分布式存储系统学习笔记(二)—分布式文件系统(3)—Facebook文件系统(Haystack)
1. 场景描述Facebook目前存储了2600亿张照片,总大小是20PB;用户每周新增照片数10亿,总大小60TB,平均每秒的写操作数达到了3500次,读操作峰值可以达到每秒百万次。2. 系统架构a) 架构描述Facebook Haystack的思路与TFS相似,也是多个逻辑文件共享一个物理文件,架构图及读请求处理流程如下:Haystack系统主要包括
1. 场景描述
Facebook目前存储了2600亿张照片,总大小是20PB;用户每周新增照片数10亿,总大小60TB,平均每秒的写操作数达到了3500次,读操作峰值可以达到每秒百万次。
2. 系统架构
a) 架构描述
Facebook Haystack的思路与TFS相似,也是多个逻辑文件共享一个物理文件,架构图及读请求处理流程如下:
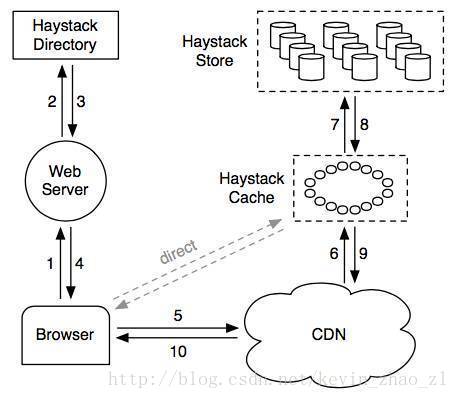
Haystack系统主要包括三个部分:目录、存储以及缓存。Haystack存储是物理存储节点,以物理卷轴的形式组织存储空间,每个物理卷轴一般很大(100GB)。每个物理卷轴对应一个物理文件,因此每个存储节点上的物理文件元数据都很小。多个物理存储节点上的物理卷轴组成一个逻辑卷轴,用于备份。Haystack目录存放逻辑卷轴和物理卷轴的对应关系以及照片id和逻辑卷轴之间的映射关系。Hatstack缓存主要用于解决对VCDN提供商过于依赖的问题,提供最近增加的照片的缓存服务。
Haystack的读流程大致为:用户访问一个页面web服务器请求Haystack目录构造一个URL:http://<CDN>/<Cache>/<Machineid>/<Logical volume,Photo>,后续根据每个部分的信息一次访问CDN,Haystack缓存和后端的Haystack存储节点。Haystack目录构造URL可以省略<CDN>部分从而使用户直接请求Haystack缓存而不经过CDN。Haystack缓存收到的请求包含两个部分:用户浏览器的请求以及CDN的请求,Haystack缓存只缓存用户浏览器发送的请求且要求请求的Haystack存储节点是可写的。一般来说Haystack后端的存储节点写一段时间以后达到容量上限变为只读,因此可写节点的照片为最近增加的照片,是热点数据
b) 写流程
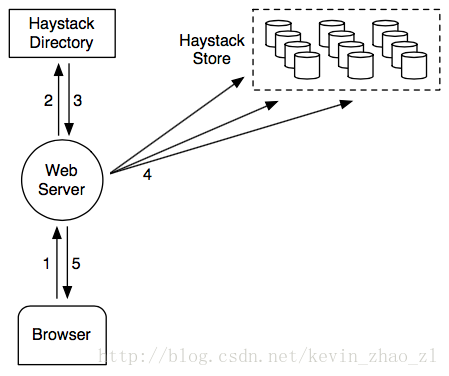
Haystack的写请求(照片上传)处理流程:Web服务器首先请求Haystack目录获取可写的逻辑卷轴接着生成照片唯一id并将数据写入每一个对应的物理卷轴(备份数一般为3)。写操作成功要求所有的物理卷轴都成功,如果中间出现故障,需要重试。
Haystack一致性模型保证只要写操作成功,逻辑卷轴对应的所有物理卷轴都存在一个有效的照片文件,但有效照片文件在不同的物理卷轴中的偏移可能不同。
Haystack存储节点支持追加操作如果需要更新一张照片,可以新增一张编号相同的照片到系统中,如果新增照片和原有的照片在不同的逻辑卷轴,Haystack目录的元数据会更新为最新的逻辑卷轴;如果新增的照片和原有照片在相同的逻辑卷轴,Haystack存储会以便宜更大的文件为准。
c) 容错处理
i. Haystack存储节点容错
检测到存储节点故障时,所有物理卷轴对应的逻辑卷轴都被标记为只读。存储节点上未完成的写操作全部失败,写操作将重试;如果发生故如果存储节点不可恢复需要执行一个拷贝任务从其他副本所在的存储节点拷贝丢失的物理卷轴的数据;由于物理卷轴一般很大,所以拷贝一般为小时级别的。
ii. Haystack目录容错
Haystack目录采用主备数据库做持久化存储,由主备数据库提供容错机制。
d) Haystack目录
Haystack的目录功能主要有:
- 提供逻辑卷轴到物理卷轴的映射,维护照片id到逻辑卷轴的映射
- 提供负载均衡,为写操作选择逻辑卷轴,读操作选择物理卷轴
- 屏蔽CDN服务,可以选择某些图片请求直接走Haystack缓存
- 标记某些逻辑卷轴为只读
前面提到,Facebook相册系统的每秒的写操作3500次,读操作100万次,每个写请求都需要通过Haystack缓存获取可写的卷轴,每个读请求需要通过Haystack缓存构造读取URL,这里需要注意,照片id到逻辑卷轴的映射数据量太大,单机内存无法存放,猜测内部使用了Mysql sharding集群且增加了Memcache集群满足查询需求。
e) Haystack存储
Haystack保存到物理卷轴,每个物理卷轴对应文件系统中的一个物理文件,每个物理文件的格式如下:
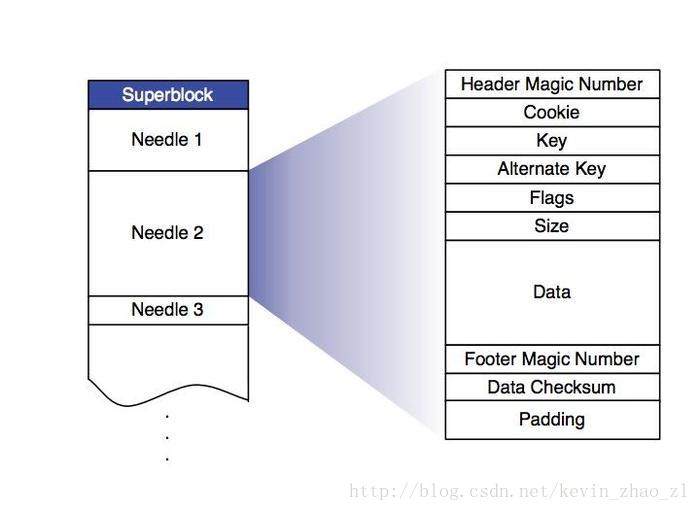
每个照片文件是一个Needle,包含实际数据及逻辑照片文件的元数据。部分元数据需要装载到内存中用于照片查找,包括Key(照片id,8字节),Alternate Key(照片规格,包括Thumbnail、Small、Medium及Large,4字节),照片在物理卷轴的偏移Offset(4字节),照片的大小Size(4字节),每张照片张勇20字节。假设每台机器可用磁盘为8TB,照片平均大小为80KB,单击存储的照片数为8TB/80KB=100M,占用内存100MBx20=2GB。
存储节点宕机时,需要恢复内存中的逻辑照片查找表,扫描整个物理卷轴耗时太长,因此对每个物理卷轴维护了一个索引文件,保存每个Needle查找相关的元数据。写操作首先更新索引文件,由于更新索引文件是异步的,所以可能出现索引文件和物理卷轴文件不一致的情况,不过由于对物理卷轴文件和索引文件的操作都是追加操作,只需要扫描物理卷轴文件最后写入的几个Needle,然后补全索引文件即可。
Haystack Store存储节点采用延迟删除的回收策略,删除照片知识像卷轴中追加一个带有删除标记的Needle,定时执行Compaction任务回收已删除空间。Compaction操作即将所有老数据文件中的数据扫描一遍,以保留最新一个照片的原则进行删除,并生成新的数据文件。
3. 讨论
相比TFS,Haystack的一大特色就是磁盘回收。Blob文件在TFS中通过<Block id,Blockoffset>标识,因此不能对TFS中的数据进行重整操作。而Haystack中的元信息只能定位到Blob文件所在的逻辑卷轴,Haystack存储节点可以根据情况对物理卷轴进行Compaction操作以回收磁盘文件。
Facebook Haystack中每个逻辑卷轴的大小为100GB,这样减少了元信息,但是增加了迁移的时间。假设限制内部网络带宽为20MB/s,那么迁移100GB的数据需要的时间为100GB/20MB/s=5000s。而TFS设计的数据规模相比Haystack要小,因此可以选择64MB的块大小,有利于负载均衡。
另外,Haystack使用RAID 6,并且底层文件系统使用性能更好的XFS,淘宝TFS不使用RAID机制,文件系统使用Ext3,由应用程序负责管理多个磁盘。Haystack使用了Akamai&Limelight的CDN服务,而淘宝使用自建的CDN。

开源、云原生的融合云平台
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)