【笔记3-4】CS224N课程笔记 - 分类与神经网络
CS224N(四)Neural Networks神经网络:基础神经元单层神经元最大化边界目标函数反向传播神经网络tips正则化Dropout神经单元【笔记3-1】CS224N - 深度自然语言处理【笔记3-2】CS224N - 词向量表示 word2vec【笔记3-3】CS224N - 高级词向量表示CS224n:深度学习的自然语言处理(2017年冬季)1080p https://www...
【笔记3-1】CS224N课程笔记 - 深度自然语言处理
【笔记3-2】CS224N课程笔记 - 词向量表示 word2vec
【笔记3-3】CS224N课程笔记 - 高级词向量表示
【笔记3-5】CS224N课程笔记 - 依存分析
【笔记3-6】CS224N课程笔记 - RNN和语言模型
【笔记3-7】CS224N课程笔记 - 神经机器翻译seq2seq注意力机制
【笔记3-8】CS224N课程笔记 - 卷积神经网络
CS224n:深度学习的自然语言处理(2017年冬季)1080p https://www.bilibili.com/video/av28030942/
涉及到的论文:
Learning representations by back-propagating errors (David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams)
http://www.iro.umontreal.ca/~pift6266/A06/refs/backprop_old.pdf
Natural Language Processing (almost) from Scratch (Ronan Collobert, Jason Weston, Leon Bottou, Michael Karlen, Koray Kavukcuoglu, Pavel Kuksa)
https://arxiv.org/pdf/1103.0398.pdf
关键词:神经网络,前向计算,反向传播,神经单元,Max-margin Loss,梯度检查,参数初始化,学习率,adagrad
神经网络:基础
当数据集难以进行简单的线性划分时,需要借助神经网络来构造非线性分类边界。
神经元
神经元是通用的计算单元,接受n个输入产生一个输出。区别不同神经元输出的是它们的参数/权重。常见的神经元有sigmoid神经元或二元逻辑回归单元。该单元采用一个n维输入向量x,产生标量激活/输出值a。神经元还与一个n维权重向量w和一个偏置标量b相关。神经元的输出为 a = 1 1 + e x p ( − ( w T x + b ) ) = 1 1 + e x p ( − [ w T b ] ⋅ [ x 1 ] ) ) a=\frac{1}{1+exp(-(w^Tx+b))}=\frac{1}{1+exp(-[w^T \ b]\cdot[x \ 1]))} a=1+exp(−(wTx+b))1=1+exp(−[wT b]⋅[x 1]))1
单层神经元
考虑将输入数据x输入到多个神经元的情况。则有 a 1 = 1 1 + e x p ( − ( w ( 1 ) T ) + b 1 ) . . . a m = 1 1 + e x p ( − ( w ( m ) T ) + b m ) a_1=\frac{1}{1+exp(-(w^{(1)T})+b_1)}\\...\\a_m=\frac{1}{1+exp(-(w^{(m)T})+b_m)} a1=1+exp(−(w(1)T)+b1)1...am=1+exp(−(w(m)T)+bm)1这些激活可以看作是一些加权特征组合。可以使用这些激活的组合来执行分类任务。
最大化边界目标函数
与大多数机器学习模型一样,神经网络也需要优化目标,即最小化误差或最大化表现。一个常见的误差度量是最大边际目标,确保为“真”标记的数据点计算的分数高于为“假”标记的数据点计算的分数。
如果将“true”的计算得分称为 s s s,将“false”的计算得分称为 s c s_c sc(下标为c,表示corrupted)。目标函数就是最大化 s − s c s-s_c s−sc或最小化 s c − s s_c-s sc−s。对目标进行修改,确保只有在 s c > s , s − s c > 0 s_c > s,s-s_c >0 sc>s,s−sc>0时才计算误差。也就是说我们只关心“正确”数据点的得分高于“错误”数据点,其余都不重要。因此,我们希望 s c > s s_c > s sc>s时误差是 s c − s s_c-s sc−s,否则是0。
因此,优化目标为 m i n i m i z e J = m a x ( s c − s , 0 ) minimize \ J = max(s_c-s,0) minimize J=max(sc−s,0)但是,上面的优化目标存在一定风险,因为它没有创建一个安全边际。我们希望标记为“true”的得分比标记为“false”的得分高一些。因此修改优化目标为 m i n i m i z e J = m a x ( Δ + s c − s , 0 ) minimize \ J = max(\Delta+s_c-s,0) minimize J=max(Δ+sc−s,0)将这个边值缩放到 Δ = 1 \Delta=1 Δ=1,定义以下优化目标 m i n i m i z e J = m a x ( 1 + s c − s , 0 ) minimize \ J = max(1+s_c-s,0) minimize J=max(1+sc−s,0)其中, s c = U T f ( W x c + b ) , s = U T f ( W x + b ) , U s_c=U^Tf(Wx_c+b),s=U^Tf(Wx+b),U sc=UTf(Wxc+b),s=UTf(Wx+b),U表示从隐藏层激活函数值到输出层之间的权重向量。
反向传播
本节讨论成本J为正值时,如何在模型中训练不同的参数。如果代价为0,则不需要更新参数。由于通常使用梯度下降(或SGD等变量)更新参数,所以我们通常需要更新方程中所需的任何参数的梯度信息 θ ( t + 1 ) = θ ( t ) − α ▽ θ ( t ) J \theta_{(t+1)}=\theta_{(t)}-\alpha\triangledown _{\theta^{(t)}}J θ(t+1)=θ(t)−α▽θ(t)J反向传播是利用链式法则计算模型上任意参数的损失梯度的方法。为了帮助理解,本节将以一个简单的神经网络为例,对其执行反向传播。使用包含单个隐藏层和单个神经元输出的神经网络,其中:
- x i x_i xi是神经网络的输入;
- s s s是神经网络的输出;
- 每一层(包括输入层和输出层)都有神经元接收输入并产生输出,k层的第j个神经元接受标量输入 z j ( k ) z_j^{(k)} zj(k),生成标量激活输出 a j ( k ) a_j^{(k)} aj(k);
- 将在 z j ( k ) z_j^{(k)} zj(k)处产生的反向传播误差称为 δ j ( k ) \delta_j^{(k)} δj(k);
- 第一层指的是输入层而不是第一个隐藏层,对于输入层,有 x j = z j ( 1 ) = a j ( 1 ) x_j=z_j^{(1)}=a_j^{(1)} xj=zj(1)=aj(1);
- W ( k ) W^{(k)} W(k)是从第k层的输出到第k+1层的输入的转移矩阵
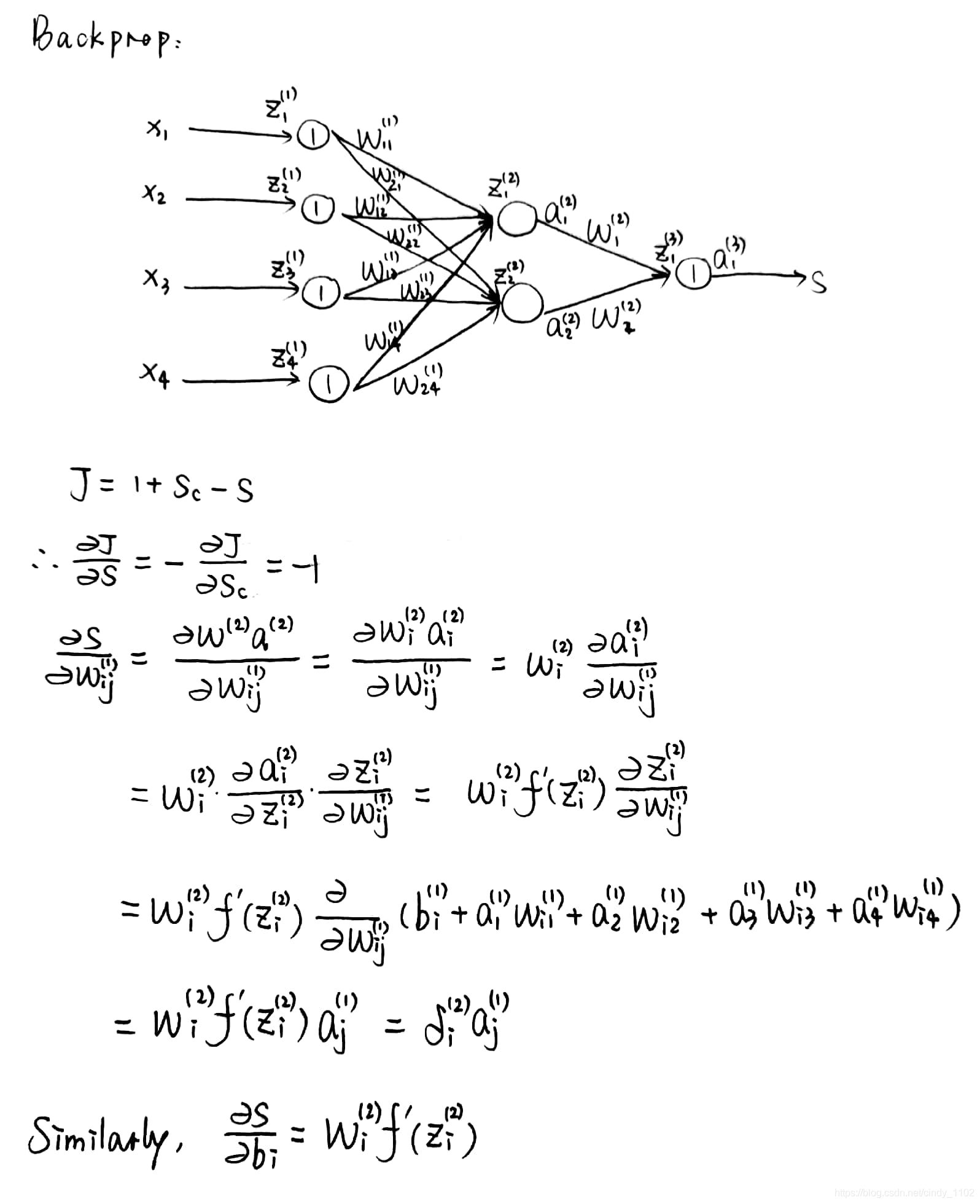
计算效率:在科学计算中,向量化的运行要快得多,如MATLAB或Pthon(使用NumPy/SciPy包)。因此应该在实践中使用向量化反向传播,同时减少重复计算。
神经网络tips
正则化
与许多机器学习模型一样,神经网络很容易过拟合。解决过拟合(也称“高方差问题”)的一种常见技术是引入L2正则化惩罚,只需在损失函数J中添加一个额外的项,这样总成本可以计算为 J R = J + λ ∑ i = 1 L ∣ ∣ W ( i ) ∣ ∣ F J_R=J+\lambda\sum_{i=1}^{L}||W^{(i)}||_F JR=J+λi=1∑L∣∣W(i)∣∣F其中, λ \lambda λ是一个超参数,控制正则化项相对于原成本函数的权重。
正则化的本质是在权重过大时进行惩罚,同时优化原始成本函数。由于Frobenius范数的二次性质(计算矩阵的平方和),L2正则化有效地减少了过拟合现象。施加这样的约束也可以解释为先验贝叶斯信念,即最优权值接近于零——接近的程度取决于 λ \lambda λ的值。选择正确的 λ \lambda λ值至关重要,必须通过超参数调优来选择。过高的 λ \lambda λ值会导致大多数权重设置过于接近于0,并且模型没有从训练数据中学到任何有意义的东西,常常在训练、验证和测试集上获得较差的准确性。过低则又会导致过拟合。
实际上,有时也会使用其他类型的正则化,比如L1正则化,它对参数元素的绝对值(而不是平方)求和——但是,在实践中很少使用这种方法,因为它会导致参数权重的稀疏性。
在下一节中,我们将讨论dropout,它通过在正向传递中随机删除(即设置为零)神经元,有效地充当另一种正则化形式。
必须指出的是,bias并没有被正则化,也不会对成本产生影响。
Dropout
Dropout是一种强大的正则化技术。在训练过程中,以一定的概率随机“丢弃”一个子集。然后在测试过程中,使用整个网络来预测。这样网络通常能从数据中学习更有意义的信息,不太可能过拟合,且通常能获得更高的整体性能。这种技术之所以如此有效一个直观的原因是,dropout所做的,本质上是同时训练成指数级的许多较小的网络,并对预测进行平均。
引入dropout的方法:取每一层神经元的输出h,并保持每个神经元的概率为p,否则将其设置为0。然后,在反向传播过程中,只通过在正向传播过程中保持活性的神经元传递梯度。最后,在测试过程中,用网络中的所有神经元来计算正向传递。
为了让dropout有效,预期的输出神经元在测试期间应该差不多。因此,通常必须在测试期间将每个神经元的输出除以某个值。
神经单元
之前讨论过包含sigmoid的神经网络,以引入非线性。在许多应用中,可以使用其他激活函数来设计网络。
- sigmoid
σ ( z ) = 1 1 + e x p ( − z ) σ ′ ( z ) = − e x p ( − z ) 1 + e x p ( − z ) = σ ( z ) ( 1 − σ ( z ) ) \sigma(z)=\frac{1}{1+exp(-z)}\\\sigma'(z)=\frac{-exp(-z)}{1+exp(-z)}=\sigma(z)(1-\sigma(z)) σ(z)=1+exp(−z)1σ′(z)=1+exp(−z)−exp(−z)=σ(z)(1−σ(z))
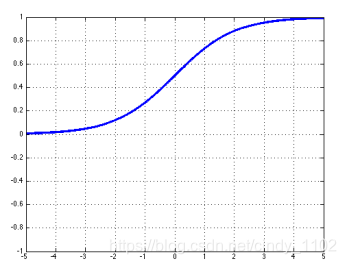
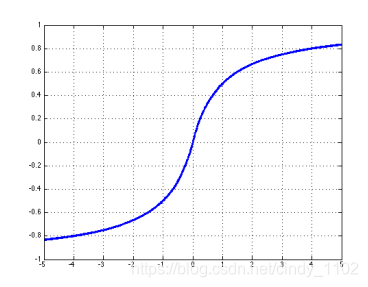
- Tanh
t a n h ( z ) = e x p ( z ) − e x p ( − z ) e x p ( z ) + e x p ( − z ) = 2 σ ( ) 2 z − 1 t a n h ′ ( z ) = 1 − ( e x p ( z ) − e x p ( − z ) e x p ( z ) + e x p ( − z ) ) 2 = 1 − t a n h 2 ( z ) tanh(z)=\frac{exp(z)-exp(-z)}{exp(z)+exp(-z)}=2\sigma()2z-1\\tanh'(z)=1-(\frac{exp(z)-exp(-z)}{exp(z)+exp(-z)})^2=1-tanh^2(z) tanh(z)=exp(z)+exp(−z)exp(z)−exp(−z)=2σ()2z−1tanh′(z)=1−(exp(z)+exp(−z)exp(z)−exp(−z))2=1−tanh2(z)
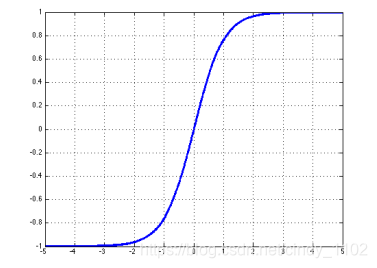
- Hard tanh
h a r d t a n h ( z ) = { − 1 , z < − 1 z , − 1 ≤ z ≤ 1 1 , z > 1 h a r d t a n h ′ ( z ) = { 1 , − 1 ≤ z ≤ 1 0 , o t h e r w i s e hardtanh(z)=\left\{\begin{matrix} -1,z<-1\\ z,-1\leq z\leq 1 \\1,z>1 \end{matrix}\right.\\hardtanh'(z)=\left\{\begin{matrix} 1,-1\leq z\leq 1 \\0,otherwise \end{matrix}\right. hardtanh(z)=⎩⎨⎧−1,z<−1z,−1≤z≤11,z>1hardtanh′(z)={1,−1≤z≤10,otherwise
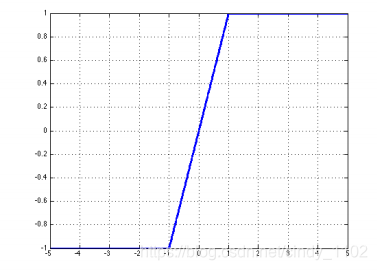
- Soft sign
s o f t s i g n ( z ) = z 1 + ∣ z ∣ s o f t s i g n ( z ) = s i g n ( z ) ( 1 + z ) 2 softsign(z)=\frac{z}{1+|z|}\\softsign(z)=\frac{sign(z)}{(1+z)^2} softsign(z)=1+∣z∣zsoftsign(z)=(1+z)2sign(z)
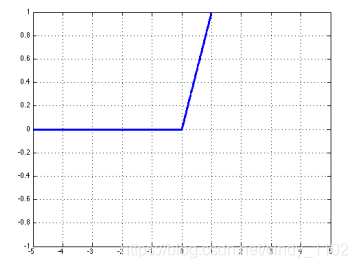
- ReLU
r e l u ( z ) = m a x ( z , 0 ) r e l u ′ ( z ) = { 1 , z > 0 0 , o t h e r w i s e relu(z)=max(z,0)\\relu'(z)=\left\{\begin{matrix} 1,z>0 \\0,otherwise \end{matrix}\right. relu(z)=max(z,0)relu′(z)={1,z>00,otherwise
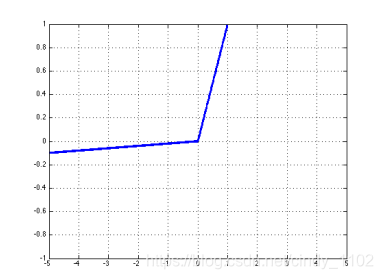
- Leaky ReLU
l e a k y ( z ) = m a x ( z , k ⋅ z ) l e a k y ′ ( z ) = { 1 , z > 0 k , o t h e r w i s e leaky(z)=max(z,k\cdot z)\\leaky'(z)=\left\{\begin{matrix} 1,z>0 \\k,otherwise \end{matrix}\right. leaky(z)=max(z,k⋅z)leaky′(z)={1,z>0k,otherwise
数据预处理
与机器学习模型一样,确保模型在当前任务上获得合理性能的一个关键步骤是数据预处理。
- 减均值
给定一组输入数据的X,减去平均特征向量得到以零为中心的数据。在实践中,只计算整个训练集的均值,然后从训练、验证和测试集中都减去这一均值。 - 归一化
缩放每个输入特征,使其具有相似的大小范围。因为输入特性通常是用不同的单位度量的,但通常希望在开始时将所有特性都视为同等重要的。将特征除以它们在整个训练集中计算的各自标准差。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)