
Redis 漫谈 —— 分布式布隆过滤及内存使用问题分析
背景介绍公司消息推送系统每日会对旗下百万级体量 app 用户进行消息推送;同时,为了防止过度打扰用户,只允许一天之中对同一个用户设备推送最多 4 条运营类消息 —— 我们选择使用基于 redis 的「分布式布隆过滤」策略实现该限制,具体工具为 github 开源项目 Orestes-Bloomfilter。布隆过滤...
背景介绍
公司消息推送系统每日会对旗下百万级体量 app 用户进行消息推送;同时,为了防止过度打扰用户,只允许一天之中对同一个用户设备推送最多 4 条运营类消息 —— 我们选择使用基于 redis 的「分布式布隆过滤」策略实现该限制,具体工具为 github 开源项目 Orestes-Bloomfilter。
布隆过滤
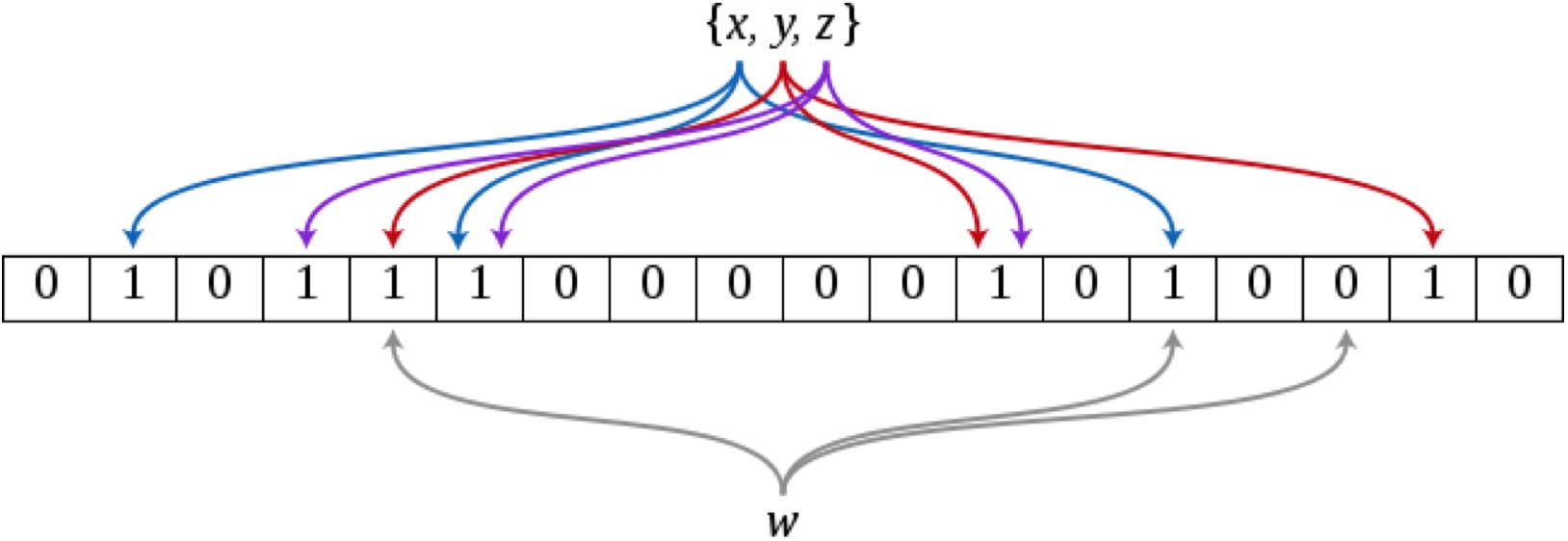
参考上图,布隆过滤器的数据结构为元素初始值均为 0 的「比特数组」;当向布隆过滤器「添加」某个元素(如上图 x、y 或 z)时,需要对该元素进行多次不同算法类型的哈希运算,将运算结果根据布隆过滤器长度取余,得到一批对应的数组位置,并将数组中这些位置的值置为 1;当「校验」某个元素是否已添加至布隆过滤器时,我们进行与「添加」元素时相同的计算得到一批数组位置,然后检查数组中这些对应位置上的值是否为 1 —— 若「均为」 1,可以认为被校验的元素已经存在于布隆过滤器中,否则表示被校验的元素尚不存在。
可以看到布隆过滤器是一种非常紧凑的数据格式;虽然存在一定「误判率」,但是相对于传统的将元素直接存放在集合中用于校验的方式,布隆过滤是一种很好的「以微弱的时间代价换空间」的做法。本文不对该算法做深入详尽的介绍,感兴趣的读者可以查阅相关资料。
工程实践
google 的 guava 包中提供了基于内存的布隆过滤器,但是对于分布式应用而言,存在单点问题和过滤状态维护的不便;于是我们对基于 redis 的分布式过滤进行调研,比较了 ReBloom 和 Orestes-Bloomfilter 两款开源工具;前者需要以模块(module)的方式集成至 redis 中;后者直接使用 setbit 命令与 redis 交互进行布隆过滤器的赋值,并且对并发批量操作做了较好的封装,于是我们优先对后者进行了测试:内存占用方面,一个预期以百万分之一的误判率对 200 万元素进行过滤或者说校验的布隆过滤器约占 7 mb 空间;过滤性能方面,4 个线程并发对 25 万元素(即总量 100 万元素)进行批量校验总耗时约 45 秒 —— 综合评估在可接受的范围,于是我们将这个方案落地实施:
public void containAndPut(final List<String> keys) {
// bloomFilterList 包含 4 个布隆过滤器客户端
bloomFilterList.forEach(bf -> {
// 尝试批量添加目标设备信息
List<Boolean> results = bf.addAll(keys);
for (int i = results.size() - 1; i >= 0; --i)
// 将成功添加的设备元素从列表中移除
if (results.get(i))
keys.remove(i);
});
}
上述代码为核心逻辑:由于在「背景介绍」中提到的每天 4 条运营类消息推送的限制,我们需要遍历一组共 4 个布隆过滤器,调用 addAll 方法尝试批量添加目标设备 keys,并在每次操作后将被成功添加的设备元素从列表中移除,最后剩下的便是已经达到发送次数上限的设备列表。
奇怪现象
该方案在生产环境运行稳定,但是在监测观察中我们也发现了一个在测试时疏忽了的奇怪现象 —— 在进行大量数据的并发过滤校验时,redis 的内存占用(used_memory_rss)会一度飙升,而后快速回落至预期水平:
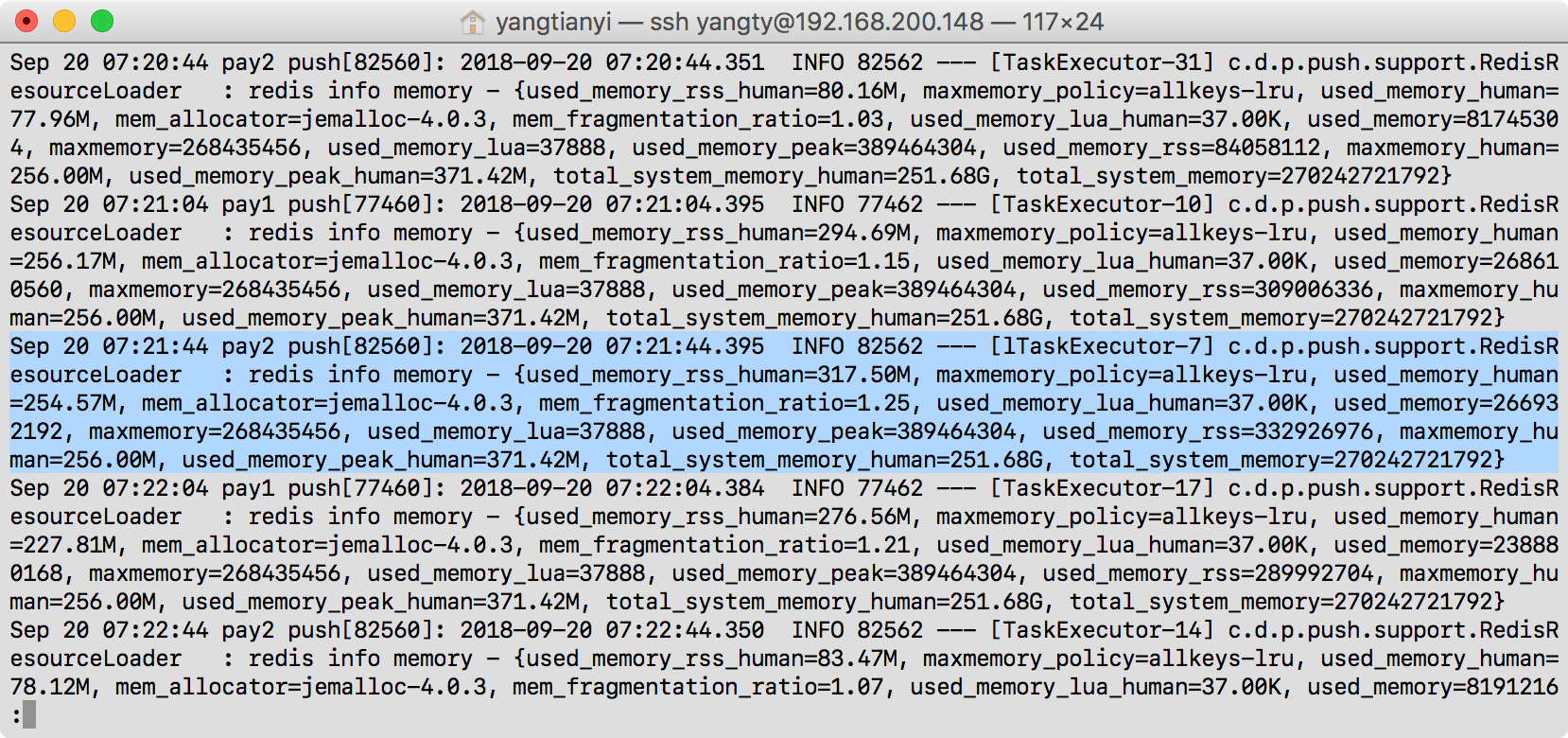
排除了 bgsave 因素后我们猜测是 redis 在进行布隆过滤操作时占用了大量内存;于是我们仔细分析了 Orestes-Bloomfilter 中相关代码逻辑:
public List<Boolean> addAll(Collection<T> elements) {
List<Boolean> added = new ArrayList<>();
// 使用事务模式
List<Boolean> results = pool.transactionallyDo(p -> {
// 遍历所有带校验元素
for (T value : elements) {
// 进行多次哈希计算
for (int position : hash(toBytes(value))) {
// 将 redis 「布隆过滤器」对应位置的值置为 1
bloom.set(p, position, true);
}
}
});
// 判断各个元素是否「初次」添加至布隆过滤器
boolean wasAdded = false;
int numProcessed = 0;
for (Boolean item : results) {
// 若 item 为 0,表示该位置元素先前非 1,判断为初次添加
if (!item) wasAdded = true;
// config().hashes() 返回整数 n,表示对某元素进行了 n 次不同的哈希计算
if ((numProcessed + 1) % config().hashes() == 0) {
added.add(wasAdded);
wasAdded = false;
}
numProcessed++;
}
return added;
}
在消息推送时我们使用上述方法对用户设备进行批量校验;基本思路是对用户设备信息进行多次不同的哈希计算,并尝试将 redis 中比特数组对应位置的值置为 1,只需其中任一位置操作成功便可判定该设备信息先前不存在,否则表示该用户设备已存在布隆过滤器中;程序与 redis 进行交互时使用的具体命令是 SETBIT key offset value,用于对 key 对应的字符串中 offset 位置赋值 value(0或1),并返回该位置先前的值。
继续分析 transactionallyDo 的方法逻辑:
public <T> List<T> transactionallyDo(Consumer<Pipeline> f, String... watch) {
return (List<T>) safelyReturn(jedis -> {
Pipeline p = jedis.pipelined();
if (watch.length != 0) {
p.watch(watch);
}
// 标记 redis 事务开始
p.multi();
// 执行调用方(此处为 addAll 方法)指定操作
f.accept(p);
// 执行 redis 事务
Response<List<Object>> exec = p.exec();
// 获取操作结果
p.sync();
return exec.get();
});
}
可以看到代码中为了保证对大量元素进行布隆过滤操作的性能,与 redis 交互时使用了「管道」 —— 即在单次交互中批量发送操作指令以减少网络 I/O;同时,为了保证并发安全性,每一批次的管道命令操作都在一个「事务」中进行。查阅相关文档,可以发现无论是管道模式还是事务模式都需要消耗 redis 内存:
While the client sends commands using pipelining, the server will be forced to queue the replies, using memory.
To perform a transaction in Redis, we first call MULTI, followed by any sequence of commands we intend to execute, followed by EXEC. When seeing MULTI, Redis will queue up commands from that same connection until it sees an EXEC, at which point Redis will execute the queued commands sequentially without interruption.
在管道模式下,redis 在回应客户端请求前需要缓存所有操作指令对应的结果;在事务模式下,redis 在真正执行该事务前需要缓存相应的操作指令;与此同时,我们的消息推送应用以并发的方式进行分布式布隆过滤 —— 综合考虑这些因素就可以理解为何 redis 进程会出现短暂的内存占用高峰了。
问题解决
虽然在内存占用达到极值(maxmemory)后,redis 仍可以继续使用内存进行操作指令缓存等非数据存储工作,但是出于稳定性考虑我们可能希望对这种情况做一定的限制;由于查明了内存快速上升的具体原因,相应的控制措施也就比较明了了 —— 可以降低进行布隆过滤的并发数或减少了管道模式下批量操作指令数来到达效果。
思考一下
- 为什么上文提到在进行批量布隆过滤操作时除了需要使用管道模式提高性能,还需要应用事务保证并发安全性?
参考资料

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)