度为 d f A df_A dfA和 d f e df_e dfe的 F F F分布,由于 F F F的值越大,越倾向于拒绝原假设,因此该检验的拒绝域 W W W为 W = { F ≥ F 1 − α ( d f A , d f e ) } , W=\{F \geq F_{1-\alpha}(df_A, df_e)\}, W={F≥F1−α(dfA,dfe)}, 其中, α \alpha α为显著性水平,一般取 0.05 0.05 0.05,这里 F 1 − α ( d f A , d f e ) F_{1-\alpha}(df_A, df_e) F1−α(dfA,dfe)通过 F F F分布查表获得。也就是说,
- 若 F ≥ F 1 − α ( d f A , d f e ) F \geq F_{1-\alpha}(df_A,df_e) F≥F1−α(dfA,dfe),则因子 A A A各组间有显著差异;
- 若 F < F 1 − α ( d f A , d f e ) F < F_{1-\alpha}(df_A,df_e) F<F1−α(dfA,dfe),则说明因子 A A A各组间差异不显著。
该检验的 p p p值通过 F F F分布对应的密度函数得到: p = P ( Y ≥ F ) . p=P(Y \geq F). p=P(Y≥F).
p p p值是利用样本观测值做出拒绝原假设的最小显著性水平,一般在实际中,若 p p p值很小( p ≤ 0.001 p \leq 0.001 p≤0.001)时,可做出拒绝原假设;若 p > 0.05 p>0.05 p>0.05时,接受原假设。当 α \alpha α与 p p p比较接近时,才比较 α \alpha α和 p p p。如果 α ≥ p \alpha \geq p α≥p,则在显著性水平 α \alpha α下拒绝 H 0 H_0 H0;否则,在显著水平 α \alpha α下接受原假设。
关于数据的计算可使用统计分析工具,一般有SPSS, SAS等,当然还有一般人接触最多的Excel,下面是利用Excel中的分析工具进行单因子方差分析。
使用Excel进行方差分析
添加数据分析工具
若功能区已经显示有“数据分析”功能(如下图)可跳过下面三步

- 选择“数据”-> 右键“数据工具”-> 选择“自定义快速访问工具栏”,选择后将弹出“Excel选项”窗口(也可通过其他方式打开);
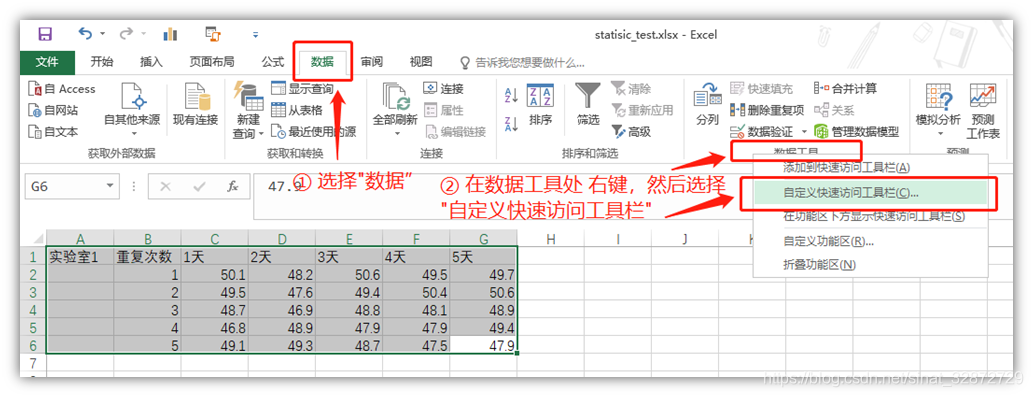
- “Excel选项” -> “加载项” -> “分析工具库-VBA”-> “转到”,选择后会弹出“加载宏”的窗口
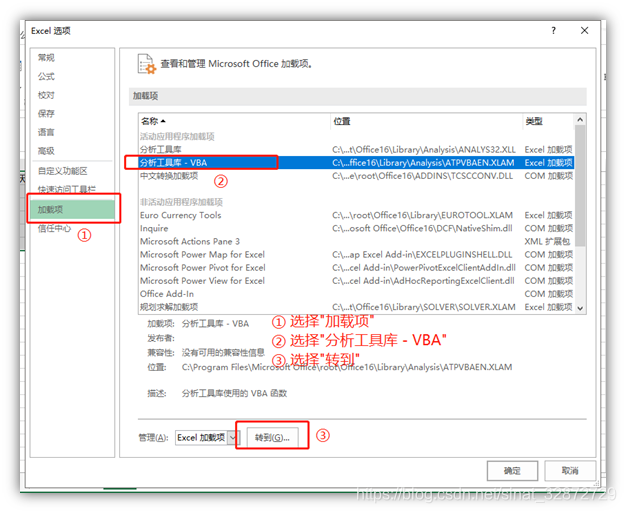
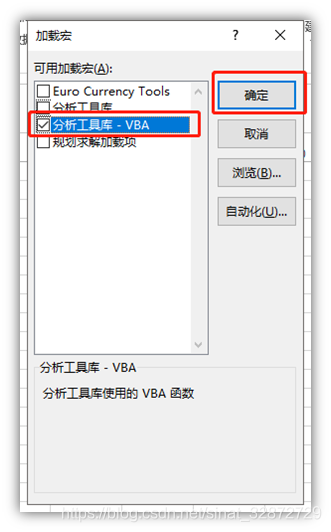
- “加载宏”-> 在“分析工具库 - VBA”前打对勾 -> “确定”,此时Excel上的功能区就会显示“数据分析”工具(如最上面第一张图)
使用分析工具库
使用如下数据进行示例操作:
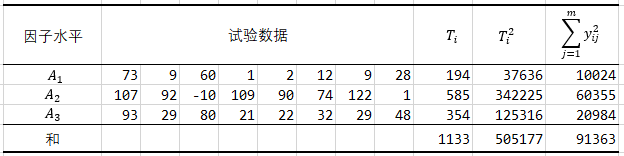
可根据上面方差分析的步骤直接计算,下面是使用Excel中的数据工具直接得到偏差平方和,自由度,均方等。
使用分析工具库进行单因子方差分析步骤:
-
“数据分析”-> “方差分析:单因素方差分析”-> 点击“确定”后,会出现方差分析选项卡。这里请注意,Excel分析工具进行方差分析时,一列作为一组,所以将上面数据进行转置。
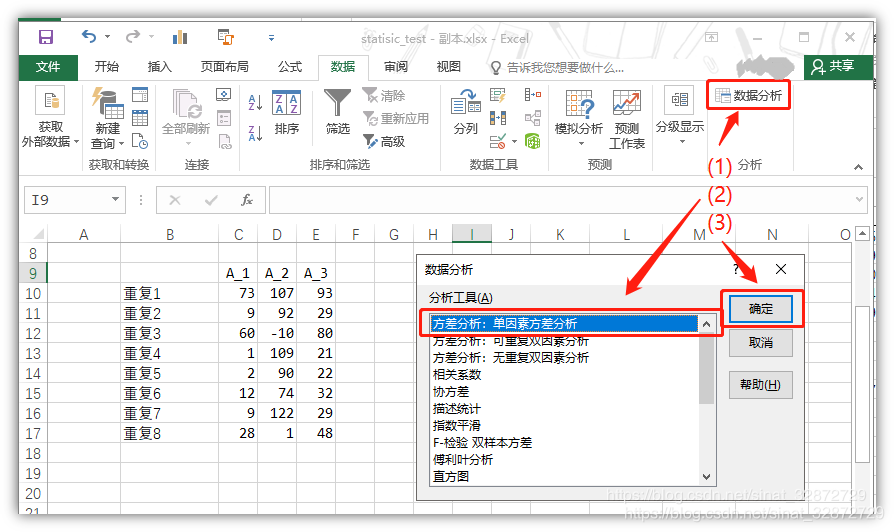
-
“方差分析:单因素方差分析”选项卡 -> 在“输入区域”选择要分析的数据(可通过右侧按钮鼠标选择,也可直接手动输入) -> 在“ α α α(A)”的选择填显著性水平(默认0.05) -> 在“输出区域”选择输出单元格 -> 点击“确定”后,会计算出对应数据的结果,其中包含平方和(SS) 、自由度(df),均方(MS) 等。(注:选项卡中"标志位于第一行"勾选表示 数据第一行为列名,在输出结果时会显示对应列名,若数据未选择列明则无需勾选,结果中列名会对应写成"列1", “列2”,…)
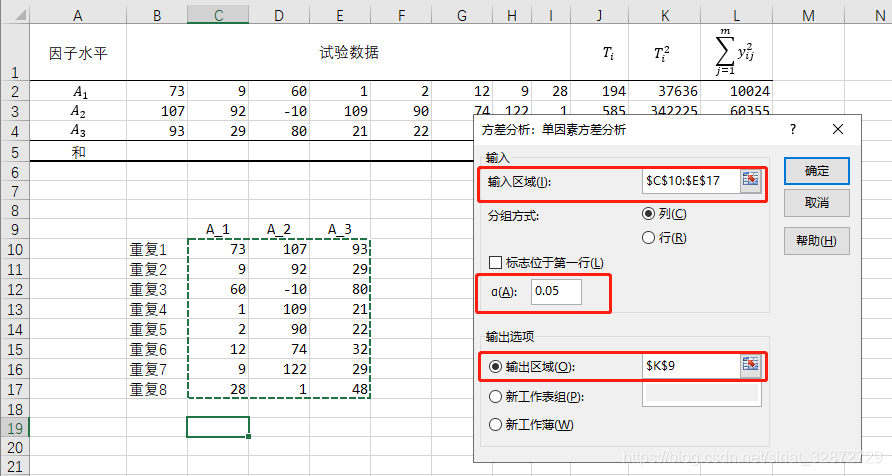
-
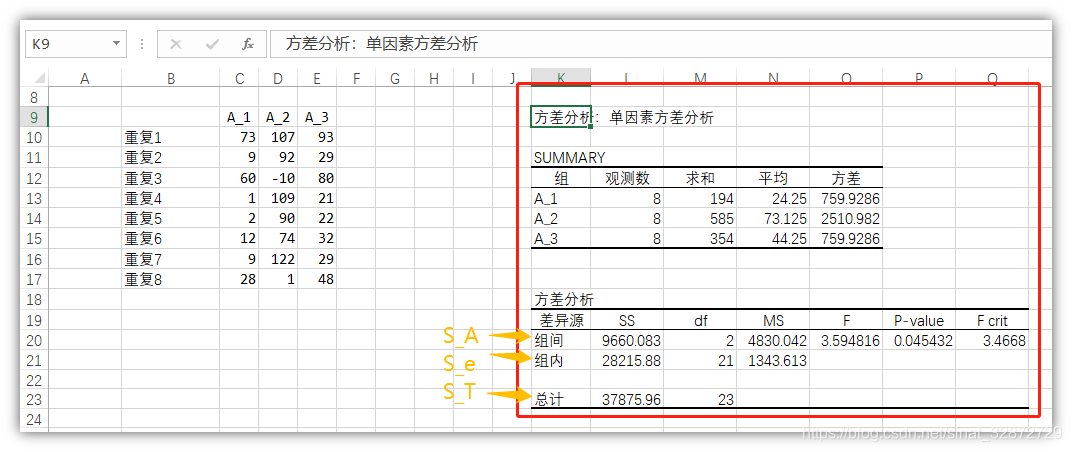
点击确定后,就会直接给出该数据对应的方差分析表:
结果说明
结果中给出了两个汇总表:
- 第一个是各组数据之和,平均值,方差;
- 第二个是方差分析的结果表,其中
- S S SS SS 表示偏差平方和
- d f df df 表示自由度
- M S MS MS表示均方
- F F F是对应组间和组内偏差平方和均方比值
- P P P- v a l u e value value为对应 F F F值的密度函数值,也可利用Excel中=F.DIST.RT(<F值>,<组间自由度>,<组内自由度>)$公式得到
- F c r i t F crit Fcrit为对应 F F F分布, α \alpha α置信水平下自由度为 d f 组间 df_{组间} df组间和 d f 组内 df_{组内} df组内的临界值,也可利用Excel中=F.INV(1-<\alpha>,<组间自由度>,<组内自由度>)公式得到
茆师松,程依明, 濮晓龙.概率论与数理统计教程第二版[M].高等教育出版社:北京,2011:423-434. ↩︎

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 46
46 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)