深度学习之五:序列模型与词向量
1 循环序列模型1.1 序列模型的适用范围序列模型是一种用于处理序列数据的模型,它可以用于语音识别,音乐生成,情感分类,机器翻译,命名实体识别等。模型的输出也可能是一个序列。1.2 相关的符号约定x<k>x<k>x^{} 表示输入序列中的第k个元素y<k>y<k>y^{} 表示输出序列中
1 循环序列模型
1.1 序列模型的适用范围
序列模型是一种用于处理序列数据的模型,它可以用于语音识别,音乐生成,情感分类,机器翻译,命名实体识别等。模型的输出也可能是一个序列。
1.2 相关的符号约定
x<k>
x
<
k
>
表示输入序列中的第k个元素
y<k>
y
<
k
>
表示输出序列中的第k个元素
x(i)<k>
x
(
i
)
<
k
>
表示第i个输入序列中的第k个元素
y(i)<k>
y
(
i
)
<
k
>
表示第i个输出序列中的第k个元素
Tx
T
x
表示输入序列的长度
T(i)x
T
x
(
i
)
表示第i个输入序列的长度
Ty
T
y
表示输出序列的长度
T(i)y
T
y
(
i
)
表示第i个输出序列的长度
1.3 RNN模型
1.3.1 词的one-hot表示
构造一个词汇表(也称为词典),若词汇个数为n,词(word)在词典中的位置i记作 wi w i ,则词可表示为一个长度为n的一维向量,向量中第 wi w i 位置的元素为1,其他位置为0。
1.3.2 模型示意
在处理序列数据时,由于输入和输出长度的不同,且序列模型的维度过高,参数过多,无法使用传统的全联接神经网络来处理,因此必须要使用新的序列化的模型。见下图:
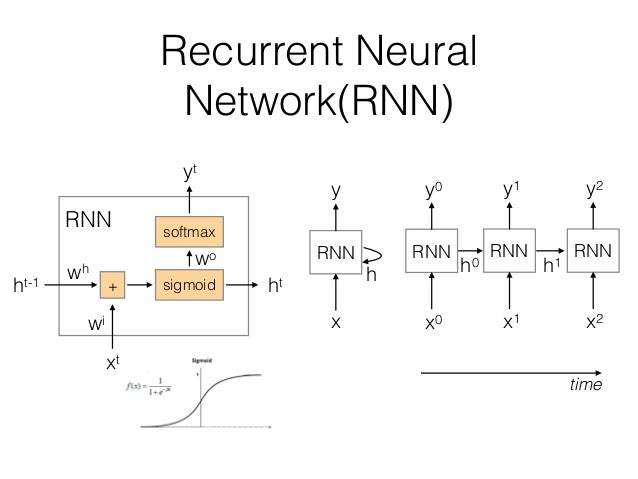
在图中,RNN单元在时刻 t0 t 0 接收输入 x0 x 0 并产生输出 y0 y 0 。在下一个时刻 t1 t 1 ,RNN单元同时接收输入 x1 x 1 和上一个时刻的输出 h0 h 0 ,从而产生本时刻的输出。这使得RNN可以考虑历史输入的影响。
1.3.3 前向传播
从上图的RNN单元的结构中,可以推导前向传播的计算公式
ht=g(Wh∗ht−1+Wixt+bh)
h
t
=
g
(
W
h
∗
h
t
−
1
+
W
i
x
t
+
b
h
)
可以将
Wh,Wi
W
h
,
W
i
横向堆叠,将
ht−1,xt
h
t
−
1
,
x
t
纵向堆叠,则公式改写为:
ht=g([Wh|Wi]⋅[ht−1xt]+bh)
h
t
=
g
(
[
W
h
|
W
i
]
⋅
[
h
t
−
1
x
t
]
+
b
h
)
yt=f(Wo∗ht+bo)
y
t
=
f
(
W
o
∗
h
t
+
b
o
)
1.3.4 RNN前向传播实现
# 实现单个RNN单元内部的计算
def rnn_cell_forward(xt, a_prev, parameters):
Wax = parameters["Wax"] #alias Wt
Waa = parameters["Waa"] #alias Wh
Wya = parameters["Wya"] #alias Wo
ba = parameters["ba"] #alias bh
by = parameters["by"] #alias bo
# compute next activation state
a_next = np.tanh(np.dot(Wax, xt) + np.dot(Waa, a_prev) + ba)
yt_pred = softmax(np.dot(Wya, a_next) + by)
cache = (a_next, a_prev, xt, parameters)
return a_next, yt_pred, cache
# 实现沿时间序列向前计算
def rnn_forward(x, a0, parameters):
caches = []
n_x, m, T_x = x.shape
n_y, n_a = parameters["Wya"].shape
# initialize "a" and "y" with zeros
a = np.zeros((n_a, m, T_x))
y_pred = np.zeros((n_y, m, T_x))
a_next = a0
# loop over all time-steps
for t in range(T_x):
# Update next hidden state, compute the prediction, get the cache
a_next, yt_pred, cache = rnn_cell_forward(x[:,:,t], a_next, parameters)
a[:,:,t] = a_next
y_pred[:,:,t] = yt_pred
caches.append(cache)
caches = (caches, x)
return a, y_pred, caches1.3.4 损失函数
单个样本的损失函数定义为:
整体的损失函数为:
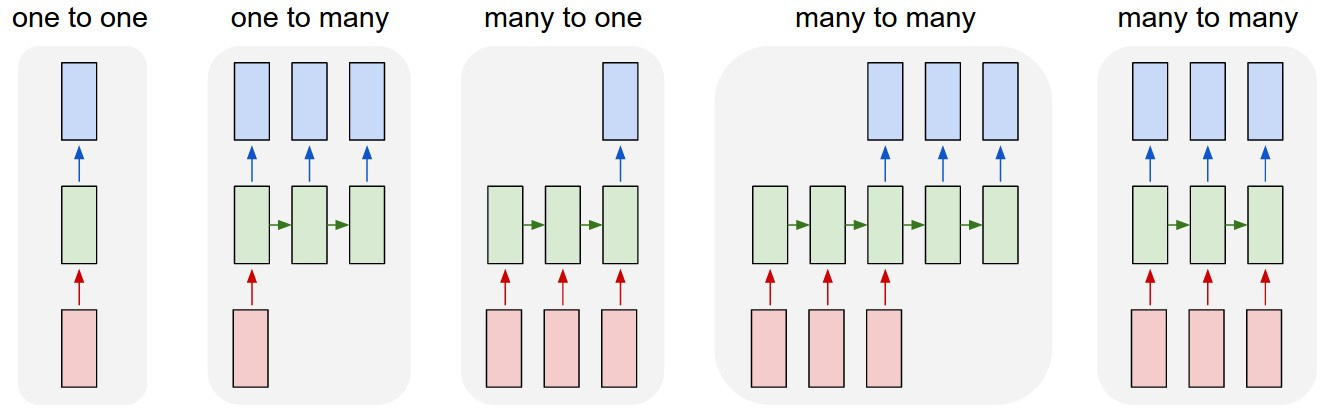
1.3.5 RNN的分类
根据输入和输出数量的不同,可以将RNN模型分为三类
Many-to-Many,例如RNN翻译模型
Many-to-One,例如情感分类模型
One-to-Many,例如音乐的生成模型
1.4 构建RNN语言模型
所谓语言模型,其实是指基于语料库的语言序列的统计概率模型,模型可以计算出某个句子的概率。
可以使用RNN来生成语言模型,需要将语料库中的语句逐个输入到RNN中,以此来训练模型的参数。
模型的损失函数为:
1.5 RNN模型序列采样
模型采样的方法,先随机选取一个词将其输入到网络中,并将每次输出作为输入进入到后一个单元中,不断循环,直到生成语句结束符。这样生成的一个语句称为模型的采样序列。
利用模型采样,可以完成文本生成的任务。
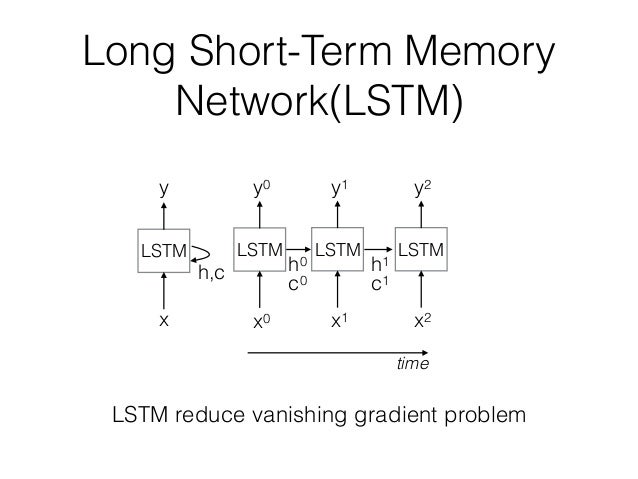
1.6 LSTM
由于语句过长,会出现梯度消失或梯度爆炸的问题,因此基本的RNN网络难于处理语言中的长程依赖问题。为了解决这个问题,人们提出了LSTM与GRU两种改进模型。
下面是1997年提出来的LSTM网络的结构,其增加了一个记忆单元(Memory cell),用于跟踪当前输入的长程依赖。
下图是LSTM单元的结构图:
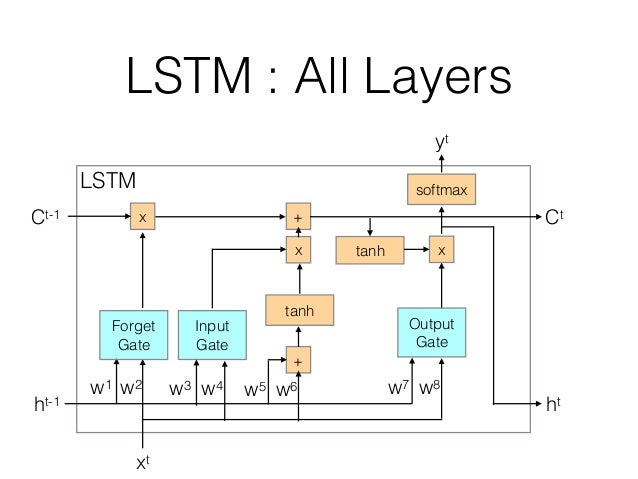
图中可以看出,相比于基本的RNN单元,新增加了遗忘门,输入门,输出门,各个门的具体实现为:
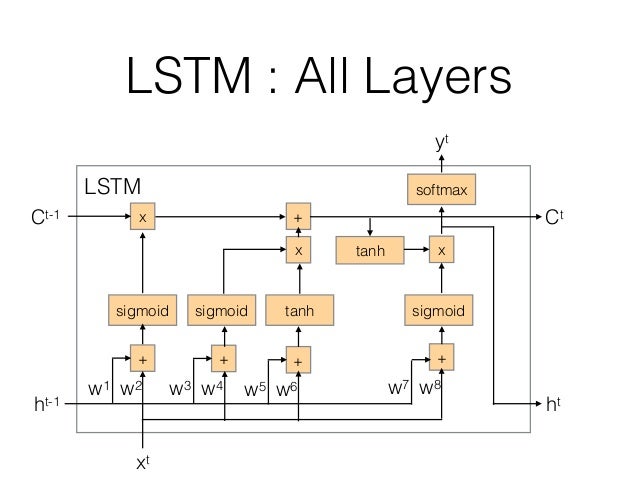
下面推导t时刻时记忆模块的更新公式:
遗忘门:
Γf=σ(Wf[h<t−1>,x<t>]+bf)
Γ
f
=
σ
(
W
f
[
h
<
t
−
1
>
,
x
<
t
>
]
+
b
f
)
输入门:
Γu=σ(Wu[h<t−1>,x<t>]+bu)
Γ
u
=
σ
(
W
u
[
h
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
候选记忆:
c<t>o=tanh(Wc[h<t−1>,x<t>]+bc)
c
o
<
t
>
=
t
a
n
h
(
W
c
[
h
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
最终记忆:
c<t>=Γf∗c<t−1>+Γu∗c<t>o
c
<
t
>
=
Γ
f
∗
c
<
t
−
1
>
+
Γ
u
∗
c
o
<
t
>
输出门:
Γo=σ(Wo[h<t−1>,x<t>]+bo)
Γ
o
=
σ
(
W
o
[
h
<
t
−
1
>
,
x
<
t
>
]
+
b
o
)
输出:
h<t>=Γo∗tanhc<t>
h
<
t
>
=
Γ
o
∗
t
a
n
h
c
<
t
>
1.7 实现LSTM的前向计算
def lstm_cell_forward(xt, a_prev, c_prev, parameters):
Wf = parameters["Wf"]
bf = parameters["bf"]
Wi = parameters["Wi"]
bi = parameters["bi"]
Wc = parameters["Wc"]
bc = parameters["bc"]
Wo = parameters["Wo"]
bo = parameters["bo"]
Wy = parameters["Wy"]
by = parameters["by"]
# Retrieve dimensions from shapes of xt and Wy
n_x, m = xt.shape
n_y, n_a = Wy.shape
# Concatenate a_prev and xt
concat = np.zeros((n_a + n_x, m))
concat[: n_a, :] = a_prev
concat[n_a:, :] = xt
# Compute values for ft, it, cct, c_next, ot, a_next
ft = sigmoid(np.dot(Wf, concat) + bf)
it = sigmoid(np.dot(Wi, concat) + bi)
cct = np.tanh(np.dot(Wc, concat) + bc)
c_next = ft * c_prev + it * cct
ot = sigmoid(np.dot(Wo, concat) + bo)
a_next = ot * np.tanh(c_next)
# Compute prediction of the LSTM cell
yt_pred = softmax(np.dot(Wy, a_next) + by)
# store values needed for backward propagation in cache
cache = (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters)
return a_next, c_next, yt_pred, cache
def lstm_forward(x, a0, parameters):
# Initialize "caches", which will track the list of all the caches
caches = []
# Retrieve dimensions from shapes of x and Wy
n_x, m, T_x = x.shape
n_y, n_a = parameters["Wy"].shape
# initialize "a", "c" and "y" with zeros
a = np.zeros((n_a, m, T_x))
c = np.zeros((n_a, m, T_x))
y = np.zeros((n_y, m, T_x))
# Initialize a_next and c_next
a_next = a0
c_next = np.zeros(a_next.shape)
# loop over all time-steps
for t in range(T_x):
# Update next hidden state, next memory state, compute the prediction, get the cache
a_next, c_next, yt, cache = lstm_cell_forward(x[:, :, t], a_next, c_next, parameters)
# Save the value of the new "next" hidden state in a
a[:, :, t] = a_next
# Save the value of the prediction in y
y[:, :, t] = yt
# Save the value of the next cell state
c[:, :, t] = c_next
# Append the cache into caches
caches.append(cache)
caches = (caches, x)
return a, y, c, caches1.8 GRU单
下图是2014年提出的GRU的单元示意图: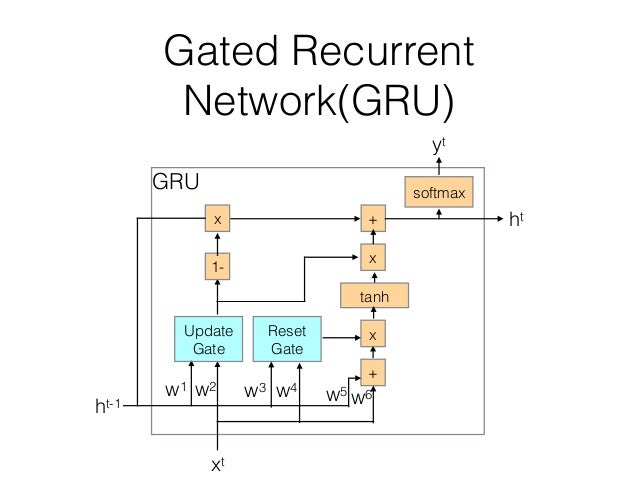
GRU单元相比LSTM单元,进行了简化。它使用两个门–更新门与重置门来控制是否更新或重置记忆单元。
下面推导
t
t
时刻时记忆单元的更新公式:
对于GRU来说,
重置门:
Γr=σ(Wr[c<t−1>,x<t>]+br)
Γ
r
=
σ
(
W
r
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
r
)
更新门:
Γu=σ(Wu[c<t−1>,x<t>]+bu)
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
候选记忆:
c<t>o=tanh(Wc[Γrc<t−1>,x<t>]+bu)
c
o
<
t
>
=
t
a
n
h
(
W
c
[
Γ
r
c
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
最终记忆:
c<t>=Γu∗c<t>o+(1−Γu)∗c<t−1>
c
<
t
>
=
Γ
u
∗
c
o
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
GRU单元只有两个门,更简单一些,运算速度更快,相比于LSTM 可以搭建更大型一些的网络。
1.9 双向神经网络
单向的RNN可以捕获前向的内容,但无法捕获后向的内容,因此人们引入双向RNN来解决需要同时捕获前后上下文的内容这种问题。
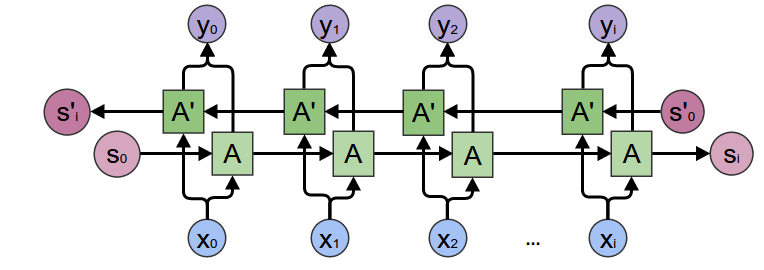
双向RNN的问题是必须有完整的句子输入,而单向RNN则没有这个约束。
1.10 深层循环神经网络

2 自然语言处理与词嵌入
2.1 词的向量表示
下面介绍最简单的一种向量表示法,即one-hot向量。初始时将所有词排序,这样每个词可分配到一个位置序号idx。然后每个词可表示成一个 R|V|∗1 R | V | ∗ 1 的向量,向量的第idx位为1,其余位置为0。
例如如果我们只有4个词,{aa,ab,ba,bb},则有:
词的one-hot表示编码过于稀疏(大量的0)。另一方面不同向量之间是正交的,无法比较不同词之间的关系。
word-embeddings是用多个不同维度的特征来表示每一个词。由于特征的维度数远小于词汇数,因此可以避免了稀疏的问题。另一方面词嵌入可以表现词之间的相似度。
下图是降维之后词向量的表示,可见相似的概念的词聚集一起。
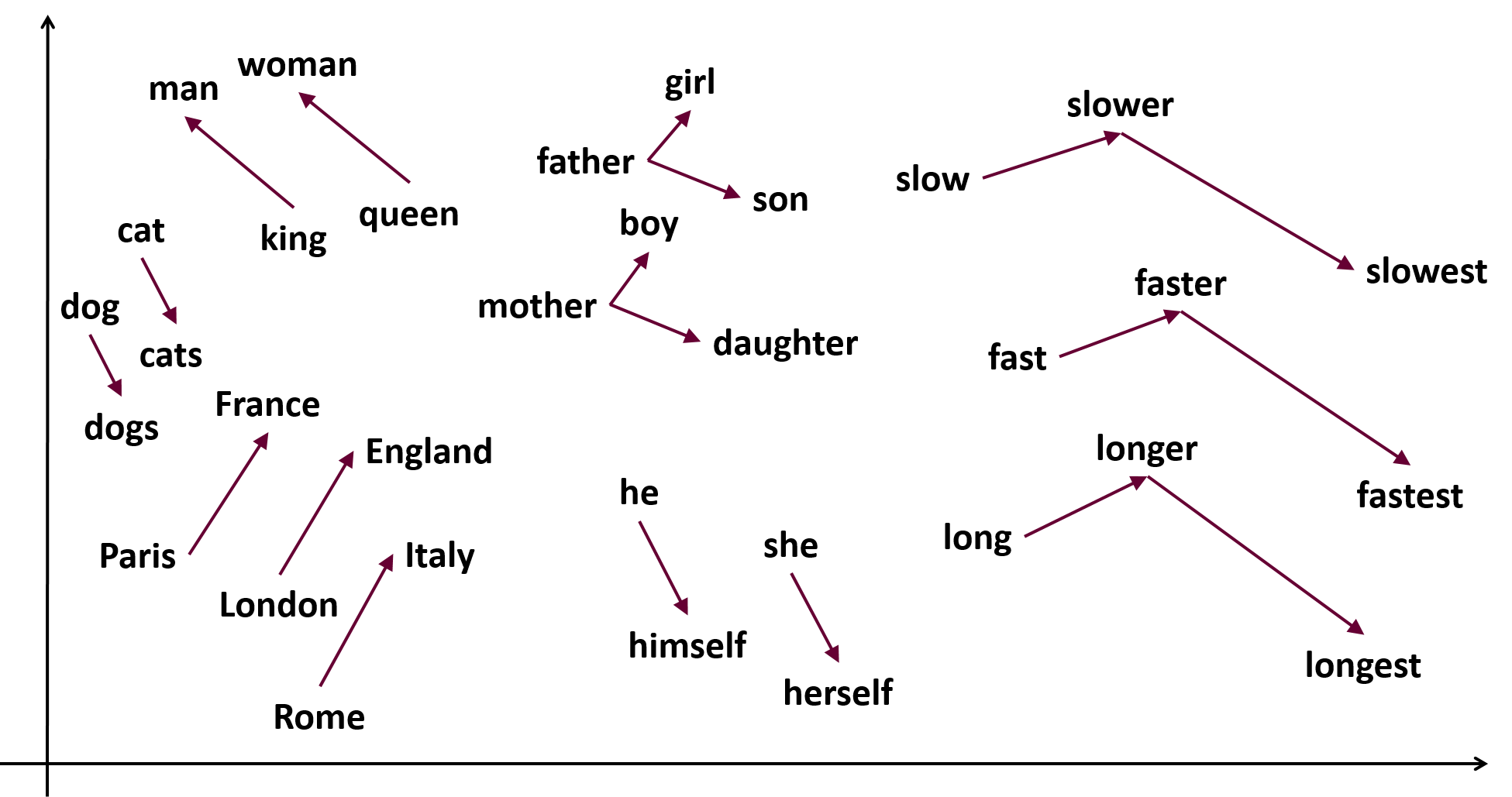
嵌入矩阵 E E 是把词典里所有词的词向量作为列向量排列成为矩阵。若某个词的one-hot表示记为,词向量表示记为 ew e w 则有:
2.2 CBOW模型
对于一个句子,根据某个位置前后(上下文长度)若干个词,而预测此位置词的模型称为连续词袋模型(Continuous Bag of Words Model)。例如,今天是__六 –> 星期。
引入下面的记号,若无特殊说明1维向量采用列向量表示:
wi
w
i
,词典中第i个词
V
V
,输入词权重矩阵,其第i列表示作为输入的向量,记作
vi
v
i
U
U
,输出词权重矩阵,其第i行表示作为输出的向量,记作
ui
u
i
模型的工作步骤:
- 若上下文长度为m,则生成2m个输入词的one-hot向量( xc−m,...xc−1,xc+1...,xc+m x c − m , . . . x c − 1 , x c + 1 . . . , x c + m )
- 对第1步得到的2m个向量,计算 vj=Vxj v j = V x j
- 对第2步得到的2m个向量,计算均值 vˆ=∑vj2m v ^ = ∑ v j 2 m
- 计算得分向量 z=Uvˆ z = U v ^ ,其中元素较高的值表示相似度越好
- 转换得分向量为概率向量 yˆ=softmax(z) y ^ = s o f t m a x ( z )
- 我们希望计算出的 yˆ=y y ^ = y ,y是输出词的one-hot向量
为了计算矩阵U和V,需要损失函数,从信息论中引入交叉熵来定义损失函数
由于y是one-hot向量,因此
则我们要最小化损失函数:
使用随机梯度下降更新 uc和vj u c 和 v j
2.3 Skip-gram模型
Skip-Gram模型可以根据一个中心,预测此词前后若干个关键词。此模型的工作步骤如下:
- 生成中心词的one-hot表示向量 x x
- 获取中心词的输入表示
- 计算得分向量 z=Uvc z = U v c
- 将得分向量转化为概率向量, yˆ=softmax(z) y ^ = s o f t m a x ( z ) ,上下文词为概率向量中较大值位置的one-hot向量
- 我们期望生成的概率向量可以匹配真实的向量
为了计算矩阵U,V,基于朴素Bayes思想,使损失函数最小化:
minimizeJ=−logP(Context|wc)
m
i
n
i
m
i
z
e
J
=
−
l
o
g
P
(
C
o
n
t
e
x
t
|
w
c
)
=log∏2mj=0,j≠mP(wc−m+j|wc)
=
l
o
g
∏
j
=
0
,
j
≠
m
2
m
P
(
w
c
−
m
+
j
|
w
c
)
=−log∏P(uc−m+j|vc)
=
−
l
o
g
∏
P
(
u
c
−
m
+
j
|
v
c
)
=−log∏exp(uTc−m+jvc)∑exp(uTkvc)
=
−
l
o
g
∏
e
x
p
(
u
c
−
m
+
j
T
v
c
)
∑
e
x
p
(
u
k
T
v
c
)
=−∑uTc−m+jvc+2mlog∑exp(uTkvc)
=
−
∑
u
c
−
m
+
j
T
v
c
+
2
m
l
o
g
∑
e
x
p
(
u
k
T
v
c
)
2.4 训练词向量的实现
本节展示使用gensim训练词向量的方法。gensim是一个开源的文档主题建模库。下面先说明其用于训练词向量的主要API。
Word2Vec(sg, size, window, hs, negative, min_count)
- sg:若1使用CBOW算法,其他为skip-gram算法
- size:训练的词向量的维度
- window:词上下文的距离
- hs:是否使用分层Softmax
- negative:是否使用负采样
- min_count:忽略频率出现小于指定次数的词
- workers:并行训练的线程数
该方法用于构建训练的模型实例。
build_vocab(sents, update)
- sents:可迭代的待训练的语料语句
- update:若为初表示新的词将追加到模型中
模型实例的方法,用于初始化训练模型的词汇表。
train(sents,total_examples,total_words, epochs)
- sents:可迭代的待训练的语料语句
- total_examples:训练语料句子数
- total_words:训练语料的词数
- epochs:训练时的迭代次数
load_word2vec_format(fname, binary)
- fname:词向量文件
- binary:词向量文件的类型,txt或bin类型
用于加载词向量文件,对于gensim生成的词向量文件的格式,其第一行为词向量的条数。从第二行开始,每行一个词向量。每行的第一列为词,其他列为浮点数。
下面的代码示例训练词向量并保存的方法。
from gensim.models import Word2Vec
# lines 为多行文本,可以从文本文件中读取
def train_model(lines):
sentences = []
for line in lines:
tokens = jieba.lcut(line, HMM=False)
sentences.append(tokens)
word2vec_model = Word2Vec(sg=1, seed=1, workers=4, size=300, min_count=5, window=5)
token_count = sum([len(sentence) for sentence in sentences])
word2vec_model.build_vocab(sentences=sentences, keep_raw_vocab=True)
word2vec_model.train(sentences=sentences, total_words=token_count, epochs=10)
print word2vec_model['king']
# array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
print word2vec_model.similarity('king', 'queen') # 0.84
word2vec_model.wv.save_word2vec_format('wv.txt')训练自己的词向量,需要从网络上准备大量的语料,然后自己花费时间进行训练,过程相对比较费时。完全可以从网络上获得他人训练好的词向量。下面的代码示例了如何加载已经训练好的词向量文件。
from gensim.models import KeyedVectors
wv = KeyedVectors.load_word2vec_format('wv.txt', binary=False)
print wv['computer']
2.5 负采样与分层Softmax
分层Softmax与负采样都是优化方法,用于加速word2vec词向量训练算法的过程。
负采样的思想是在生成语料时随机从字典中选择大量不在窗口内的词与中心词构成y

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)