语音识别--浅谈语音识别
1.语音识别简介:语音识别:将语音转成文字的一个过程;2.语音识别过程:3.学习语音资料:
1.前言:
本科毕业之后,开始了北漂,一直想从事一些偏上层方面的工作,开始找工作期间各种碰壁。可能自己c语言的基础还可以的原因,被现在的单位的引擎组招了过来,起初只是被用来干一些引擎的支持和测试,慢慢的开始接触到了语音识别等引擎的开发,所以利用自己在工作中所了解得在这里班门弄斧地谈谈语音识别,也是想工作进行总结。也欢迎大家指出错误和不足。
1.语音识别简介:
语音识别技术即AutomaticSpeechRecognition(简称ASR),是指将人说话的语音信号转换为可被计算机程序所识别的信息,从而识别说话人的语音指令及文字内容的技术。目前语音识别被广泛的应用于客服质检,导航,智能家居等领域。
2.语音识别过程:
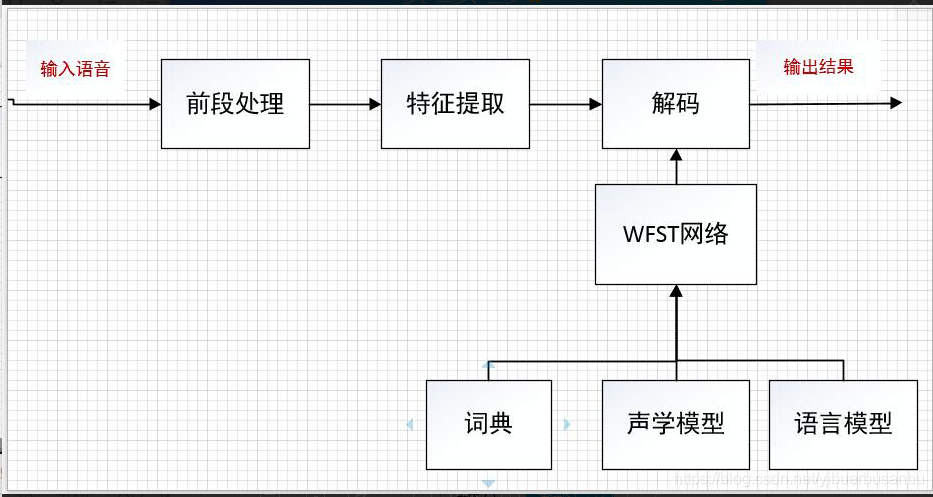
语音识别大体上包含前端处理,特征提取,模型训练,解码四个模块。其中前端处理包括了,语音转码,高通滤波,端点检测等。
上图目前语音识别的基本流程,输入的语音数据流经过前端处理(语音格式转码,高通,端点检测),语音格式转码是将输入的语音数据转成pcm或者wav格式的语音,端点检测是检测出转码后语音中的有效语音,这样对解码速度和识别率上都会改善。经过前端处理之后的得到的分段语音数据送入特征提取模块,进行声学特征提取。最后解码模块对提取的特征数据进行解码,解码过程中利用发音字典,声学模型,语言模型等信息构建WFST搜索空间,在搜索空间内寻找匹配概率最大的最优路径,便得到最优的识别结果。
在其他章节中会详细介绍以上四个模块。
3.语音识别的学习:
由于语音识别本事就是一个非常大并且繁琐的工程,设计到知识面很广,目前我也在想如何把这个学习过程更加系统化,简单化。希望这一块能得到前辈的指点。
目前我再看这些书籍:
1).数学之美,这本书对整个语音识别过程以及各个模块讲的很详细,也很通俗易懂,是一本不错的语音识别入门的书。
2).语音信号处理,这本书对前端处理模块的学习有很大的帮助,由于是一本教材书籍,自己在有些地方看起来也很晦涩,目前也想在网上找一些相关网课看看,这样更加深理解,找到的话也会第一时间分享。
3).关于特征提起模块,网上有很多帖子写的都很详细,后面我也会整理一下。
4).解码和模型训练…未完!!!

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)