语音识别实践——第6章总结2:
CD-DNN-HMM带来语音识别性能提升的三大关键因素是:1)使用足够深的神经网络;2)使用一长段的帧作为输入;3)直接对三因素进行建模。1.进行比较和分析的数据集实验:a.必应(bing)移动语音搜索数据集:数据分为训练集、开发集、测试集,避免三个集合之间重复。语言模型:一元词组、二元词组、三元词组。语言模型混淆度/困惑度:PPL(Perplixity),度量语言模型性能。PP...
CD-DNN-HMM带来语音识别性能提升的三大关键因素是:
1)使用足够深的神经网络;
2)使用一长段的帧作为输入;
3)直接对三因素进行建模。
1.进行比较和分析的数据集实验:
a.必应(bing)移动语音搜索数据集:
数据分为训练集、开发集、测试集,避免三个集合之间重复。
语言模型:一元词组、二元词组、三元词组。
语言模型混淆度/困惑度:PPL(Perplixity),度量语言模型性能。
PPL的计算公式如下:
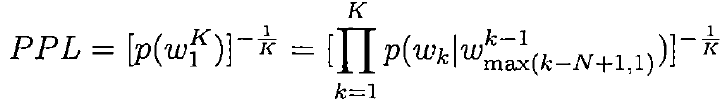
K表示K元语法。
PPL的数值越小,表明在给定历史词序列的情况下产生下一个词序列的可能性越高,也就是语言模型越好。一般情况下,PPL的值在100左右。
识别率度量一般用句子错误率(SER)和词错误率(WER).
重复识别错误的词技术。
GMM-HMM采用了状态聚类后的跨词三音素模型,训练采用的准则是最大似然(maximum likelihood,ML)、最大相互信息(maximum mutual information,MMI)和最小因素错误(minimum phone error,MPE)准则。采用39维音频特征,即13维静态梅尔频率倒谱系数(Mel-frequency cepstral coefficient)及其一阶、二阶导数。这些特征采用倒谱均值和方差归一化(Cepstral mean and variance normalization,CMVN)算法进行了预处理。
结果显示:MPE>MMI>ML,语音识别性能依次衰减。
在CD-DNN-HMM中,DNN的输入特征是11帧(5-1-5),当前帧加前后各5帧的MFCC特征。在预训练及不同的迭代中选用不同的学习率。
minibatch,惯性系数的设置。这些都是超参数。
b.switchboard数据集
系统使用13维PLP(频谱线性预测系数,perceptual linear prediction coefficient,包括三阶差分),做滑动窗口的均值-方差归一化,然后使用异方差线性判别分析(heteroscedastic linear discriminant analysis,HLDA)降到了39维。
语言模型可由标注数据训练。
DNN使用随机梯度下降(SGD)及小批量(mini_batch)训练。mini_batch=256,表示mini_batch为256帧。
2.对单音素或者三因素状态进行建模
对三因素直接建模可以从细致的标注中获得益处,并且缓和过拟合。虽然增加DNN的输出层节点数会降低帧的分类正确率,它减少了HMM中令人困惑的状态转移,因此降低了解码中的二义性。
3.越深越好:
窄切深的神经网络性能优于宽且浅的神经网络。
在实际中,神经网络越深,识别率越高,训练解码代价越大,我们需要在词错误率提升和训练解码代价提升之间做出权衡。
4.利用相邻的语音帧:
为了在GMM系统中使用相邻的帧,需要使用复杂的技术,如fMPE、HLDA、基于区域的转换或者tandem结构。因为GMM中使用对角的协方差矩阵,特征各个维度之间需要是统计不相关的。DNN则是一个鉴别性模型,无论相关或不相关特征都可以接受。
5.预训练:
6.训练数据标注质量的影响:
7.调整转移概率:

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)