语音识别实践——第4章:DNN
深度神经网络框架:(前向神经网络FDNN&&全连接神经网络FCNN)使用误差反向传播来进行参数训练(训练准则、训练算法)数据预处理最常用的两种数据预处理技术是样本特征归一化和全局特征标准化。a.样本特征归一化如果每个样本均值的变化与处理的问题无关,就应该将特征均值归零,减小特征相对于DNN模型的变化。在语音识别中,倒谱均值归一化(CMN)是在句子内减
-
深度神经网络框架:(前向神经网络FDNN&&全连接神经网络FCNN)
-
使用误差反向传播来进行参数训练(训练准则、训练算法)
-
数据预处理
最常用的两种数据预处理技术是样本特征归一化和全局特征标准化。
a.样本特征归一化
如果每个样本均值的变化与处理的问题无关,就应该将特征均值归零,减小特征相对于DNN模型的变化。在语音识别中,倒谱均值归一化(CMN)是在句子内减去MFCC特征的均值,可以减弱声学信道扭曲带来的影响。以CMN为例,对于每个句子,样本归一化先要用该句子所有的帧特征估算第i维的均值:
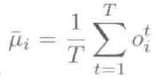
其中,T表示该句子中第i维特征帧的个数,然后该句中的所有第i维特征帧减去该均值。
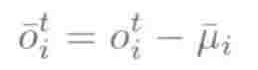
b.全局特征标准化
全局特征标准化的目的是使用全局转换缩放每维数据,使得最终的特征向量处于相似的动态范围内。在语音识别中,对于实数特征,如MFCC和FBANK,通常使用一个全局转换将每维特征归一化为均值为0,方差为1。两种数据预处理方法中的全局转换都只采用训练数据估计,然后直接应用到训练数据集和测试数据集。

然后训练集和测试集中的所有数据可以用以下公式来标准化:
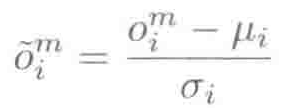
全局特征标准化是有效的。在DNN训练中,通过归一化特征,在所有的权重矩阵维度上使用相同的学习率仍然得到好的模型。如果不做特征归一化,能量维或者MFCC特征第一维c0会遮蔽其他维度特征;如果不使用类似AdaGrad的学习率自动调整算法,这些特征维度会在模型参数调整过程中主导学习过程。 -
模型初始化
DNN是一个高度非线性模型,训练准则是非凸函数,所以初始模型会极大地影响最终模型的性能。
初始化DNN模型的方法:
1)初始化的权重必须使得隐层神经元节点在sigmod函数的线性范围内活动;可以得到足够大的梯度,使得模型学习过程更加有效。
2)随机初始化参数,如果所有的模型参数都相同的话,所有隐层神经元节点将有相同的输出,在DNN底层会检测到相同的特征模式。随机初始化的目的是为了打破对称性。
对于语音识别系统中的DNN,通常每个隐层有1000~2000个隐层神经元节点,通常使用N(w,0,0.05)高斯分布或一个取值范围在[-0.05,0.05]之间的正态分布随机初始化权重矩阵;偏差系数b通常初始化为0。 -
权重衰减(即正则化)
过拟合问题主要是因为 通常希望最小化期望损失,但实际中最小化的是训练集上定义的经验损失。即所训练的模型在训练集上有很好的性能,但在测试集上性能比较差,也就是说模型的泛化能力比较差。
缓和过拟合问题最简单的方法就是使用正则化训练准则,可以使模型参数不过分地拟合训练数据,最常用的正则项包括基于L1范数的正则项和基于L2范数(Frobenious范数)的正则项。
包含正则项时,训练准则公式如下:
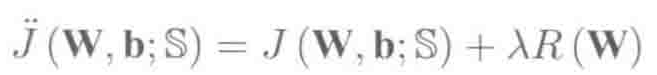
mse(mean squared error)均方误差损失
ce(cross entropy)交叉熵损失
其中,J(W,b,S)是在训练集S上优化的经验损失Jmse(W,b,S)或者Jce(W,b,S),R(W)是正则化项,lambda是插值权重或称作正则化权重。且:

sgn是阶跃函数。
当训练集的大小相对于DNN模型中的参数量较小时,正则化法是有效的。语音识别中DNN模型通常有超过1百万的参数,lambda应该较小(10-4数量级),甚至当训练数据量较大时设置为0。 -
丢弃法(dropout)
控制过拟合的另一种方法是dropout,dropout基本想法是在训练过程中随即丢弃每一个隐层中一定比例(称为丢弃比例,用alpha表示)的神经元。这意味着即使在训练过程中有一些神经元被丢弃,剩下的(1-alpha)隐层神经元依然需要在每一种随机组合中有很好的表现。这需要每一个神经元在检测模式的时候更少依赖其它神经元。 -
批量块大小的选择
神经网络中参数更新需要从训练样本的一个批量集合(batch)中计算经验梯度。对批量大小的选择会影响收敛速度和模型结果。
批量训练(batch training):最简单批量选择是使用整个训练集。如果我们的唯一目标是最小化训练集上的损失,利用整个训练集的梯度得到的将是真实的梯度(即方差为0)。即使我们目标是优化期望的损失,利用整个训练集进行梯度估计仍然比利用其它任何子集得到的方差要小。优势:1.批量训练收敛性好;2.容易在多个计算机间并行。但批量训练需要在模型参数更新前遍历整个数据集,效率低。
随机梯度下降(Stoachstic gradient decent,SGD):在机器学习中也被称为在线学习。SGD根据从单个训练样本估计得到的梯度来更新模型参数。如果样本点是独立同分布的,则从单个样本点进行的梯度估计是一个对整个训练集的无偏估计,但估计的方差却不是,除非所有样本点相同。
在批量训练中,无论模型参数初始化在哪一个basin里,都将找到其最低点,这导致最终模型估计将高度以来初始模型。而SGD算法的梯度估计带噪声,使它可以跳出不好的局部最优,进入一个更好的basin。
*SGD通常比批量训练快得多,尤其表现在大数据集上。但在同一台计算机上,SGD算法是很难并行化的,且由于SGD对梯度的估计存在噪声,不能完全收敛至局部最低点,而是在最低点附近浮动。浮动的程度取决于学习率和梯度估计方差的大小。
一个基于批量训练和SGD算法的这种方案是"小批量”(minibatch)训练。小批量训练会从训练样本中抽出一小组数据并基于此估计梯度,小批量的梯度估计也是无偏的,且其估计的方差比SGD算法要小。小批量训练允许我们比较容易地在批量内部进行并行计算,使得它比SGD更快收敛。既然我们在训练早期阶段比较倾向于较大的梯度估计方差来快速跳出不好的局部最优,在训练后期使用较小的方差落在最低点,那我们可以最初选用较小的批量数目,然后换用较大的批量数目。*批量的大小可以根据梯度估计方差自动决定,也可以在每一轮通过搜索样本的一个小子集来决定。 -
取样随机化
-
惯性系数
如果模型更新是基于之前所有的梯度(更加全局的视野),而不是仅基于当前的梯度(局部视野),收敛速度更快。Nesterov加速梯度算法被证明在满足凸条件下是最优的。在DNN中应用惯性系数时:

rho是惯性系数(或称动力因子),在SGD或者小批量训练条件下,通常取值为0.9~0.99^4。惯性系数会使参数更新变得平滑,还能减小梯度估计的方差。
上面惯性系数的定义在批量大小相同时表现很好,但在可变的批量大小中惯性系数的定义不再可用。
惯性系数可被考虑成一种有限脉冲响应(FIR)滤波器,推出在不同批量大小Mb的条件下的惯性系数取值为:
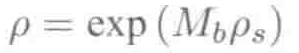
-
学习率和停止准则
-
网络结构
-
可重复性和可重启性

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)