数据挖掘考题汇总
文章目录数据挖掘习题汇总一 数据挖掘概述二 认识数据数据挖掘习题汇总一 数据挖掘概述数据与知识的区别与联系?数据: 指描述事物的符号记录, 它涉及到事物的存在形式, 是关于事物的一组离散且客观的事实描述。知识: 反映各种事物的信息进入人们大脑,对神经细胞产生作用后留下的痕迹联系和区别: 通过数据可以推导出知识, 比如我们可以通过一系列出售数据推导出这个商店是卖什么的(是否正确地运用...
·
文章目录
数据挖掘习题汇总
一 数据挖掘概述
- 数据与知识的区别与联系?
- 数据: 指描述事物的符号记录, 它涉及到事物的存在形式, 是关于事物的一组离散且客观的事实描述。
- 知识: 反映各种事物的信息进入人们大脑,对神经细胞产生作用后留下的痕迹
- 联系和区别: 通过数据可以推导出知识, 比如我们可以通过一系列出售数据推导出这个商店是卖什么的(是否正确地运用知识对数据做出解释,以得到准确的信息)
- 列举几项你知道的数据挖掘应用, 并论述数据挖掘在其中的作用?
- 传感数据(卫星, 位传感器)
- 天体/空间物理数据
- 生物/化学数据(基因序列, 分子结构)
- …
- 数据挖掘方法过程是什么?
- 挖掘前(数据清理, 变换, 归约, 采样, 统计, 预计算)
- 关键方法:
- 分类预测
- 聚类分析
- 孤立点分析
- 趋势和演变分析
- 数据挖掘与统计的区别与联系?
- 有大量数据的地方就需要数据挖掘
- 统计是初级阶段, 挖掘是进阶
- 数据挖掘是多学科交叉, 统计学只是其中的一部分
- 数据挖掘与数据管理的区别与联系?
- 只有经过一定的数据管理过程才能让数据挖掘出来的信息更有价值?..
二 认识数据
- 数据属性有哪些类别?不同类别的属性有哪些作用?
- 标称属性: 就是用来描述一类事物的, 一般用来分类。
- 二元属性: 就是0或者1
- 序数属性: 就是属性之间有顺序的 如讲师, 副教授, 教授
- 数值属性: 定量的, 分为区间标度属性和比例标度属性
- ps. 标称, 二元, 序数是定性的, 数值是定量的
- 如何对属性的区间标度变量和二元变量进行相似度度量?
- 区间标度变量

- 相似度度量
- 区间标度变量
- 基本统计描述有哪些?
- 总量描述
- 中心趋势描述(均值, 中位数, 众数, 中列数)
- 相对描述
- 变异描述(指标变异越大, 平均数的代表性越小;指标变异越小, 平均数代表性越大)
- 基本统计描述该如何使用?
- 会算不等于会用
- 首先理解各个指标代表的意义
- 进行相关分析, 找到变量之间的关联关系
- 进行回归分析, 通过一般关系推导数学模型, 通过已知变量推导未知变量
- 为什么需要进行数据可视化?
- 借助图形化的手段, 清晰有效的传达和沟通信息
- 数据可视化的七个阶段是什么?
- 获取
- 分析
- 过滤
- 挖掘
- 表达
- 修饰
- 交互
- 数据可视化解决的重点问题是什么?
- 数据来源
- 数据结构
- 关注信息
- 分析处理
- 视觉模型
- 清晰易读
- 操作控制
三 数据预处理
- 数据预处理的作用?
- 在数据进行处理前进行的一些操作
- 现实世界中通常无法直接对原始数据进行挖掘或者结果差强人意, 为了提高数据挖掘质量我们需要进行数据预处理, 将数据处理成更加符合预期的数据。
- 什么是ETL?ETL包括哪些步骤?
- ETL是数据抽取(Extract)、清洗(Cleaning)、转换(Transform)、装载(Load)的过程。是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
- 数据质量问题包含哪些?由什么原因导致?
- 数据质量

- 数据质量原因


- 数据质量
- ETL的常见问题包含哪些?
- 字符集问题
- 缓慢变化维处理
- 增量, 实时同步的处理
- 错误数据的检测
- 变化数据的捕获
- 抽取异常中止的处理
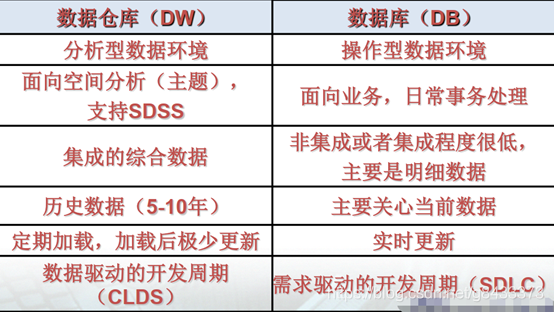
- 数据库和数据仓库的区别?
- NoSql数据模型有哪些?与SQL模型相比, 有什么区别和联系, 各有什么优劣?
- 键值对模型如(redis, MemcacheDB等)
- 文档模型(如 xml, json, mongoDB等)
- 列族模型(如 hbase, amazon simpleDB等)
- 图模型(如 neo4J)
- SQL和No-SQL的关系区别
- 常见的数据预处理方法有哪些?分别如何处理?
- 数据清洗
- 数据集成与变换
- 数据归约
- 离散化和概念分层
- TF-IDF算法是什么, 有什么实际意义?
- 算法过程

- 数学含义

- 算法过程
四 分类基础
- 概念描述和OLAP的区别是什么?
- OLAP联机分析处理,是数据仓库的核心,是对OLTP的历史数据进行加工,分析处理,用于处理商业智能,决策支持等重要的决策信息
- 概念描述方法有哪些?
- 数据泛化
- 解析特征
- 挖掘类比较
- 什么是分类, 什么是有指导/无指导学习?
- 分类就是将样本按照不同特征分为不同类别
- 有指导学习: 模型的学习在被告知每个训练样本属于哪个类的指导下进行
- 无指导学习: 模型不知道训练样本属于哪个类, 聚类是典型的无指导学习
- 什么是决定性现象, 什么是不确定现象?
- 决定性现象: 就是不是0就是1的现象, 如水到100度必然沸腾, 筛子不可能到8点
- 不确定现象: 在基本条件保持不变的情况下, 一系列的实验会得到不同的结果。
- 什么是随机试验, 样本空间, 样本点, 随机事件, 复合事件, 必然事件, 不可能事件?


- 事件间的关系有哪些?
- 概率与频率的区别与联系?
- 在试验次数足够多的情况下, 频率趋近于概率
- 概率有哪些基本性质?
- 什么是古典概率?
- 什么是条件概率?条件概率有哪些性质?
- 什么是乘法定理?

- 条件概率与无条件概率有什么关系?

- 条件概率与积事件概率有什么关系?

- 什么是全概率公式?

- 什么是贝叶斯公式, 贝叶斯公式有什么作用, 有哪些局限性?


- 什么是朴素贝叶斯分类?
- 就是贝叶斯中特征都是独立存在的?

- 就是贝叶斯中特征都是独立存在的?
- 什么是贝叶斯网络? 贝叶斯网络和朴素贝叶斯有什么区别和联系?

- 区别和联系
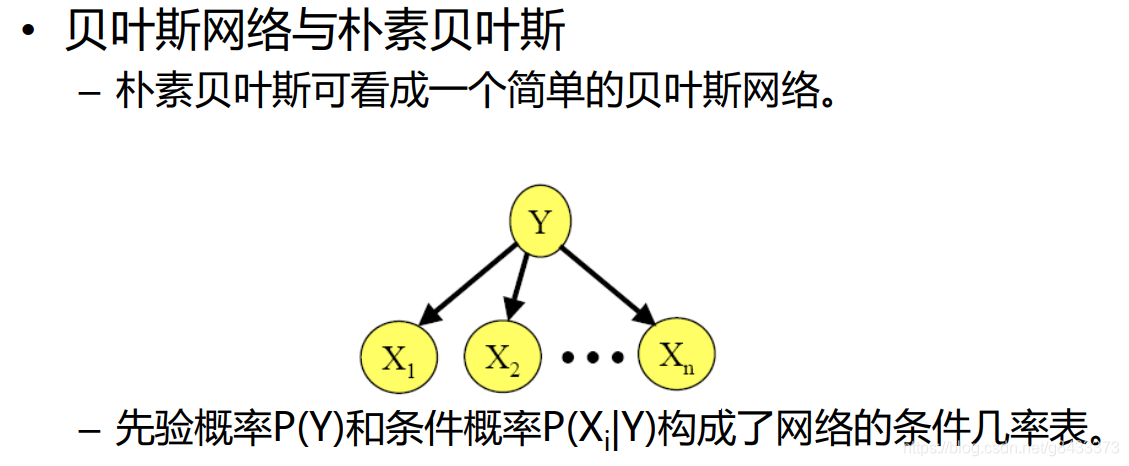
- 区别和联系

五 决策树与链接分析
- 什么是决策树?

- 决策树有什么用?

- 决策树生成方法有哪些?各有什么特点?
- 如何对决策树进行剪枝?
- 前期修剪
- 后期修剪
- 为什么要进行规则提取?如何进行规则提取?
- 很多规则有可能冗余?
- 决策树的进一步策略有哪些?
- 纯度计算
- 错误率计算
- 多属性组合分类
- 什么是图?
- 对象(节点) 及 对象间关系(边)的一种直观展示

- 对象(节点) 及 对象间关系(边)的一种直观展示
- 如何计算图的最短路径?
- Pagerank, 漏斗模型, 关键路径, 矩阵分析有哪些作用?
- pagerank: 就是根据不同网页间链接的出度入度数量 判断网页权重
- 漏斗模型: 自顶而下, 逐层反应各个流程的数量和比例便于分析流失原因和转化率
- 关键路径: 顶点表示事件, 弧表示活动, 弧上权值表示活动持续时间, 用来预估工程时间(关键路径算法)
- 矩阵分析: 表示两个因素之间的关联关系?

六 随机过程与抽样
- 什么是马尔科夫模型?什么是转移概率?什么是C-K方程?
- 什么是HMM, HMM的三大问题是什么?
- HMM三大问题的求解算法是什么?
- 什么叫抽样?抽样都有哪些?如何抽样?
七 聚类基础
- 什么是聚类?

- 聚类有什么用?
- 聚类和分类有什么区别和联系?
- 划分聚类的算法思想, 过程, 优点, 缺点和可拓展点有哪些?


- 点与点, 点与类, 类与类的距离计算方法有哪些?


- 聚类评估典型任务有哪些, 思想分别是什么, 有哪些典型的计算方法?
八 高级聚类方法
- 密度聚类的核心概念 算法思想 过程 优点 缺点?
- 网格聚类的核心概念 算法思想 过程 优点 缺点?
- 图聚类的核心概念 算法思想 过程 优点 缺点?
- 什么是离群点?
- 离群点检测有什么意义?
- 离群点检测方法有哪些?
九 频繁模式挖掘基础
- 什么是频繁模式?
- 频繁模式相关基本概念有哪些?
- 支持度和置信度的计算和作用?
- 什么是关联规则?
- 频繁模式挖掘有哪些作用?
- Apriori方法的思想 过程 优点 缺点是什么 改进方法有哪些?
- 什么是频繁图?
- 如何挖掘频繁图?
十 频繁模式挖掘进阶和关联规则
- 如何进行频繁序列挖掘?
- 如何生成关联规则?
- FP-Tree方法是什么 如何挖掘FP-Tree?
- 什么是多层关联规则?
- 为什么进行模式评估?
- 如何判断相关性 如何计算兴趣度?
十二 群体智能挖掘
- 遗传学算法的生物学基础/算法思想/基本过程?
- 蚁群算法的生物学基础/算法思想/基本过程?
- 人工蜂群算法的生物学基础/算法思想/基本过程?
- 人工神经网络算法的生物学基础/算法思想/基本过程?
十三 集成挖掘
- bagging和boosting机制分别是什么, 有什么异同点?
- Bandit策略是什么?
- 随机森林算法基本思路是什么?
- GBDT算法基本思路?
- adaboost算法基本思路?
十四 复杂类型数据挖掘
- 什么是模糊集, 模糊计算有什么性质?
- 如何进行模糊统计?
- 什么是模糊矩阵, 模糊矩阵如何运算?
- 如何进行模糊聚类, 如何进行模糊分类?
- 空间数据和序列数据有什么特点?
- 空间挖掘与序列挖掘与普通挖掘方法有什么区别和联系?
- 序列有哪些种, 判别方法有哪些?
- 什么是GMM, GMM求解算法是什么?

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)