Httpclient 以multipart/form-data形式post上传文件及提交参数
在大学里由于要做某些英语听力作业,是在PC客户端上的,而做完提交后显示的答案又没办法复制,再重新填写的话答案就消失了,所以懒得去记,好在答案图片并不复杂,便想做一个可以识别出图片中的英文的小软件。因为我自己并没有做OCR的经验,于是我就到网上找可以在线识别文字的网站,找着找着找到了一个不错的网站,识别速度很快,还是免费的,因此开始下手。首先例行f12,打开调试窗口,然而没有发现请求参数,而是看到了
在大学里由于要做某些英语听力作业,是在PC客户端上的,而做完提交后显示的答案又没办法复制,再重新填写的话答案就消失了,所以懒得去记,好在答案图片并不复杂,便想做一个可以识别出图片中的英文的小软件。因为我自己并没有做OCR的经验,于是我就到网上找可以在线识别文字的网站,找着找着找到了一个不错的网站,识别速度很快,还是免费的,因此开始下手。
首先例行f12,打开调试窗口,然而没有发现请求参数,而是看到了一个陌生的东东:Request Payload,
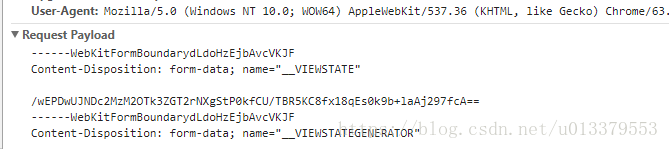
然后到百度一查才发现一般需要提交文件就会用multipart/form-data这种形式,这种形式是以分界线来分割数据的,

这种形式提交数据时参数会显示在Request Payload。
一开始我按照网上的博客去请求的时候,总是失败,因为我把分界线和参数名前面的Content-Disposition: form-data;都写进去请求的name里了,在这里大家要注意,只写name里的东西,如果有多个的话用;分开

ok。接下来进入正题:如何去构造这样的post请求。上代码:
HttpClient context = new DefaultHttpClient();
HttpPost post = new HttpPost("url");
post.setHeader("Accept-Language","zh-CN,zh;q=0.9");
post.setHeader("Accept-Encoding","gzip, deflate"); //像header这些自己去设置吧
MultipartEntityBuilder builder = MultipartEntityBuilder.create();
builder.addBinaryBody("name=\"File\"; filename=\"testImg.png\"", new File("C:\\Users\\Administrator\\Desktop\\testImg.png"));//添加文件
builder.addTextBody("Language", "9"); //添加文本类型参数
post.setEntity(builder.build());
HttpResponse response = context.execute(post);
byte[] res =null;
//获取参数
/**请求发送成功,并得到响应**/
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
res = EntityUtils.toByteArray(response.getEntity());
}
System.out.println(Jsoup.parse(new String( uncompress(res),"utf-8")).select("div[class=div_res]"));还有就是它这个网站返回的是gzip编码的数据,所以我最后需要解码,顺便附上解码的代码吧
public static byte[] uncompress(byte[] b) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
ByteArrayInputStream in = new ByteArrayInputStream(b);
GZIPInputStream gunzip = new GZIPInputStream(in);
byte[] buffer = new byte[256];
int n;
while ((n = gunzip.read(buffer)) >= 0) {
out.write(buffer, 0, n);
}
return out.toByteArray();
}最后大功告成啦


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)