
非root用户下搭建hadoop
环境准备1、在VirtualBox下安装Ubuntu14.042、两台虚拟主机都有名为hadoop用户3、实现准备好hadoop-2.7.4.tar.gz,jdk-8u151-linux-x64.tar.gz压缩包一、安装增强工具,以便方便本机与虚拟机传输工具打开虚拟机后在窗口顶部点击设备,点击安装增强工具功能,弹出窗口后点击Run,输入当前普通用户密码,然后等待弹出命令行运行结束sudo mou
环境准备
3、实现准备好hadoop-2.7.4.tar.gz,jdk-8u151-linux-x64.tar.gz压缩包
一、安装增强工具,以便方便本机与虚拟机传输工具
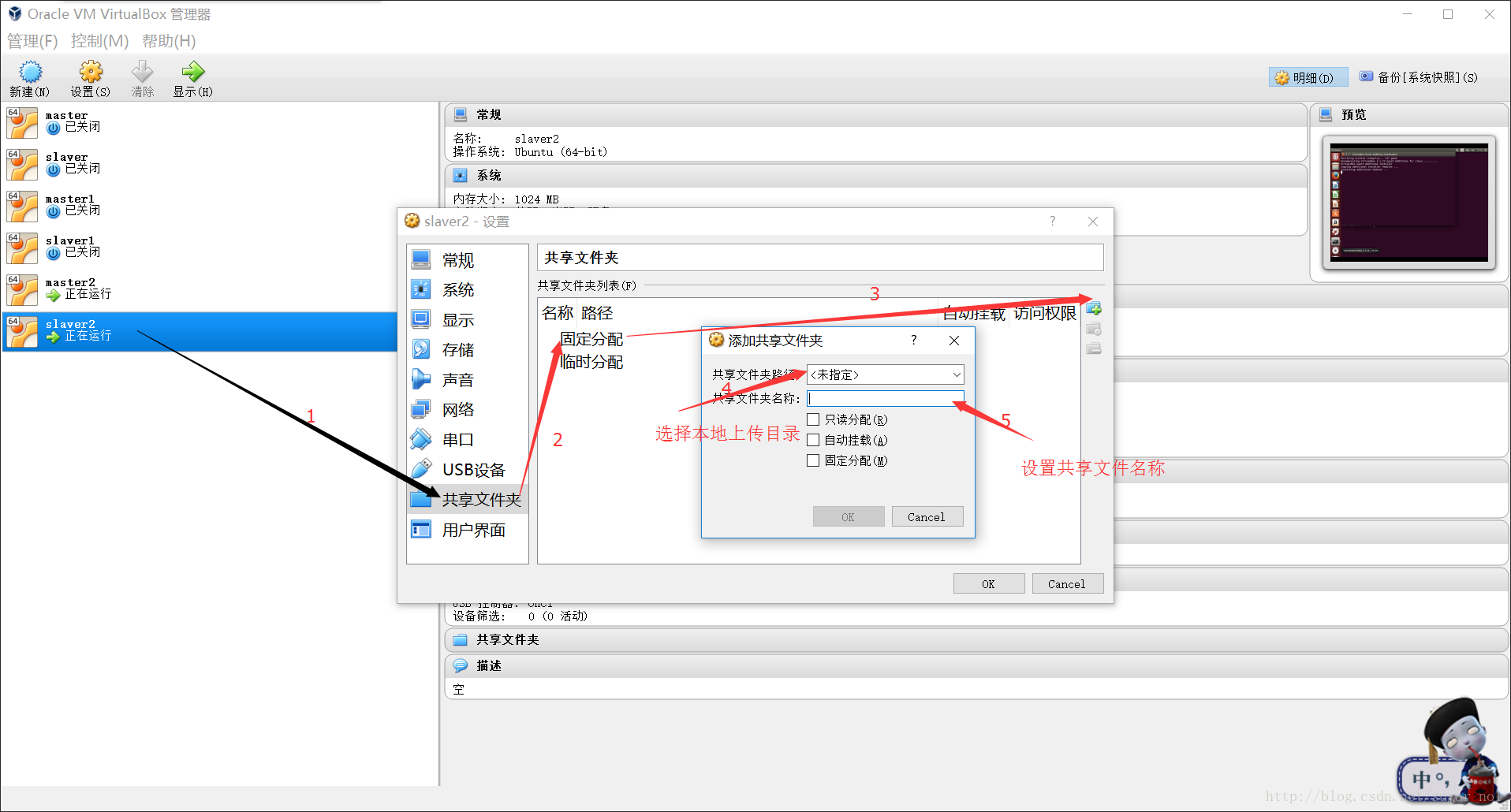
打开虚拟机后在窗口顶部点击设备,点击安装增强工具功能,弹出窗口后点击Run,输入当前普通用户密码,然后等待弹出命令行运行结束
sudo mount -t vboxsf 共享文件夹名称 虚机目录
二、创建软件存放目录
我是在/home/hadoop/创建hadoop目录后来发现不是太好,但不管在哪都要保证每台虚机存放位置要一致
hadoop@master:~$ ls
Desktop Documents Downloads examples.desktop hadoop Music Pictures Public soft Templates Videos
解压事先准备的压缩包到指定的目录
tar -zxvf hadoop-2.7.4.tar.gz -C ~/hadoop
tar -zxvf jdk-8u151-linux-x64.tar.gz -C ~/hadoop
进入~/hadoop重命名
mv jdk1.8.0_151 jdk
mv hadoop-2.7.4 hadoop
三、安装ssh,配置免密码登录
sudo apt-get install openssh-server
输入hadoop用户密码
ssh localhost 初始化ssh以生成~/.ssh目录
进入~/.ssh目录
ssh-keygen -t rsa
一直敲回车
生成authorized_keys
cat id_rsa.pub >> authorized_keys
同样的操作在slaver节点上安装、配置ssh服务
在master节点上将authorized_keys复制到slaver节点上
hadoop@master:~/.ssh$ scp authorized_keys hadoop@salver:~
再将复制后的文件添加到本机的authorized_keys中
hadoop@master:~/.ssh$cat ../autorized_keys >> autorized_keys
四、配置环境变量,设置主机域名
1、配置环境变量
hadoop@master:~$ vi ~/.bashrc
export JAVA_HOME=/home/hadoop/hadoop/jdk
export HADOOP_HOME=/home/hadoop/hadoop/hadoop
export SCALA_HOME=/home/hadoop/hadoop/scala
export SPARK_HOME=/home/hadoop/hadoop/spark
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH
2、设置域名
hadoop@master:~$ sudo vi /etc/hosts
内容:
127.0.0.1 localhost
#127.0.1.1 master
10.0.2.21 master
10.0.2.22 slaver
在slaver节点上同样设置,也可以使用scp -r 命令将master节点上的文件复制到slaver节点上
刷新一下后即可验证配置是否正确
hadoop@master:~$ source ~/.bashrc
hadoop@master:~$ java -versionjava version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
同样使用scp -r 可以将master节点中的jdk、hadoop文件复制到slaver进行同样的验证
五、修改hadoop配置文件
hadoop-env.sh 文件
hadoop@master:~/hadoop/hadoop/etc/hadoop$ vi hadoop-env.sh
修改内容为export JAVA_HOME=/home/hadoop/hadoop/jdk
具体jdk根据自己而修改
core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
</property>
</configuration>
hdfs-site.xml 文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
</configuration>
mapred-site.xml.template文件(文件名可改为 mapred-site.xml)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce-shuffle</value>
</property>
</configuration>
slaves文件
master
slaver
格式化namenode
进入hadoop文件下的bin
./hdfs namenode -format
启动hadoop
进入hadoop文件下的sbin
./start-all.sh
jps查看
master节点上
hadoop@master:~/hadoop/hadoop/etc/hadoop$ jps
4337 Jps
2820 DataNode
2693 NameNode
hadoop@master:~/hadoop/hadoop/etc/hadoop$ jps
4337 Jps
2820 DataNode
2693 NameNode
3626 Master
3739 Worker
3163 ResourceManager
2987 SecondaryNameNode
3163 ResourceManager
2987 SecondaryNameNode
slaver节点上
hadoop@master:~/hadoop/hadoop/etc/hadoop$ jps
4337 Jps
2820 DataNode
2693 NameNode
3626 Master
3739 Worker
3163 ResourceManager
2987 SecondaryNameNode
验证Wordcount
进入hadoop文件下cd share/hadoop/mapreduce/
hadoop@master:~/hadoop/hadoop/share/hadoop/mapreduce$ hadoop jar ./hadoop-mapreduce-examples-2.7.4.jar wordcount /input/xxx /out
本次只是验证hadoop分布式,不是太严谨
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)