
stata 倾向得分匹配操作
ssc install psmatch2,replace*安装倾向得分匹配命令包cd "C:\Users\Administrator\Desktop\stata work" *设置工作路径use ldw_exper.dta,clear*读取数据(数据放在工作路径)reg re78 t,r*做一元线性回归作为参照(re78表示1978年实际收入,t是否参加培训)*...
倾向得分匹配法是一种研究方法,它在研究某项治疗、政策、或者其他事件的影响因素上很常见。对于经济、金融学领域来说,比如需要研究某个劳动者接受某种高等教育对其收入的影响,或者比如研究某个企业运用了某项管理层激励措施以后对企业业绩的影响。如果我们简单地将是否执行了某项时间作为虚拟变量,而对总体进行回归的话,参数估计就会产生偏误,因为在这样的情况下,我们只观察到了某一个对象他因为发生了某一事件后产生的表现,并且拿这种表现去和另一些没有发生这件事情的其他对象去做比较。这样的比较显然是不科学的,因为比较的基础并不同。
通俗地说,我们真正要做的是考虑,如果拿小明来说,小明读了研究生和小明没有读研究生,他的收入会差多少?可是小明已经读了研究生,我怎么才能估计出他要是不读研究生,他的收入会是多少呢?
于是,我们引入“倾向得分匹配”这样一种研究方法。英文叫Propensity Score Matching。这种方法能让我们从一大堆没有参加培训的人群中(也就是我们的总体样本的一个子集),对每个人读研究生的概率进行估计,然后选出和小明具有非常相似的去读研究生的概率,可是没有去读的同学小刚——作为小明的对照,然后再来看他们的区别。当样本中的每个研究生”小明“都找到了匹配的非研究生”小刚“,我们便能对这两组样本进行比较研究了。
下面以陈强高级计量经济学及stata应用书中的例子来实现倾向得分匹配的应用,该案例研究参加就业培训是否能显著提高实际收入。数据附文后(百度网盘提取)
ssc install psmatch2,replace *安装倾向得分匹配命令包
cd "C:\Users\Administrator\Desktop\stata work" *设置工作路径
use ldw_exper.dta,clear *读取数据(数据放在工作路径)
reg re78 t,r *做一元线性回归作为参照 (re78表示1978年实际收入,t是否参加培训)

*在未控制任何协变量的情况下,平均处理效应为1.794,即参加培训的平均比没有参加培训的收入高1.794千美元
reg re78 t age educ black hisp married re74 re75 u74 u75,r
*age为年龄,educ为教育年限,black为是否黑人,hisp是否拉丁裔,married(是否已婚),re74,re75表示1974年,1975年实际收入,u74,u75表示1974年,1975年是否失业
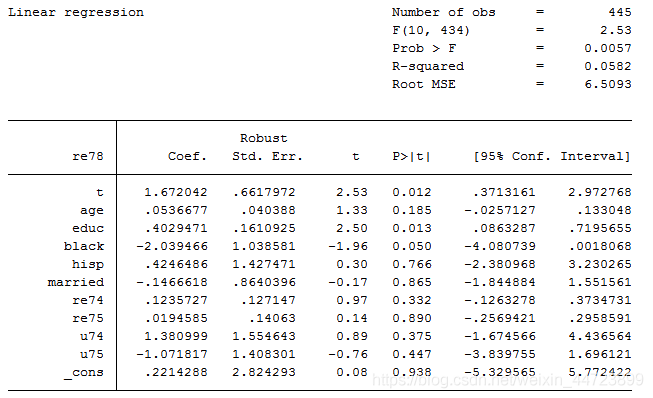
*加入协变量后,处理效应略有下降,1.672和之前比变化不大,协变量中黑人和教育显著,其它不显著
*下面进行一对一匹配
psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) n(1) ate ties logit common
t为处理变量,后面均为协变量,re78为结果变量,logit来估计结果,ties表包括所有倾向得分相同的并列个体,ate表同时汇报ATE,ATU,ATT,common表示仅对共同取值范围内个体
*进行匹配
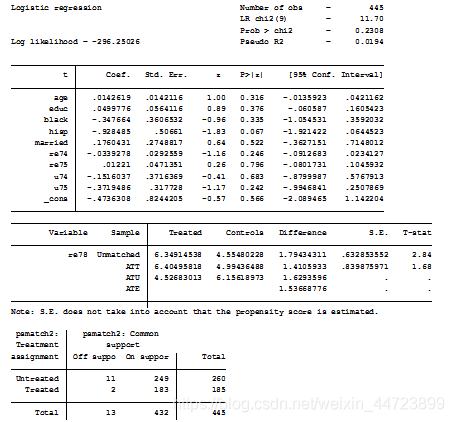
结果显示,ATT=1.41,t=1.68小于临界值,不显著ATE,ATU类似。Unmatched表示不匹配的结果,和一元回归结果一样,最下面显示控制组有11个不在共同范围内,处理组有2个不*在共同范围,其余432个均在范围内
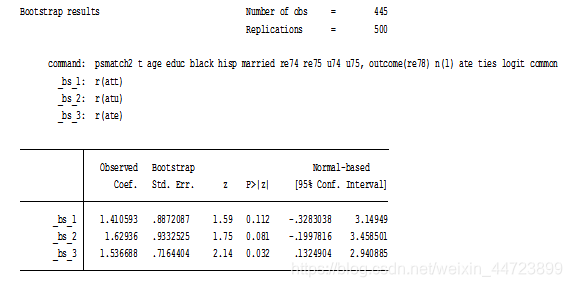
*考虑自助法估计标准误
set seed 2019
bootstrap r(att) r(atu) r(ate),reps(500):psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) n(1) ate ties logit common
*下面使用pstest来考查匹配结果是否较好平衡了数据
quiet psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) n(1) ate ties logit common
pstest age educ black hisp married re74 re75 u74 u75,both graph

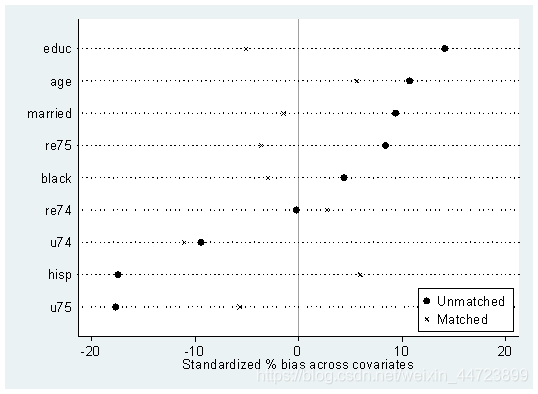
*下面画条形图来显示倾向得分匹配的共同取值范围
psgraph
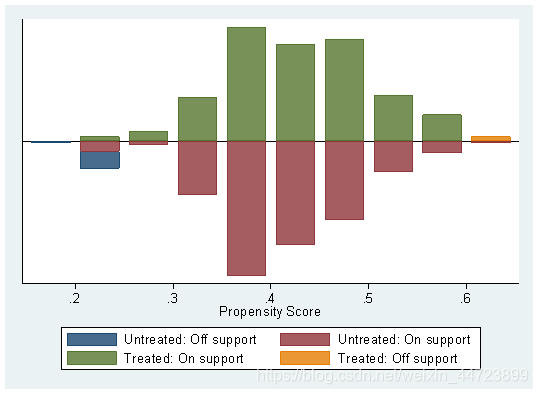
*从上图可以直观看出,大多数均在共同取值范围内(on support),匹配时仅会损失少量样
*本
*下面进行k近邻匹配,令k=4,节省空间,采用quietly省去结果的汇报
psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) n(4) ate ties logit common quietly
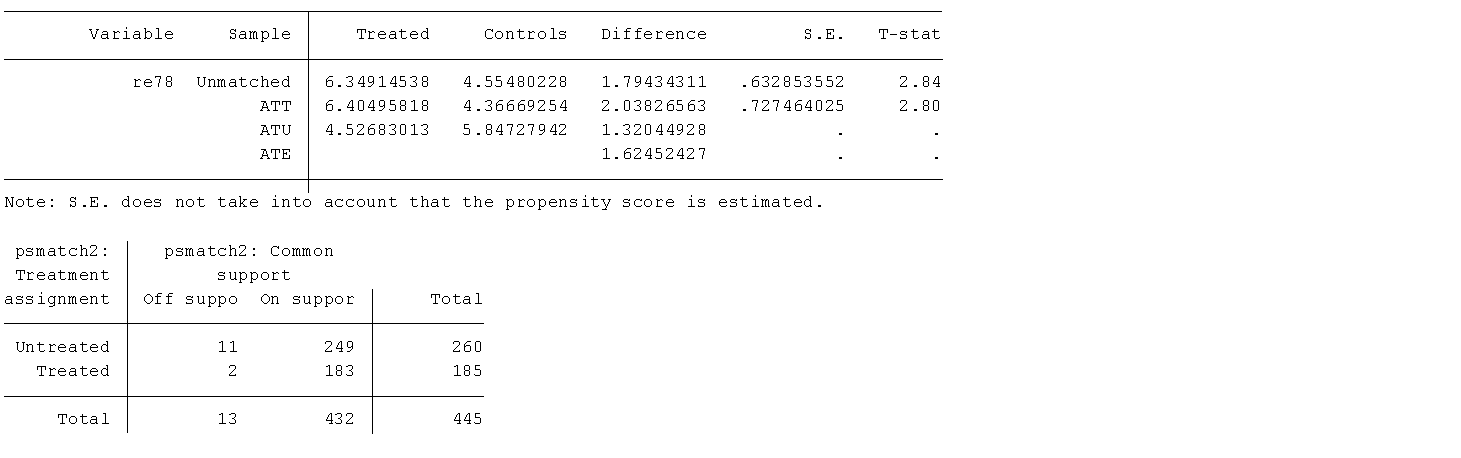
*上表显示,一对四匹配和一对一匹配类似,下面进行卡尺内一对四匹配,首先计算倾向得分的标准差,乘以0.25

sum _pscore
dis 0.25*r(sd)
0.01979237
*由此可知0.25倍的标准差约等于0.02,将卡尺范围定为0.01,对倾向得分相差1%的观测
*值进行一对四匹配
psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) n(4) cal(0.01) ate ties logit common quietly
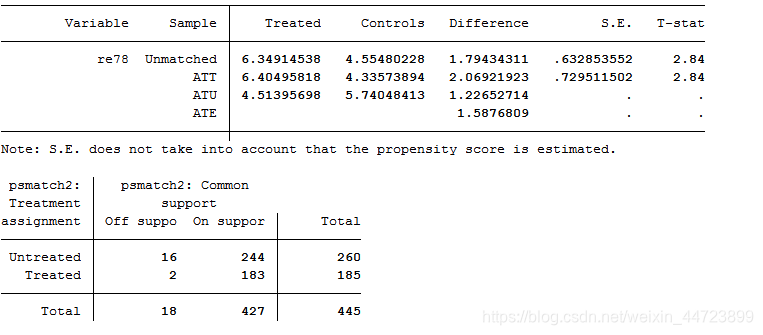
*上表显示,大多数一对四匹配发生在卡尺0.01范围内,不存在太远的近邻,进行半径(卡尺)匹配
psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) radius cal(0.01) ate ties logit common quietly
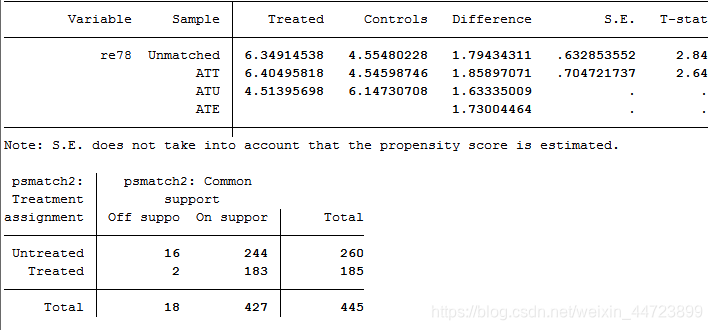
*匹配结果依然类似,下面进行核匹配
psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) kernel ate ties logit common quietly
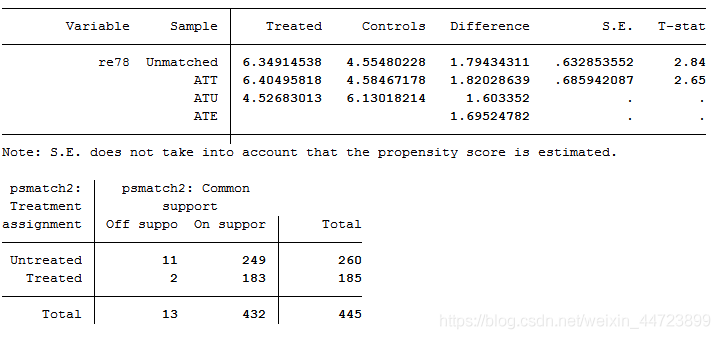
*结果依然类似,进行局部线性回归匹配(使用默认核函数与带宽)
psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) llr ate ties logit common quietly
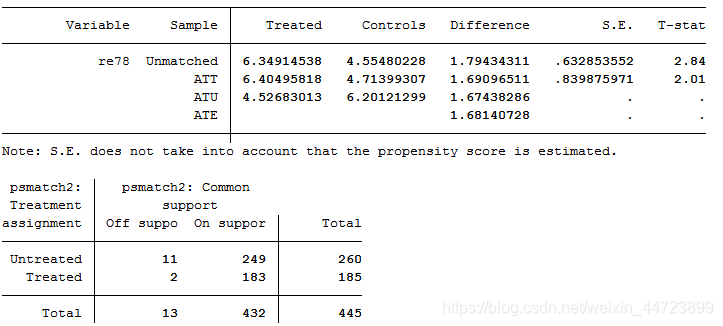
*上表未汇报ATT标准误,采用自助法得到标准误
set seed 2019
bootstrap r(att) r(atu) r(ate),reps(500):psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) llr ate ties logit common quietly
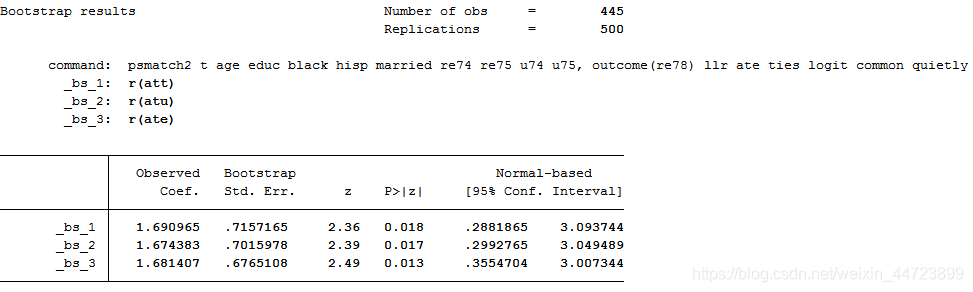
*根据上表自助标准误,对平均处理效应的三种度量均至少在5%水平上显著
*下面进行条匹配(同样使用自助法),先安装一个非官方命令spline
findit snp7_1
set seed 2019
bootstrap r(att) r(atu) r(ate),reps(500):psmatch2 t age educ black hisp married re74 re75 u74 u75,outcome(re78) spline ate ties logit common quietly
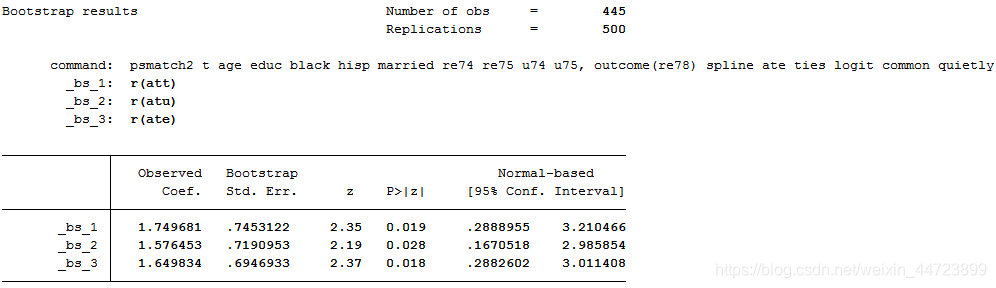
*估计结果仍然类似,总之,以上各匹配得分结果显示,参加就业培训的平均处理效应为正,在经济意义和统计意义上均显著
*最后进行马氏匹配,计算异方差稳健标准误
psmatch2 t, outcome(re78) mahal(age educ black hisp married re74 re75 u74 u75) n(4) ai(4) ate
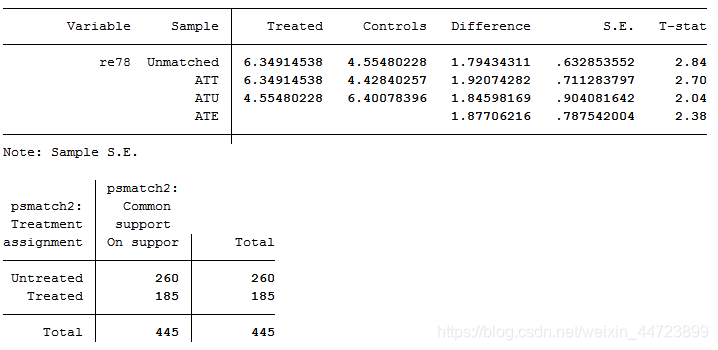
*分析结果类似,证实上述结果非常稳健
链接:https://pan.baidu.com/s/18pReupZyZQpS2Wfxe1GV1A
提取码:wuih
本操作使用的数据请从百度云盘提取

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 82
82 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)