深度学习中的超参数设定及训练技巧
一、网络超参数的设定输入数据像素大小的设定:为便于GPU并行计算,一般将图像大小设置为到 2 的 次幂卷积层参数的设定:卷积核大小一般使用 1∗11∗11*1、3∗33∗33*3 或 5∗55∗55*5使用 zero padding,可以充分利用边缘信息、使输入大小保持不变卷积核的个数通常设置为 2 的次幂,如 64, 128, 256, 512, 1024 等池化层参数的设...
·
一、网络超参数的设定
-
输入数据像素大小的设定:
- 为便于GPU并行计算,一般将图像大小设置为到
2 的 次幂
- 为便于GPU并行计算,一般将图像大小设置为到
-
卷积层参数的设定:
- 卷积核大小一般使用 1 ∗ 1 1*1 1∗1、 3 ∗ 3 3*3 3∗3 或 5 ∗ 5 5*5 5∗5
- 使用 zero padding,可以充分利用边缘信息、使输入大小保持不变
- 卷积核的个数通常设置为
2 的次幂,如 64, 128, 256, 512, 1024 等
-
池化层参数的设定:
- 一般采用卷积核大小 2 ∗ 2 2*2 2∗2,步长为 2 2 2
- 也可采用 stride convolutional layer 来代替池化层实现下采样
-
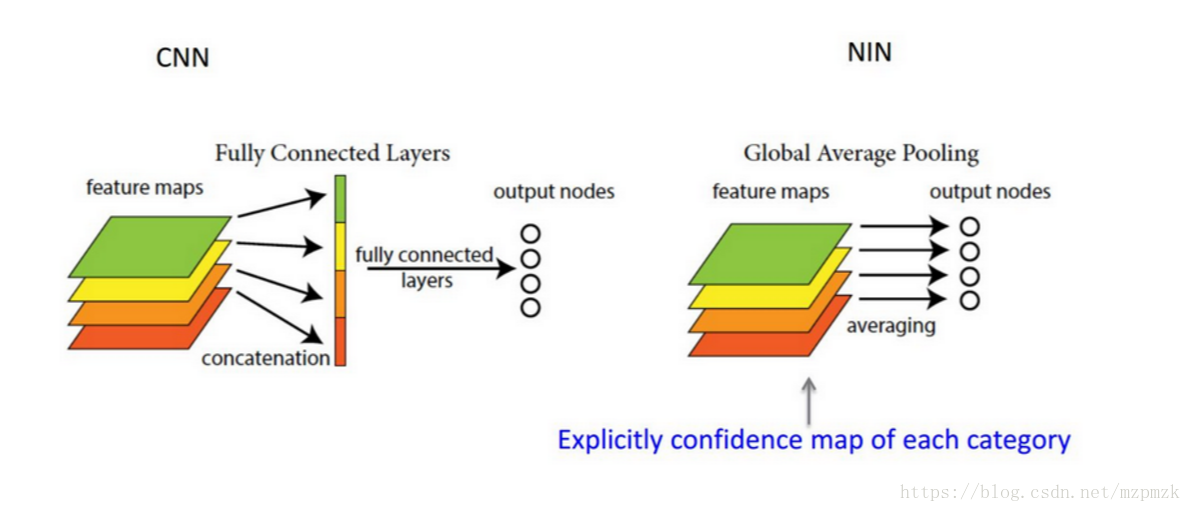
全连接层(可使用 Global Average Pooling 来代替):
- Global Average Pooling 和 Average Pooling(
Local) 的差别就在“Global”这个字眼上。Global 和 Local 在字面上都是用来形容 pooling 窗口区域的。Local 是取 Feature Map 的一个子区域求平均值,然后滑动;Global 显然就是对整个 Feature Map 求均值了(kernel 的大小设置成和 Feature Map 的相同) - 所以,有多少个 Feature Map 就可以输出多少个节点。一般可将输出的结果直接喂给 softmax 层
- Global Average Pooling 和 Average Pooling(
-
卷积的选取:
-
1、卷积核
尺寸方面:- 大卷积核用多个小卷积核代替
- 单一尺寸卷积核用多尺寸卷积核代替
- 固定形状卷积核趋于使用可变形卷积核
- 使用1×1卷积核(bottleneck 结构)
-
2、卷积层
通道方面:- 标准卷积用 depthwise 卷积代替
- 使用分组卷积
- 分组卷积前使用 channel shuffle
- 通道加权计算
-
3、卷积层
连接方面:- 使用 skip connection,让模型更深
- densely connection,使每一层都融合上其它层的特征输出(DenseNet)
-
4、启发:
- 类比到通道加权操作,卷积层跨层连接能否也进行加权处理?
bottleneck + Group conv + channel shuffle + depthwise的结合会不会成为以后降低参数量的标准配置?
-
二、训练超参数的设定
- learning-rate 的选择
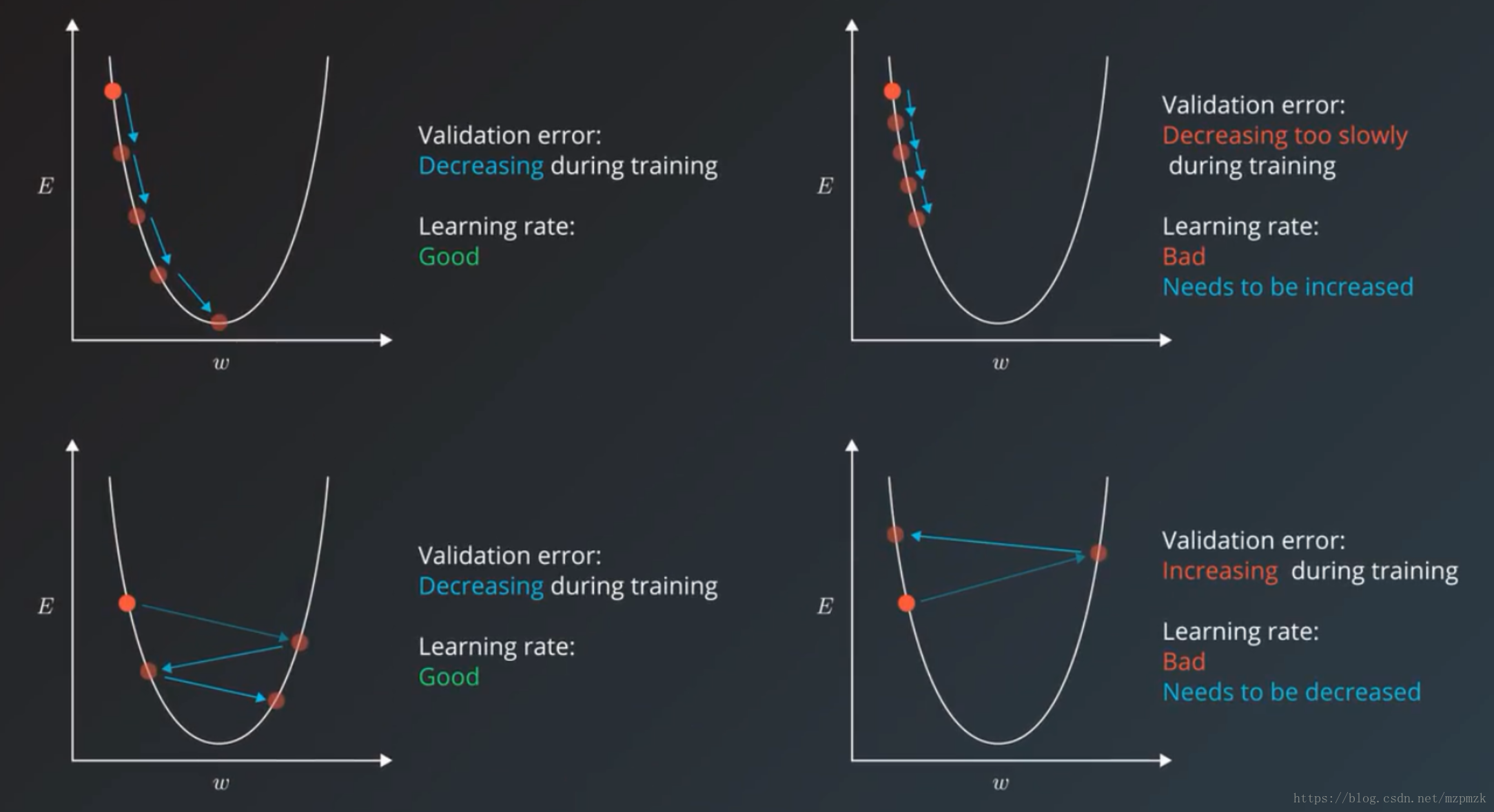
- 固定学习率时,
0.01,0.001等都是比较好的选择,另外我们可以通过 validation error 来判断学习率的好坏,如下图所示。 - 自动调整学习率时,可使用 learning rate decay 算法(step decay,exponential decay)或一些自适应优化算法(Adam,Adadelta)。
- 固定学习率时,
- mini-batch 的选择
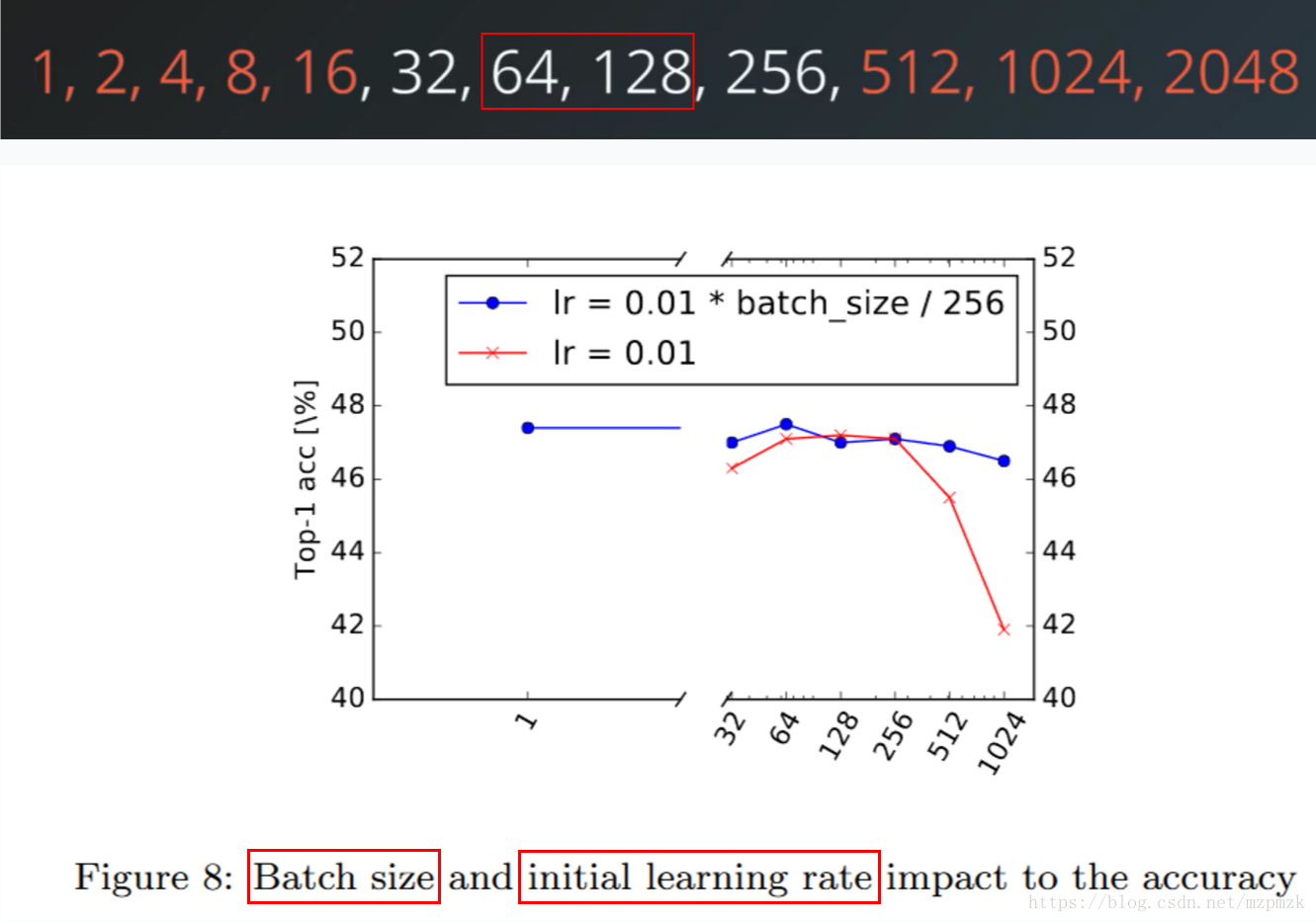
- batch size 太小会使训练速度很慢;太大会加快训练速度,但同时会导致内存占用过高,并有可能降低准确率。
- 所以 32 至 256 是不错的初始值选择,尤其是
64 和 128,选择2的指数倍的原因是:计算机内存一般为 2 的指数倍,采用 2 进制编码。
- the number of training iterations or epochs
Early Stopping:如果验证误差未在一段时间内(eg:200 次迭代)训练内降低,则停止训练过程- tf.train 的训练钩子函数中已存在两个预定义的停止 Monitor 函数。
- StopAtStepHook:用于在特定步数之后要求停止训练的 Monitor 函数
- NanTensorHook:监控损失并在遇到 NaN 损失时停止训练的 Monitor 函数
三、训练技巧
- shuffle per epoch
- 梯度裁剪:防止梯度爆炸
- 迁移学习:
- 将从源数据集学到的知识迁移到目标数据集上
- 例如,虽然 ImageNet 的图像⼤多跟目标数据无关,但在该数据集上训练的模型
可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。
- 微调: 迁移学习中的⼀个常⽤技术
- 在源数据集(例如ImageNet数据集)上
预训练⼀个神经⽹络模型,即源模型 - 创建⼀个新的神经⽹络模型,即目标模型,它
复制了源模型上除了输出层外的所有模型设计及其参数 - 为目标模型添加⼀个输出大小为
目标数据集类别个数的输出层,并随机初始化该层的模型参数 - 在⽬标数据集上训练⽬标模型。我们将
从头训练输出层,而其余层的参数基于源模型的参数微调得到 - ⼀般来说,微调参数层(finetune_net)会使用
较小的学习率(eg:0.001)或固定不变,而从头训练输出层(scratch_net)可以使用较大的学习率(eg:0.01)
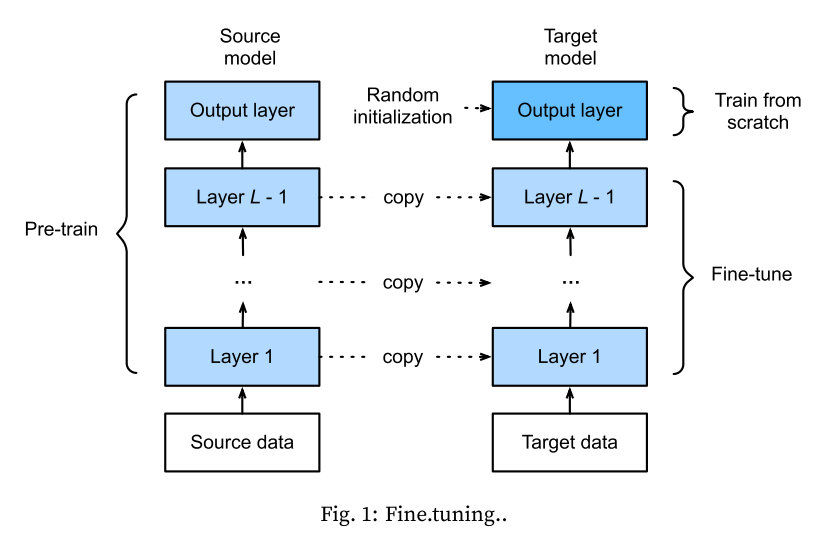
- 在源数据集(例如ImageNet数据集)上
四、参考资料
1、深度学习手册 - 第 11.4 章:选择超参数
2、神经网络和深度学习手册 - 第 3 章:如何选择神经网络超参数?
3、系统评估 CNN 在 ImageNet 上的进步
4、变形卷积核、可分离卷积?卷积神经网络中十大拍案叫绝的操作。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)