深度学习的激活函数 :sigmoid、tanh、ReLU 、Leaky Relu、RReLU、softsign 、softplus、GELU
【 tensorflow中文文档:tensorflow 的激活函数有哪些】激活函数可以分为两大类 :饱和激活函数:sigmoid、 tanh非饱和激活函数:ReLU 、Leaky Relu、ELU【指数线性单元】、PReLU【参数化的ReLU 】、RReLU【随机ReLU】相对于饱和激活函数,使用“非饱和激活函数”的优势在于两点:1.首先,“非饱和激活...
【 tensorflow中文文档:tensorflow 的激活函数有哪些】

激活函数可以分为两大类 :
- 饱和激活函数: sigmoid、 tanh
- 非饱和激活函数: ReLU 、Leaky Relu 、ELU【指数线性单元】、PReLU【参数化的ReLU 】、RReLU【随机ReLU】
相对于饱和激活函数,使用“非饱和激活函数”的优势在于两点:
1.首先,“非饱和激活函数”能解决深度神经网络【层数非常多!!】的“梯度消失”问题,浅层网络【三五层那种】才用sigmoid 作为激活函数。
2.其次,它能加快收敛速度。
目录
(2)tanh (双曲正切函数 ;Hyperbolic tangent function)
(3) relu (Rectified linear unit; 修正线性单元 )
(4)Leaky Relu (带泄漏单元的relu ) (5) RReLU(随机ReLU)
(6)softsign (7)softplus (8)Softmax
(1)sigmoid 函数 (以前最常用)

参数 α > 0 可控制其斜率。 sigmoid 将一个实值输入压缩至[0,1]的范围,也可用于二分类的输出层。
(2)tanh (双曲正切函数 ;Hyperbolic tangent function)

将 一个实值输入压缩至 [-1, 1]的范围,这类函数具有平滑和渐近性,并保持单调性.

(3) relu (Rectified linear unit; 修正线性单元 )
深度学习目前最常用的激活函数
# Relu在tensorflow中的实现: 直接调用函数
tf.nn.relu( features, name= None )
与Sigmoid/tanh函数相比,ReLu激活函数的优点是:
- 使用梯度下降(GD)法时,收敛速度更快
- 相比Relu只需要一个门限值,即可以得到激活值,计算速度更快
缺点是: Relu的输入值为负的时候,输出始终为0,其一阶导数也始终为0,这样会导致神经元不能更新参数,也就是神经元不学习了,这种现象叫做“Dead Neuron”。
为了解决Relu函数这个缺点,在Relu函数的负半区间引入一个泄露(Leaky)值,所以称为Leaky Relu函数。
(4)Leaky Relu (带泄漏单元的relu )
数学表达式: y = max(0, x) + leak*min(0,x)
与 ReLu 相比 ,leak 给所有负值赋予一个非零斜率, leak是一个很小的常数 ,这样保留了一些负轴的值,使得负轴的信息不会全部丢失)

#leakyRelu在tennsorflow中的简单实现
tf.maximum(leak * x, x),比较高效的写法为:
import tensorflow as tf
def LeakyReLU(x,leak=0.2,name="LeakyReLU"):
with tf.variable_scope(name):
f1 = 0.5*(1 + leak)
f2 = 0.5*(1 - leak)
return f1*x+f2*tf.abs(x)
(5) RReLU(随机ReLU)
在训练时使用RReLU作为激活函数,则需要从均匀分布U(I,u)中随机抽取的一个数值 ,作为负值的斜率。
(6)softsign
数学表达式:
,导数:

(7)softplus
Softplus函数是Logistic-Sigmoid函数原函数。 ,加了1是为了保证非负性。Softplus可以看作是强制非负校正函数max(0,x)平滑版本。红色的即为ReLU。
(8)Softmax
用于多分类神经网络输出
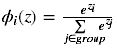
(11)GELU :高斯误差线性单元
在这篇论文中,作者展示了几个使用GELU的神经网络优于使用ReLU作为激活的神经网络的实例。GELU也被用于BERT。
GELU、ReLU和LeakyReLU的函数
def gelu(x):
return 0.5 * x * (1 + math.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * math.pow(x, 3))))
def relu(x):
return max(x, 0)
def lrelu(x):
return max(0.01*x, x)
以下两个是以前使用的:
(9)阈值函数 、阶梯函数

相应的输出 为
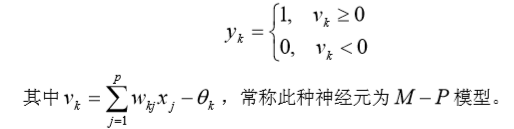
(10)分段线性函数
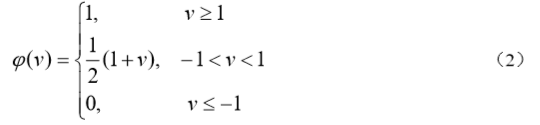
它类似于一个放大系数为 1 的非线性放大器,当工作于线性区时它是一个线性组合器, 放大系数趋于无穷大时变成一个阈值单元。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)