【语音】提取MFCCs特征
MFCC: Mel Frequency Cepstral Coefficient tutorial任何自动语音识别(asr)系统的第一步都是提取特征,即识别音频信号中有利于识别语言内容的成分,丢弃所有其他携带信息的成分,如背景噪声、情绪等。想深入了解语音,先从了解人的发声原理开始。人发出的声音是通过舌、牙等声道的形状来过滤的,这种形状决定了发出什么样的声音。如果我们能准确地确定音素的形状,就能..
MFCC: Mel Frequency Cepstral Coefficient tutorial
任何自动语音识别(asr)系统的第一步都是提取特征,即识别音频信号中有利于识别语言内容的成分,丢弃所有其他携带信息的成分,如背景噪声、情绪等。
想深入了解语音,先从了解人的发声原理开始。人发出的声音是通过舌、牙等声道的形状来过滤的,这种形状决定了发出什么样的声音。如果我们能准确地确定音素的形状,就能准确地表示所产生的音素。声道的形状表现在短时间功率谱的包络线中,而MFCCs的工作就是准确地表示这个包络线。本文将提供一个关于MFCCs的简短教程。
MFCCs是一种广泛应用于语音识别的特征,它是由Davis和 Mermelstein 在20世纪80年代提出的,自提出后一直处于最先进水平。在MFCCs提出之前,线性预测系数(LPCs)和线性预测倒谱系数(LPCCs)是自动语音识别(ASR)的主要特征类型,特别是使用HMM的分类器。
MFCC提取步骤
基本步骤为:
- 将语音信号分帧
- 对每一帧计算功率谱的周期图估计。
- 将梅尔滤波器应用于功率谱,计算每个滤波器的能量。
- 取所有滤波器能量的对数。
- 取对数滤波器组能量的DCT。
- 保留DCT系数较低的12-13个,其余的丢弃,便得到MFCC特征。
此外,还有一些更常见的操作,有时帧能量被附加到每个特征向量。通常还会附加Delta和Delta-Delta特性。同态滤波也通常应用于最终的特征。
为什么这么做?
现在我们将详细介绍这些步骤,并解释为什么每个步骤都是必要的。
音频信号是不断变化的,所以为了简化问题,我们假设音频信号在短时间内变化不大(当我们说它不变时,我们的意思是统计上的,即统计上的平稳,很明显,即使在短时间内样本也在不断变化)。这就是为什么我们把信号帧为20-40ms。如果帧较短,我们没有足够的样本来得到可靠的光谱估计,如果帧较长,整个帧内的信号变化太多。
下一步是计算每帧的功率谱。受到人类耳蜗(耳朵里的一个器官)的启发,即耳蜗根据传入声音的频率在不同的地方振动,根据耳蜗中震动的位置(震动的是小毛),不同的神经发出信号,告知大脑某些频率的存在。我们的周期图估计值为我们执行了类似的工作,识别帧中出现的频率。
周期图谱估计仍然包含许多ASR不需要的信息。特别是耳蜗无法分辨两个紧密间隔的频率之间的差别。随着频率的增加,这种效应变得更加明显。由于这个原因,我们取一组周期图箱,并把它们加起来,以了解在不同的频率区域存在多少能量。这是由我们的梅尔过滤器库完成的:第一个滤波器非常窄的,它给出了0赫兹附近存在多少能量的指示。当频率越高,我们的滤波器就越宽,因为我们对变化的关注就越少。我们只对每个点的能量感兴趣。梅尔尺度精确地告诉我们如何放置过滤器,以及如何制作过滤器。有关如何计算间距,请参阅下面。
一旦我们有了过滤器的能量,我们对它们取对数。这也是受到人类听觉启发的:我们听不到线性尺度上的响度。一般来说,要使一个声音的感知音量翻倍,我们需要投入8倍的能量。这意味着,如果一开始声音就很大,那么能量的巨大变化可能听起来并没有那么大的区别。这种压缩操作使我们的特性与人类实际听到的更接近。为什么是对数而不是立方根?对数允许我们使用倒谱平均减法,这是一种信道标准化技术。
最后一步是计算对数滤波器组能量的DCT。执行此操作的主要原因有两个。因为我们的滤波器都是重叠的,所以滤波器能量是相互关联的。DCT能够将能量去相关,这意味着对角协方差矩阵可以用来特征建模,如HMM分类器。但是注意,26个DCT系数中只有12个保留了下来。这是因为更高的DCT系数表示了过滤器库能量的快速变化,而这些快速的变化实际上降低了ASR性能,所以我们通过降低它们得到了一个小的改进。
什么是梅尔尺度?
Mel scale即梅尔尺度,将纯音的感知频率或音高与其实际测量频率联系起来。人类在低频时比在高频时更能辨别音调的细微变化。结合这个尺度使我们的特征与人类听到的更接近。
由频率到Mel scale的换算公式为:
M
(
f
)
=
1125
ln
(
1
+
f
/
700
)
(
1
)
M(f)=1125\ln(1+f/700)\qquad\qquad\qquad\qquad (1)
M(f)=1125ln(1+f/700)(1)
反过来,由Mel scale到频率的公式为:
M
−
1
(
m
)
=
700
(
exp
(
m
/
1125
)
−
1
)
(
2
)
M^{-1}(m)=700(\exp(m/1125)-1)\qquad\qquad\qquad(2)
M−1(m)=700(exp(m/1125)−1)(2)
实现细节
我们从一个语音信号开始,假设采样频率为16kHz。
1.分帧。将语音信号分为20-40ms每帧,这里是25ms。这意味着16kHz信号的帧长为0.025*16000 = 400个样本点。帧步长通常约为10ms(160个样本点),这样一来帧之间就会有重叠的部分(重叠部分为 25 − 10 = 15 m s 25-10=15ms 25−10=15ms) 。第一个400个样本点的帧从样本0开始,下一个400个样本点的帧从样本160开始,以此类推,直到到达语音文件的末尾。分割后,如果语音文件的最后一帧不是400个样本点,那么用0填充到400个样本点。
接下来的步骤应用于每一帧,每帧提取一组12个MFCC系数。顺便提一下符号:我们称 s ( n ) s(n) s(n)为时域信号,分帧后我们得到 s i ( n ) s_i(n) si(n),其中 n n n的范围是1-400(假设每帧有400个样本), i i i表示第 i i i帧。当我们进行离散傅里叶变换DFT后,得到 S i ( k ) S_i(k) Si(k),其中 i i i表示与时域对应的帧号。 P i ( k ) P_i(k) Pi(k)表示第 i i i帧的功率谱。
2.对帧进行离散傅里叶变换:
S
i
(
k
)
=
∑
n
=
1
N
s
i
(
n
)
h
(
n
)
e
−
j
2
π
k
n
/
N
1
≤
k
≤
K
S_i(k)=\sum^{N}_{n=1}s_i(n)h(n)e^{-j2\pi kn/N} \qquad 1\le k \le K
Si(k)=n=1∑Nsi(n)h(n)e−j2πkn/N1≤k≤K
其中
h
(
n
)
h(n)
h(n)是长度为
N
N
N个样本数的窗口(如汉明窗),
K
K
K是DFT的长度,
s
i
(
n
)
s_i(n)
si(n)的基于周期图的功率谱估计为:
P
i
(
k
)
=
1
N
∣
S
i
(
k
)
∣
2
P_i(k)=\frac{1}{N}|S_i(k)|^2
Pi(k)=N1∣Si(k)∣2
这叫做功率谱的周期图估计。我们通常执行512点快速离散傅里叶变换(FFT),只保留前257个系数。
3.计算梅尔滤波器。这是一组20-40(26是标准)三角滤波器,我们将其应用在步骤2中得到的的周期图功率谱估计中。我们的滤波器租以26个长度为257的向量的形式出现(与步骤2中FFT数量一致)。每个向量大多为零,但在频谱的某一特定区域内都是非零的。为了计算滤波器组能量,我们将每个滤波器组与功率谱相乘,然后将系数相加。完成此操作后,我们剩下26个数字,这些数字指示每个滤波器组中有多少能量。有关如何计算滤波器组的详细说明,请参见下面。这里给出一些图帮助理解。
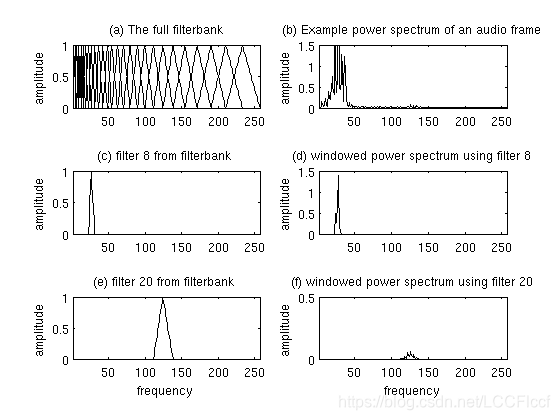
4.对步骤3中的26个能量取对数。
5.对26个对数滤波器组能量进行离散余弦变换(DCT)得到26个倒谱系数。对于ASR,只保留26个系数中较低的12-13个。
得到的特征(每帧12个数字)称为梅尔倒谱系数MFCC。
Computing the Mel filterbank
在本节中,为了便于显示,使用了10个滤波器组,实际上您将使用26-40个滤波器组。
要获得如图1(a)所示的滤波器库,我们首先必须选择一个较低和较高的频率。较好的值是较低的值为300Hz和较高的值为8000Hz。当然,如果语音采样的频率是8000赫兹,我们的上频率限制在4000赫兹。然后遵循以下步骤:
-
利用公式(1),将上下频率转换为Mel scale。我们这里300Hz是401.25 Mels, 8000Hz是2834.99 Mels。
-
在这个例子中,我们将使用10个过滤器组,为此我们需要12个点。这意味着我们需要10个额外的点,以401.25到2834.99为线性间隔。结果是:
m(i) = 401.25, 622.50, 843.75, 1065.00, 1286.25, 1507.50, 1728.74, 1949.99, 2171.24, 2392.49, 2613.74, 2834.99 -
现在用方程2把它们转换回赫兹
h(i) = 300, 517.33, 781.90, 1103.97, 1496.04, 1973.32, 2554.33, 3261.62, 4122.63, 5170.76, 6446.70, 8000注意我们的起点和终点都在我们想要的频率上。
-
我们没有在上面计算的精确点上放置滤波器所需的频率分辨率,所以我们需要将这些频率四舍五入到最近的FFT bin中。这个过程不影响特征的准确性。要将频率转换为FFT bin编号,我们需要知道FFT大小和采样率:
f(i) = floor((nfft+1)*h(i)/sample_rate)结果如下:
f(i) = 9, 16, 25, 35, 47, 63, 81, 104, 132, 165, 206, 256我们可以看到最终的滤波器组结束于bin 256,它对应于8000Hz和512点FFT大小。
-
现在我们创建滤波器组。第一个滤波器组将从第一个点开始,在第二个点达到峰值,然后在第三个点返回零。第二个滤波器将从第2点开始,在第3点达到最大值,然后在第4点为零,以此类推。计算公式如下:
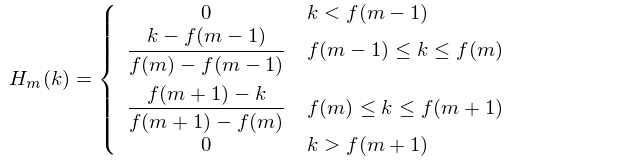
其中 M M M是我们想要的过滤器的数量, f ( ) f() f()是M+ 2 Mel间隔频率的列表。
最终所有10个相互重叠的过滤器的图如下:
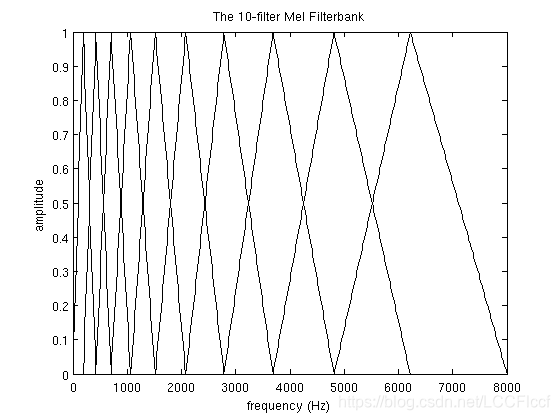
这个滤波器组是从0Hz开始,到8000Hz结束,这只是一个简单的示例。上面的example是从300Hz开始的。
Deltas and Delta-Deltas
也称为微分和加速度系数。MFCC特征向量只描述单个帧的功率谱包络线,但似乎语音在动态中也有信息,比如MFCC系数随时间的轨迹。结果表明,计算MFCC轨迹并将其附加到原始特征向量上可以大大提高ASR性能(如果我们有12个MFCC系数,我们还会得到12个delta系数,这将结合起来得到长度为24的特征向量)。
为了计算delta系数,使用以下公式:
d
t
=
∑
n
=
1
N
n
(
c
t
+
n
−
c
t
−
n
)
2
∑
n
=
1
N
n
2
d_t=\frac{\sum^N_{n=1}n(c_{t+n}-c_{t-n})}{2\sum^N_{n=1}n^2}
dt=2∑n=1Nn2∑n=1Nn(ct+n−ct−n)
其中
d
t
d_t
dt是delta系数,t帧中从静态系数
c
t
+
N
c_{t+N}
ct+N到
c
t
−
N
c_{t-N}
ct−N中计算得到的,N=2。(加速度)系数的计算方法也是一样的,但它们是由deltas来计算的,而不是静态系数。
Implementations
代码传送门 here

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)