
论文LPRNet:License Plate Recognition via Deep Neural Networks翻译工作
利用卷积神经网络的车牌识别摘要本文提出了基于卷积神经网络的端到端的车牌识别LPRNet,其无需对字符提前及逆行切割。我们的方法受到了最近取得突破的深度神经网络的启发,该方法在中文车牌上的实时识别准确率可以高达95%,在NVIDIA GeForce GTX1080上的识别速度达每张3ms,Core i7-6700k CPU上的识别速度为每张1.3ms。LPRNet由轻量级...
利用卷积神经网络的车牌识别
利用卷积神经网络的车牌识别
S e r g e y Z h e r z d e v e x − I n t e l ∗ I O T G C o m p u t e r V i s i o n G r o u p s e r g e y z h e r z d e v @ g m a i l . c o m A l e x e y G r u z d e v I n t e l I O T G C o m p u t e r V i s i o n G r o u p a l e x e y . g r u z d e v @ i n t e l . c o m Sergey Zherzdev \newline ex-Intel∗\newline IOTG Computer Vision Group\newline sergeyzherzdev@gmail.com\newline \ \newline Alexey Gruzdev\newline Intel\newline IOTG Computer Vision Group\newline alexey.gruzdev@intel.com\newline SergeyZherzdevex−Intel∗IOTGComputerVisionGroupsergeyzherzdev@gmail.com AlexeyGruzdevIntelIOTGComputerVisionGroupalexey.gruzdev@intel.com
摘要
本文提出了基于卷积神经网络的端到端的车牌识别LPRNet,其无需对字符提前进行切割。我们的方法受到了最近取得突破的深度神经网络的启发,该方法在中文车牌上的实时识别准确率可以高达95%,在NVIDIA GeForce GTX1080上的识别速度达每张3ms,Core i7-6700k CPU上的识别速度为每张1.3ms。
LPRNet由轻量级的卷积神经网络组成,所以它可以采用端到端的方法来进行训练。据我们所知,LPRNet是第一个没有采用RNNs的实时车牌识别系统。因此,LPRNet算法可以为LPR创建嵌入式部署的解决方案,即便是在具有较高挑战性的中文车牌识别上。
1.Introductiopn
车牌自动识别是应用在交通管理、数字安全监控、车辆识别以及大城市的停车管理领域的兼具挑战性以及重要性的任务。由于图片的模糊,光线条件差以及车牌数字的多变性,物理影响(变形),天气条件等因素使得车牌识别的任务变得较为复杂。一个强大的车牌识别系统应该要能够克服环境的多变性并且保证识别的准确率。也就是说,该系统应该要能够使用到自然环境中。本文解决了车牌识别问题并且介绍了LPRNet算法,采用该方法无需进行字符的预切割以及后续的单个字符的识别工作。在本文中,我们没有考虑车牌检测定位问题,如果有必要定位的话其可以通过LBP级联来完成该部分的任务。LRPNet基于深度卷积神经网络。最近的研究表明了卷积神经网络在机器视觉领域的有效性以及优越性,包括在图像分类、物体检测以及语义分割领域。然而,将其运行在一个嵌入式的设备上仍然是一个具有挑战性的任务。LPRNet是有一个极其高校的神经网络,它的每一个单一的前向传播只需要0.34GFLops。而且,我们的模型部署在Core i7-6700k SkyLake CPU上可以进行端到端的训练,且识别具有较高的准确率。此外,LPRNet可以部分的移植到FPGA上,其可是释放CPU在其他部分的流水线上的计算能力。我们的主要贡献可以总结为以下几点:
·LPRNet是一个用于高质量的车牌识别的实时框架,其支持模板以及可变长的独立车牌LPR采用端到端的识别方法,无需进行字符的预切割。
·LPRNet是第一个没有使用RNN的车牌实时识别方法,其可以部署在各种不同的平台上,包括嵌入式设备。
·LPRNet在实际交通监控视频中的应用显示我们的方法具有足够强大的能力去处理疑难问题,例如视角以及相机的扭曲,较差的光线条件以及视角的改变。
论文的剩下部分采用以下组织形式,Sec. 2 描述我们的相关工作。Sec 3回顾了LPRNet模型的细节。Sec. 4 报告了中文车牌识别的结果,包括我们的算法对于消融的研究。最后我们在Sec. 5中对我们的工作以及相关的结论进行总结。
2.Related Work
更早期的普遍的车牌识别工作中,一般有字符的分割以及字符的分类两部分组成。
·字符的分割采用不同的典型的手工算法,结合了投影连接以及基于图形组件的轮廓等。其采用一个二值图或者中间结果作为输入,因此受到图片的噪声、低分辨率、模糊以及扭曲的影响较大。
·字符的分类典型的采用基于LP字符集的光学字符识别方法。
由于分类紧跟随着字符的分割处理,因此字符识别质量在很大程度上取决于应用的分割方法。为了解决字符分割的问题我们采用了基于端到端的卷积神经网络,其将整张车牌的图像作为网路的输入,最终网络输出得到字符序列。无分割
的模型采用变长序列编码的CTC损失函数。其采用在二值图上手工提取的特征LBP作为CNN的输入用于产生字符在每一个类别上的可能性。在所有的图片上采用滑创窗的方法获得基于解码器的双向LSTM的输入序列。由于解码器的输出以及目标字符序列长度是不同的,所以采用了CTC loss 用于无切割的端到端训练。[6]中的模型主要沿用了【2】中所描述的方法,除了滑窗的方法被替代为了对CNN的输出特征进行滑窗分割以此作为RNN的输入序列(滑窗扫过整个特征图,用于取代输入)相比之下[7]使用基于CNN的模型来生成整个LP图像,以产生全局LP嵌入,通过11个完全连接的模型头部将其解码为11个字符长度的序列。每一个头部被训练用于分类字符串中的第i个目标字符(假定序列已经填充到了预先指定的长度),因此整个识别过程通过一次前向传播即可工作。该模型同时还采用了空间变换网络(STN)来减少输入的图片扭曲所产生的影响。
【9】中的模型尝试通过一个一个单一的深度神经网络来解决车牌的检测以及识别的问题。
【10】最近的研究中尝试利用基于生成对抗网络(GAN)合成数据的方法以便于生成更大的更加具有代表性的车牌数据集。
在我们的方法中,我们避免了在二值图中手工提取特征的过程,取而代之,我们采用原始的RGB像素作为CNN的输入。将基于LSTM的序列解码器接受通过滑窗处理的CNN输出的方法取代为了一个全卷积模型其输出为每一个字符对应的可能性序列同时利用CTC损失函数进行训练。为了使得模型获得更好的表现以及更好的进行预编码,中间的特征图由全局上下文嵌入进行增强【12】。同时受到了SqueezeNet Fire Blocks的启发,对该方法的骨干卷积神经网络模型进行缩减以适用于更低的计算代价。同时采用了批标准化以及Dropout的技术用于正则化处理。
车牌图像的输入尺寸不但影响到计算的花费,同时还影响到了识别的质量,因此我们需要在高分辨率以及中等分辨率之间进行权衡。
3.LPRNet
3.1. Design architecture
在该部分我们将对LPRNet的网络设计细节进行介绍。
在最近的研究中,人们广泛地采用迁移学习的技术运用强大的分类网络作为骨干网络以适用于他们的任务,例如VGG,ResNet或者GoogleNet。然而,这并不是构建快速而轻量级的网络的最佳选择,因此在我们的骨干网络中采用了最近研究发现的架构技巧。我们的CNN模型骨干(表2)的灵感来自SqueezeNet Fire Blocks [13]和Inception块结构[14,15,16]。同时我们在每一层卷积的后面采用了Batch Normalization以及ReLU激活函数以获得最佳的实践效果。
简而言之,我们的设计由以下几个部分组成
·定位网络采用了Spatial Transformer Layer[8] (可选的)
·轻量级的卷积神经网络作为骨干网络
·每个位置的字符分类头部
·用于进一步序列解码的字符概率
·后过滤程
首先,输入的图像采用[8]中所提到的Spatial Transfer Layer进行处理,这一步是可选的但它使得我们可以进一步地探究如何对输入图像进行装换以获得更好的特征并用于识别。原始的LocNet(详见表[1])结构用于估计最佳的转换参数。
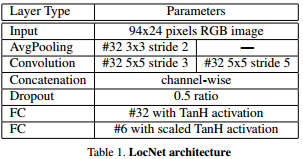
骨干网络的结构在表[3]中进行了描述。骨干网络获取原始的RGB图片作为输入,并且计算出大量特征的空间分布。宽卷积(1*13的卷积核)利用本地字符的上下文从而取代了基于LSTM的RNN网络。骨干子网络的输出可以被认为是一个代表对应字符可能性的序列,它的长度刚到等于输入图像的宽度。由于解码器的输出与目标字符序列的长度是不一致的,因此我们采用了CTC损失函数[20] 用于无需分割的端到端训练。CTC 损失函数是一种广泛地用于处理输入和输出序列不对齐的方法。而且,CTC提供了一个从每个时间步的可能性转化为输出序列的可能性的有效方法。更多过于CTC损失函数的细节可以查询相应的资料。

为了进一步地提升模型的表现,预增强解码器所得的中间特征图,采用用全局上下文关系进行嵌入[12]。它是通过全连接层对骨干网络的输出层进行计算,随后将其平铺到所需的大小最后再与骨干网络的输出进行拼接。为了调整映射到每一个字符类的特征的深度,我们采用了1×1的卷积。对于推理阶段的解码过程我们考虑2个选项:贪心搜索和集束搜索。虽然贪心搜索在每个位置获取最大的类概率,但是集束搜索可以最大化总的输出序列的概率[3,4]。
对于后期过滤,我们使用面向任务的语言模型实现一组目标国家车牌(LP)模板。请注意,后过滤与集束搜索(Beam Search)一起应用。 后过滤程序获得通过集束搜索找到的前N个最有可能的序列并返回第一个与预定义模板集相匹配的模板,当然这取决于相关国家的车牌指定法规。
3.2训练细节
所有的训练实验都是通过TensorFlow完成的。
在训练过程中,我们采用了Adam优化器,batch的大小设定为32,初始学习率为0.001。梯度噪音比例为0.001。在训练的时候,我们在每100k个迭代之后就让学习率下降十倍,并且总共训练250k个迭代。在实验中我们通过随机仿射变换,旋转,缩放以及平移等操作进行数据增强。值得一提的是,LocNet的应用会导致训练开始时结果退化,因为LocNet无法从识别器获得合理的梯度,这通常不利于前几次迭代。因此,在我们的实验中,我们仅在5k个迭代之后才开启LocNet。所有的其他超参数均是通过在目标数据集上进行交叉验证所获得的。
4.实验结果
LPRNet是我们通过多种不同的实验并且受到[2]的启发所提出的。它主要是基于Inception模块,随后通过一个双向的LSTM(BiLSTM)解码器,并利用CTC损失函数进行训练。首先,我们把biLSTM替换为了biGRU,但模型的效果并没有得到明显的提升。随后,我们开始把注意力放在消除复杂的biLSTM解码器上,因为目前大部分的嵌入式设备都不具备足够的计算能力和内存来运行biLSTM。更重要的是,我们的LSTM采用的是空间序列而不是时间序列,所以LSTM的输入在训练以及推理阶段都是预先知道的。因此我们相信RNN可以用空间卷积代替,而不会显着降低精度。为了提高运行时的性能,我们也对LPRNet basic进行了修改,对于所有的池化层都采用了2×2的步长,其缩减了LPRNet的中间特征图的尺寸,同时减低了整个推理过程的计算代价。(详细参加表4中GFLOPs列的指标)
4.1中文车牌数据集
我们利用从各种安全监控摄像头获得中文车牌数据集来测试模型。首先利用基于LPB(Local Binary Pattern)的检测器获取图像中车牌的bounding boxes。然后对所有的车牌进行人工标记。数据集一共包含11696张裁剪的车牌图片,其被按照9:1的比例分别分成训练集以及验证集。使用自动裁剪的牌照图像用于训练可以使网络对于检测伪像更加鲁棒,因为在某些情况下,被裁剪的车牌边缘包含一些周围的背景,而在其他情况下,车牌裁剪得太靠近边缘,没有背景甚至有些时候车牌的某些信息会被裁剪从而 丢失。
表[4]展示了不同模型的识别准确率。

4.2消融(Ablation)研究
消融研究在确定各种增强功能与各自的准确性/性能改进之间的相关性上至关重要。它可以帮助其他的研究人员采用论文中的观点并复现出更加具有前景的架构方法。表[5]总结了不同的架构方法对准确率的影响。

4.3性能分析
LPRNet简化模型被移植到各种硬件平台,包括CPU,GPU和FPGA。 结果如表6所示:

这里的GPU是NVIDIA R GeForceTM1080,CPU是Intel R.CoreTMi7-6700K SkyLake,FPGA是Intel R ArriaTM10和IE用于Intel R OpenVINO的推理引擎。
5.结论以及未来的工作
在该工作中,我们展示了利用一个极小的卷积神经网络进行车牌的识别任务。我们介绍了LPRNet模型,其可以用于各种具有挑战性的数据,并且取得了95%的准确率,同时我们展示了网络结构的细节,论文的动机以及消融研究。
我们展示了LPRNet可以在各种硬件进行实时的推断计算,包括CPU,GPU以及FPGA。我们可以确定LPRNet可以获得实时的性能,甚至是在具有更低能源的嵌入式设备上。LPRNet很有可能可以采用现代的修剪和量化技术进行压缩,使其可以进一步地减低计算的复杂性。
作为未来的研究方向,LPRNet的工作可以通过将基于CNN的检测部分合并到我们的算法中来进行扩展,以使得检测和识别的任务可以同时利用单一的网络来进行评估,并且提升基于LBP的级联检测器的表现效果。
References
[1] C. N. E. Anagnostopoulos, I. E. Anagnostopoulos, I. D.Psoroulas, V. Loumos, and E. Kayafas, “License Plate Recognition From Still Images and Video Sequences: A Survey,” IEEE Transactions on Intelligent Transportation Systems, vol. 9, no. 3, pp. 377–391, Sep. 2008. 1
[2] H. Li and C. Shen, “Reading Car License Plates Using Deep Convolutional Neural Networks and LSTMs,”arXiv:1601.05610 [cs], Jan. 2016, arXiv: 1601.05610. 2,4
[3] A. Graves, Supervised Sequence Labelling with Recurrent Neural Networks, 2012th ed. Heidelberg ; New York:Springer, Feb. 2012. 2, 3
[4] A. Graves, S. Fernndez, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning. ACM, 2006, pp. 369–376. 2, 3
[5] S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, Nov.1997. 2
[6] T. K. Cheang, Y. S. Chong, and Y. H. Tay, “Segmentationfree Vehicle License Plate Recognition using ConvNetRNN,” arXiv:1701.06439 [cs], Jan. 2017, arXiv:1701.06439. 2
[7] V. Jain, Z. Sasindran, A. Rajagopal, S. Biswas, H. S. Bharadwaj, and K. R. Ramakrishnan, “Deep Automatic License Plate Recognition System,” in Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing, ser. ICVGIP ’16. New York, NY, USA: ACM, 2016, pp. 6:1–6:8. 2
[8] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial Transformer Networks,” arXiv:1506.02025 [cs], Jun. 2015, arXiv: 1506.02025.2, 3
[9] H. Li, P. Wang, and C. Shen, “Towards End-to-End Car License Plates Detection and Recognition with Deep Neural Networks,” ArXiv e-prints, Sep. 2017. 2
[10] X. Wang, Z. Man, M. You, and C. Shen, “Adversarial Generation of Training Examples: Applications to Moving Vehicle License Plate Recognition,” ArXiv e-prints, Jul. 2017. 2
[11] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative Adversarial Networks,” ArXiv e-prints, Jun.2014. 2
[12] W. Liu, A. Rabinovich, and A. C. Berg, “ParseNet: Looking Wider to See Better,” arXiv:1506.04579 [cs], Jun. 2015,arXiv: 1506.04579. 2, 3
[13] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J.Dally, and K. Keutzer, “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5mb model size,”arXiv:1602.07360 [cs], Feb. 2016, arXiv: 1602.07360. 2, 3
[14] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. Alemi,“Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning,” arXiv:1602.07261 [cs], Feb.2016, arXiv: 1602.07261. 2, 3
[15] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed,D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich,“Going Deeper with Convolutions,” arXiv:1409.4842 [cs], Sep. 2014, arXiv: 1409.4842. 2, 3
[16] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the Inception Architecture for Computer Vision,” arXiv:1512.00567 [cs], Dec. 2015, arXiv:1512.00567. 2, 3
[17] S. Ioffe and C. Szegedy, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift,” arXiv:1502.03167 [cs], Feb. 2015, arXiv:1502.03167. 2, 3
[18] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A Simple Way to Prevent Neural Networks from Overfitting,” J. Mach. Learn. Res.,vol. 15, no. 1, pp. 1929–1958, Jan. 2014. 2

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)