
唇语识别技术的开源教程,听不见声音我也能知道你说什么!
作者 | Amirsina Torfi、Seyed Mehdi Iranmanesh、Nasser M. Nasrabadi译者 | 清爹整理 | Jane出品 | AI科技大本营【导读】唇语识别系统使用机器视觉技术,从图像中连续识别出人脸,判断其中正在说话的人,提取此人连续的口型变化特征,随即将连续变化的特征输入到唇语识别模型中,识别出讲话人口型对应的发音,随后根据识别出的...
作者 | Amirsina Torfi、Seyed Mehdi Iranmanesh、Nasser M. Nasrabadi
译者 | 清爹
整理 | Jane
出品 | AI科技大本营
【导读】唇语识别系统使用机器视觉技术,从图像中连续识别出人脸,判断其中正在说话的人,提取此人连续的口型变化特征,随即将连续变化的特征输入到唇语识别模型中,识别出讲话人口型对应的发音,随后根据识别出的发音,计算出可能性最大的自然语言语句。
唇语识别并非最近才出现的技术,早在 2003 年,Intel 就开发了唇语识别软件 Audio Visual Speech Recognition(AVSR),开发者得以能够研发可以进行唇语识别的计算机;2016 年 Google DeepMind 的唇语识别技术就已经可以支持 17500 个词,新闻测试集识别准确率达到了 50% 以上。

大家一定很好奇唇语识别系统要怎么实现。Amirsina Torfi 等人实现了使用 3D 卷积神经网络的交叉视听识别技术进行唇语识别,并将代码托管到 GitHub 上开源:
传送门:
https://github.com/astorfi/lip-reading-deeplearning
接下来就为大家介绍如何使用 3D 卷积神经网络的交叉视听识别技术进行唇语识别,完整的论文可参阅:
https://ieeexplore.ieee.org/document/8063416
下面是进行唇语识别的简单实现方法。


用户需要按照格式准备输入数据。该项目使用耦合 3D 卷积神经网络实现了视听匹配(audio-visual matching)。唇语识别就是这个项目的具体应用之一。
概况
当音频损坏时,视听语音识别(Audio-visual recognition,AVR)被认为是完成语音识别任务的另一种解决方案,同时,它也是一种在多人场景中用于验证讲话人的视觉识别方法。AVR 系统的方法是利用从某种模态中提取的信息,通过填补缺失的信息来提高另一种模态的识别能力。
▌问题与方法
这项工作的关键问题是找出音频和视频流之间的对应关系。我们提出了一种耦合 3D 卷积神经网络架构,该架构可以将两种模式映射到一个表示空间中,并使用学到的多模态特征来判断视听流间的对应关系。
▌如何利用 3D 卷积神经网络
我们提出的该架构将结合时态信息和空间信息,来有效地发现不同模态的时态信息之间的相关性。我们的方法使用相对较小的网络架构和更小的数据集,并在性能上优于现有的视听匹配方法,而现有方法主要使用 CNN 来表示特征。我们还证明了有效的对选择(pair selection)方法可以显著提高性能。
代码实现
输入管道须由用户提供。其余部分的实现包含基于话语的特征提取的数据集。
▌唇语识别
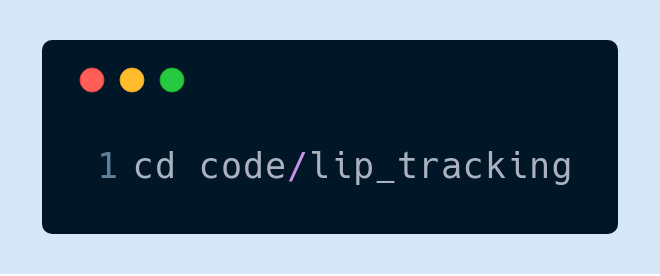
就唇语识别来讲,必须将视频作为输入。首先,使用 cd 命令进入相应的目录:
运行专用的 python file 如下:

运行上述脚本,通过保存每个帧的嘴部区域来提取唇部动作,并在画框圈出嘴部区域来创建新的视频,以便进行更好的可视化。
所需的 arguments 由以下 Python 脚本定义, VisualizeLip.py 文件中已定义该脚本:
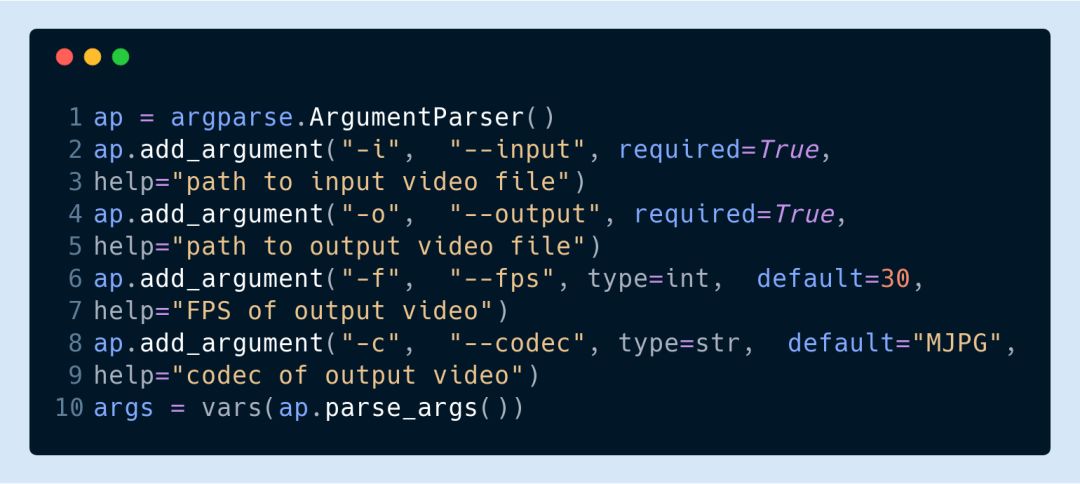
一些已定义的参数有其默认值,它们并不需要进一步的操作。
▌处理
视觉部分,视频通过后期处理,使其帧率相等,均为 30f/s。然后,使用 dlib 库跟踪视频中的人脸和提取嘴部区域。最后,所有嘴部区域都调整为相同的大小,并拼接起来形成输入特征数据集。数据集并不包含任何音频文件。使用 FFmpeg 框架从视频中提取音频文件。数据处理管道如下图所示:

▌输入管道
我们所提出的架构使用两个不相同的卷积网络(ConvNet),输入是一对语音和视频流。网络输入是一对特征,表示从 0.3 秒的视频中提取的唇部动作和语音特征。主要任务是确定音频流是否与唇部运动视频在所需的流持续时间内相对应。在接下来的两个小节中,我们将分别讲解语音和视觉流的输入。
语音网络(Speech Net)
在时间轴上,时间特征是非重叠的 20ms 窗口,用来生成局部的频谱特征。语音特征输入以图像数据立方体的形式表示,对应于频谱图,以及 MFEC 特征的一阶导数和二阶导数。这三个通道对应于图像深度。从一个 0.3 秒的视频剪辑中,可以导出 15 个时态特征集(每个都形成 40 个 MFEC 特征),这些特征集形成了语音特征立方体。一个音频流的输入特征维数为 15x40x3。如下图所示:

语音特征使用 SpeechPy 包进行提取。
要了解输入管道是如何工作的,请参阅:
code/speech_input/input_feature.py
视觉网络(Visual Net)
在这项工作中使用的每个视频剪辑的帧率是 30 f/s。因此,9 个连续的图像帧形成 0.3 秒的视频流。网络的视频流的输入是大小为 9x60x100 的立方体,其中 9 是表示时态信息的帧数。每个通道是嘴部区域的 60x100 灰度图像。

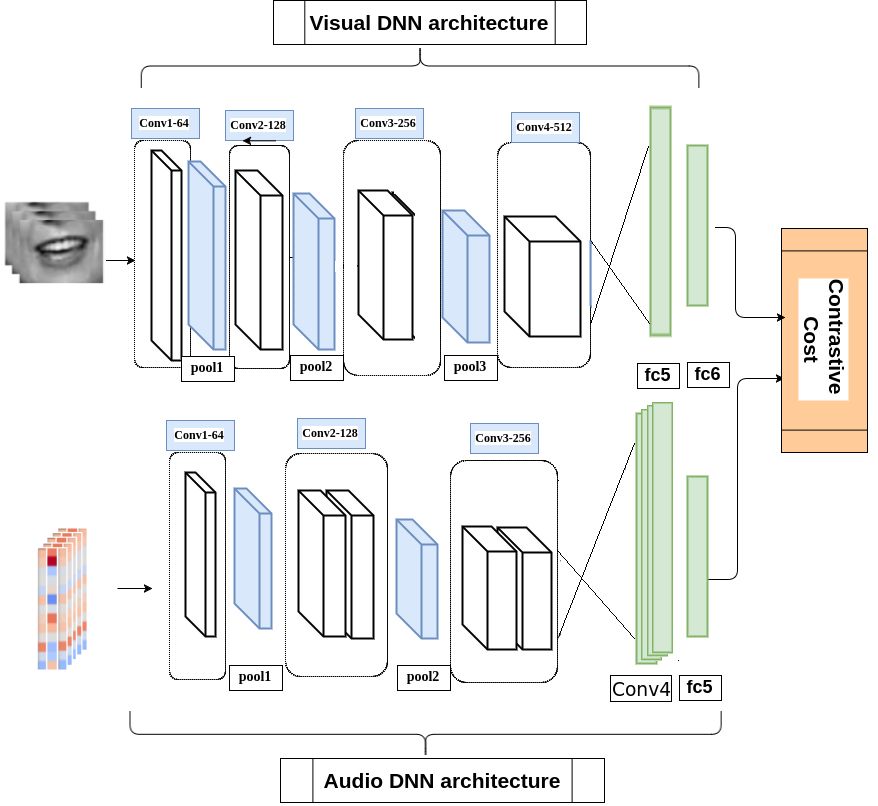
架构
该架构是一个耦合 3D 卷积神经网络,其中必须训练具有不同权重的两个网络。在视觉网络中,唇部运动的空间信息和时态信息相结合,以此来利用时间相关性。在音频网络中,提取的能量特征作为空间维度,堆叠的音频帧构成了时间维度。在我们提出的 3D 卷积神经网络架构中,卷积运算是在连续的时间帧上对两个视听流执行的。
训练 / 评估
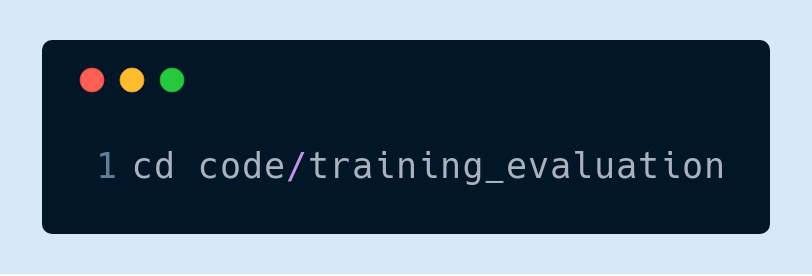
首先,克隆存储库。然后,用 cd 命令进入专用目录:
最后,必须执行 train.py 文件:
对于评估阶段,必须执行类似脚本:
▌运行结果
下面的结果表明了该方法对收敛准确度和收敛速度的影响。
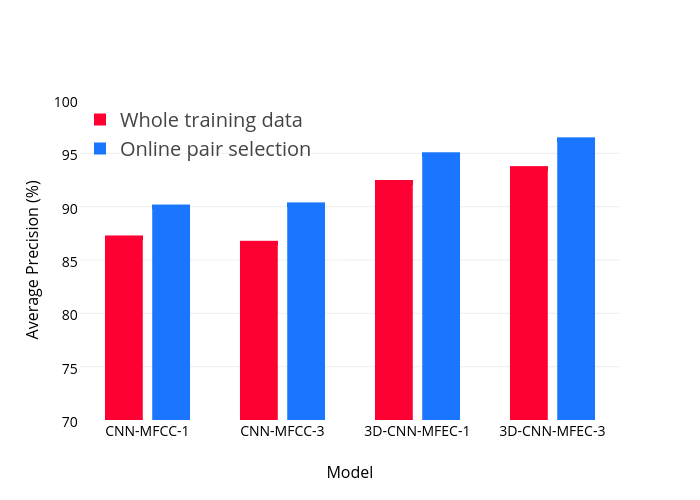
最好的结果,也就是最右边的结果,属于我们提出的方法。
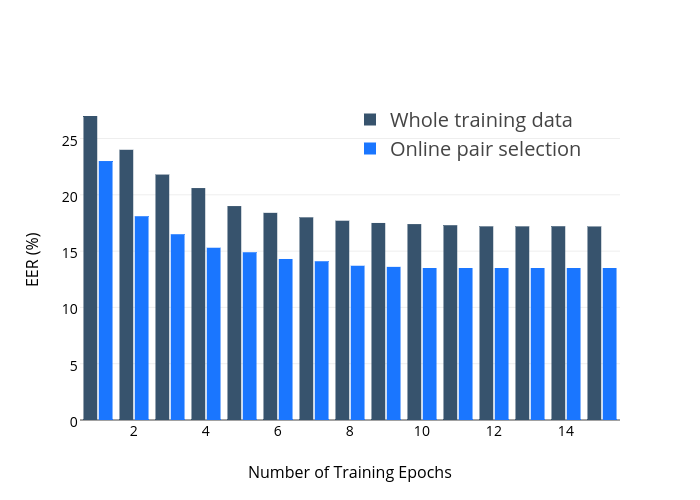
所提出的在线对选择方法的效果如上图所示。
分析到这,希望大家可以到 Github 上找到源码,开始练起!附上作者给的代码演示。
DEMO 演示地址
1.Training/Evaluation :
https://asciinema.org/a/kXIDzZt1UzRioL1gDPzOy9VkZ
2.Lip Tracking:
https://asciinema.org/a/RiZtscEJscrjLUIhZKkoG3GVm
--【完】--
推荐阅读
南开大学提出最新边缘检测与图像分割算法,精度刷新记录(附开源地址)
点击「阅读原文」,查看大会更多详情。2018 AI开发者大会——摆脱焦虑,拥抱技术前沿。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 6
6 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)