
【Spark】Springboot搭建spark脚手架
文章目录前言装备ProjectNoteManvenApplication.ymlCore-codeSparkApplication(程序启动入口)SparkJob(抽象每个SparkJob的父类)job使用(demo)启动SparkJobGitHubAuthor前言Spark开发的脚手架。试过原生spark,spring+spark,springboot+spark,但不得不说,确实还是喜欢...
文章目录
Github
地址:https://github.com/ithuhui/hui-bigdata-spark
模块:【hui-bigdata-spark-starter】
分支:master
位置:com.hui.bigdata.SparkApplication
Note
Spark开发的脚手架。
试过原生spark,spring+spark,springboot+spark,但不得不说,确实还是喜欢springboot,因此自己集成一个springboot做spark开发的脚手架。
声明,个人真的很不喜欢很多不同的博客,确实同一个文章(抄袭来抄袭去)并且不实际的东西。
提以下几点
- 网上的抄袭太严重,很多用‘web结构的大数据‘让我很懵,service,dao,controller都冒出来了。
- 如果纯粹的跑数据,大数据跟controller木有半毛钱关系,也不应该用’浏览器访问url‘来启动spark任务
- 基于上述,自己琢磨了一下,做了个简单好用的脚手架
- 配置要实现抽离,利用springboot的autoconfig
- 根据CDH或者其他大数据平台集群,需要做相应的jar包版本调整。
Ready
- IDEA
- MAVEN
Project
Note
- 项目结构:
├─hui-bigdata-spark-common(公共组件)
│ └─src
│ └─main
│ └─java
│ └─com
│ └─hui
│ └─bigdata
│ └─common
│ ├─spark
│ └─utils
├─hui-bigdata-spark-starter(启动类)
│ └─src
│ └─main
│ ├─java
│ │ └─com
│ │ └─hui
│ │ └─bigdata
│ │ └─config
│ └─resources
├─hui-bigdata-statistics-a(统计模块A)
│ └─src
│ └─main
│ └─java
│ └─com
│ └─hui
│ └─bigdata
│ └─statistics
│ ├─config
│ ├─job
│ └─model
├─hui-bigdata-statistics-b(统计模块B)
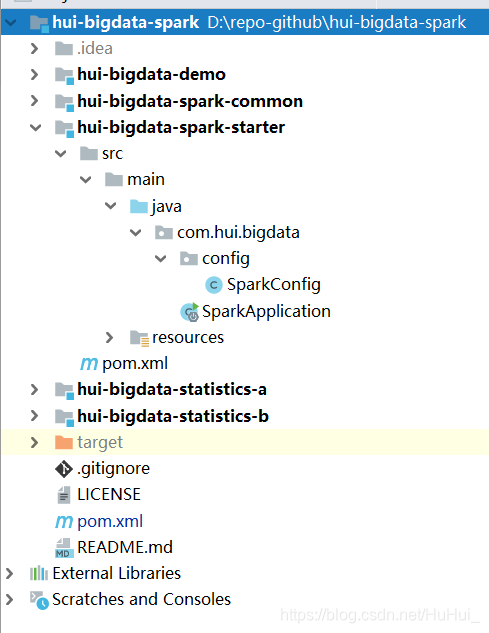
- 划分模块的说明:
- 希望统计模块可复用。(如果公司有相同业务,只是数据源不一样,直接引入该模块做少量配置即可)
- starter 模块是程序的启动入口。不管什么spark统计任务,只需要把该脚手架复制一份,并且引入统计模块A/B/…即可
- demo是原生跑spark的一些例子
Manven
<!-- springboot -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
</parent>
<!-- 根据项目,按需引入 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
Application.yml
#应用名
spring:
application:
name: hui-bigdata-spark
#端口号
server:
port: 8081
#sparkconfig配置
spark:
app-name: hui
master: local[4]
spark-home: 1
Core-code
SparkApplication(程序启动入口)
原理是参数传入类路径通过反射获取类信息,并且使用到了springboot的implements CommandLineRunner让容器启动完成的时候执行。
package com.hui.bigdata;
import com.hui.bigdata.common.spark.SparkJob;
import com.hui.bigdata.common.utils.SpringBootBeanUtils;
import com.hui.bigdata.config.SparkConfig;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.util.Utils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* <b><code>SparkApplication</code></b>
* <p/>
* Description
* <p/>
* <b>Creation Time:</b> 2019/4/12 9:55.
*
* @author Hu-Weihui
* @since hui-bigdata-springboot ${PROJECT_VERSION}
*/
@SpringBootApplication
public class SparkApplication implements CommandLineRunner {
@Autowired
private SparkConfig sparkConfig;
public static void main(String[] args) {
SpringApplication.run(SparkApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
// 初始化Spark环境
SparkConf sparkConf = new SparkConf()
.setAppName(sparkConfig.getAppName())
.setMaster(sparkConfig.getMaster());
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
String className = args[0];
Class clazz = Utils.classForName(className);
Object sparkJob = SpringBootBeanUtils.getBean(clazz);
if (sparkJob instanceof SparkJob){
((SparkJob) sparkJob).execute(javaSparkContext);
}
}
}
SparkJob(抽象每个SparkJob的父类)
package com.hui.bigdata.common.spark;
import lombok.extern.slf4j.Slf4j;
import org.apache.spark.api.java.JavaSparkContext;
import java.io.Serializable;
/**
* <b><code>SparkJob</code></b>
* <p/>
* Description
* <p/>
* <b>Creation Time:</b> 2019/4/12 10:01.
*
* @author Hu-Weihui
* @since hui-bigdata-springboot ${PROJECT_VERSION}
*/
@Slf4j
public abstract class SparkJob implements Serializable {
/**
* Instantiates a new Spark job.
*/
protected SparkJob(){};
/**
* 带参数
*
* @param javaSparkContext the java spark context
* @param args the args
* @author HuWeihui
* @since hui_project v1
*/
public void execute(JavaSparkContext javaSparkContext, String[] args) {
};
/**
* 不带参数
*
* @param javaSparkContext the java spark context
* @author HuWeihui
* @since hui_project v1
*/
public void execute(JavaSparkContext javaSparkContext) {
};
}
job使用(demo)
package com.hui.bigdata.statistics.job;
import com.hui.bigdata.common.spark.SparkJob;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.springframework.stereotype.Component;
import scala.Tuple2;
import java.beans.Transient;
import java.util.Arrays;
/**
* <b><code>StatisticsJob</code></b>
* <p/>
* Description
* <p/>
* <b>Creation Time:</b> 2019/4/18 19:25.
*
* @author Hu-Weihui
* @since hui-bigdata-spark ${PROJECT_VERSION}
*/
@Component
public class StatisticsJob extends SparkJob {
@Override
public void execute(JavaSparkContext javaSparkContext) {
JavaRDD<Integer> parallelize = javaSparkContext.parallelize(Arrays.asList(1, 2, 3, 4), 3);
Tuple2<Integer, Integer> reduce = parallelize.mapToPair(x -> new Tuple2<>(x, 1))
.reduce((x, y) -> getReduce(x, y));
System.out.println("数组sum:" + reduce._1 + " 计算次数:" + (reduce._2 - 1));
}
@Transient
public Tuple2 getReduce(Tuple2<Integer, Integer> x, Tuple2<Integer, Integer> y) {
Integer a = x._1();
Integer b = x._2();
a += y._1();
b += y._2();
return new Tuple2(a, b);
}
}
启动SparkJob
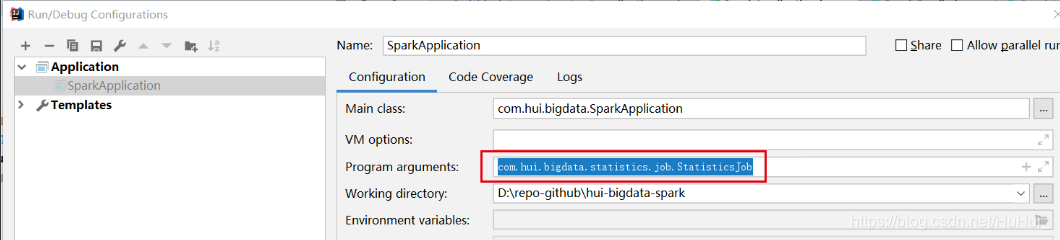
IDEA使用:只要在Program arguments传入需要执行的Job用Main函数启动即可。
jar包同理,后面传参com.xxxx.job.xxxJob即可,run()方法会通过反射获取到类
GitHub
https://github.com/ithuhui/hui-bigdata-spark
Author
作者:HuHui
转载:欢迎一起讨论web和大数据问题,转载请注明作者和原文链接,感谢

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)