模式识别
对于时间和空间中可观察的物体,如果我们可以区分它们是否相同或相似,都可以称之为“模式”(或“模式类”)。模式所指的不是事物本身,而是从事物中获得的信息。因此,模式常常表现为具有时间和空间分布的信息。模式的直观特性包括:可观察性,可区分性,相似性。模式识别就是对模式的区分和认识,把对象根据其特征归到若干类别中的适当一类。模式识别并不是根据物体本身来判断的,而是根...
对于时间和空间中可观察的物体,如果我们可以区分它们是否相同或相似,都可以称之为“模式”(或“模式类”)。模式所指的不是事物本身,而是从事物中获得的信息。因此,模式常常表现为具有时间和空间分布的信息。模式的直观特性包括:可观察性,可区分性,相似性。
模式识别就是对模式的区分和认识,把对象根据其特征归到若干类别中的适当一类。
模式识别并不是根据物体本身来判断的,而是根据被感知到的某些性质,也就是物体特征来判别的。所以,也就引出了模式的定义---这些如物体的纹理、硬度、比重等的被感知到的物体特性,叫做模式。所以为了识别物体,也就是进行分类,一般会用分类器这个工具。故而分类器实际上识别的不是物体,而是物体的模式。物体识别精准与否与分类器有直接关联,一个好的分类器是物体识别的关键所在,而选择物体的什么特征来描述物体,则是直接相关的。
什么叫做类?一个物体是一个物理单位,而在图像分析里面通常表示为分割后的一个区域。而整个物体集合可以分为几个不相交的子集合,子集合从某种分类角度来说,就是具有某种共同的特性,被称为类。如彩色图里面,用颜色特征分类器来筛选的话,所以蓝色可能属于一个类,所有红色图案属于另外一个类。但是也有可能是红色和蓝色属于一个类,这就视设计的分类器而定了。实际上,模式识别理论就是研究如何针对特定的基本物体描述集合来设计分类器。一般地,物体识别等价于模式识别。
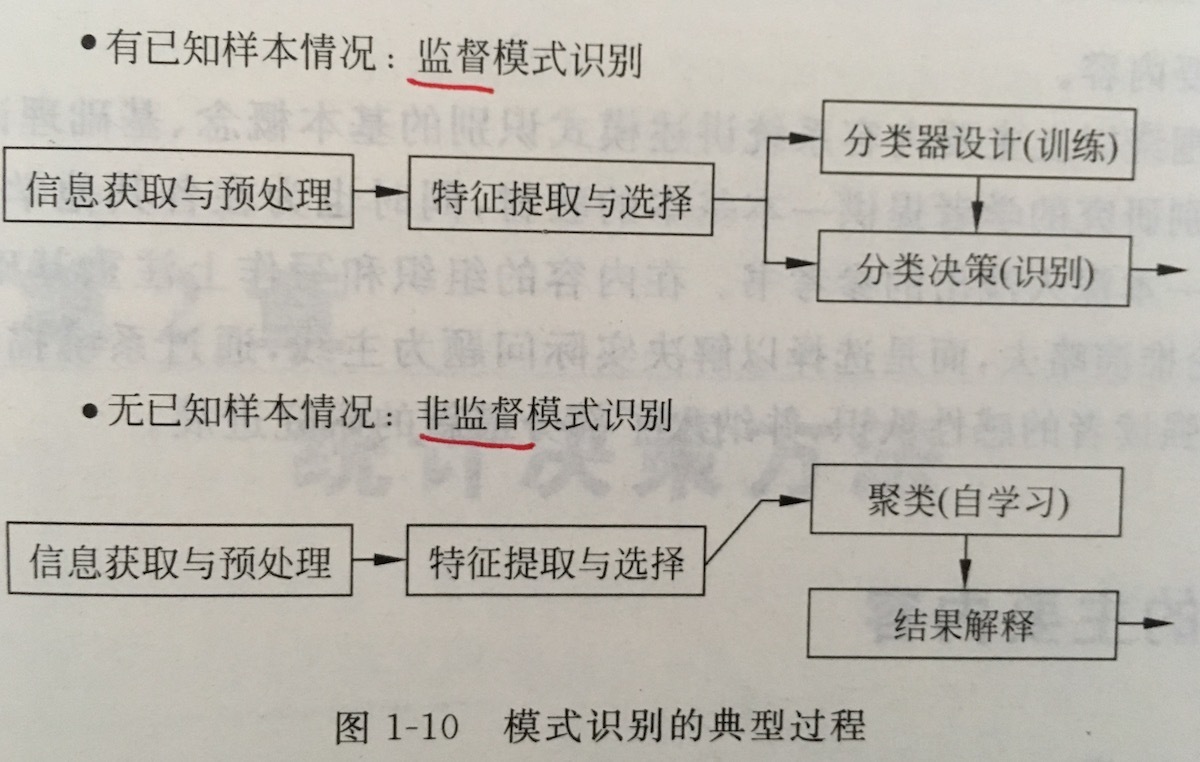
模式识别的主要步骤如下:

模式识别系统的组成框图如下图所示。一个模式识别系统处理的完整过程通常包括:可归纳为:数据/信息获取与预处理、特征提取与选择、分类或聚类、后处理四个步骤。
几种常见模式识别算法
1. K-Nearest Neighbor
K-NN可以说是一种最直接的用来分类未知数据的方法。

实际上K-NN本身的运算量是相当大的,因为数据的维数往往不止2维,而且训练数据库越大,所求的样本间距离就越多。训练数据有上千个,所以每次求距离(这里用的是欧式距离,就是我们最常用的平方和开根号求距法) 这样每个点的归类都要花上上百万次的计算。所以现在比较常用的一种方法就是kd-tree。也就是把整个输入空间划分成很多很多小子区域,然后根据临近的原则把它们组织为树形结构。然后搜索最近K个点的时候就不用全盘比较而只要比较临近几个子区域的训练数据就行了。kd-tree的一个比较好的课件可以见下面链接:
当然,kd-tree有一个问题就是当输入维数跟训练数据数量很接近时就很难优化了。所以用PCA(稍后会介绍)降维大多数情况下是很有必要的。
2. Bayes Classifier
在模式识别的实际应用中,贝叶斯方法绝非就是post正比于prior*likelihood这个公式这么简单,一般而言我们都会用正态分布拟合likelihood来实现。
用正态分布拟合是什么意思呢?贝叶斯方法式子的右边有两个量,一个是prior先验概率,这个求起来很简单,就是一大堆数据中求某一类数据占的百分比就可以了,比如300个一堆的数据中A类数据占100个,那么A的先验概率就是1/3。第二个就是likelihood,likelihood可以这么理解:对于每一类的训练数据,我们都用一个multivariate正态分布来拟合它们(即通过求得某一分类训练数据的平均值和协方差矩阵来拟合出一个正态分布),然后当进入一个新的测试数据之后,就分别求取这个数据点在每个类别的正态分布中的大小,然后用这个值乘以原先的prior便是所要求得的后验概率post了。
贝叶斯公式中还有一个evidence,对于初学者来说,可能会一下没法理解为什么在实际运算中它不见了。实则上,evidence只是一个让最后post归一化的东西,而在模式分类中,我们只需要比较不同类别间post的大小,归一化反而增加了它的运算量。当然,在有的地方,这个evidence绝对不能省,比如GMM中,需要用到EM迭代,这时候如果不用evidence将post归一化,后果就会很可怕。
3. Principle Component Analysis
PCA或者主成份分析,是一种很好的简化数据的方法。主元分析最大的意义就是让我明白了线性代数中特征值跟特征向量究竟代表什么,从而让我进一步感受到了线性代数的博大精深魅力无穷。
PCA简而言之就是根据输入数据的分布给输入数据重新找到更能描述这组数据的正交的坐标轴,比如下面一幅图,对于那个椭圆状的分布,最方便表示这个分布的坐标轴肯定是椭圆的长轴短轴而不是原来的x y。
那么如何求出这个长轴和短轴呢?于是线性代数就来了:我们求出这堆数据的协方差矩阵,然后再求出这个协方差矩阵的特征值和特征向量,对应最大特征值的那个特征向量的方向就是长轴(也就是主元)的方向,次大特征值的就是第二主元的方向,以此类推。
4. Linear Discriminant Analysis
LDA,基本和PCA是一对双生子,它们之间的区别就是PCA是一种无监督的映射方法而LDA是一种有监督映射方法:

图左是PCA,它所作的只是将整组数据整体映射到最方便表示这组数据的坐标轴上,映射时没有利用任何数据内部的分类信息。因此做了PCA后,整组数据在表示上更加方便(降低了维数并将信息损失降到最低),但在分类上也许会变得更加困难;
图右是LDA,可以明显看出,在增加了分类信息之后,两组输入映射到了另外一个坐标轴上,有了这样一个映射,两组数据之间的就变得更易区分了(在低维上就可以区分,减少了很大的运算量)。
5. Non-negative Matrix Factorization
NMF,中文译为非负矩阵分解。NMF,简而言之,就是给定一个非负矩阵V,我们寻找另外两个非负矩阵W和H来分解它,使得后W和H的乘积是V。论文中所提到的最简单的方法,就是根据最小化||V-WH||的要求,通过Gradient Discent推导出一个update rule,然后再对其中的每个元素进行迭代,最后得到最小值,具体的update rule见下图,注意其中Wia等带下标的符号表示的是矩阵里的元素,而非代表整个矩阵。
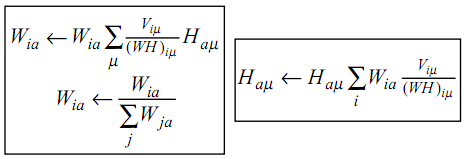
相比于PCA、LDA,NMF有个明显的好处就是它的非负,因为为在很多情况下带有负号的运算算起来都不这么方便,但是它也有一个问题就是NMF分解出来的结果不像PCA和LDA一样是恒定的。
6. Gaussian Mixture Model
GMM高斯混合模型粗看上去跟上文所提的贝叶斯分类器有点类似,但两者的方法有很大的不同。在贝叶斯分类器中,我们已经事先知道了训练数据(training set)的分类信息,因此只要根据对应的均值和协方差矩阵拟合一个高斯分布即可。而在GMM中,我们除了数据的信息,对数据的分类一无所知,因此,在运算时我们不仅需要估算每个数据的分类,还要估算这些估算后数据分类的均值和协方差矩阵。。。也就是说如果有1000个训练数据,10种分类的话,需要求的未知数是1000+10+10(用未知数表示未必确切,确切的说是1000个1x10标志向量,10个与训练数据同维的平均向量,10个与训练数据同维的方阵)那么这个问题是怎么解决的呢?这里用的是一种叫EM迭代的方法。
from:几种常见模式识别算法整理和总结
from:模式识别/机器学习百题(含大部分答案)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)