
JAVA中关于”容器“的理解
众所周知,JAVA是一门强类型的编程语言,该语言有很多的特性,而本文所要讲的是关于JAVA中“容器”这一知识点的简要探究。在我看来,“容器”其实就是一种用来存储数据的数据结构,在JAVA中容器可分为即“集合”(Set)、“列表”(List)、“映射”(Map)。至于,为什么需要容器,总的来说,主要是在以数组作为数据的存储结构中,其长度难以扩充,同时数组中元素类型必须相同。而容器可以弥补数组的这两个
众所周知,JAVA是一门强类型的编程语言,该语言有很多的特性,而本文所要讲的是关于JAVA中“容器”这一知识点的简要探究。在我看来,“容器”其实就是一种用来存储数据的数据结构,在JAVA中容器可分为即“集合”(Set)、“列表”(List)、“映射”(Map)。至于,为什么需要容器,总的来说,主要是在以数组作为数据的存储结构中,其长度难以扩充,同时数组中元素类型必须相同。而容器可以弥补数组的这两个缺陷。下图为容器API类的一个结构图。 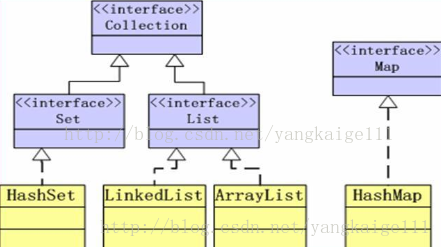
LinkedList相当于《数据结构》中线性结构中的链式存储结构,ArrayList相当于顺序存储结构,它们分别实现了Set接口和List接口,而这两个接口又分别实现了Collection接口,这个Collection接口中其实没有任何方法和属性,它只是起到一种标识的作用;HashMap也是一种容器,它现实了Map接口,其特点就是以键值对的形式来存放数据,它可以不用通过比较而直接进行数据的操作,可以比较好的解决”哈希冲突“问题,可是它并不能完美地解决该问题。但我要讲的是关于HashSet这个子类使用方法的理解,如能理解这一问题,将会对JAVA中容器的概念有比较深刻的了解。
我们知道,在JAVA中合集的元素要求不重复,但可以无序,当我们往一个HashSet中添加数据的时候,如果没有这个数据对象所属的类没有重写相关方法,我们添加相同数据时,然后再输出,就会发现,输出了相同的数据,这很明显和JAVA中集合的性制不符合。我们先来考虑一下,以下程序的运行结果。
public class TestHashSet
{
public static void main(String[] args)
{
Collection c = new HashSet();
c.add(new Student(1001, "张三"));
c.add(new Student(1002, "李四"));
c.add(new Student(1003, "王五")); //10行
c.add(new Student(1003, "王五"));
c.add(new Student(1003, "王五"));
c.add(new Student(1003, "王五"));
c.add(new Student(1003, "王五")); //14行
Iterator i = (Iterator) c.iterator();
while (i.hasNext())
{
System.out.println(i.next());
}
}
}
class Student
{
private int num;
private String name;
public Student()
{
}
public Student(int num, String name)
{
this.num = num;
this.name = name;
}
public String toString()
{
return "学号: " + this.num + ", 姓名: " + name;
}
public boolean equals(Object o)//需要重写的方法
{
Student s = (Student)o;
return this.num==s.num && this.name.equals(s.name);
}
public int hashCode()//需要重写的方法
{
return num * this.name.hashCode();
}
}当 hashCode()和equals(Object o)方法被重写时,可以正常输出集合中的数据,即它会自动把我们输入的重复数据忽略。运行结果如下: 
但当我们把其中一个该重写的方法注释或两个都注释后。运行结果如下: 
我们可以发现输入的重复数据全部输出了,这明显是不正确的。
这时,我们就应该考虑了,为什么要重写这两个方法,同时又应该怎样去重写?这两个问题对深刻理解该容器的特性有很大的作用。
根据我的理解,我们首先要对《数据结构》有一定了解才行。
我可以理解为的HashSet容器中的存储结构应该是以链表的方式来存储,而每个数据元素是根据一定计算放在不同或相同链表的不同位置。不同的链表又存在数组的不同位置。该存储结构如下图所示: 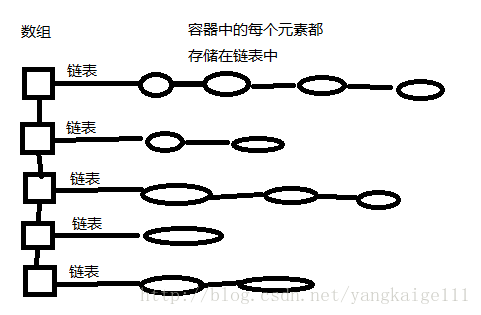
在这之前,我们首先要了解的是,如果一个类没有重写hashCode方法,默认情况下,它会返回不同的值,即,当通过这个类来创建不同的对象时,所得到的hashCode值是不同的,还有一点就是,如果没有重写equals方法默认情况下,在比较一个类中的两个 对象时,就算这两个对象中的内容相等,也会返回false值。
还有一点需要注意的是通过java中的一些内置类已经重写了hashCode()方法,因此通过这些类创建的对象其hashCode值是一样的,equals方法也是被重写了(即两个对象的内容相等就返回true),而我们自己定义的类默认是没有重写的。
下面说一下。在执行一个元素的保存操作时,它的存储过程其实是分为两个步骤的。第一步为:通过hashCode()方法,计算一个类对应的hashCode值,要知道如果我们重写了该方法,通过这个类创建的每个对象其hashCode值都是相同的,因此就可以唯一确定该对象应该存在哪个链表中,第二步是:当找到一个链表后,就要计算重写的equals方法在链表中找一下,有没有元素其内容已经和待存储的元素内容相同,如果有就不存储该,如果没有,就把该元素放到该链表中。
由此我们可以看,为什么要重写一个类中的这两个方法了,
num * this.name.hashCode()就是要确保,通过该类创建的对象都有一个相同的hash码值,以便存在相同的链表中;this.num==s.num && this.name.equals(s.name);功能就是比较两个对象中的内容,如果内容相同则第二个对象就不用存储了,这就保证在一个HashSet容器中不会出现相同的值对象。
以上就是关于hash“容器”的一个简单小结。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)