




- @weixin_44723899
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
#1.6 字典的基本操作# 创建字典d = dict() #创建一个空字典d = {}type(d)dictlist1 = [("a",'ok'),('1','lk'),("001",'lk')]#列表中嵌套元组d1 = dict(list1)print(d1){'a': 'ok', '1': 'lk', '001': 'lk'}list11 = [("a",'ok'),('a','lk'),("
摘要 本案例使用PyTorch框架构建MLP神经网络模型实现MNIST手写数字识别。主要步骤包括:设置随机种子保证结果可重复性;加载MNIST数据集并进行标准化预处理,计算训练集的均值和标准差;定义包含随机旋转、随机裁剪等数据增强的transform操作;划分90%训练集和10%验证集;展示预处理后的样本图像以验证数据增强效果。案例完整实现了从数据准备到模型构建的流程,为后续的神经网络训练和评估奠

摘要 本案例使用PyTorch框架构建MLP神经网络模型实现MNIST手写数字识别。主要步骤包括:设置随机种子保证结果可重复性;加载MNIST数据集并进行标准化预处理,计算训练集的均值和标准差;定义包含随机旋转、随机裁剪等数据增强的transform操作;划分90%训练集和10%验证集;展示预处理后的样本图像以验证数据增强效果。案例完整实现了从数据准备到模型构建的流程,为后续的神经网络训练和评估奠
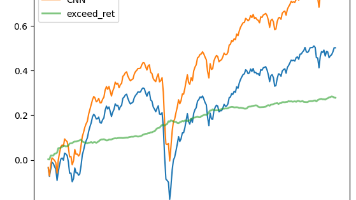
本案例展示了使用卷积神经网络(CNN)分析股票K线图来预测价格趋势。采用1993-2001年的月度20日K线数据作为训练集,构建了一个包含3个卷积层和1个全连接层的CNN模型。模型采用LeakyReLU激活函数和Xavier权重初始化,并加入了批量归一化和Dropout层以防止过拟合。数据被划分为70%训练集和30%验证集,通过PyTorch框架实现数据加载和模型训练。该案例演示了如何将CNN应用
摘要 本案例使用PyTorch框架构建MLP神经网络模型实现MNIST手写数字识别。主要步骤包括:设置随机种子保证结果可重复性;加载MNIST数据集并进行标准化预处理,计算训练集的均值和标准差;定义包含随机旋转、随机裁剪等数据增强的transform操作;划分90%训练集和10%验证集;展示预处理后的样本图像以验证数据增强效果。案例完整实现了从数据准备到模型构建的流程,为后续的神经网络训练和评估奠
信用卡欺诈检测案例摘要 本案例使用欧洲持卡人2013年9月的信用卡交易数据,包含284,807笔交易,其中仅492笔为欺诈(占比0.172%)。数据经过PCA处理,包含28个主成分特征(V1-V28)以及时间和金额两个原始特征。案例展示了数据读取、探索性分析(EDA)和模型构建过程,使用Adaboost、Gradient Boosting和XGBoost等算法处理高度不平衡的分类问题。测试集比例为

本文基于电商平台手机评论数据,使用SVM模型进行情感分析。数据集包含8186条评论,分为好评(1)、中评(0)和差评(-1)三类。通过jieba进行中文分词处理,并利用WordCloud生成词云图直观展示不同情感评论的高频词汇。为提升模型效果,建立了停用词表去除"手机"等无区分意义的词语。案例展示了从文本预处理到情感分类的完整流程,为电商平台分析用户评价提供了实用方法。

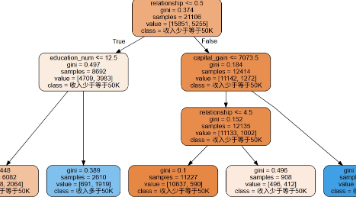
摘要 本案例使用决策树模型预测成年人收入水平(是否大于50K)。数据集包含年龄、工作类别、教育程度等特征。首先对数据进行预处理:删除含"?"的异常值,合并相似教育等级(如将1st-4th等合并为Elementary-School)。然后划分训练集和测试集,使用LabelEncoder对分类变量进行编码。通过决策树分类器建模,评估模型在准确率、精确率和召回率等指标上的表现。案例展示了从数据清洗到模型
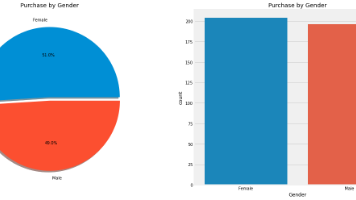
本案例基于社交网络广告数据,使用KNN算法预测用户购车行为。数据集包含400名用户的年龄、薪资和购车决策信息,平均年龄37岁,平均薪资69,742美元。分析显示64.2%用户未购车。通过标准化处理特征数据后,构建KNN分类模型(n_neighbors=1)进行训练。案例展示了从数据探索到模型构建的全过程,旨在实现汽车广告的精准投放。可视化分析包括性别分布、薪资分布和购车比例等关键指标。
# 5.6 支持向量机#汽车评价数据,6个特征变量,1个分类标签,共1728条记录#要求取1690条记录作为训练集,余下的作为测试集,计算预测准确率import numpy as npimport pandas as pdimport osos.chdir("C:\\Users\\Administrator\\Desktop")#更改工作路径,注意双\\ 任何操作前可以先将常用包和路径先设置好#